写给程序员的机器学习入门 (十四) - 对抗生成网络 如何造假脸(一)
对抗生成网络 (GAN) 的原理
所谓生成网络就是用于生成文章,音频,图片,甚至代码等数据的机器学习模型,例如我们可以给出一个需求让网络生成一份代码,如果网络足够强大,生成的代码质量足够好并且能满足需求,那码农们就要面临失业了😱。当然,目前机器学习模型可以生成的数据比较有限并且质量都很一般,码农们的饭碗还是能保住一段时间的。
生成网络和普通的模型一样,要求有输入和输出,假设我们可以传入一些条件让网络生成符合条件的图片:
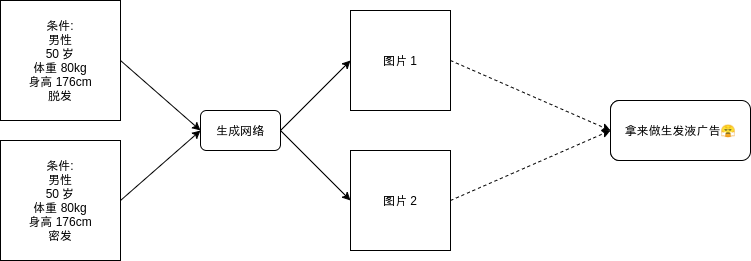
看起来非常好用,但训练这样的模型需要一个庞大的数据集,并且得一张张图片去标记它们的属性,实现起来会累死人。这篇文章介绍的对抗生成网络属于无监督学习,可以完全不需要给数据打标签,你只需要给模型认识一些真实数据,就可以让模型输出类似真实数据的假数据。对抗生成网络分为两部分,第一部分是生成器 (Generator),第二部分是识别器 (Discriminator),生成器负责根据随机条件生成数据,识别器负责识别数据是否为真。
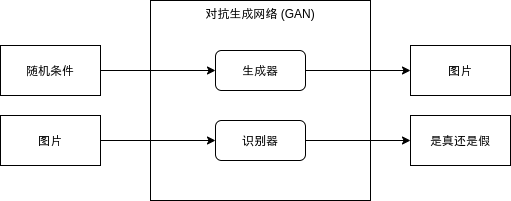
训练对抗生成网络有两大目标,这两大目标是矛盾的,这就是为什么我们叫对抗生成网络:
- 生成器需要生成骗过识别器 (输出为真) 的数据
- 识别器需要不被生成器骗过去 (针对生成器生成的数据输出为假,针对真实数据输出为真)
对抗生成网络的训练流程大致如下,需要循环训练生成器和识别器:
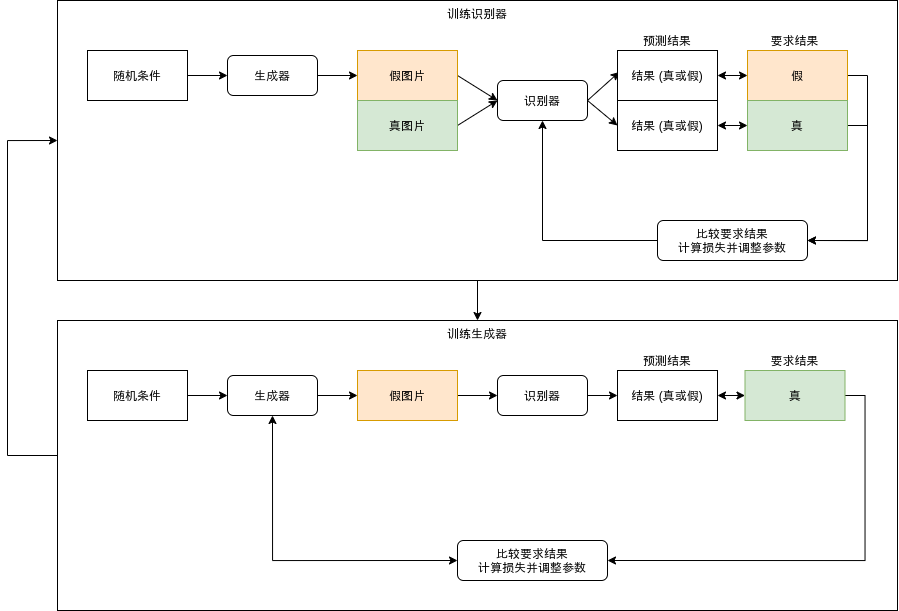
简单通俗一点我们可以用造假皮包为例来理解,好理解了吧🤗:
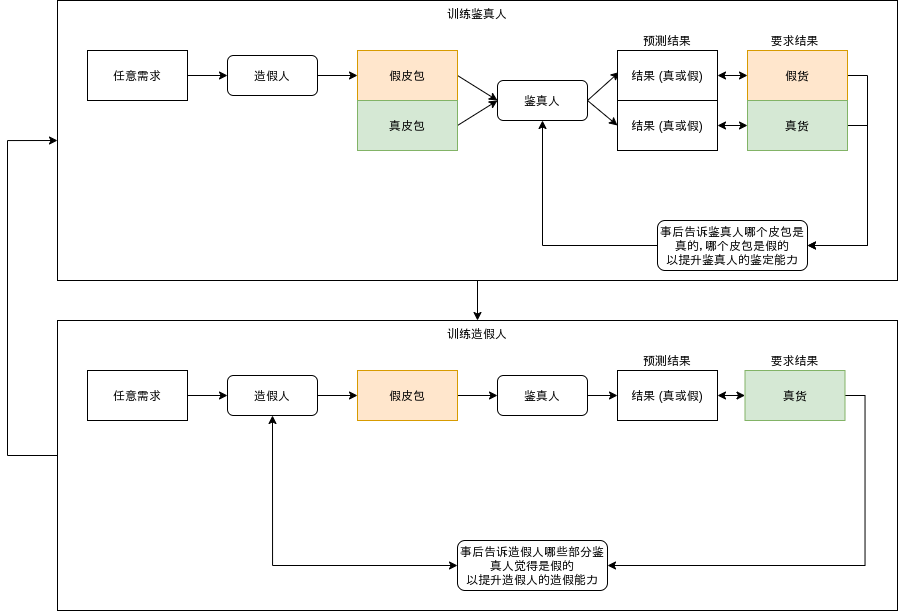
和现实造假皮包一样,生成器会生成越来越接近真实数据的假数据,最后会生成和真实数据一模一样的数据,但这样反而就远离我们构建生成网络的目的了(不如直接用真实数据)。使用生成网络通常是为了达到以下的目的:
- 要求大量看上去是真的,但稍微不一样的数据
- 要求没有版权保护的数据 (假数据没来的版权🤒)
- 生成想要但是现实没有的数据 (需要更进一步的工作)
看以上的流程你可能会发现,因为对抗生成网络是无监督学习,不需要标签,我们只能给模型传入随机的条件来让它生成数据,模型生成出来的数据看起来可能像真的但不一定是我们想要的。如果我们想要指定具体的条件,则需要在训练完成以后分析随机条件对生成结果的影响,例如随机生成的第二个数字代表性别,第六个数字代表年龄,第八个数字代表头发的数量,这样我们就可以调整这些条件来让模型生成想要的图片。
还记得上一篇人脸识别的模型不?人脸识别的模型会把图片转换为某个长度的向量,训练完成以后这个向量的值会代表人物的属性,而这一篇是反过来,把某个长度的向量转换回图片,训练成功以后这个向量同样会代表人物的各个属性。当然,两种的向量表现形式是不同的,把人脸识别输出的向量交给对抗生成网络,生成的图片和原有的图片可能会相差很远,把人脸识别输出的向量还原回去的方法后面再研究吧🤕。
对抗生成网络的实现
反卷积层 (ConvTranspose2d)
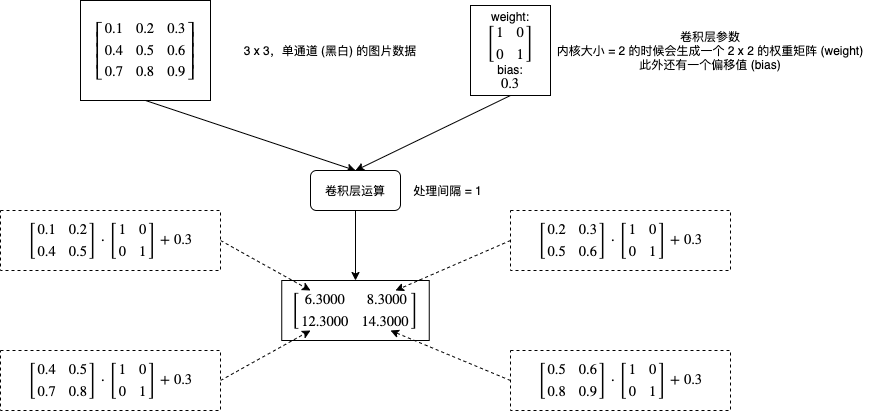
在第八篇介绍 CNN 的文章中,我们了解过卷积层运算 (Conv2d) 的实现原理,CNN 模型会利用卷积层来把图片的长宽逐渐缩小,通道数逐渐扩大,最后扁平化输出一个代表图片特征的向量:
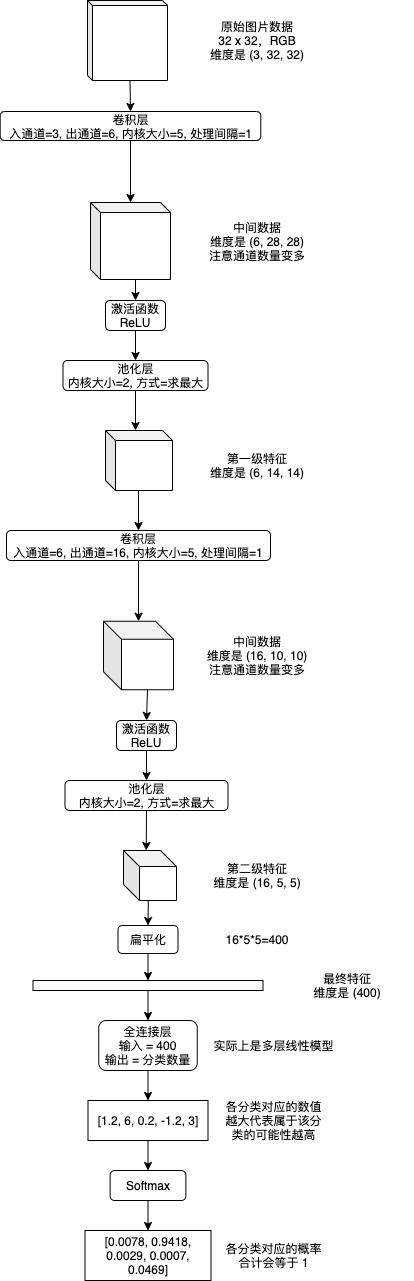
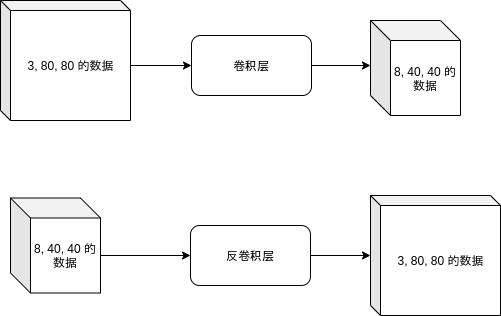
而在对抗生成网络的生成器中,我们需要实现反向的操作,即把向量当作一个 (向量长度, 1, 1) 的图片,然后把长宽逐渐扩大,通道数 (最开始是向量长度) 逐渐缩小,最后变为 (3, 图片长度, 图片宽度) 的图片 (3 代表 RGB)。
实现反向操作需要反卷积层 (ConvTranspose2d),反卷积层简单的来说就是在参数数量相同的情况下,把输出大小的数据还原为输入大小的数据:
要理解反卷积层的具体运算方式,我们可以把卷积层拆解为简单的矩阵乘法:
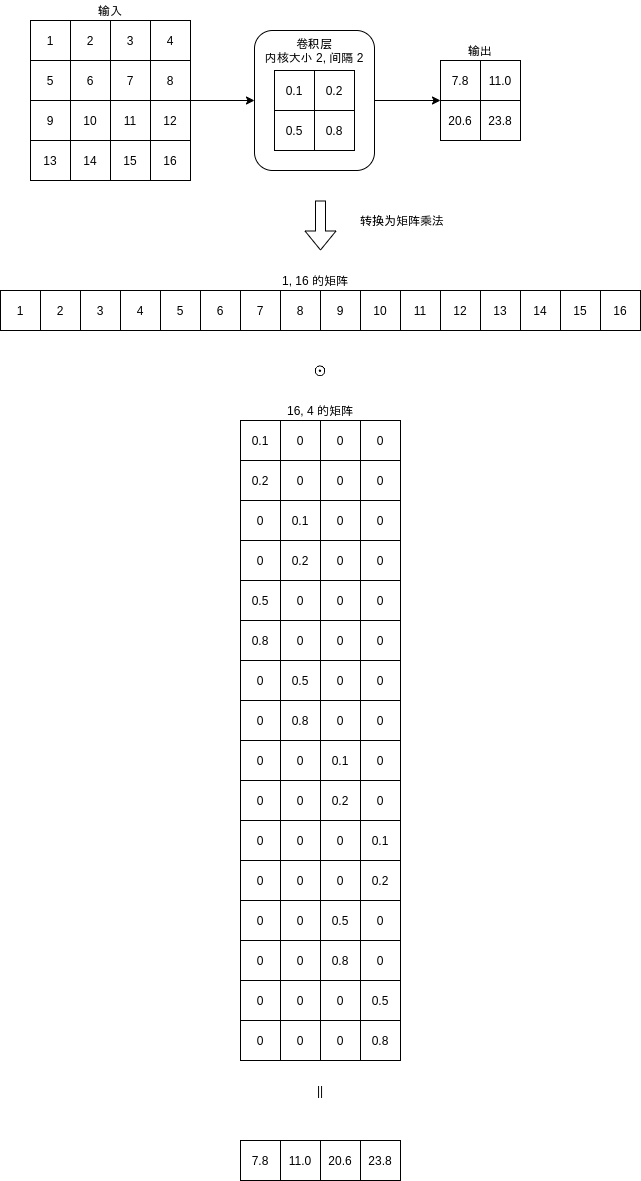
可以看到卷积层计算的时候可以根据内核参数和输入大小生成一个矩阵,然后计算输入与这个矩阵的乘积来得到输出结果。
而反卷积层则会计算输入与转置 (Transpose) 后的矩阵的乘积得到输出结果:
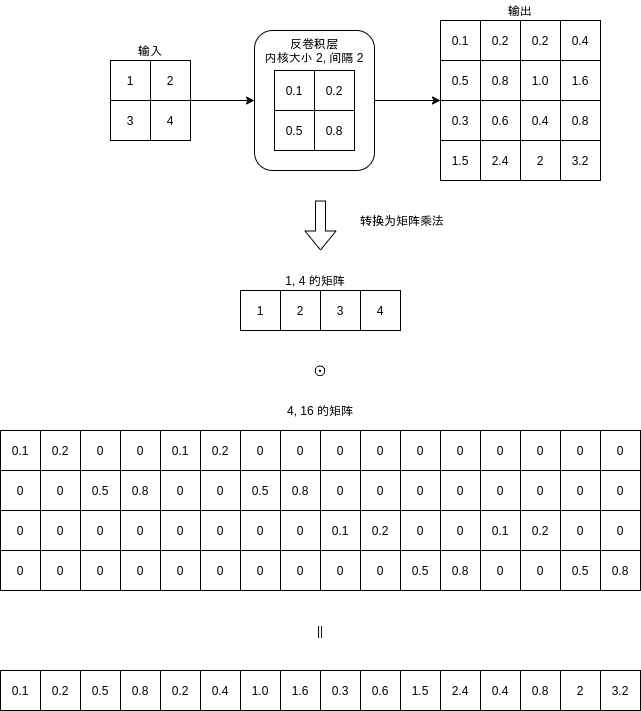
可以看到卷积层与反卷积层的区别只在于是否转置计算使用的矩阵。此外,通道数量转换的计算方式也是一样的。
测试反卷积层的代码如下:
>>> import torch
# 生成测试用的矩阵
# 第一个维度代表批次,第二个维度代表通道数量,第三个维度代表长度,第四个维度代表宽度
>>> a = torch.arange(1, 5).float().reshape(1, 1, 2, 2)
>>> a
tensor([[[[1., 2.],
[3., 4.]]]])
# 创建反卷积层
>>> convtranspose2d = torch.nn.ConvTranspose2d(1, 1, kernel_size=2, stride=2, bias=False)
# 手动指定权重 (让计算更好理解)
>>> convtranspose2d.weight = torch.nn.Parameter(torch.tensor([0.1, 0.2, 0.5, 0.8]).reshape(1, 1, 2, 2))
>>> convtranspose2d.weight
Parameter containing:
tensor([[[[0.1000, 0.2000],
[0.5000, 0.8000]]]], requires_grad=True)
# 测试反卷积层
>>> convtranspose2d(a)
tensor([[[[0.1000, 0.2000, 0.2000, 0.4000],
[0.5000, 0.8000, 1.0000, 1.6000],
[0.3000, 0.6000, 0.4000, 0.8000],
[1.5000, 2.4000, 2.0000, 3.2000]]]],
grad_fn=<SlowConvTranspose2DBackward>)
需要注意的是,不一定存在一个反卷积层可以把卷积层的输出还原到输入,这是因为卷积层的计算是不可逆的,即使存在一个可以把输出还原到输入的矩阵,这个矩阵也不一定有一个等效的反卷积层的内核参数。
生成器的实现 (Generator)
接下来我们看一下生成器的定义,原始介绍 GAN 的论文给出了生成 64x64 图片的网络,而这里给出的是生成 80x80 图片的网络,其实区别只在于一开始的输出通道数量 (论文是 4, 这里是 5)
class GenerationModel(nn.Module):
"""生成虚假数据的模型"""
# 编码长度
EmbeddedSize = 128
def __init__(self):
super().__init__()
self.generator = nn.Sequential(
# 128,1,1 => 512,5,5
nn.ConvTranspose2d(128, 512, kernel_size=5, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
# => 256,10,10
nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
# => 128,20,20
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# => 64,40,40
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# => 3,80,80
nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1, bias=False),
# 限制输出在 -1 ~ 1,不使用 Hardtanh 是为了让超过范围的值可以传播给上层
nn.Tanh())
def forward(self, x):
y = self.generator(x.view(x.shape[0], x.shape[1], 1, 1))
return y
表现如下:

其中批次正规化 (BatchNorm) 用于控制参数值范围,防止层数过多 (后面会结合识别器训练) 导致梯度爆炸问题。
还有一个要点是生成器输出的范围会在 -1 ~ 1,也就是使用 -1 ~ 1 代表 0 ~ 255 的颜色值,这跟我们之前处理图片的时候把值除以 255 使得范围在 0 ~ 1 不一样。使用 -1 ~ 1 可以提升输出颜色的精度 (减少浮点数的精度损失)。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 125
- 统信桌面专业版【全盘安装UOS系统】介绍 120
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 112
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
