写给程序员的机器学习入门 (三) - 线性模型,激活函数与多层线性模型(二)
多层线性模型
接下来我们看看怎样在 pytorch 里面定义多层线性模型,上一节已经介绍过 torch.nn.Linear 是 pytorch 中单层线性模型的封装,组合多个 torch.nn.Linear 就可以实现多层线性模型。
组合 torch.nn.Linear 有两种方法,一种创建一个自定义的模型类,关于模型类在上一篇已经介绍过:
# 引用 pytorch,nn 等同于 torch.nn
import torch
from torch import nn
# 定义模型
class MyModel(nn.Module):
def __init__(self):
# 初始化基类
super().__init__()
# 定义参数
# 这里一共定义了三层
# 第一层接收 2 个输入,返回 32 个隐藏值 (内部 weight 矩阵为 32 行 2 列)
# 第二层接收 32 个隐藏值,返回 64 个隐藏值 (内部 weight 矩阵为 64 行 32 列)
# 第三层接收 64 个隐藏值,返回 1 个输出 (内部 weight 矩阵为 1 行 64 列)
self.layer1 = nn.Linear(in_features=2, out_features=32)
self.layer2 = nn.Linear(in_features=32, out_features=64)
self.layer3 = nn.Linear(in_features=64, out_features=1)
def forward(self, x):
# x 是一个矩阵,行数代表批次,列数代表输入个数,例如有 50 个批次则为 50 行 2 列
# 计算第一层返回的隐藏值,例如有 50 个批次则 hidden1 为 50 行 32 列
# 计算矩阵乘法时会转置 layer1 内部的 weight 矩阵,50 行 2 列乘以 2 行 32 列等于 50 行 32 列
hidden1 = nn.functional.relu(self.layer1(x))
# 计算第二层返回的隐藏值,例如有 50 个批次则 hidden2 为 50 行 64 列
hidden2 = nn.functional.relu(self.layer2(hidden1))
# 计算第三层返回的输出,例如有 50 个批次则 y 为 50 行 1 列
y = self.layer3(hidden2)
# 返回输出
return y
# 创建模型实例
model = MyModel()
我们可以定义任意数量的层,但每一层的接收值个数 (in_features) 必须等于上一层的返回值个数 (out_features),第一层的接收值个数需要等于输入个数,最后一层的返回值个数需要等于输出个数。
第二种方法是使用 torch.nn.Sequential,这种方法更简便:
# 引用 pytorch,nn 等同于 torch.nn
import torch
from torch import nn
# 创建模型实例,效果等同于第一种方法
model = nn.Sequential(
nn.Linear(in_features=2, out_features=32),
nn.ReLU(),
nn.Linear(in_features=32, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=1))
# 注:
# nn.functional.relu(x) 等于 nn.ReLU()(x)
如前面所说的,层数越多隐藏值数量越多模型就越强大,但需要更长的训练时间并且更容易发生过拟合问题,实际操作时我们可以选择一个比较小的模型,再按需要增加层数和隐藏值个数。
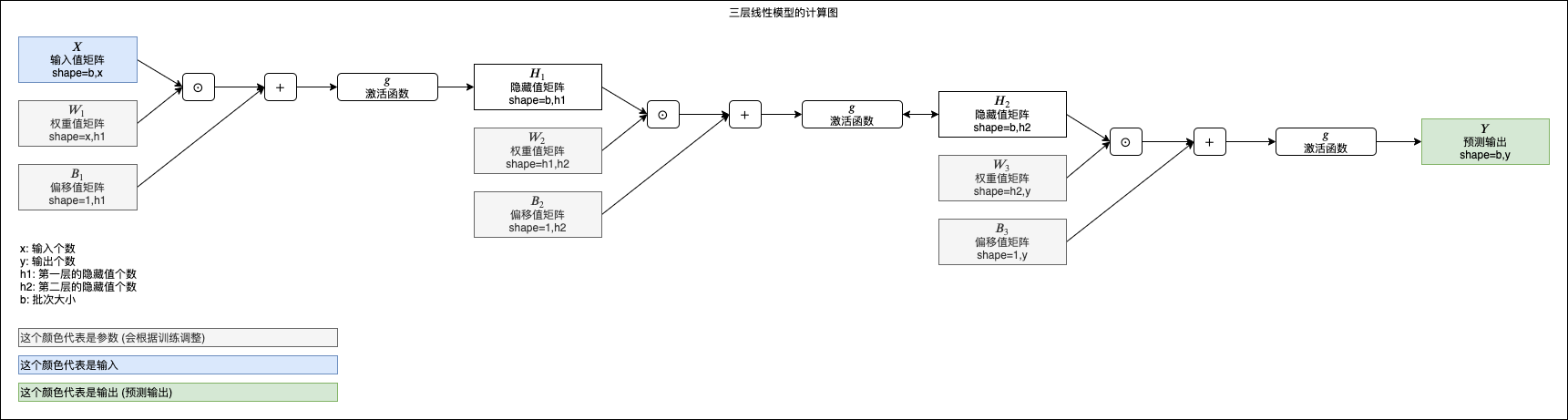
三层线性模型的计算图可以表现如下,以后这个系列在讲解其他模型的时候也会使用相同形式的图表表示模型的计算路径:
实例 - 根据码农条件求工资
我们已经了解到如何创建多层线性模型,现在可以试试解决比较实际的问题了,对于大部分码农来说最实际的问题就是每个月能拿多少工资😿,那就来建立一个根据码农的条件,预测可以拿到多少工资的模型吧。
以下是从某个地方秘密收集回来的码农条件和工资数据(其实是按某种规律随机生成出来的,不是实际数据🙀):
年龄,性别,工作经验,Java,NET,JS,CSS,HTML,工资
29,0,0,1,2,2,1,4,12500
22,0,2,2,3,1,2,5,15500
24,0,4,1,2,1,1,2,16000
35,0,6,3,3,0,1,0,19500
45,0,18,0,5,2,0,5,17000
24,0,2,0,0,0,1,1,13500
23,1,2,2,3,1,1,0,10500
41,0,16,2,5,5,2,0,16500
50,0,18,0,5,0,5,2,16500
20,0,0,0,5,2,0,1,12500
26,0,6,1,5,5,1,1,27000
46,0,12,0,5,4,4,2,12500
26,0,6,1,5,3,1,1,23500
40,0,9,0,0,1,0,1,17500
41,0,20,3,5,3,3,5,20500
26,0,4,0,1,2,4,0,18500
42,0,18,5,0,0,2,5,18500
21,0,1,1,0,1,2,0,12000
26,0,1,0,0,0,0,2,12500
完整数据有 50000 条,可以从 https://github.com/303248153/BlogArchive/tree/master/ml-03/salary.csv 下载。
每个码农有以下条件:
- 年龄
- 性别 (0: 男性, 1: 女性)
- 工作经验年数 (仅限互联网行业)
- Java 编码熟练程度 (0 ~ 5)
- NET 编码熟练程度 (0 ~ 5)
- JS 编码熟练程度 (0 ~ 5)
- CSS 编码熟练程度 (0 ~ 5)
- HTML 编码熟练程度 (0 ~ 5)
也就是有 8 个输入,1 个输出 (工资),我们可以建立三层线性模型:
- 第一层接收 8 个输入返回 100 个隐藏值
- 第二层接收 100 个隐藏值返回 50 个隐藏值
- 第三层接收 50 个隐藏值返回 1 个输出
写成代码如下 (这里使用了 pandas 类库读取 csv,使用 pip3 install pandas 即可安装):
# 引用 pytorch 和 pandas
import pandas
import torch
from torch import nn
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=100)
self.layer2 = nn.Linear(in_features=100, out_features=50)
self.layer3 = nn.Linear(in_features=50, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
# 给随机数生成器分配一个初始值,使得每次运行都可以生成相同的随机数
# 这是为了让训练过程可重现,你也可以选择不这样做
torch.random.manual_seed(0)
# 创建模型实例
model = MyModel()
# 创建损失计算器
loss_function = torch.nn.MSELoss()
# 创建参数调整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.0000001)
# 从 csv 读取原始数据集
df = pandas.read_csv('salary.csv')
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 切分训练集 (60%),验证集 (20%) 和测试集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_tensor[traning_indices][:,:-1]
traning_set_y = dataset_tensor[traning_indices][:,-1:]
validating_set_x = dataset_tensor[validating_indices][:,:-1]
validating_set_y = dataset_tensor[validating_indices][:,-1:]
testing_set_x = dataset_tensor[testing_indices][:,:-1]
testing_set_y = dataset_tensor[testing_indices][:,-1:]
# 开始训练过程
for epoch in range(1, 1000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
# 切换模型到训练模式,将会启用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.train()
for batch in range(0, traning_set_x.shape[0], 100):
# 切分批次,一次只计算 100 组数据
batch_x = traning_set_x[batch:batch+100]
batch_y = traning_set_y[batch:batch+100]
# 计算预测值
predicted = model(batch_x)
# 计算损失
loss = loss_function(predicted, batch_y)
# 从损失自动微分求导函数值
loss.backward()
# 使用参数调整器调整参数
optimizer.step()
# 清空导函数值
optimizer.zero_grad()
# 检查验证集
# 切换模型到验证模式,将会禁用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.eval()
predicted = model(validating_set_x)
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).mean()
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
print(f"validating accuracy: {validating_accuracy}")
# 检查测试集
predicted = model(testing_set_x)
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
# 手动输入数据预测输出
while True:
try:
print("enter input:")
r = list(map(float, input().split(",")))
x = torch.tensor(r).view(1, len(r))
print(model(x)[0,0].item())
except Exception as e:
print("error:", e)
输出如下,可以看到最后没有参与训练的验证集的正确度达到了 93.3% 测试集的正确度达到了 93.1%,模型成功的摸索出了某种规律:
epoch: 1
validating x: tensor([[42., 0., 16., ..., 5., 5., 5.],
[28., 0., 0., ..., 4., 0., 0.],
[23., 0., 3., ..., 0., 1., 1.],
...,
[44., 1., 15., ..., 2., 0., 2.],
[30., 0., 1., ..., 1., 1., 2.],
[50., 1., 18., ..., 5., 5., 2.]]), y: tensor([[24500.],
[12500.],
[17500.],
...,
[10500.],
[15000.],
[16000.]]), predicted: tensor([[27604.2578],
[15934.7607],
[14536.8984],
...,
[23678.5547],
[18189.6953],
[29968.8789]], grad_fn=<AddmmBackward>)
validating accuracy: 0.661293625831604
epoch: 2
validating x: tensor([[42., 0., 16., ..., 5., 5., 5.],
[28., 0., 0., ..., 4., 0., 0.],
[23., 0., 3., ..., 0., 1., 1.],
...,
[44., 1., 15., ..., 2., 0., 2.],
[30., 0., 1., ..., 1., 1., 2.],
[50., 1., 18., ..., 5., 5., 2.]]), y: tensor([[24500.],
[12500.],
[17500.],
...,
[10500.],
[15000.],
[16000.]]), predicted: tensor([[29718.2441],
[15790.3799],
[15312.5791],
...,
[23395.9668],
[18672.0234],
[31012.4062]], grad_fn=<AddmmBackward>)
validating accuracy: 0.6694601774215698
省略途中输出
epoch: 999
validating x: tensor([[42., 0., 16., ..., 5., 5., 5.],
[28., 0., 0., ..., 4., 0., 0.],
[23., 0., 3., ..., 0., 1., 1.],
...,
[44., 1., 15., ..., 2., 0., 2.],
[30., 0., 1., ..., 1., 1., 2.],
[50., 1., 18., ..., 5., 5., 2.]]), y: tensor([[24500.],
[12500.],
[17500.],
...,
[10500.],
[15000.],
[16000.]]), predicted: tensor([[22978.7656],
[13050.8018],
[18396.5176],
...,
[11449.5059],
[14791.2969],
[16635.2578]], grad_fn=<AddmmBackward>)
validating accuracy: 0.9311849474906921
testing x: tensor([[48., 1., 18., ..., 5., 0., 5.],
[22., 1., 2., ..., 2., 1., 2.],
[24., 0., 1., ..., 3., 2., 0.],
...,
[24., 0., 4., ..., 0., 1., 1.],
[39., 0., 0., ..., 0., 5., 5.],
[36., 0., 5., ..., 3., 0., 3.]]), y: tensor([[14000.],
[10500.],
[13000.],
...,
[15500.],
[12000.],
[19000.]]), predicted: tensor([[15481.9062],
[11011.7266],
[12192.7949],
...,
[16219.3027],
[11074.0420],
[20305.3516]], grad_fn=<AddmmBackward>)
testing accuracy: 0.9330180883407593
enter input:
最后我们手动输入码农条件可以得出预测输出 (35 岁男 10 年经验 Java 5 NET 2 JS 1 CSS 1 HTML 2 大约可拿 26k 😤):
enter input:
35,0,10,5,2,1,1,2
26790.982421875
虽然训练成功了,但以上代码还有几个问题:
- 学习比率设置的非常低 (0.0000001),这是因为我们没有对数据进行正规化处理
- 总是会固定训练 1000 次,不能像第一篇文章提到过的那样自动检测哪一次的正确度最高,没有考虑过拟合问题
- 不能把训练结果保存到硬盘,每次运行都需要从头训练
- 需要把所有数据一次性读取到内存中,数据过多时内存可能不够用
- 没有提供一个使用训练好的模型的接口
这些问题都会在下篇文章一个个解决。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 123
- 统信桌面专业版【全盘安装UOS系统】介绍 117
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 109
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 102
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益208.98元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
