写给程序员的机器学习入门 (五) - 递归模型 RNN,LSTM 与 GRU (一)
了,窗口设置过小可能会导致没有足够的信息用于预测输出,过大则会影响性能。

递归模型 (Recursive Model) 可以用于处理不定长度的输入,用法是一次只传固定数量的输入给模型,可以分多次传,传的次数根据数据而定。以上述例子来说,“这部片非常好看” 每次传一个字需要传 7 次,“这部片很无聊” 每次传一个字需要传 6 次。而递归模型每收到一次输入都会返回一次输出,有的场景只会使用最后一次输出的结果 (例如这个例子),而有的场景则会使用每一次输出的结果。
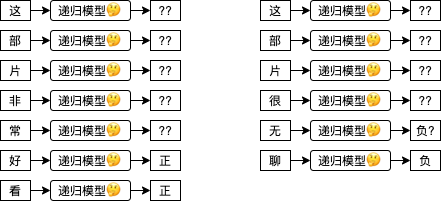
换成代码可以这样理解:
model = MyRecursiveModel()
model('这')
model('部')
model('片')
model('非')
model('常')
model('好')
last_output = model('看')
print(last_output)
接下来我们看看几个经典的递归模型是怎么实现的。
最简单的递归模型 - RNN (tanh)
RNN tanh (Recurrent Neural Network - tanh) 是最简单的递归模型,计算公式如下,数学不好的第一印象可能会觉得妈呀一看数学公式就头昏脑胀了🙀,我们先一个个参数来分析,H 是递归模型内部记录的一个隐藏值矩阵,Ht 代表当前时序的值,而 H(t-1) 代表前一个时序的值,t 可以置换到具体的数字,例如 Ht0 代表隐藏值矩阵最开始的状态 (一般会使用 0 初始化),Ht1 代表隐藏值矩阵第一次更新以后的状态,Ht2 代笔隐藏值矩阵第二次更新以后的状态,计算 Ht1 时 H(t-1) 代表 Ht0,计算 Ht2 时 H(t-1) 代表 Ht1;Wx 是针对输入的权重值,Bx 是针对输入的偏移值,Wh 是针对隐藏的权重值,Bh 是针对隐藏的偏移值;tanh 用于把实数转换为 -1 ~ 1 之间的范围。这个公式和之前我们看到的人工神经元很相似,只是把每一次的输入和当前隐藏值经过计算后的值加在一起,然后使用 tanh 作为激活函数生成新的隐藏值,隐藏值会当作每一次的输出使用。
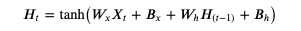
如果你觉得文本难以理解,可以看展开以后的公式:
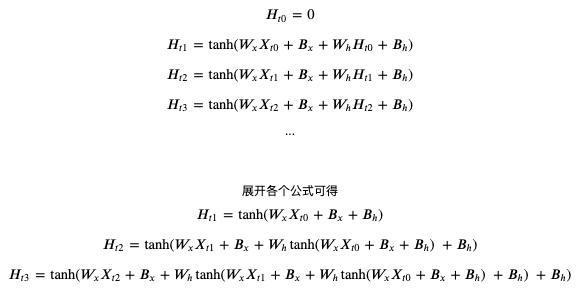
可以看到每次的输出结果都会根据之前的输入计算,tanh 用于非线性过滤和控制值范围在 -1 ~ 1 之间。
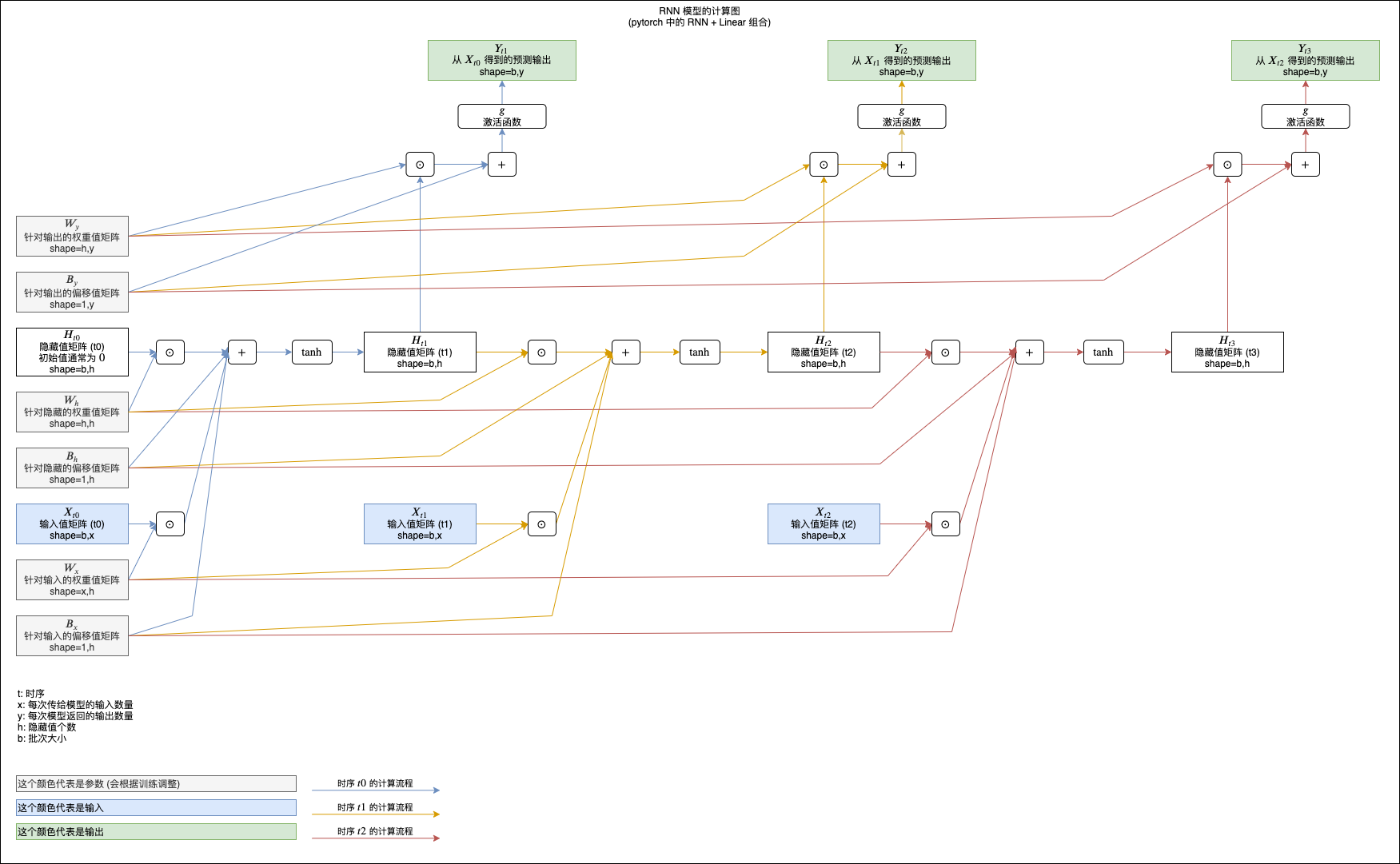
你也可以参考下面的计算图来理解,图中展示了 RNN tanh 模型如何计算三次输入和返回三次输出 (注意最后加了一层额外的线性模型用于把 RNN 返回的隐藏值转换为预测输出):
(看不清请在新标签单独打开图片,或者另存为到本地以后查看)
在 pytorch 中使用 RNN
因为递归模型支持不定长度的数据,而 pytorch 围绕 tensor 来进行运算,tensor 的维度又是固定的,要在 pytorch 中使用递归模型需要很繁琐的处理,下图说明了处理的整个流程:
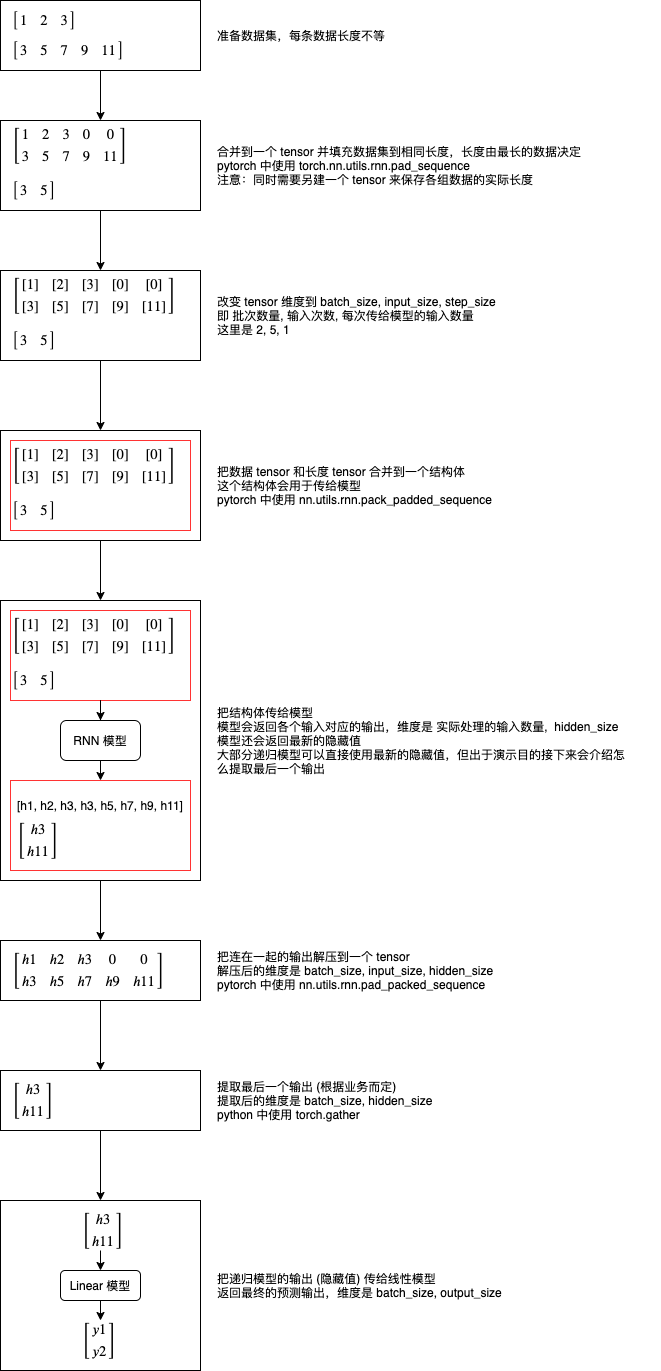
我们再来看看怎样在代码里面实现这个流程:
# 引用 pytorch 类库
>>> import torch
# 准备数据集
>>> data1 = torch.tensor([1, 2, 3], dtype=torch.float)
>>> data2 = torch.tensor([3, 5, 7, 9, 11], dtype=torch.float)
>>> datalist = [data1, data2]
# 合并到一个 tensor 并填充数据集到相同长度
# 这里使用 batch_first 指定第一维度为批次数量
>>> padded = torch.nn.utils.rnn.pad_sequence(datalist, batch_first=True)
>>> padded
tensor([[ 1., 2., 3., 0., 0.],
[ 3., 5., 7., 9., 11.]])
# 另建一个 tensor 来保存各组数据的实际长度
>>> lengths = torch.tensor([len(x) for x in datalist])
>>> lengths
tensor([3, 5])
# 建立 RNN 模型,每次接收 1 个输入,内部拥有 8 个隐藏值 (每次都会返回 8 个最新的隐藏值)
# 指定 num_layers 可以在内部叠加 RNN 模型,这里不叠加所以只指定 1
>>> rnn_model = torch.nn.RNN(input_size = 1, hidden_size = 8, num_layers = 1, batch_first = True)
# 建立 Linear 模型,每次接收 8 个输入 (RNN 模型返回的隐藏值),返回 1 个输出
>>> linear_model = torch.nn.Linear(in_features = 8, out_features = 1)
# 改变 tensor 维度到 batch_size, input_size, step_size
# 即 批次数量, 输入次数, 每次传给模型的输入数量
>>> x = padded.reshape(padded.shape[0], padded.shape[1], 1)
>>> x
tensor([[[ 1.],
[ 2.],
[ 3.],
[ 0.],
[ 0.]],
[[ 3.],
[ 5.],
[ 7.],
[ 9.],
[11.]]])
# 把数据 tensor 和长度 tensor 合并到一个结构体
# 这样做的意义是可以避免 RNN 计算填充的那些 0
# enforce_sorted 表示数据事先没有排序过,如果不指定这个选项会出错
>>> packed = torch.nn.utils.rnn.pack_padded_sequence(x, lengths, batch_first=True, enforce_sorted=False)
>>> packed
PackedSequence(data=tensor([[ 3.],
[ 1.],
[ 5.],
[ 2.],
[ 7.],
[ 3.],
[ 9.],
[11.]]), batch_sizes=tensor([2, 2, 2, 1, 1]), sorted_indices=tensor([1, 0]), unsorted_indices=tensor([1, 0]))
# 把结构体传给模型
# 模型会返回各个输入对应的输出,维度是 实际处理的输入数量, hidden_size
# 模型还会返回最新的隐藏值
>>> output, hidden = rnn_model(packed)
>>> output
PackedSequence(data=tensor([[-0.3055, 0.2916, 0.2736, -0.0502, -0.4033, -0.1438, -0.6981, 0.6284],
[-0.2343, 0.2279, 0.0595, 0.1867, -0.2527, -0.0518, -0.1913, 0.5276],
[-0.0556, 0.2870, 0.3035, -0.3519, -0.4015, 0.1584, -0.9157, 0.6472],
[-0.1488, 0.2706, 0.1115, -0.0131, -0.2350, 0.1252, -0.4981, 0.5706],
[-0.0179, 0.1201, 0.4751, -0.5256, -0.3701, 0.1289, -0.9834, 0.7087],
[-0.1094, 0.1283, 0.1698, -0.1136, -0.1999, 0.1847, -0.7394, 0.5756],
[ 0.0426, 0.1866, 0.5581, -0.6716, -0.4857, 0.0039, -0.9964, 0.7603],
[ 0.0931, 0.2418, 0.6602, -0.7674, -0.6003, -0.0989, -0.9991, 0.8172]],
grad_fn=<CatBackward>), batch_sizes=tensor([2, 2, 2, 1, 1]), sorted_indices=tensor([1, 0]), unsorted_indices=tensor([1, 0]))
>>> hidden
tensor([[[-0.1094, 0.1283, 0.1698, -0.1136, -0.1999, 0.1847, -0.7394,
0.5756],
[ 0.0931, 0.2418, 0.6602, -0.7674, -0.6003, -0.0989, -0.9991,
0.8172]]], grad_fn=<IndexSelectBackward>)
# 把连在一起的输出解压到一个 tensor
# 解压后的维度是 batch_size, input_size, hidden_size
# 注意第二个返回值是各组输出的实际长度,等于之前的 lengths,所以我们不需要
>>> unpacked, _ = torch.nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
>>> unpacked
tensor([[[-0.2343, 0.2279, 0.0595, 0.1867, -0.2527, -0.0518, -0.1913,
0.5276],
[-0.1488, 0.2706, 0.1115, -0.0131, -0.2350, 0.1252, -0.4981,
0.5706],
[-0.1094, 0.1283, 0.1698, -0.1136, -0.1999, 0.1847, -0.7394,
0.5756],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000]],
[[-0.3055, 0.2916, 0.2736, -0.0502, -0.4033, -0.1438, -0.6981,
0.6284],
[-0.0556, 0.2870, 0.3035, -0.3519, -0.4015, 0.1584, -0.9157,
0.6472],
[-0.0179, 0.1201, 0.4751, -0.5256, -0.3701, 0.1289, -0.9834,
0.7087],
[ 0.0426, 0.1866, 0.5581, -0.6716, -0.4857, 0.0039, -0.9964,
0.7603],
[ 0.0931, 0.2418, 0.6602, -0.7674, -0.6003, -0.0989, -0.9991,
0.8172]]], grad_fn=<IndexSelectBackward>)
# 提取最后一个输出 (根据业务而定)
# 提取后的维度是 batch_size, hidden_size
# 可以看到使用 RNN tanh 时最后一个输出的值等于之前返回的 hidden
>>> last_hidden = unpacked.gather(1, (lengths - 1).reshape(-1, 1, 1).repeat(1, 1, unpacked.shape[2]))
>>> last_hidden
tensor([[[-0.1094, 0.1283, 0.1698, -0.1136, -0.1999, 0.1847, -0.7394,
0.5756]],
[[ 0.0931, 0.2418, 0.6602, -0.7674, -0.6003, -0.0989, -0.9991,
0.8172]]], grad_fn=<GatherBackward>)
# 把 RNN 模型返回的隐藏值传给 Linear 模型,得出预测输出
>>> predicted = linear_model(last_hidden)
>>> predicted
tensor([[[0.1553]],
[[0.1431]]], grad_fn=<AddBackward0>)
之后根据实际输出计算误差,然后根据自动微分调整参数即可进行训练。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 123
- 统信桌面专业版【全盘安装UOS系统】介绍 117
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 109
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 102
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益208.98元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
