写给程序员的机器学习入门 (一) - 从基础说起(一)
机器学习的本质
在讲解具体的例子与模型之前,我们先来了解一下什么是机器学习。在业务中我们有很多需要解决的问题,例如用户提交订单时如何根据商品列表计算订单金额,用户搜索商品时如何根据商品关键字得出商品搜索结果,用户查看商品一览时如何根据用户已买商品计算商品推荐列表,这些问题都可以分为 输入,操作,输出,如下图所示:
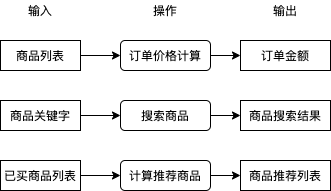
其中操作部分我们通常会直接编写程序代码实现,程序代码会查询数据库,使用某种算法处理数据等,这些工作可能很枯燥,一些程序员受不了了就会自称码农,因为日复一日编写这些逻辑就像种田一样艰苦和缺乏新意。你有没有想过如果有一套系统,可以只给出一些输入和输出的例子就能自动实现操作中的逻辑?如果有这么一套系统,在处理很多问题的时候就可以不需要考虑使用什么逻辑从输入转换到输出,我们只需提供一些例子这套系统就可以自动帮我们实现。
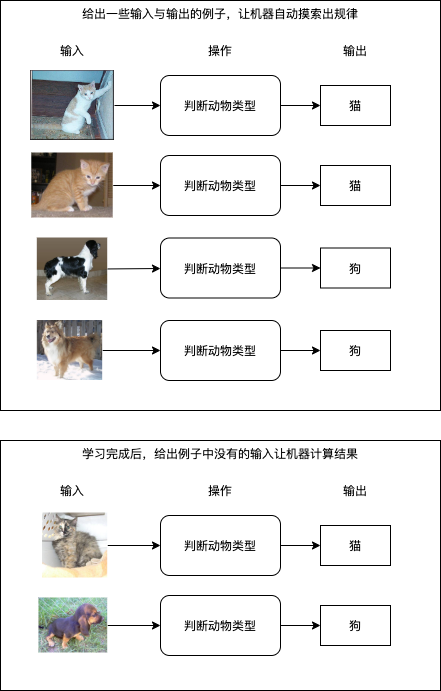
好消息是这样的系统是存在的,我们给出一些输入与输出的例子,让机器自动摸索出它们之间的规律并且建立一套转换它们的逻辑,就是所谓的机器学习。目前机器学习可以做到从图片识别出物体类别,从图片识别出文字,从文本识别出大概含义,也可以做到上图中的从已买商品列表计算出推荐商品列表,这些操作都不需要编写具体逻辑,只需要准备一定的例子让机器自己学习即可,如果成功摸索出规律,机器在遇到例子中没有的输入时也可以正确的计算出输出结果,如下图所示:
可惜的是机器学习不是万能的,我们不能指望机器可以学习到所有规律从而实现所有操作,机器学习的界限主要有:
- 做不到 100% 的精度,例如前述的根据商品列表计算订单价格要求非常准确,我们不能用机器学习来实现这个操作
- 需要一定的数据量,如果例子较少则无法成功学习到规律
- 无法实现复杂的判断,机器学习与人脑之间仍然有相当大的差距,一些复杂的操作无法使用机器学习代替
到这里我们应该对机器学习是什么有了一个大概的印象,如何根据输入与输出摸索出规律就是机器学习最主要的命题,接下来我们会更详细分析机器学习的流程与步骤。需要注意的是,不是所有场景都可以明确的给出输入与输出的例子,可以明确给出例子的学习称为有监督学习 (supervised learning),而只给出输入不给出输出例子的学习称为无监督学习 (unsupervised learning),无监督学习通常用于实现数据分类,虽然不给出输出但是会按一定的规律控制学习的过程,因为无监督学习应用范围不广,这个系列讲的基本上都是有监督学习。
机器学习的流程与步骤
我们先来了解一下机器学习的流程:
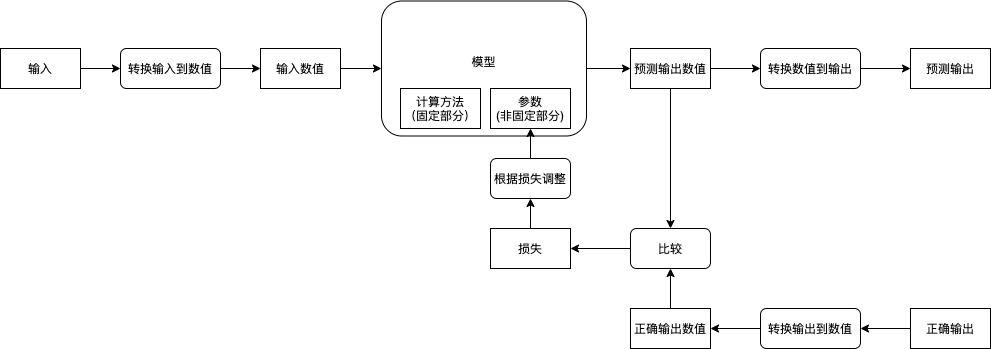
而实现机器学习需要以下的步骤:
- 收集输入与输出的例子
- 建立模型
- 确定输入输出与模型可接收返回的数值之间如何转换
- 使用输入与输出的例子调整模型的参数
- 使用没有参与训练的输入与输出评价模型是否成功摸索出规律
收集输入与输出的例子
在开始机器学习之前我们需要先收集输入与输出的例子,收集到的例子又称数据集 (Dataset),收集工作一般是个苦力活,例如学习从图片判断物体类别需要收集一堆图片并手动对它们进行分类,学习从图片识别文字需要收集一堆图片并手动记录图片对应的文本,这样的工作通常称为打标签 (Labeling),标签 (Label) 就相当于这个数据对应的输出结果。有些时候我们也可以偷懒,例如实现验证码识别的时候我们可以反过来根据文本生成图片,然后把图片当作输入文本当作输出,再例如实现商品推荐的时候我们可以把用户购买过的商品分割成两部分,一部分作为已购买商品 (输入),另一部分作为推荐商品 (输出)。注意输入与输出可以有多个,例如视频网站可以根据用户的年龄,性别,所在地 (3 个输入) 来判断用户喜欢看的视频类型 (1 个输出),再例如自动驾驶系统可以根据视频输入,雷达输入与地图路线 (3 个输入) 计算汽车速度与方向盘角度 (2 个输出),后面会介绍如何处理多个输入与输出,包括数量可变的输入。
如果你只是想试试手而不是解决实际的业务问题,可以直接用别人收集好的数据集,以下是包含了各种公开数据集链接的 Github 仓库:
https://github.com/awesomedata/awesome-public-datasets
建立模型
用于让机器学习与实现操作的就是模型 (Model),模型可以分为两部分,第一部分是计算方法,这部分需要我们来决定并且不会在学习过程中改变;第二部分是参数,这部分会随着学习不断调整,最终实现我们想要的操作。模型的计算方法需要根据业务(输入与输出的类型)来决定,例如分类可以使用多层线性模型,图像识别可以使用 CNN 模型,趋势预测可以使用 RNN 模型,文本翻译可以使用 Transformer 模型,对象识别可以使用 R-CNN 模型等 (这些模型会在后续的章节详细介绍),通常我们可以直接用别人设计好的模型再加上一些细微调整(只会做这种工作的也叫调参狗😊,我们的第一个小目标),而一些复杂的业务需要自己设计模型,这是真正难的地方。你可能会想是否有一种模型可以适用于所有类型的业务,遗憾的是目前并没有,如果有那就是真正的人工智能了。
因为篇幅限制,现实使用的模型会在后面的文章中介绍,请参考本文末尾的预告。
确定输入输出与模型可接收返回的数值之间如何转换
在机器学习中,模型只会接受和返回数值 (通常使用多维数组,即矩阵),所以我们还需要决定输入输出与数值之间如何转换,例如输入是图片时,我们可以把每个像素的红绿蓝值与图片大小一起组成一个三维数组(红绿蓝 * 图片宽度 * 图片高度),再例如输入是数据库中的商品时,我们可以先根据总商品大小创建一个一维数组,然后用数组 1, 0, 0, ... 代表第一个商品,数组 0, 1, 0, ... 代表第二个商品,数组 0, 0, 1, ... 代表第三个商品,把数值转换到输出也一样,将对应关系反过来就行了。注意转换方式也是一个比较重要的部分,使用正确的转换方式可以让机器学习事半功倍,而使用错误的转换方式可能导致学习缓慢或学习失败。
为了提升学习速度,我们通常会一次性的给模型传入多组输入并让模型返回多组输出,传入的多组输入也叫批次 (Batch),例如准备了 10000 组输入与输出,每次给模型传入 50 组,那么批次大小就是 50,需要分 2000 个批次传入。分批次会让输入与输出的数组维度加一,例如一次性传 50 张宽 30 x 高 20 的图片时,需要把这些图片转换为一个 50 x 3 x 30 x 20 的四维数组,再例如传 50 个商品时,需要把这些商品转换为一个 50 x 商品数量的二维数组。你可能会有疑问为什么不能一次性把所有输入传给模型,如果输入输出数量过大(有的数据集会有上百万组数据),那么计算机不会有足够的内存处理它们;另一个原因是分批次传入可以防止过拟合 (Overfitting),但本篇不会详细介绍这点。惯例上,我们通常会选择 32 ~ 100 为批次大小。
此外,为了提升学习效果我们还可以选择把数值正规化 (Normalization),例如一个输入数值的取值范围在 0 ~ 10 的时候,我们可以把数值全部除以 10,用 0 代表最小的值,用 1 代表最大的值,这个手法可以改善模型的学习速度与提升最终的效果。因为理解需要一定的数学知识,本篇不会详细介绍为什么。
使用输入与输出的例子调整模型的参数
接下来我们就可以开始学习了,首先我们会给模型的参数 (非固定部分) 随机赋值,然后给模型传入预先准备好的输入,然后模型返回预测的输出,第一次因为参数是随机的,返回的预测输出与正确输出可能会差很远,例如传一张狗的图片给模型,模型可能会告诉你这是猪。接下来你需要纠正模型,把预测输出的数值与正确输出的数值通过某种方法得到它们的相差值 (也叫损失 - Loss),然后根据损失来调整模型的参数 (修改参数使得损失接近 0),让下一次模型的预测输出的数值更接近正确输出的数值。如果把事先准备的所有输入 (批次) 都传给了模型,并且根据模型的预测输出与正确输出调整了模型的参数,那么就可以说经过了一轮训练 (1 Epoch),通常我们需要经过好几轮训练才能达到理想的效果。
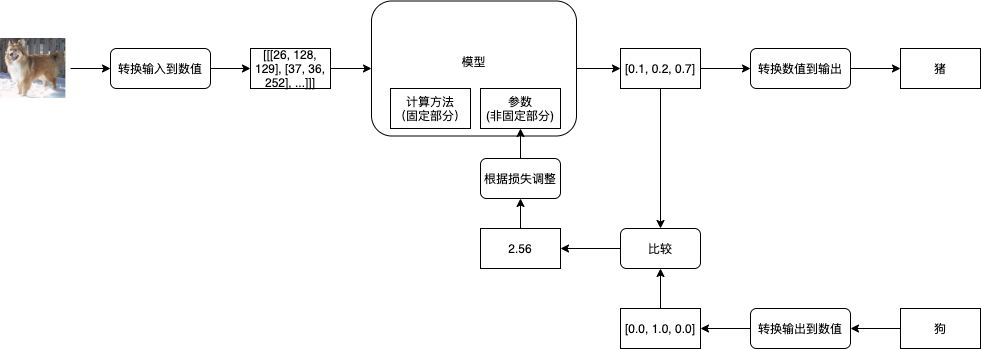
评价模型是否达到理想的效果通常会使用正确率 (Accuracy, 很多文章会缩写成 Acc),例如传入 100 个输入给模型,模型返回的 100 个预测输出中有 99 个与正确输出是一致的,那么正确率就是 99 %。如果模型足够强大,我们可以让模型针对参与训练的输入达到 100 % 的正确率,但这并不能说明模型训练成功,我们还需要使用没有参与训练的输入与输出来评价模型是否成功摸索出规律。如果模型能力不足,或者用了与业务不匹配的模型,那么模型会给出很低的正确率,并且经过再多训练都不会改善,这个时候我们就需要换一个模型了。模型通过训练达到很高的正确率又称收敛 (Converge),我们首先需要确定模型能收敛,再确定模型是否能成功摸索出规律。
使用没有参与训练的输入与输出评价模型是否成功摸索出规律
如果模型针对参与训练的输入达到了很高的正确率,那么就有两种情况,第一种情况是模型成功的摸索出规律了,第二种情况是模型只是把所有参与训练的输入与输出记住。第二种情况非常糟糕,就像我们把试卷的所有问题和答案记住了,但是没有理解为什么,遇到另一张没看过的试卷时就会得出很低的分数,这样的情况又称过拟合 (Overfitting)。
为了判断是否发生过拟合,我们通常会把事先准备好的输入与输出数据集打乱并分为三个集合,分别是训练集 (Training Set),验证集 (Validating Set) 与测试集 (Testing Set),举例来说我们可以把 70 % 的数据划给训练集,15 % 的数据划给验证集,剩余 15 % 的数据划给测试集。训练集中的输入与输出用于传给模型并且调整模型的参数;验证集中的输入与输出不会参与训练,用于在经过每一轮训练后判断模型在遇到未知的输入时可以得出的正确率,如果模型针对训练集可以得出 99 % 的正确率,但针对验证集只能得出 50 % 的正确率,那么就可以判断发生了过拟合;测试集用于在最终训练完成后判断模型是否过度偏向于训练集与验证集中的数据,如果针对测试集都可以得出比较高的正确率,那么就可以说这个模型训练成功了。
因为实际的业务场景中收集到的输入与输出会夹杂一些不完全正确的数据,如果不停的去训练模型,模型为了迎合这些不完全正确的数据会去破坏已经摸索出的规律,导致最终一定发生过拟合。为了防止这种情况我们可以使用提早停止 (Early Stopping) 的手法,在每一轮训练后都计算模型针对训练集与验证集的正确率,然后在验证集正确率最高的时候停止训练,例如:
- 第一轮训练后,训练集正确率 60 %,验证集正确率 58 %
- 第二轮训练后,训练集正确率 79 %,验证集正确率 72 %
- 第三轮训练后,训练集正确率 88 %,验证集正确率 86 %
- 第四轮训练后,训练集正确率 92 %,验证集正确率 85 %
- 第五轮训练后,训练集正确率 99 %,验证集正确率 78 %
我们可以看出应该在第三轮训练后停止训练,在实际操作中我们会记录每一轮训练的正确率与验证集正确率最高时模型的状态,如果验证集正确率经过一定训练次数都没有超过之前的最高值,那么就使用之前记录的模型状态作为结果并停止训练。在停止训练后,我们需要判断验证集正确率的最高值是否达到我们满意的水平,如果没有达到则代表模型不适合或者没有能力应付当前的业务,我们需要修改模型并重新开始训练。
如果验证集正确率的最高值达到我们满意的水平,那么就可以做最后一步了,即用模型判断测试集的正确率,因为测试集完全没有参与过之前的步骤,如果测试集的正确率也达到满意的水平,那么就可以说这个模型训练成功了。但如果测试集的正确率没有达到满意的水平,则代表模型对训练集与验证集有偏向,因为我们在验证集正确率不满意的时候会修改模型,修改后的模型会更偏向于验证集的数据,但这个偏向可能会不适合验证集以外的数据。训练集,验证集与测试集的意义可以总结如下:
- 训练集 (Training Set): 用于训练模型参数
- 验证集 (Validating Set): 用于判断模型是否支持处理没有训练过的输入,并手动调整模型的计算方法
- 测试集 (Testing Set): 用于最终判断模型是否支持处理完全没有参与训练与手动调整模型的输入
一个常见的人为错误是划分这三个集合的时候没有对数据进行打乱,例如有猫狗猪的图片各 1000 张,如果划分集合的时候这些图片是排序好的,那么训练集会只有猫和狗的图片,测试集会只有猪的图片,这样就很难确保训练出来的模型可以正确识别猪了。
从划分数据集到训练成功的流程可以总结如下:
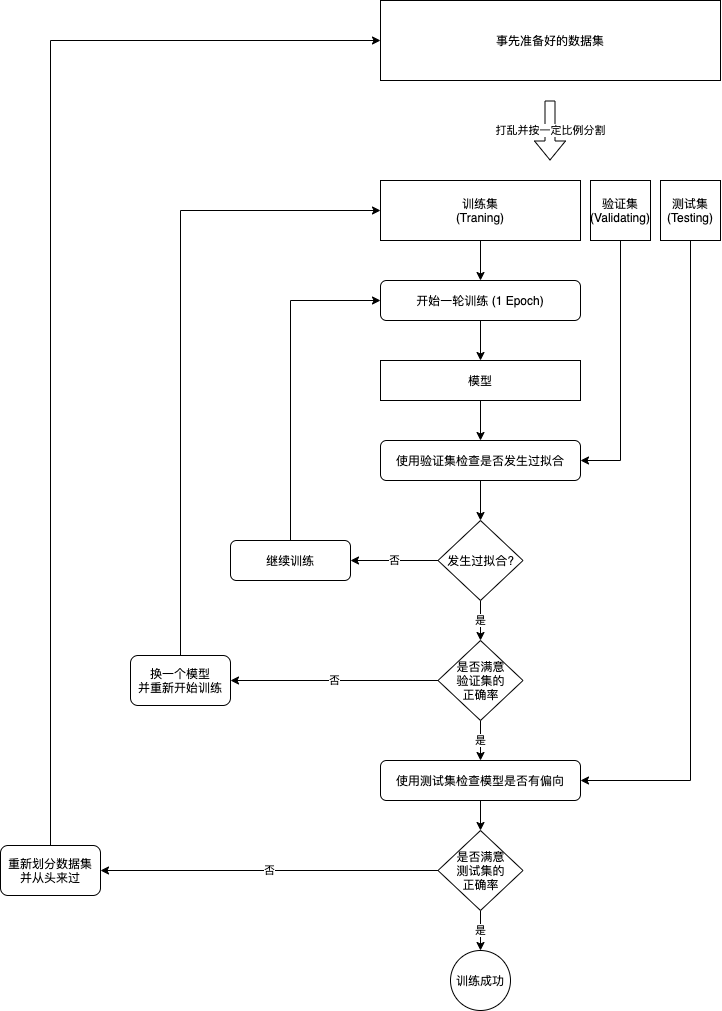
注1: 让模型成功摸索出规律 (针对未知输入得出正确输出) 的工作一般称为泛化 (Generalization)。
注2: 防止过拟合还有另外一些手法,会在接下来的文章中介绍。
机器学习,深度学习与人工智能的区别
对初学者来说一个很常见的问题是,机器学习,深度学习与人工智能有什么区别?如果机器学习的模型非常复杂(经过多层次的计算),那么就可以说是深度学习,如果模型的效果非常好,在某个领域达到或者超过人类的水平,那就可以说是人工智能。但实际上它们都是 PPT 词汇,给👼投资人👶看的时候写人工智能比写机器学习要抢眼多了,就算不满足人工智能的水平很多公司都会宣传为人工智能。这个系列是给在 IT 食物链最底层的程序员看的,所以还是谦虚点叫机器学习吧。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 123
- 统信桌面专业版【全盘安装UOS系统】介绍 116
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 108
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 101
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益217.85元

1843880570 收益214.2元

IT-feng 收益208.98元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
