写给程序员的机器学习入门 (四) - 训练过程中常用的技巧 (一)
保存和读取模型状态
在 pytorch 中各种操作都是围绕 tensor 对象来的,模型的参数也是 tensor,如果我们把训练好的 tensor 保存到硬盘然后下次再从硬盘读取就可以直接使用了。
我们先来看看如何保存单个 tensor,以下代码运行在 python 的 REPL 中:
# 引用 pytorch
>>> import torch
# 新建一个 tensor 对象
>>> a = torch.tensor([1, 2, 3], dtype=torch.float)
# 保存 tensor 到文件 1.pt
>>> torch.save(a, "1.pt")
# 从文件 1.pt 读取 tensor
>>> b = torch.load("1.pt")
>>> b
tensor([1., 2., 3.])
torch.save 保存 tensor 的时候会使用 python 的 pickle 格式,这个格式保证在不同的 python 版本间兼容,但不支持压缩内容,所以如果 tensor 非常大保存的文件将会占用很多空间,我们可以在保存前压缩,读取前解压缩以减少文件大小:
# 引用压缩库
>>> import gzip
# 保存 tensor 到文件 1.pt,保存时使用 gzip 压缩
>>> torch.save(a, gzip.GzipFile("1.pt.gz", "wb"))
# 从文件 1.pt 读取 tensor,读取时使用 gzip 解压缩
>>> b = torch.load(gzip.GzipFile("1.pt.gz", "rb"))
>>> b
tensor([1., 2., 3.])
torch.save 不仅支持保存单个 tensor 对象,还支持保存 tensor 列表或者词典 (实际上它还可以保存 tensor 以外的 python 对象,只要 pickle 格式支持),我们可以调用 state_dict 获取一个包含模型所有参数的集合,再用 torch.save 就可以保存模型的状态:
>>> from torch import nn
>>> class MyModel(nn.Module):
... def __init__(self):
... super().__init__()
... self.layer1 = nn.Linear(in_features=8, out_features=100)
... self.layer2 = nn.Linear(in_features=100, out_features=50)
... self.layer3 = nn.Linear(in_features=50, out_features=1)
... def forward(self, x):
... hidden1 = nn.functional.relu(self.layer1(x))
... hidden2 = nn.functional.relu(self.layer2(hidden1))
... y = self.layer3(hidden2)
... return y
...
>>> model = MyModel()
>>> model.state_dict()
OrderedDict([('layer1.weight', tensor([[ 0.2261, 0.2008, 0.0833, -0.2020, -0.0674, 0.2717, -0.0076, 0.1984],
省略途中输出
0.1347, 0.1356]])), ('layer3.bias', tensor([0.0769]))])
>>> torch.save(model.state_dict(), gzip.GzipFile("model.pt.gz", "wb"))
读取模型状态可以使用 load_state_dict 函数,不过你需要保证模型的参数定义没有发生变化,否则读取会出错:
>>> new_model = MyModel()
>>> new_model.load_state_dict(torch.load(gzip.GzipFile("model.pt.gz", "rb")))
<All keys matched successfully>
一个很重要的细节是,如果你读取模型状态后不是准备继续训练,而是用于预测其他数据,那么你应该调用 eval 函数来禁止自动微分等功能,这样可以加快运算速度:
>>> new_model.eval()
pytorch 不仅支持保存和读取模型状态,还支持保存和读取整个模型包括代码和参数,但我不推荐这种做法,因为使用的时候会看不到模型定义,并且模型依赖的类库或者函数不会一并保存起来所以你还是得预先加载它们否则会出错:
>>> torch.save(model, gzip.GzipFile("model.pt.gz", "wb"))
>>> new_model = torch.load(gzip.GzipFile("model.pt.gz", "rb"))
记录训练集和验证集的正确率变化
我们可以在训练过程中记录训练集和验证集的正确率变化,以观察是否可以收敛,训练速度如何,以及是否发生过拟合问题,以下是代码例子:
# 引用 pytorch 和 pandas 和显示图表使用的 matplotlib
import pandas
import torch
from torch import nn
from matplotlib import pyplot
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=100)
self.layer2 = nn.Linear(in_features=100, out_features=50)
self.layer3 = nn.Linear(in_features=50, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
# 给随机数生成器分配一个初始值,使得每次运行都可以生成相同的随机数
# 这是为了让训练过程可重现,你也可以选择不这样做
torch.random.manual_seed(0)
# 创建模型实例
model = MyModel()
# 创建损失计算器
loss_function = torch.nn.MSELoss()
# 创建参数调整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.0000001)
# 从 csv 读取原始数据集
df = pandas.read_csv('salary.csv')
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 切分训练集 (60%),验证集 (20%) 和测试集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_tensor[traning_indices][:,:-1]
traning_set_y = dataset_tensor[traning_indices][:,-1:]
validating_set_x = dataset_tensor[validating_indices][:,:-1]
validating_set_y = dataset_tensor[validating_indices][:,-1:]
testing_set_x = dataset_tensor[testing_indices][:,:-1]
testing_set_y = dataset_tensor[testing_indices][:,-1:]
# 记录训练集和验证集的正确率变化
traning_accuracy_history = []
validating_accuracy_history = []
# 开始训练过程
for epoch in range(1, 500):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
# 切换模型到训练模式,将会启用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.train()
traning_accuracy_list = []
for batch in range(0, traning_set_x.shape[0], 100):
# 切分批次,一次只计算 100 组数据
batch_x = traning_set_x[batch:batch+100]
batch_y = traning_set_y[batch:batch+100]
# 计算预测值
predicted = model(batch_x)
# 计算损失
loss = loss_function(predicted, batch_y)
# 从损失自动微分求导函数值
loss.backward()
# 使用参数调整器调整参数
optimizer.step()
# 清空导函数值
optimizer.zero_grad()
# 记录这一个批次的正确率,torch.no_grad 代表临时禁用自动微分功能
with torch.no_grad():
traning_accuracy_list.append(1 - ((batch_y - predicted).abs() / batch_y).mean().item())
traning_accuracy = sum(traning_accuracy_list) / len(traning_accuracy_list)
traning_accuracy_history.append(traning_accuracy)
print(f"training accuracy: {traning_accuracy}")
# 检查验证集
# 切换模型到验证模式,将会禁用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.eval()
predicted = model(validating_set_x)
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).mean()
validating_accuracy_history.append(validating_accuracy.item())
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
print(f"validating accuracy: {validating_accuracy}")
# 检查测试集
predicted = model(testing_set_x)
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
# 显示训练集和验证集的正确率变化
pyplot.plot(traning_accuracy_history, label="traning")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
# 手动输入数据预测输出
while True:
try:
print("enter input:")
r = list(map(float, input().split(",")))
x = torch.tensor(r).view(1, len(r))
print(model(x)[0,0].item())
except Exception as e:
print("error:", e)
经过 500 轮训练后会生成以下的图表:
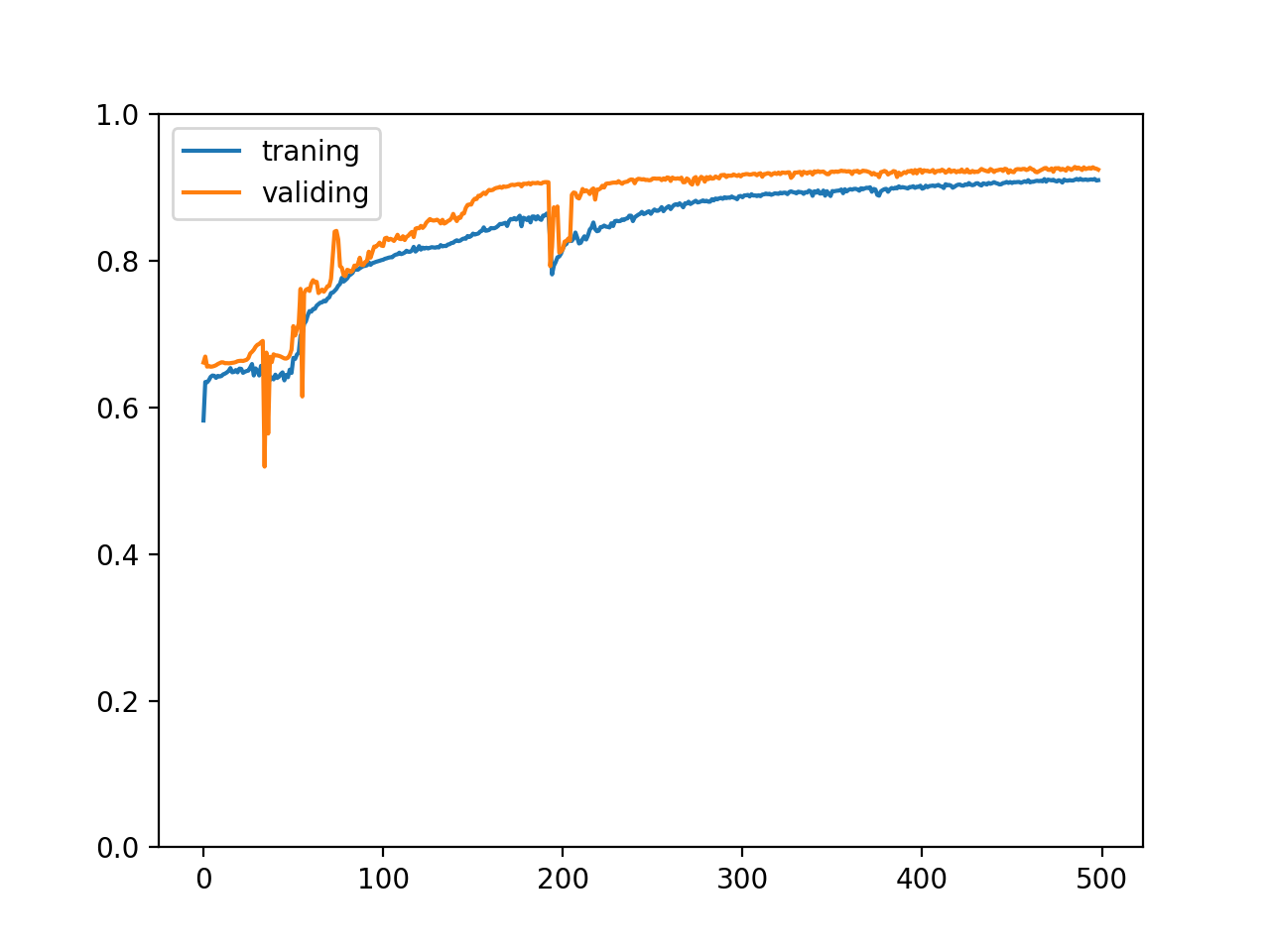
我们可以从图表看到训练集和验证集的正确率都随着训练逐渐上升,并且两个正确率非常接近,这代表训练很成功,模型针对训练集掌握了规律并且可以成功预测没有经过训练的验证集,但实际上我们很难会看到这样的图表,这是因为例子中的数据集是精心构建的并且生成了足够大量的数据。
我们还可能会看到以下类型的图表,分别代表不同的状况:
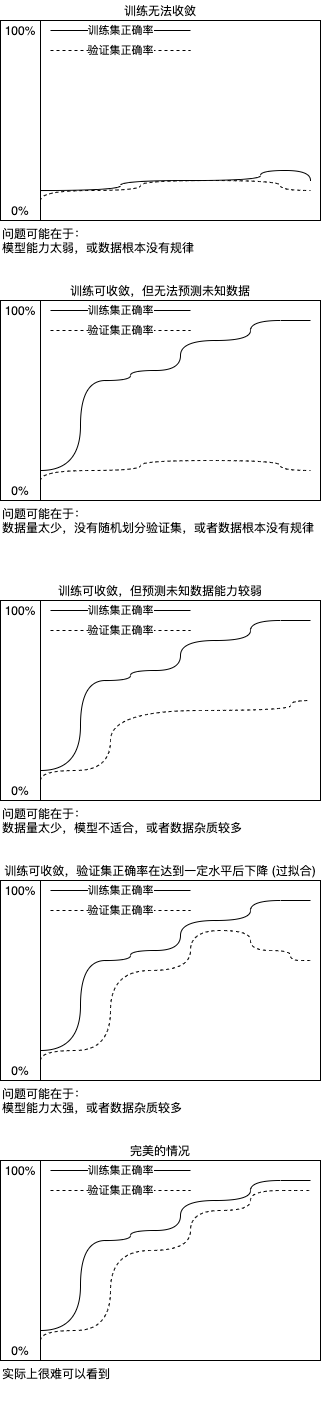
如果有足够的数据,数据遵从某种规律并且杂质较少,划分训练集和验证集的时候分布均匀,并且使用适当的模型,即可达到理想的状况,但实际很难做到😩。通过分析训练集和验证集的正确率变化我们可以定位问题发生在哪里,其中过拟合问题可以用提早停止 (Early Stopping) 的方式解决 (在第一篇文章已经提到过),接下来我们看看如何决定什么时候停止训练。
决定什么时候停止训练
还记得第一篇提到的训练流程吗?我们将会了解如何在代码中实现这个训练流程:

实现判断是否发生过拟合,可以简单的记录历史最高的验证集正确率,如果经过很多次训练都没有刷新最高正确率则结束训练。记录最高正确率的同时我们还需要保存模型的状态,这时模型摸索到了足够多的规律,但是还没有修改参数适应训练集中的杂质,用来预测未知数据可以达到最好的效果。这种手法又称提早停止 (Early Stopping),是机器学习中很常见的手法。
代码实现如下:
# 引用 pytorch 和 pandas 和显示图表使用的 matplotlib
import pandas
import torch
from torch import nn
from matplotlib import pyplot
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=100)
self.layer2 = nn.Linear(in_features=100, out_features=50)
self.layer3 = nn.Linear(in_features=50, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
# 给随机数生成器分配一个初始值,使得每次运行都可以生成相同的随机数
# 这是为了让训练过程可重现,你也可以选择不这样做
torch.random.manual_seed(0)
# 创建模型实例
model = MyModel()
# 创建损失计算器
loss_function = torch.nn.MSELoss()
# 创建参数调整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.0000001)
# 从 csv 读取原始数据集
df = pandas.read_csv('salary.csv')
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 切分训练集 (60%),验证集 (20%) 和测试集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_tensor[traning_indices][:,:-1]
traning_set_y = dataset_tensor[traning_indices][:,-1:]
validating_set_x = dataset_tensor[validating_indices][:,:-1]
validating_set_y = dataset_tensor[validating_indices][:,-1:]
testing_set_x = dataset_tensor[testing_indices][:,:-1]
testing_set_y = dataset_tensor[testing_indices][:,-1:]
# 记录训练集和验证集的正确率变化
traning_accuracy_history = []
validating_accuracy_history = []
# 记录最高的验证集正确率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 开始训练过程
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
# 切换模型到训练模式,将会启用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.train()
traning_accuracy_list = []
for batch in range(0, traning_set_x.shape[0], 100):
# 切分批次,一次只计算 100 组数据
batch_x = traning_set_x[batch:batch+100]
batch_y = traning_set_y[batch:batch+100]
# 计算预测值
predicted = model(batch_x)
# 计算损失
loss = loss_function(predicted, batch_y)
# 从损失自动微分求导函数值
loss.backward()
# 使用参数调整器调整参数
optimizer.step()
# 清空导函数值
optimizer.zero_grad()
# 记录这一个批次的正确率,torch.no_grad 代表临时禁用自动微分功能
with torch.no_grad():
traning_accuracy_list.append(1 - ((batch_y - predicted).abs() / batch_y).mean().item())
traning_accuracy = sum(traning_accuracy_list) / len(traning_accuracy_list)
traning_accuracy_history.append(traning_accuracy)
print(f"training accuracy: {traning_accuracy}")
# 检查验证集
# 切换模型到验证模式,将会禁用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.eval()
predicted = model(validating_set_x)
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).mean()
validating_accuracy_history.append(validating_accuracy.item())
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
print(f"validating accuracy: {validating_accuracy}")
# 记录最高的验证集正确率与当时的模型状态,判断是否在 100 次训练后仍然没有刷新记录
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
torch.save(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 100:
# 在 100 次训练后仍然没有刷新记录,结束训练
print("stop training because highest validating accuracy not updated in 100 epoches")
break
# 使用达到最高正确率时的模型状态
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(torch.load("model.pt"))
# 检查测试集
predicted = model(testing_set_x)
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
# 显示训练集和验证集的正确率变化
pyplot.plot(traning_accuracy_history, label="traning")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
# 手动输入数据预测输出
while True:
try:
print("enter input:")
r = list(map(float, input().split(",")))
x = torch.tensor(r).view(1, len(r))
print(model(x)[0,0].item())
except Exception as e:
print("error:", e)
最终输出如下:
省略开始的输出
stop training because highest validating accuracy not updated in 100 epoches
highest validating accuracy: 0.93173748254776 from epoch 645
testing x: tensor([[48., 1., 18., ..., 5., 0., 5.],
[22., 1., 2., ..., 2., 1., 2.],
[24., 0., 1., ..., 3., 2., 0.],
...,
[24., 0., 4., ..., 0., 1., 1.],
[39., 0., 0., ..., 0., 5., 5.],
[36., 0., 5., ..., 3., 0., 3.]]), y: tensor([[14000.],
[10500.],
[13000.],
...,
[15500.],
[12000.],
[19000.]]), predicted: tensor([[15612.1895],
[10705.9873],
[12577.7988],
...,
[16281.9277],
[10780.5996],
[19780.3281]], grad_fn=<AddmmBackward>)
testing accuracy: 0.9330222606658936
训练集与验证集的正确率变化如下,可以看到我们停在了一个很好的地方😸,继续训练下去也不会有什么改进:
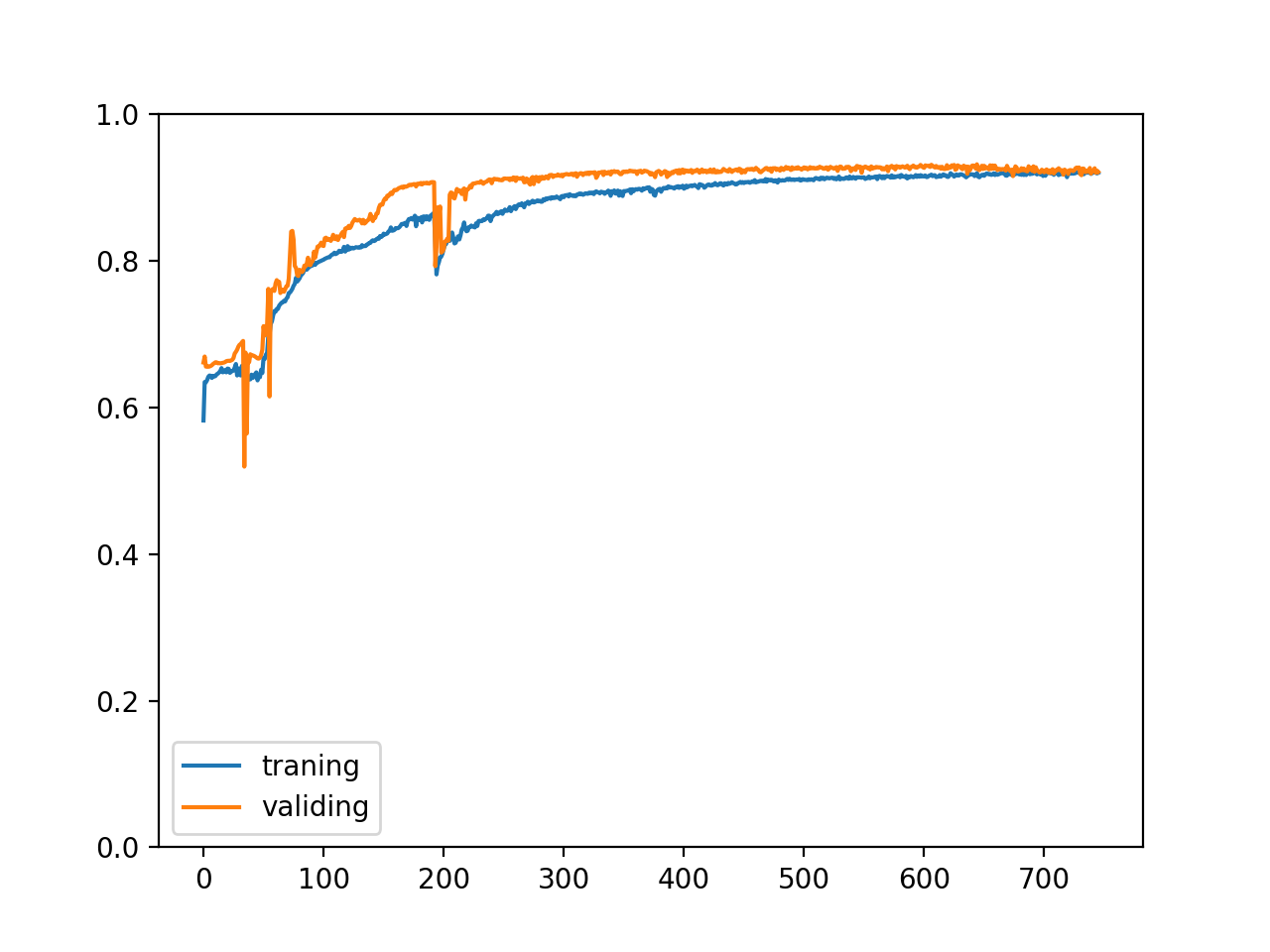
改进程序结构
我们还可以对程序结构进行以下的改进:
- 分离准备数据集和训练的过程
- 训练过程中分批读取数据
- 提供接口使用训练好的模型
至此为止我们看到的训练代码都是把准备数据集,训练,训练后评价和使用写在一个程序里面的,这样做容易理解但在实际业务中会比较浪费时间,如果你发现一个模型不适合,需要修改模型那么你得从头开始。我们可以分离准备数据集和训练的过程,首先读取原始数据并且转换到 tensor 对象再保存到硬盘,然后再从硬盘读取 tensor 对象进行训练,这样如果需要修改模型但不需要修改输入输出转换到 tensor 的编码时,可以节省掉第一步。
在实际业务上数据可能会非常庞大,做不到全部读取到内存中再分批次,这时我们可以在读取原始数据并且转换到 tensor 对象的时候进行分批,然后训练的过程中逐批从硬盘读取,这样就可以防止内存不足的问题。
最后我们可以提供一个对外的接口来使用训练好的模型,如果你的程序是 python 写的那么直接调用即可,但如果你的程序是其他语言写的,可能需要先建立一个 python 服务器提供 REST 服务,或者使用 TorchScript 进行跨语言交互,详细可以参考官方的教程。
总结起来我们会拆分以下过程:
- 读取原始数据集并转换到 tensor 对象
- 分批次保存 tensor 对象到硬盘
- 分批次从硬盘读取 tensor 对象并进行训练
- 训练时保存模型状态到硬盘 (一般选择保存验证集正确率最高时的模型状态)
- 提供接口使用训练好的模型
以下是改进后的示例代码:
import os
import sys
import pandas
import torch
import gzip
import itertools
from torch import nn
from matplotlib import pyplot
class MyModel(nn.Module):
"""根据码农条件预测工资的模型"""
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=100)
self.layer2 = nn.Linear(in_features=100, out_features=50)
self.layer3 = nn.Linear(in_features=50, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
def save_tensor(tensor, path):
"""保存 tensor 对象到文件"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""从文件读取 tensor 对象"""
return torch.load(gzip.GzipFile(path, "rb"))
def prepare():
"""准备训练"""
# 数据集转换到 tensor 以后会保存在 data 文件夹下
if not os.path.isdir("data"):
os.makedirs("data")
# 从 csv 读取原始数据集,分批每次读取 2000 行
for batch, df in enumerate(pandas.read_csv('salary.csv', chunksize=2000)):
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 切分训练集 (60%),验证集 (20%) 和测试集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
training_set = dataset_tensor[traning_indices]
validating_set = dataset_tensor[validating_indices]
testing_set = dataset_tensor[testing_indices]
# 保存到硬盘
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def train():
"""开始训练"""
# 创建模型实例
model = MyModel()
# 创建损失计算器
loss_function = torch.nn.MSELoss()
# 创建参数调整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.0000001)
# 记录训练集和验证集的正确率变化
traning_accuracy_history = []
validating_accuracy_history = []
# 记录最高的验证集正确率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 读取批次的工具函数
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 计算正确率的工具函数
def calc_accuracy(actual, predicted):
return max(0, 1 - ((actual - predicted).abs() / actual.abs()).mean().item())
# 开始训练过程
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
# 切换模型到训练模式,将会启用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.train()
traning_accuracy_list = []
for batch in read_batches("data/training_set"):
# 切分小批次,有助于泛化模型
for index in range(0, batch.shape[0], 100):
# 划分输入和输出
batch_x = batch[index:index+100,:-1]
batch_y = batch[index:index+100,-1:]
# 计算预测值
predicted = model(batch_x)
# 计算损失
loss = loss_function(predicted, batch_y)
# 从损失自动微分求导函数值
loss.backward()
# 使用参数调整器调整参数
optimizer.step()
# 清空导函数值
optimizer.zero_grad()
# 记录这一个批次的正确率,torch.no_grad 代表临时禁用自动微分功能
with torch.no_grad():
traning_accuracy_list.append(calc_accuracy(batch_y, predicted))
traning_accuracy = sum(traning_accuracy_list) / len(traning_accuracy_list)
traning_accuracy_history.append(traning_accuracy)
print(f"training accuracy: {traning_accuracy}")
# 检查验证集
# 切换模型到验证模式,将会禁用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
validating_accuracy_list.append(calc_accuracy(batch[:,-1:], model(batch[:,:-1])))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 记录最高的验证集正确率与当时的模型状态,判断是否在 100 次训练后仍然没有刷新记录
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 100:
# 在 100 次训练后仍然没有刷新记录,结束训练
print("stop training because highest validating accuracy not updated in 100 epoches")
break
# 使用达到最高正确率时的模型状态
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 检查测试集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
testing_accuracy_list.append(calc_accuracy(batch[:,-1:], model(batch[:,:-1])))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 显示训练集和验证集的正确率变化
pyplot.plot(traning_accuracy_history, label="traning")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用训练好的模型"""
parameters = [
"Age",
"Gender (0: Male, 1: Female)",
"Years of work experience",
"Java Skill (0 ~ 5)",
"NET Skill (0 ~ 5)",
"JS Skill (0 ~ 5)",
"CSS Skill (0 ~ 5)",
"HTML Skill (0 ~ 5)"
]
# 创建模型实例,加载训练好的状态,然后切换到验证模式
model = MyModel()
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 询问输入并预测输出
while True:
try:
x = torch.tensor([int(input(f"Your {p}: ")) for p in parameters], dtype=torch.float)
# 转换到 1 行 1 列的矩阵,这里其实可以不转换但推荐这么做,因为不是所有模型都支持非批次输入
x = x.view(1, len(x))
y = model(x)
print("Your estimated salary:", y[0,0].item(), "\n")
except Exception as e:
print("error:", e)
def main():
"""主函数"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 给随机数生成器分配一个初始值,使得每次运行都可以生成相同的随机数
# 这是为了让过程可重现,你也可以选择不这样做
torch.random.manual_seed(0)
# 根据命令行参数选择操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
执行以下命令即可走一遍完整的流程,如果你需要调整模型,可以直接重新运行 train 避免 prepare 的时间消耗:
python3 example.py prepare
python3 example.py train
python3 example.py eval如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 123
- 统信桌面专业版【全盘安装UOS系统】介绍 117
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 109
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 102
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益208.98元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
