写给程序员的机器学习入门 (一) - 从基础说起(二)
一个最简单的例子
为了更好的理解前述的步骤,我准备了一个最简单的例子:
假设有以下的输入与输出,怎样才能自动找出从输入转换到输出的方法呢?

你很可能一眼就已经看出了它们的规律,别急,让我们使用机器学习来解决这个问题。
我们可以先假设输入乘以某个值再加上某个值等于输出,然后:
- 用 x 代表输入
- 用 y 代表输出
- 用 weight 代表输入乘以的值 (公式中缩写为 w)
- 用 bias 代表输出加上的值 (公式中缩写为 b)
用数学公式可以表达如下:
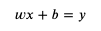
这个公式就是模型中的计算方法部分,而 weight 和 bias 则是这个模型的参数,我们把部分输入与输出代入 x 和 y:
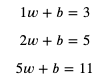
接下来要做的就是找出可以满足这些等式的 weight 和 bias。
我们首先随便给 weight 和 bias 分配值,例如给 weight 分配 1,给 bias 分配 0,然后试试计算结果:
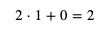
这个计算结果 2 就是预测输出,而预测输出和正确输出之间的差距就是损失。
如果用 predicted (缩写 p) 代表预测输出,用 loss (缩写 l) 代表损失,可以得出以下公式:
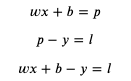
如果 loss 等于 0,那么预测输出 predicted 就会等于正确输出 y,我们的目标是尽量的让 loss 接近 0。
想想如果 weight 增加 1 时 loss 会增加多少,而 bias 增加 1 时 loss 会增加多少:
- weight 增加 1 时,loss 会增加 x
- bias 增加 1 时,loss 会增加 1
可以看出 weight 和 bias 与 loss 是正相关的,并且 weight 和 bias 对 loss 的贡献是 x 比 1,在前面的例子中,loss 等于 predicted - y 等于 2 - 5 等于 -3,我们需要增加 weight 和 bias 的值来让 loss 更接近 0。增加 weight 和 bias 时的比例应该与贡献比例一致,试着给 weight 加上 x,bias 加上 1,调整以后 weight 等于 3,bias 等于 1,计算结果如下:
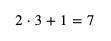
这下 loss 等于 7 - 5 等于 2 了,我们需要减少 weight 和 bias 来让 loss 更接近 0,如果和之前一样 weight 减去 x,bias 减去 1,那么 weight 和 bias 就会变回之前的值,不管调整多少次都无法减少 loss,噢😢。解决这个问题可以控制每次 weight 和 bias 的修改量,例如每次只修改 0.01 倍 (这个倍数又称学习比率 - Learning Rate - 简称 LR),总结规则如下:
如果 loss 小于 0:
- weight 增加 x 乘以 0.01
- bias 增加 0.01
如果 loss 大于 0:
- weight 减少 x 乘以 0.01
- bias 减少 0.01
模拟一下修改的过程:
第一轮:
x = 2, y = 5, weight = 1, bias = 0
predicted = 2 * 1 + 0 = 2
loss = 2 - 5 = -3
weight += 2 * 0.1
bias += 0.1
第二轮:
x = 2, y = 5, weight = 1.02, bias = 0.01
predicted = 2 * 1.02 + 0.01 = 2.05
loss = 2.05 - 5 = -2.95
weight += 2 * 0.1
bias += 0.1
第三轮:
x = 2, y = 5, weight = 1.04, bias = 0.02
predicted = 2 * 1.04 + 0.02 = 2.1
loss = 2.1 - 5 = -2.9
weight += 2 * 0.1
bias += 0.1
可以看到 loss 越来越接近 0,继续修改下去 weight 会等于 2.2,bias 会等于 0.6,满足 x 等于 2,y 等于 5 的情况,但满足不了数据集中的其他数据。我们可以编写一个程序遍历数据集中的数据来进行同样的修改,来看看能不能找到满足数据集中所有数据的 weight 和 bias:
# 定义参数
weight = 1
bias = 0
# 定义学习比率
learning_rate = 0.01
# 准备训练集,验证集和测试集
traning_set = [(2, 5), (5, 11), (6, 13), (7, 15), (8, 17)]
validating_set = [(12, 25), (1, 3)]
testing_set = [(9, 19), (13, 27)]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
for x, y in traning_set:
# 计算预测值
predicted = x * weight + bias
# 计算损失
loss = predicted - y
# 打印除错信息
print(f"traning x: {x}, y: {y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 判断需要如何修改 weight 和 bias 才能减少 loss
if loss < 0:
# 需要增加 weight 和 bias 来让 predicted 更大
weight += x * learning_rate
bias += 1 * learning_rate
else:
# 需要减少 weight 和 bias 来让 predicted 更小
weight -= x * learning_rate
bias -= 1 * learning_rate
# 检查验证集
validating_accuracy = 0
for x, y in validating_set:
predicted = x * weight + bias
validating_accuracy += 1 - abs(y - predicted) / y
print(f"validating x: {x}, y: {y}, predicted: {predicted}")
validating_accuracy /= len(validating_set)
# 如果验证集正确率大于 99 %,则停止训练
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 检查测试集
testing_accuracy = 0
for x, y in testing_set:
predicted = x * weight + bias
testing_accuracy += 1 - abs(y - predicted) / y
print(f"testing x: {x}, y: {y}, predicted: {predicted}")
testing_accuracy /= len(testing_set)
print(f"testing accuracy: {testing_accuracy}")
输出结果如下:
epoch: 1
traning x: 2, y: 5, predicted: 2, loss: -3, weight: 1, bias: 0
traning x: 5, y: 11, predicted: 5.109999999999999, loss: -5.890000000000001, weight: 1.02, bias: 0.01
traning x: 6, y: 13, predicted: 6.4399999999999995, loss: -6.5600000000000005, weight: 1.07, bias: 0.02
traning x: 7, y: 15, predicted: 7.940000000000001, loss: -7.059999999999999, weight: 1.1300000000000001, bias: 0.03
traning x: 8, y: 17, predicted: 9.64, loss: -7.359999999999999, weight: 1.2000000000000002, bias: 0.04
validating x: 12, y: 25, predicted: 15.410000000000004
validating x: 1, y: 3, predicted: 1.3300000000000003
validating accuracy: 0.5298666666666668
epoch: 2
traning x: 2, y: 5, predicted: 2.6100000000000003, loss: -2.3899999999999997, weight: 1.2800000000000002, bias: 0.05
traning x: 5, y: 11, predicted: 6.560000000000001, loss: -4.439999999999999, weight: 1.3000000000000003, bias: 0.060000000000000005
traning x: 6, y: 13, predicted: 8.170000000000002, loss: -4.829999999999998, weight: 1.3500000000000003, bias: 0.07
traning x: 7, y: 15, predicted: 9.950000000000003, loss: -5.049999999999997, weight: 1.4100000000000004, bias: 0.08
traning x: 8, y: 17, predicted: 11.930000000000003, loss: -5.069999999999997, weight: 1.4800000000000004, bias: 0.09
validating x: 12, y: 25, predicted: 18.820000000000007
validating x: 1, y: 3, predicted: 1.6600000000000006
validating accuracy: 0.6530666666666669
epoch: 3
traning x: 2, y: 5, predicted: 3.220000000000001, loss: -1.779999999999999, weight: 1.5600000000000005, bias: 0.09999999999999999
traning x: 5, y: 11, predicted: 8.010000000000002, loss: -2.9899999999999984, weight: 1.5800000000000005, bias: 0.10999999999999999
traning x: 6, y: 13, predicted: 9.900000000000002, loss: -3.099999999999998, weight: 1.6300000000000006, bias: 0.11999999999999998
traning x: 7, y: 15, predicted: 11.960000000000004, loss: -3.0399999999999956, weight: 1.6900000000000006, bias: 0.12999999999999998
traning x: 8, y: 17, predicted: 14.220000000000006, loss: -2.779999999999994, weight: 1.7600000000000007, bias: 0.13999999999999999
validating x: 12, y: 25, predicted: 22.230000000000008
validating x: 1, y: 3, predicted: 1.9900000000000007
validating accuracy: 0.7762666666666669
省略途中的输出
epoch: 90
traning x: 2, y: 5, predicted: 4.949999999999935, loss: -0.05000000000006466, weight: 1.9799999999999676, bias: 0.9900000000000007
traning x: 5, y: 11, predicted: 10.999999999999838, loss: -1.616484723854228e-13, weight: 1.9999999999999676, bias: 1.0000000000000007
traning x: 6, y: 13, predicted: 13.309999999999807, loss: 0.3099999999998069, weight: 2.0499999999999674, bias: 1.0100000000000007
traning x: 7, y: 15, predicted: 14.929999999999772, loss: -0.07000000000022766, weight: 1.9899999999999674, bias: 1.0000000000000007
traning x: 8, y: 17, predicted: 17.48999999999974, loss: 0.4899999999997391, weight: 2.059999999999967, bias: 1.0100000000000007
validating x: 12, y: 25, predicted: 24.759999999999607
validating x: 1, y: 3, predicted: 2.9799999999999676
validating accuracy: 0.9918666666666534
testing x: 9, y: 19, predicted: 18.819999999999705
testing x: 13, y: 27, predicted: 26.739999999999572
testing accuracy: 0.9904483430799063
最终 weight 等于 2.05,bias 等于 1.01,它针对没有训练过的检查集和测试集可以达到 99 % 的正确率 (预测输出 99 % 接近正确输出),如果 99 % 的正确率可以接受,那么就可以说这次训练成功了。
如果你想看 weight 和 bias 的变化,可以记录它们的值并且使用 matplotlib 来显示图表。
安装 matplotlib 的命令:
pip3 install matplotlib
修改后的代码:
# 定义参数
weight = 1
bias = 0
# 定义学习比率
learning_rate = 0.01
# 准备训练集,验证集和测试集
traning_set = [(2, 5), (5, 11), (6, 13), (7, 15), (8, 17)]
validating_set = [(12, 25), (1, 3)]
testing_set = [(9, 19), (13, 27)]
# 记录 weight 与 bias 的历史值
weight_history = [weight]
bias_history = [bias]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
for x, y in traning_set:
# 计算预测值
predicted = x * weight + bias
# 计算损失
loss = predicted - y
# 打印除错信息
print(f"traning x: {x}, y: {y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 判断需要如何修改 weight 和 bias 才能减少 loss
if loss < 0:
# 需要增加 weight 和 bias 来让 predicted 更大
weight += x * learning_rate
bias += 1 * learning_rate
else:
# 需要减少 weight 和 bias 来让 predicted 更小
weight -= x * learning_rate
bias -= 1 * learning_rate
weight_history.append(weight)
bias_history.append(bias)
# 检查验证集
validating_accuracy = 0
for x, y in validating_set:
predicted = x * weight + bias
validating_accuracy += 1 - abs(y - predicted) / y
print(f"validating x: {x}, y: {y}, predicted: {predicted}")
validating_accuracy /= len(validating_set)
# 如果验证集正确率大于 99 %,则停止训练
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 检查测试集
testing_accuracy = 0
for x, y in testing_set:
predicted = x * weight + bias
testing_accuracy += 1 - abs(y - predicted) / y
print(f"testing x: {x}, y: {y}, predicted: {predicted}")
testing_accuracy /= len(testing_set)
print(f"testing accuracy: {testing_accuracy}")
# 显示 weight 与 bias 的变化
from matplotlib import pyplot
pyplot.plot(weight_history, label="weight")
pyplot.plot(bias_history, label="bias")
pyplot.legend()
pyplot.show()
输出的图表,可以看到 weight 接近 2 以后一直上下浮动,而 bias 逐渐接近 1:
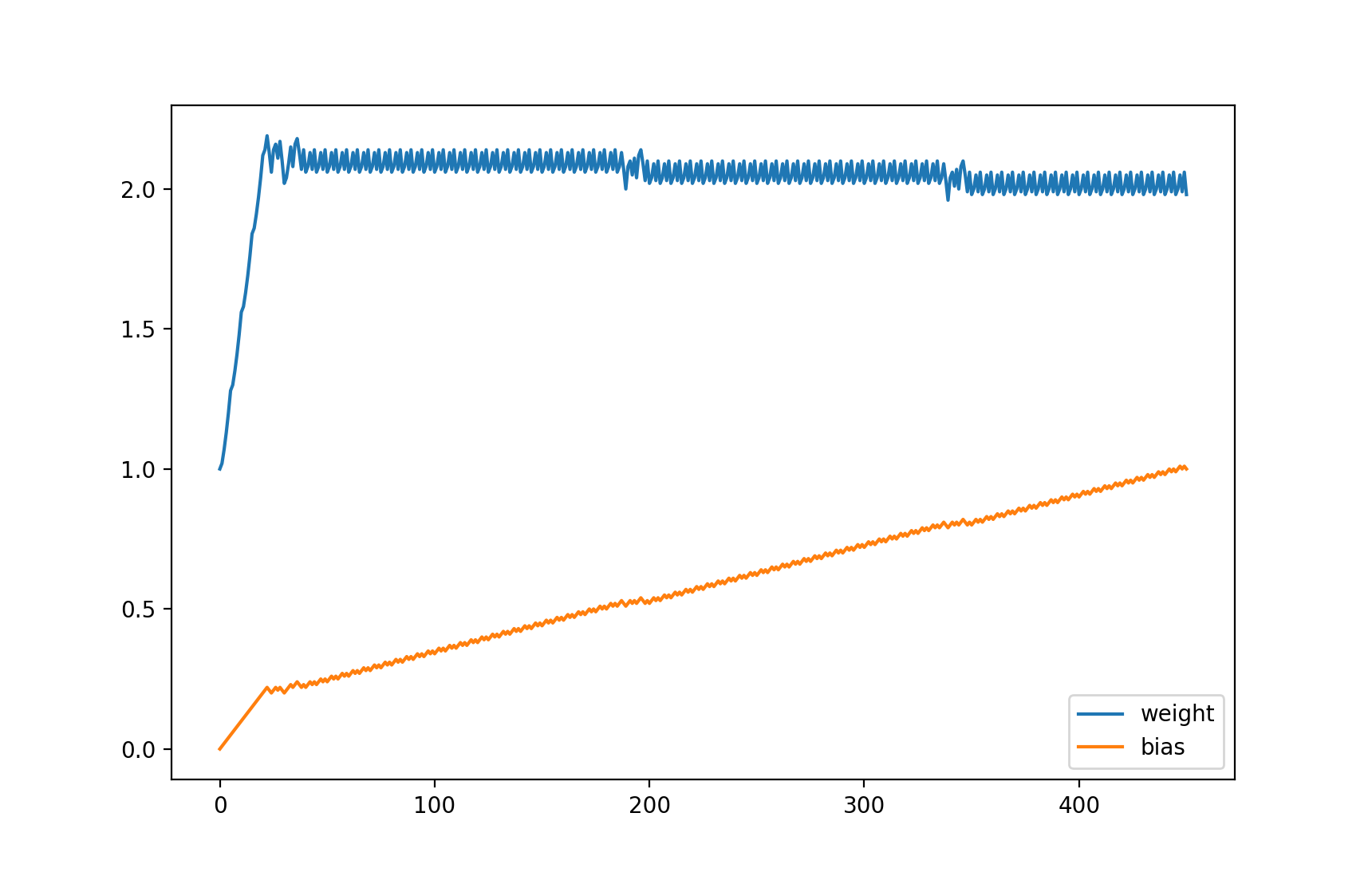
等等,你是不是觉得这个例子很蠢?这个例子的确很蠢,如果我们用其他方法 (例如联立方程式) 可以马上计算出 weight 应该等于 2,bias 应该等于 1,这时预测输出 100 % 等于正确输出。但这个例子代表了机器学习最基础的原理 - 计算各个参数对损失的贡献比例然后修改参数让损失接近 0,如果模型的计算方法非常复杂,将没有方法立刻计算出可以让损失等于 0 的参数值,只能慢慢的调整参数去试。
好了,那为什么上面的例子不能调整 weight 到 2,bias 到 1 呢?主要有两个原因,第一是学习比率为 0.01,如果出现 loss 很接近但小于 0,weight 和 bias 增加以后 loss 大于 0,然后减少 weight 和 bias 又让 loss 变回原来的值,那么接下来无论学习多少次 loss 都不会等于 0,而是在小于 0 的某个值和大于 0 的某个值之间摇摆;第二是我们在正确率达到 99 % 的时候就中断了训练。你可以试试减少学习比率和增加中断训练需要的正确率,试试 weight 和 bias 会不会更接近 2 和 1。
此外在这个例子中,因为所有数据都是完美的,没有杂质在里面,并且模型非常的简单,所以不会出现过拟合 (Overfitting) 问题,也不需要使用提早停止 (Early Stopping) 的手法来防止过拟合。
机器学习与微分
很多机器学习的文章喜欢用抛物线和一个球来形容机器学习训练的过程:
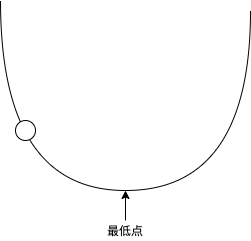
把球看作参数,抛物线看作 loss 的值,如果球在左半部分 loss 小于 0,如果球在右半部分 loss 大于 0,如果球落在最低点那么 loss 等于 0,机器学习的过程就是调整这个球的位置。球所在的位置的梯度 (Gradient) 决定了球的移动方向和每次的移动距离(移动速度),球在左半边的时候会向右移,球在右半边的时候会向左移,而梯度越大每次的移动距离就越长,如果每次的移动距离很长,球可能会一直左右摇摆而无法落在最低点,这个时候我们就需要使用学习比率 (Learning Rate) 来控制每次移动的距离,让每次移动的距离等于 梯度 * 学习比率。
在前述的例子中,参数 weight 的梯度是 x,而参数 bias 的梯度是 1,这实际上就是它们的导函数 (Derivative Function):

如果你还记得高中学过的微积分,那么立刻就能看明白,但我问过但很多程序员都说已经忘光了还给数学老师了😓,所以我在这里再简单解释一下微分的概念,还记得的就当复习叭。
所谓微分就是求某个函数的导函数,而导函数就是求某一个点上值的变化与结果的变化的关联 (梯度)。以前面的例子为例,weight 如果增加 1,那么 loss 就会增加 x,weight 如果增加 2,那么 loss 就会增加 2x,所以 weight 的导函数可以用 x 来表示;而 bias 如果增加 1,那么 loss 就会增加 1,bias 如果增加 2,那么 loss 就会增加 2,所以 bias 的导函数可以用 1 来表示。
求导函数的通用公式如下:
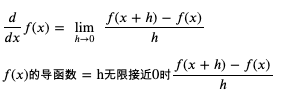
求 weight 和 bias 的导函数 (weight 和 bias 的变化与 loss 的变化的关联) 的过程如下:

你可能会有疑问为什么要求 h 无限接近于 0,这是因为导函数求的是某个点上变化的关联,而这个关联可能会根据点的位置而不同,在上述例子中 weight 和 bias 不管在哪里,它们和 loss 的关联都是相同的,不会依赖于 weight 和 bias 的值。我们可以看一个根据位置不同关联发生变化的例子,例如 x 的平方:
当 x 等于 3 时,x 的平方等于 9
当 x 等于 5 时,x 当平方等于 25
求 x 的变化与 x 的平方的变化的关联
当 x 等于 3 + 1 时,x 的平方等于 16,与原值相差 7
当 x 等于 5 + 1 时,x 当平方等于 36,与原值相差 11
可以看到当 x 增加 1 时,x 的平方增加多少不是固定的,会依赖于 x 的值
求 x 的平方的导函数的过程如下:
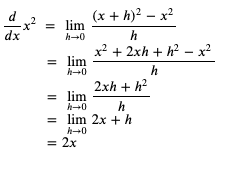
我们可以粗略检查一下这个导函数是否正确 (以下的代码运行在 python 的 REPL 中):
>>> ((3 + 1) ** 2 - 3 ** 2) / 1
7.0
>>> ((3 + 0.1) ** 2 - 3 ** 2) / 0.1
6.100000000000012
>>> ((3 + 0.01) ** 2 - 3 ** 2) / 0.01
6.009999999999849
>>> ((3 + 0.001) ** 2 - 3 ** 2) / 0.001
6.000999999999479
>>> ((5 + 1) ** 2 - 5 ** 2) / 1
11.0
>>> ((5 + 0.1) ** 2 - 5 ** 2) / 0.1
10.09999999999998
>>> ((5 + 0.01) ** 2 - 5 ** 2) / 0.01
10.009999999999764
>>> ((5 + 0.001) ** 2 - 5 ** 2) / 0.001
10.001000000002591
可以看到变化的值越接近 0,变化值与结果的关联越接近 2x。
现在我们了解微分了,那积分是什么呢?积分分为不定积分和定积分,不定积分就是反过来从导函数求原始函数,定积分就是从导函数和参数的变化范围求结果的变化范围:

好了,复习就到此为止,我们来总结一下机器学习是怎么利用微分来调整参数的:
- 假设一个可以从输入计算输出的公式
- 定好计算损失的方法,并把公式变形为计算损失的公式
- 利用微分来计算公式的各个参数对损失的贡献比例 (也就是偏导)
- 随机分配参数的值
- 用预先收集好的输入计算预测输出,然后用预测输出和正确输出计算损失
- 根据各个参数对损失的贡献比例调整参数,使得损失接近 0
- 损失非常接近 0 时,代表公式计算的预测输出非常接近正确输出,如果达到可接受的范围就可以停止训练
这种调整参数方式称为梯度下降法 (Gradient Descent),因为参数的值是随机分配的,通常又称为随机梯度下降法 (Stochastic Gradient Descent, 简称 SGD)。
让参数调整量依赖损失的大小
我们再来回头看看前面的例子,会发现调整参数的时候,调整量只会依赖输入与学习比率,不会依赖损失的大小,如果我们想在损失比较大的时候调整多一点,损失比较小的时候调整少一点,应该怎么办呢?
我们可以改变损失的计算方法,把预测输出和正确输出相差的值的平方作为损失,这里我引入一个新的临时变量 diff (缩写 d) 来表示预测输出和正确输出相差的值:
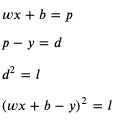
这个时候应该如何计算 weight 和 bias 的导函数呢?
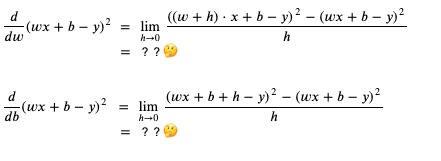
我们可以使用连锁律 (Chain Rule),简单的来说就是如果 x 的变化影响了 y 的变化,y 的变化影响了 z 的变化,那么 x 的变化 与 z 的变化之间的关系可以用前面两个变化的关系组合计算出来 (注意下图中的公式用的是 Lagrange's notation,只是记法不一样):
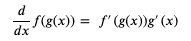
使用连锁律计算 weight 和 bias 的导函数的过程如下 (如果你有兴趣和时间可以试试不用连锁律计算,看看结果是否一样):

可以看到修改 loss 的计算方式后,weight 和 bias 对 loss 的贡献比例是 2 * diff * x 比 2 * diff,会依赖于预测输出与正确输出相差的值,现在我们修改一下上面例子的代码,看看是否仍然可以训练成功:
# 定义参数
weight = 1
bias = 0
# 定义学习比率
learning_rate = 0.01
# 准备训练集,验证集和测试集
traning_set = [(2, 5), (5, 11), (6, 13), (7, 15), (8, 17)]
validating_set = [(12, 25), (1, 3)]
testing_set = [(9, 19), (13, 27)]
# 记录 weight 与 bias 的历史值
weight_history = [weight]
bias_history = [bias]
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
for x, y in traning_set:
# 计算预测值
predicted = x * weight + bias
# 计算损失
diff = predicted - y
loss = diff ** 2
# 打印除错信息
print(f"traning x: {x}, y: {y}, predicted: {predicted}, loss: {loss}, weight: {weight}, bias: {bias}")
# 计算导函数值
derivative_weight = 2 * diff * x
derivative_bias = 2 * diff
# 修改 weight 和 bias 以减少 loss
# diff 为正时代表预测输出 > 正确输出,会减少 weight 和 bias
# diff 为负时代表预测输出 < 正确输出,会增加 weight 和 bias
weight -= derivative_weight * learning_rate
bias -= derivative_bias * learning_rate
# 记录 weight 和 bias 的历史值
weight_history.append(weight)
bias_history.append(bias)
# 检查验证集
validating_accuracy = 0
for x, y in validating_set:
predicted = x * weight + bias
validating_accuracy += 1 - abs(y - predicted) / y
print(f"validating x: {x}, y: {y}, predicted: {predicted}")
validating_accuracy /= len(validating_set)
# 如果验证集正确率大于 99 %,则停止训练
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 检查测试集
testing_accuracy = 0
for x, y in testing_set:
predicted = x * weight + bias
testing_accuracy += 1 - abs(y - predicted) / y
print(f"testing x: {x}, y: {y}, predicted: {predicted}")
testing_accuracy /= len(testing_set)
print(f"testing accuracy: {testing_accuracy}")
# 显示 weight 与 bias 的变化
from matplotlib import pyplot
pyplot.plot(weight_history, label="weight")
pyplot.plot(bias_history, label="bias")
pyplot.legend()
pyplot.show()
输出如下:
epoch: 1
traning x: 2, y: 5, predicted: 2, loss: 9, weight: 1, bias: 0
traning x: 5, y: 11, predicted: 5.66, loss: 28.5156, weight: 1.12, bias: 0.06
traning x: 6, y: 13, predicted: 10.090800000000002, loss: 8.463444639999992, weight: 1.6540000000000001, bias: 0.1668
traning x: 7, y: 15, predicted: 14.246711999999999, loss: 0.567442810944002, weight: 2.003104, bias: 0.22498399999999996
traning x: 8, y: 17, predicted: 17.108564320000003, loss: 0.011786211577063013, weight: 2.10856432, bias: 0.24004976
validating x: 12, y: 25, predicted: 25.332206819199993
validating x: 1, y: 3, predicted: 2.3290725023999994
validating accuracy: 0.8815346140160001
epoch: 2
traning x: 2, y: 5, predicted: 4.420266531199999, loss: 0.3360908948468813, weight: 2.0911940287999995, bias: 0.23787847359999995
traning x: 5, y: 11, predicted: 10.821389980735997, loss: 0.03190153898148744, weight: 2.1143833675519996, bias: 0.24947314297599996
traning x: 6, y: 13, predicted: 13.046511560231679, loss: 0.0021633252351850635, weight: 2.1322443694784, bias: 0.25304534336128004
traning x: 7, y: 15, predicted: 15.138755987910837, loss: 0.019253224181112433, weight: 2.1266629822505987, bias: 0.25211511215664645
traning x: 8, y: 17, predicted: 17.10723714394308, loss: 0.011499805041069082, weight: 2.1072371439430815, bias: 0.2493399923984297
validating x: 12, y: 25, predicted: 25.32814566046583
validating x: 1, y: 3, predicted: 2.3372744504317566
validating accuracy: 0.8829828285293095
epoch: 3
traning x: 2, y: 5, predicted: 4.427353651343945, loss: 0.327923840629112, weight: 2.0900792009121885, bias: 0.24719524951956806
traning x: 5, y: 11, predicted: 10.823573450784844, loss: 0.03112632726796794, weight: 2.112985054858431, bias: 0.2586481764926892
traning x: 6, y: 13, predicted: 13.045942966156671, loss: 0.0021107561392730407, weight: 2.1306277097799464, bias: 0.2621767074769923
traning x: 7, y: 15, predicted: 15.13705972504188, loss: 0.01878536822855566, weight: 2.125114553841146, bias: 0.2612578481538589
traning x: 8, y: 17, predicted: 17.105926192335282, loss: 0.011220358222651178, weight: 2.1059261923352826, bias: 0.2585166536530213
validating x: 12, y: 25, predicted: 25.324134148545966
validating x: 1, y: 3, predicted: 2.3453761313679533
validating accuracy: 0.8844133389237396
省略途中的输出
epoch: 202
traning x: 2, y: 5, predicted: 4.950471765167672, loss: 0.002453046045606255, weight: 2.0077909582882314, bias: 0.9348898485912089
traning x: 5, y: 11, predicted: 10.984740851695477, loss: 0.00023284160697942092, weight: 2.0097720876815246, bias: 0.9358804132878555
traning x: 6, y: 13, predicted: 13.003973611325808, loss: 1.578958696858945e-05, weight: 2.011298002511977, bias: 0.936185596253946
traning x: 7, y: 15, predicted: 15.011854308097591, loss: 0.00014052462047262272, weight: 2.01082116915288, bias: 0.9361061240274299
traning x: 8, y: 17, predicted: 17.009161566019216, loss: 8.393429192445584e-05, weight: 2.0091615660192175, bias: 0.935869037865478
validating x: 12, y: 25, predicted: 25.02803439201881
validating x: 1, y: 3, predicted: 2.9433815220012365
validating accuracy: 0.9900028991598299
testing x: 9, y: 19, predicted: 19.00494724565038
testing x: 13, y: 27, predicted: 27.03573010747495
testing accuracy: 0.9992081406680464
weight 与 bias 的变化如下:
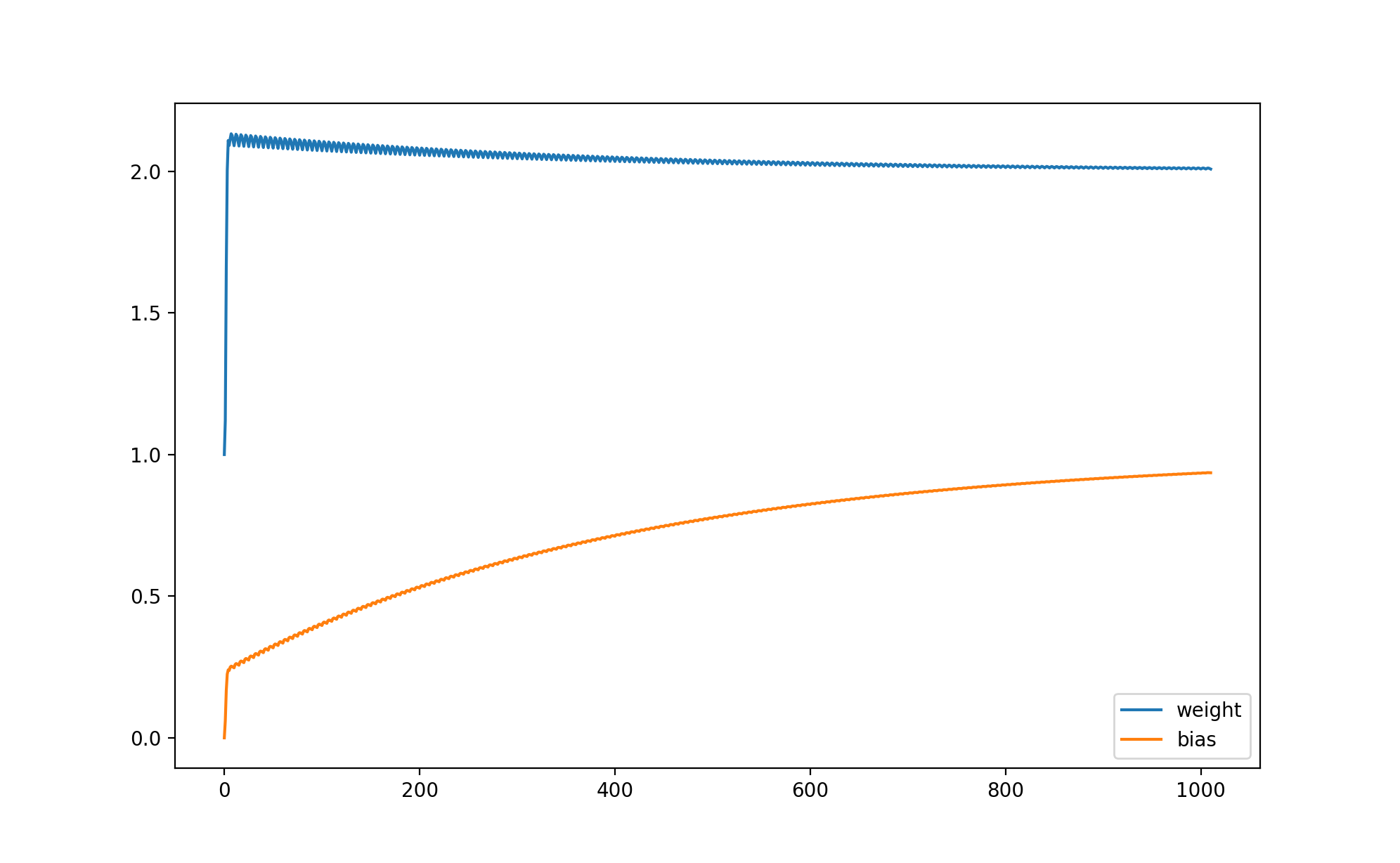
你可能会发现训练速度比前面的例子慢很多,这是因为这个例子实在太简单了,所以无法显示出让参数调整量依赖损失的优势,在复杂的场景下它可以让训练速度更快并且让预测输出更接近正确输出。此外,还有另外一些计算损失的方法,例如 Cross Entropy 等,它们将在后面的文章中提到。
最后补充一个知识点,通过输入计算预测输出的过程在机器学习中称作 Forward,而通过损失调整参数的过程则称作 Backward,如果参数经过多层计算,那么可以把调整多层参数的过程称为反向传播 (Backpropagation),多层计算的模型将在后面的文章中提到。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 123
- 统信桌面专业版【全盘安装UOS系统】介绍 116
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 108
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 101
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益217.85元

1843880570 收益214.2元

IT-feng 收益208.98元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
