写给程序员的机器学习入门 (十二) - 脸部关键点检测 (一)
脸部关键点检测模型
脸部关键点检测模型其实就是普通的 CNN 模型,在第八篇文章中已经介绍过🤒,第八篇文章中,输入是图片,输出是分类 (例如动物的分类,或者验证码中的字母分类)。而这一篇文章输入同样是图片,输出则是各个脸部关键点的坐标:
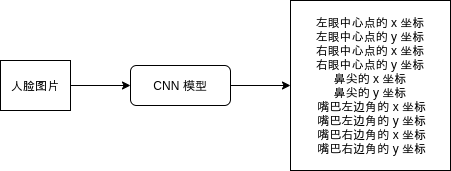
我们会让模型输出五个关键点 (左眼中心,右眼中心,鼻尖,嘴巴左边角,嘴巴右边角) 的 x 坐标与 y 坐标,合计一共 10 个输出。
模型输出的坐标值范围会落在 -1 ~ 1 之间,这是把图片左上角视为 -1,-1,右下角视为 1,1 以后正规化的坐标值。不使用绝对值的原因是机器学习模型并不适合处理较大的值,并且使用相对坐标可以让处理不同大小图片的逻辑更加简单。你可能会问为什么不像前一篇介绍的 YOLO 一样,让坐标值范围落在 0 ~ 1 之间,这是因为下面会使用仿射变换来增加人脸样本,而仿射变换要求相对坐标在 -1 ~ 1 之间,让坐标值范围落在 -1 ~ 1 之间可以省掉转换的步骤。
训练使用的数据集
准备数据集是机器学习中最头疼的部分,一般来说我们需要上百度搜索人脸的图片,然后一张一张的截取,再手动标记各个器官的位置,但这样太苦累了😭。这篇还是像之前的文章一样,从网上找一个现成的数据集来训练,偷个懒🤗。
使用的数据集:
https://www.kaggle.com/drgilermo/face-images-with-marked-landmark-points
下载回来以后可以看到以下的文件:
face_images.npz
facial_keypoints.csv
face_images.npz 是使用 zip 压缩后的 numpy 数据转储文件,把文件名改为 face_images.zip 以后再解压缩即可得到 face_images.npy 文件。
之后再执行 python 命令行,输入以下代码加载数据内容:
>>> import numpy
>>> data = numpy.load("face_images.npy")
>>> data.shape
(96, 96, 7049)
可以看到数据包含了 7049 张 96x96 的黑白人脸图片。
再输入以下代码保存第一章图片:
>>> import torch
>>> data = torch.from_numpy(data).float()
>>> data.shape
torch.Size([96, 96, 7049])
# 把通道放在最前面
>>> data = data.permute(2, 0, 1)
>>> data.shape
torch.Size([7049, 96, 96])
# 提取第一张图片的数据并保存
>>> from PIL import Image
>>> img = Image.fromarray(data[0].numpy()).convert("RGB")
>>> img.save("1.png")
这就是提取出来的图片:

对应以下的坐标,坐标的值可以在 facial_keypoints.csv 中找到:
left_eye_center_x,left_eye_center_y,right_eye_center_x,right_eye_center_y,left_eye_inner_corner_x,left_eye_inner_corner_y,left_eye_outer_corner_x,left_eye_outer_corner_y,right_eye_inner_corner_x,right_eye_inner_corner_y,right_eye_outer_corner_x,right_eye_outer_corner_y,left_eyebrow_inner_end_x,left_eyebrow_inner_end_y,left_eyebrow_outer_end_x,left_eyebrow_outer_end_y,right_eyebrow_inner_end_x,right_eyebrow_inner_end_y,right_eyebrow_outer_end_x,right_eyebrow_outer_end_y,nose_tip_x,nose_tip_y,mouth_left_corner_x,mouth_left_corner_y,mouth_right_corner_x,mouth_right_corner_y,mouth_center_top_lip_x,mouth_center_top_lip_y,mouth_center_bottom_lip_x,mouth_center_bottom_lip_y
66.0335639098,39.0022736842,30.2270075188,36.4216781955,59.582075188,39.6474225564,73.1303458647,39.9699969925,36.3565714286,37.3894015038,23.4528721805,37.3894015038,56.9532631579,29.0336481203,80.2271278195,32.2281383459,40.2276090226,29.0023218045,16.3563789474,29.6474706767,44.4205714286,57.0668030075,61.1953082707,79.9701654135,28.6144962406,77.3889924812,43.3126015038,72.9354586466,43.1307067669,84.4857744361
各个坐标对应 csv 中的字段如下:
- 左眼中心点的 x 坐标: left_eye_center_x
- 左眼中心点的 y 坐标: left_eye_center_y
- 右眼中心点的 x 坐标: right_eye_center_x
- 右眼中心点的 y 坐标: right_eye_center_y
- 鼻尖的 x 坐标: nose_tip_x
- 鼻尖的 y 坐标: nose_tip_y
- 嘴巴左边角的 x 坐标: mouth_left_corner_x
- 嘴巴左边角的 y 坐标: mouth_left_corner_y
- 嘴巴右边角的 x 坐标: mouth_right_corner_x
- 嘴巴右边角的 y 坐标: mouth_right_corner_y
csv 中还有更多的坐标但我们只使用这些🤒。
接下来定义一个在图片上标记关键点的函数:
from PIL import ImageDraw
DefaultPointColors = ["#FF0000", "#FF00FF", "#00FF00", "#00FFFF", "#FFFF00"]
def draw_points(img, points, colors = None, radius=1):
"""在图片上描画关键点"""
draw = ImageDraw.Draw(img)
colors = colors or DefaultPointColors
for index, point in enumerate(points):
x, y = point
color = colors[index] if index < len(colors) else colors[0]
draw.ellipse((x-radius, y-radius, x+radius, y+radius), fill=color, width=1)
再使用这个函数标记图片即可得到:

使用仿射变换增加人脸样本
仔细观察 csv 中的坐标值,你可能会发现里面的坐标大多都是很接近的,例如左眼中心点的 x 坐标大部分都落在 65 ~ 75 之间。这是因为数据中的人脸图片都是经过处理的,占比和位置比较标准。如果我们直接拿这个数据集来训练,那么模型只会输出学习过的区间的值,这是再拿一张占比和位置不标准的人脸图片给模型,模型就会输出错误的坐标。
解决这个问题我们可以随机旋转移动缩放人脸以增加数据量,在第十篇文章我们学到怎样用仿射变换来提取图片中的某个区域并缩放到固定的大小,仿射变换还可以用来实现旋转移动和缩放,批量计算时的效率非常高。

首先我们需要以下的变量:
- 弧度,范围是 -π ~ π,对应 -180°~ 180°
- 缩放比例,1 代表 100%
- 横向移动量:范围是 -1 ~ 1,把图片中心视为 0,左边视为 -1,右边视为 1
- 纵向移动量:范围是 -1 ~ 1,把图片中心视为 0,左边视为 -1,右边视为 1
根据这些变量生成仿射变换参数的公式如下:
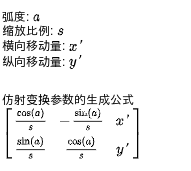
需要注意的是仿射变换参数用于转换 目标坐标 到 来源坐标,在处理图片的时候可以根据目标像素找到来源像素,然后设置来源像素的值到目标像素的值实现各种变形操作。上述的参数只能用于处理图片,如果我们想计算变形以后的图片对应的坐标,我们还需要一个转换 来源坐标 到 目标坐标 的仿射变换参数,计算相反的仿射变换参数的公式如下:
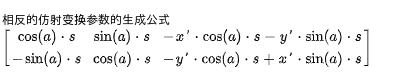
翻译到代码如下:
def generate_transform_theta(angle, scale, x_offset, y_offset, inverse=False):
"""
计算变形参数
angle: 范围 -math.pi ~ math.pi
scale: 1 代表 100%
x_offset: 范围 -1 ~ 1
y_offset: 范围 -1 ~ 1
inverse: 是否计算相反的变形参数 (默认计算把目标坐标转换为来源坐标的参数)
"""
cos_a = math.cos(angle)
sin_a = math.sin(angle)
if inverse:
return (
( cos_a * scale, sin_a * scale, -x_offset * cos_a * scale - y_offset * sin_a * scale),
(-sin_a * scale, cos_a * scale, -y_offset * cos_a * scale + x_offset * sin_a * scale))
else:
return (
(cos_a / scale, -sin_a / scale, x_offset),
(sin_a / scale, cos_a / scale, y_offset))
变形后的人脸样本如下,背景添加了随机颜色让模型更难作弊,具体代码参考后面的 prepare 函数吧😰:

如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 128
- 统信桌面专业版【全盘安装UOS系统】介绍 123
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 116
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 106
- 麒麟系统连接打印机常见问题及解决方法 11
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
