写给程序员的机器学习入门 (十一) - 对象识别 YOLO - 识别人脸位置与是否戴口罩(一)
YOLO 模型概览
YOLO 的缩写是 You only look once,翻译成中文是宝贝你只需要看一次喔😘。YOLO 模型可以直接根据图片输出包含对象的区域与区域对应的分类,一步到位,不像 RCNN 系列的模型需要先计算包含对象的区域,再根据区域判断对应的分类,YOLO 模型的速度比 RCNN 系列的模型要快很多。
YOLO 模型的结构如下:
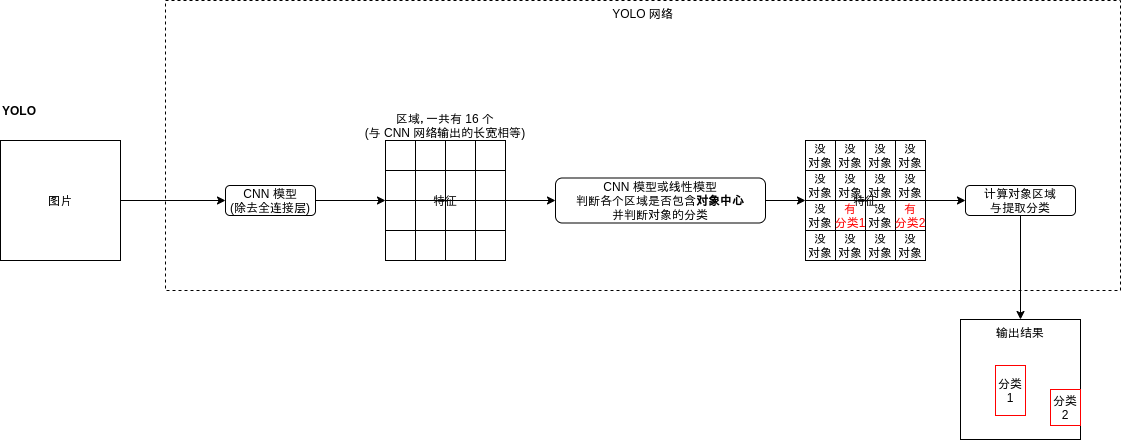
是不是觉得有点熟悉?看上去就像 Faster-RCNN 的区域生成网络 (RPN) 啊。的确,YOLO 模型原理上就是寻找区域的同时判断区域包含的对象分类,YOLO 模型与区域生成网络有以下的不同:
- YOLO 模型会输出各个区域是否包含对象中心,而不是包含对象的一部分
- YOLO 模型会同时输出对象分类
- YOLO 模型输出的区域偏移会根据对象中心点计算,具体算法在下面说明
YOLO 模型与 Faster-RCNN 的区域生成网络最大的不同是会判断各个区域是否包含对象中心,如下图中狗脸覆盖了四个区域,但只有左下角的区域包含了狗脸的中心,YOLO 模型应该只判断这个区域包含对象。
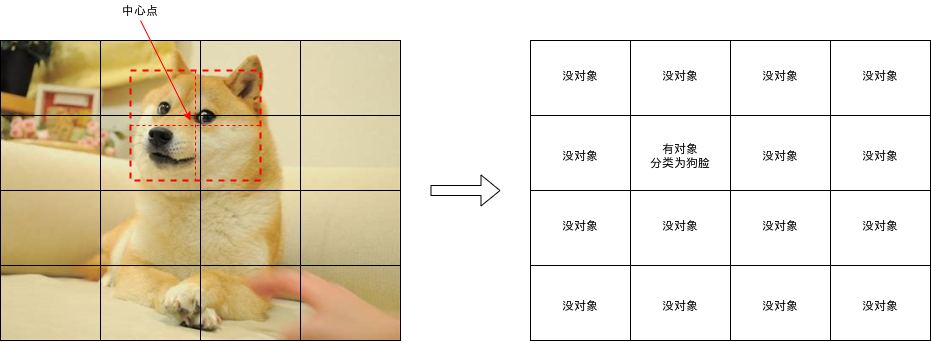
当然,如果对象中心非常接近区域的边界,那么判断起来将会很困难,YOLO 模型在训练的时候会忽略对象重叠率高于一定水平的区域,具体可以参考后面给出的代码。
YOLO 模型会针对各个区域输出以下的结果,这里假设有三个分类:
- 是否包含对象中心 (是为 1, 否为 0)
- 区域偏移 x
- 区域偏移 y
- 区域偏移 w
- 区域偏移 h
- 分类 1 的可能性 (0 ~ 1)
- 分类 2 的可能性 (0 ~ 1)
- 分类 3 的可能性 (0 ~ 1)
输出结果的维度是 批次大小, 区域数量, 5 + 分类数量。
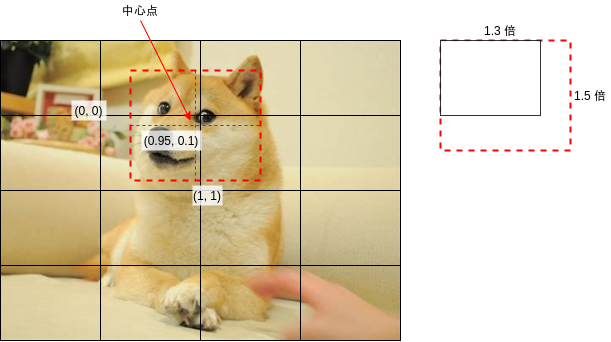
区域偏移用于调整输出的区域范围,例如上图中狗脸的中心点大约在区域的右上角,如果把区域左上角看作 (0, 0),右下角看作 (1, 1),那么狗脸中心点应该在 (0.95, 0.1) 的位置,而狗脸大小相对于区域长宽大概是 (1.3, 1.5) 倍,生成训练数据的时候会根据这 4 个值计算区域偏移,具体计算代码在下面给出。
看到这里你可能会想,YOLO 模型看起来很简单啊,我可以丢掉操蛋的 Faster-RCNN 模型了🤢。不,没那么简单,以上介绍的只是 YOLOv1 模型,YOLOv1 模型的精度非常低,后面为了改进识别精度还发展出 YOLOv2, YOLOv3, YOLOv4, YOLOv5 模型😮,接下来将会介绍 YOLOv2, YOLOv3 模型主要改进了什么部分,再给出 YOLOv3 模型的实现。YOLOv4 和 YOLOv5 模型主要改进了提取特征用的 CNN 模型 (也称骨干网络 Backbone Network),原始的 YOLO 模型使用了 C 语言编写的 Darknet 作为骨干网络,而这篇使用 Resnet 作为骨干网络,所以只介绍到 YOLOv3。
YOLOv2
YOLOv2 最主要的改进点是引入了锚点 (Anchor),如果你已经看完前几篇文章那么应该很了解锚点是什么,锚点会从每个区域的中心点衍生出不同形状的多个锚点区域:
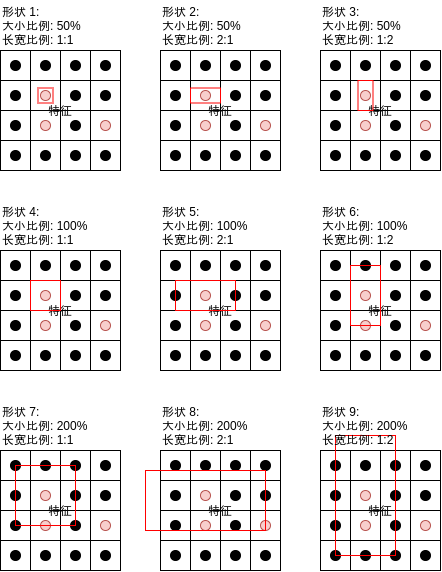
Faster-RCNN 使用锚点主要为了提升区域重叠率以避免漏掉部分对象 (Faster-RCNN 训练时会根据重叠率判断区域是否包含对象,如果对象很长或者很宽但形状只有正方形,那么重叠率就会比较低导致该对象被漏掉),然而 YOLO 使用对象中心点,并不会存在因重叠率不足而漏掉对象的问题,YOLO 使用锚点是为了支持识别中心位于同一个区域的多个对象,如下图所示:

如果对象中心落在某个区域,YOLO 会计算该区域对应的各个形状的重叠率,并使用重叠率最高的形状,这样如果多个对象中心落在同一个区域但它们的形状不同,就会分别判断出不同的分类。YOLOv2 的输出如下图所示:
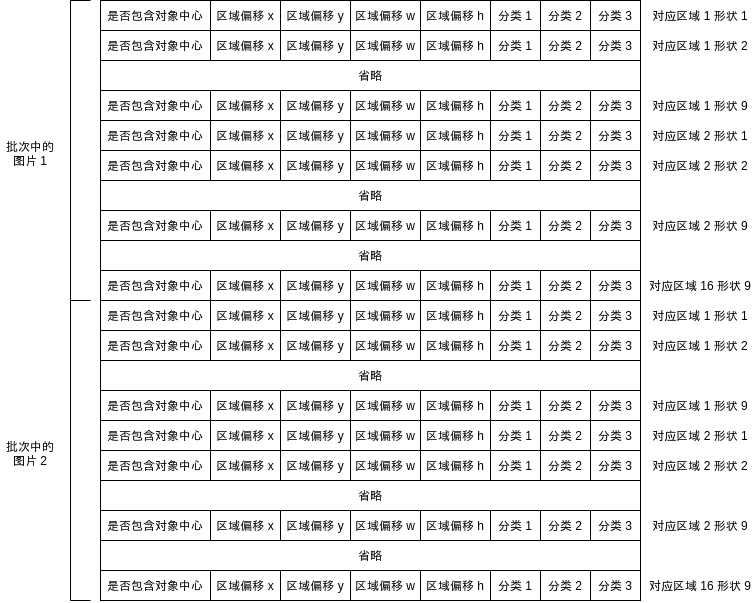
输出结果的维度是 批次大小, 区域数量 * 形状数量, 5 + 分类数量。
YOLOv2 还有一些针对骨干网络和训练方法的改进点,但这篇文章都没用到所以就不介绍了,如果你有兴趣可以参考后面给出的论文链接。
你可能会注意到 YOLO 划分的区域是固定的,并且判断区域是否存在对象和对象的分类时只会使用该区域中的数据,这样会导致以下的问题:
- 如果对象相对区域过大,则模型很难确定哪个区域包含中心点
- Faster-RCNN 按锚点区域的重叠率而不是中心点判断是否包含对象,所以不会有这个问题
- 如果对象相对区域过大,则每个区域都只包含对象的一小部分,很难依据这一小部分来判断对象分类 (例如区域只包含鼻子的时候模型需要只根据鼻子判断是否人脸)
- Faster-RCNN 分两步走,标签分类网络会根据区域生成网络给出的区域截取特征再判断分类,所以不会有这个问题
- 如果对象相对区域过小,则多个对象有可能处于同一个区域中
- 因为 Faster-RCNN 不会有以上两个问题,所以可以用更小的区域

因此,YOLOv2 只适合对象大小和区域大小比较接近的场景。
YOLOv3
为了更好的支持不同大小的对象,YOLOv3 引入了多尺度检测机制 (Multi-Scale Detection),这个机制可以说是 YOLO 模型的精华,引入这个机制之前 YOLO 模型的精度很不理想,而引入之后 YOLO 模型达到了接近 Faster-RCNN 的精度,并且速度还是比 Faster-RCNN 要快。
多尺度检测机制简单的来说就是按不同的尺度划分区域,然后再检测这些不同大小的区域是否包含对象,检测的时候大区域的特征会混合到小区域中,使得小区域判断时拥有一定程度的上下文信息。
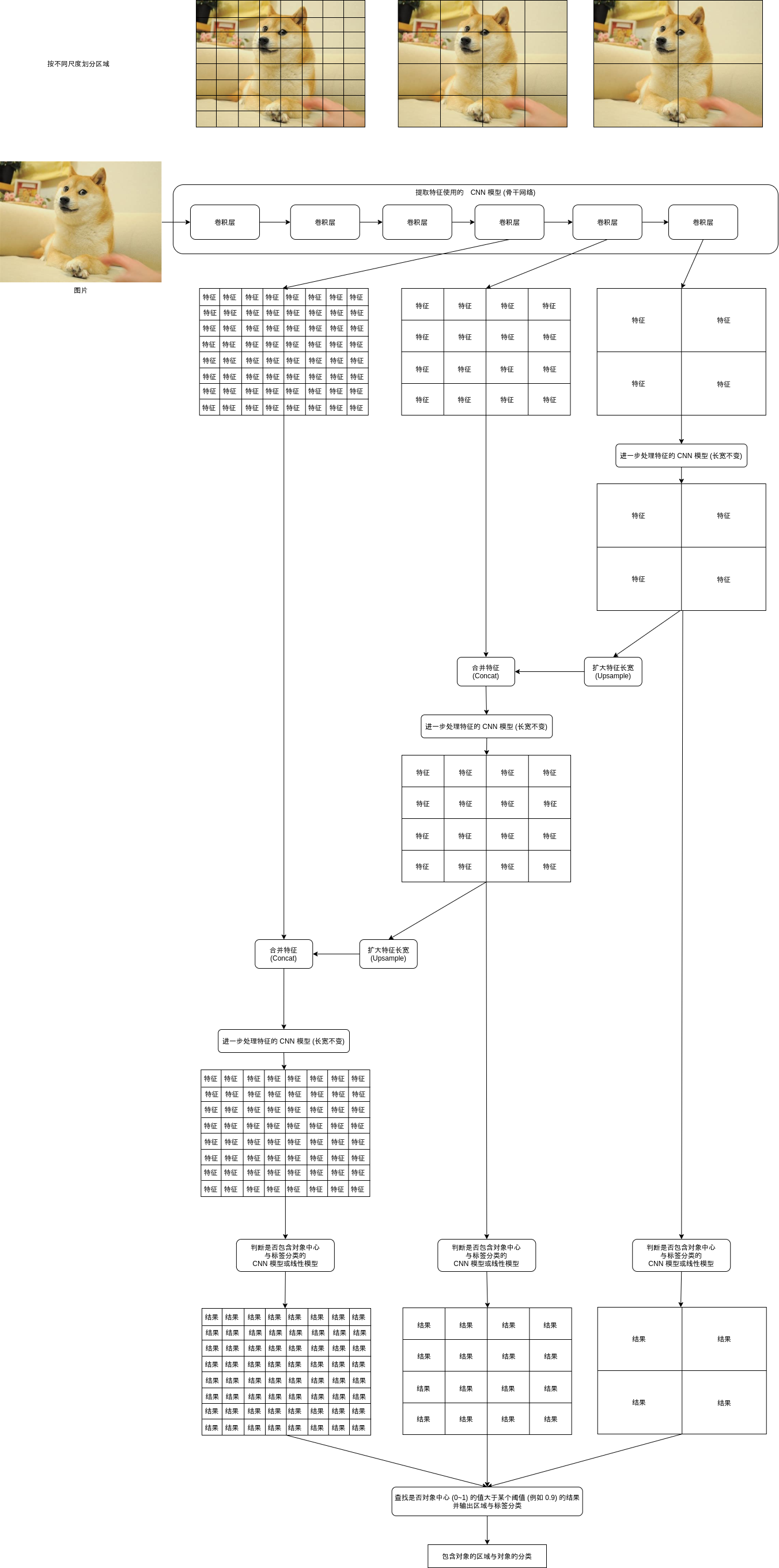
实现多尺度检测机制首先要让 CNN 模型输出不同尺度的特征,我们之前已经看过 CNN 模型中的卷积层可以输出比原有大小更小的特征 (参考第 8 篇),例如指定内核大小 (kernel_size) 为 3,处理间隔 (stride) 为 2,填充大小 (padding) 为 1 的时候,输出大小刚好是输入大小的一半,把这样的卷积层放到 CNN 模型的末尾,然后保留各个卷积层的输出,就可以得出不同尺度的特征。例如指定 3 个尺度的时候,可能会得到以下大小的 3 个特征:
- 批次大小, 通道数量, 8, 8
- 批次大小, 通道数量, 4, 4
- 批次大小, 通道数量, 2, 2
之后再反向处理这三个特征,首先把 批次大小, 通道数量, 2, 2 交给进一步处理特征的 CNN 模型,这个模型会让输出长宽等于输入长宽,所以输出大小和原有大小相同,再扩大特征到 批次大小, 通道数量, 4, 4,例如:
a b
c d
扩大以后会变为
a a b b
a a b b
c c d d
c c d d
之后再合并这个特征到大小为 批次大小, 通道数量, 4, 4 的特征,得出 批次大小, 通道数量 * 2, 4, 4 的特征,把这个特征交给进一步处理特征的 CNN 模型,之后的流程就如上图所示了,最终会得出以下大小的 3 个结果:
- 批次大小, 形状数量 * (5 + 分类数量), 8, 8
- 批次大小, 形状数量 * (5 + 分类数量), 4, 4
- 批次大小, 形状数量 * (5 + 分类数量), 2, 2
变形以后得出:
- 批次大小, 8 * 8 * 形状数量, 5 + 分类数量
- 批次大小, 4 * 4 * 形状数量, 5 + 分类数量
- 批次大小, 2 * 2 * 形状数量, 5 + 分类数量
总结起来,YOLOv3 模型的结构如下图所示:
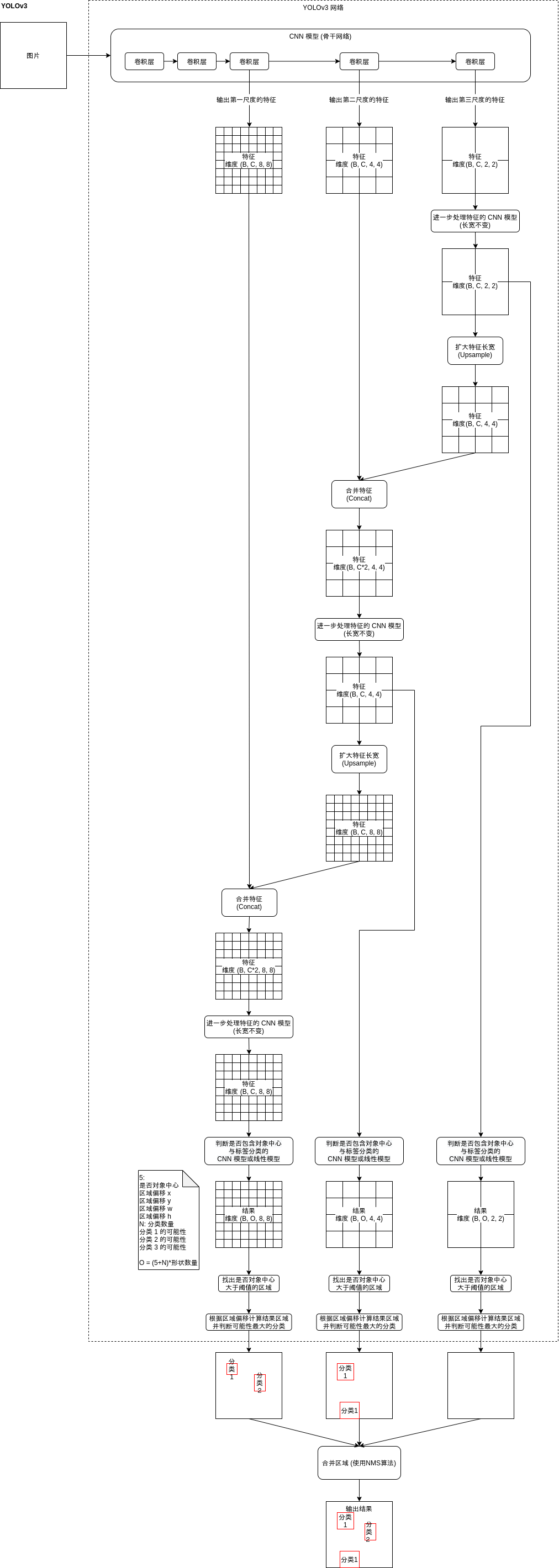
YOLO 模型的实现
接下来我们来看看 YOLO 模型的实现细节,后面会给出完整代码。注意这篇的实现与官方实现不完全一样🤕,这篇会用 Resnet 作为骨干网络,并且会以识别人脸位置为目标调整参数。
定义锚点 (Anchor)
首先是生成锚点范围列表,代码看起来和 Faster-RCNN 使用的差不多:
IMAGE_SIZE = (256, 256) # 缩放图片的大小
Anchors = None # 锚点列表,包含 锚点数量 * 形状数量 的范围
AnchorSpans = (16, 32, 64) # 尺度列表,值为锚点之间的距离
AnchorAspects = ((1, 1), (1, 2), (2, 1)) # 锚点对应区域的长宽比例列表
def generate_anchors():
"""根据锚点和形状生成锚点范围列表"""
w, h = IMAGE_SIZE
anchors = []
for span in AnchorSpans:
for x in range(0, w, span):
for y in range(0, h, span):
xcenter, ycenter = x + span / 2, y + span / 2
for ratio in AnchorAspects:
ww = span * ratio[0]
hh = span * ratio[1]
xx = xcenter - ww / 2
yy = ycenter - hh / 2
xx = max(int(xx), 0)
yy = max(int(yy), 0)
ww = min(int(ww), w - xx)
hh = min(int(hh), h - yy)
anchors.append((xx, yy, ww, hh))
return anchors
Anchors = generate_anchors()
但 YOLO 需要分别处理每个尺度,所以生成的锚点范围列表会首先按尺度排序,生成出来的结构如下:
[
尺度1区域1形状1的范围,
尺度1区域1形状2的范围,
尺度1区域1形状3的范围,
尺度1区域2形状1的范围,
尺度1区域2形状2的范围,
尺度1区域2形状3的范围,
...
尺度2区域1形状1的范围,
尺度2区域1形状2的范围,
尺度2区域1形状3的范围,
...
尺度3区域1形状1的范围,
尺度3区域1形状2的范围,
尺度3区域1形状3的范围,
...
]
最终会包含 (256/16)^2*3 + (256/32)^2*3 + (256/64)^2*3 = 768 + 192 + 48 = 1008 个锚点范围。
这篇文章会用 YOLO 模型实现识别人脸位置与是否带口罩,而人脸的形状通常接近 1:1,所以下面的代码会使用以下的参数生成锚点范围列表:
AnchorSpans = (16, 32, 64) # 尺度列表,值为锚点之间的距离
AnchorAspects = ((1, 1), (1.5, 1.5)) # 锚点对应区域的长宽比例列表
如果你想用来检测其他物体,可以修改参数使得锚点范围的形状更匹配物体形状,以提升检测率。
调整区域范围的算法
在有了锚点范围之后,我们还需要决定一个把锚点范围调整到物体范围的算法,一共需要四个参数,计算规则如下:
- 区域偏移 x: 物体的中心点在锚点范围中的 x 轴位置,0~1 之间
- 区域偏移 y: 物体的中心点在锚点范围中的 y 轴位置,0~1 之间
- 区域偏移 w: log(物体的长度与锚点范围长度的比例)
- 区域偏移 h: log(物体的高度与锚点范围高度的比例)
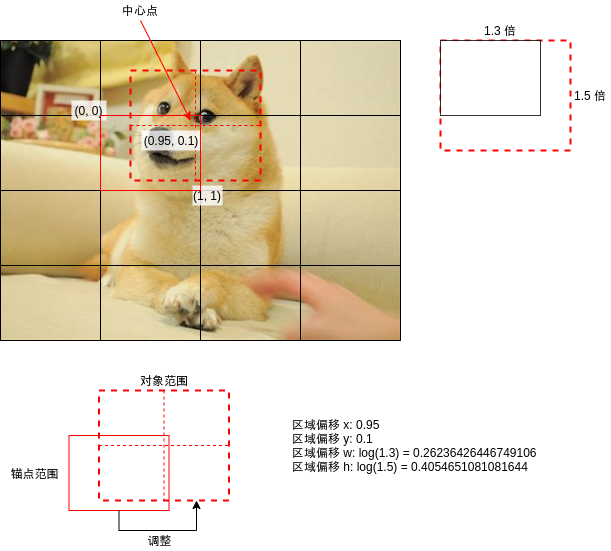
看起来比较简单吧😎,需要注意的是这样调整出来的物体范围中心点一定会在锚点范围中,这点跟 Faster-RCNN 使用的算法不一样。
以下是计算使用的代码,注释中的 "实际区域" 代表物体范围,"候选区域" 代表锚点范围。
def calc_box_offset(candidate_box, true_box):
"""计算候选区域与实际区域的偏移值,要求实际区域的中心点必须在候选区域中"""
# 计算实际区域的中心点在候选区域中的位置,范围会在 0 ~ 1 之间
x1, y1, w1, h1 = candidate_box
x2, y2, w2, h2 = true_box
x_offset = ((x2 + w2 // 2) - x1) / w1
y_offset = ((y2 + h2 // 2) - y1) / h1
# 计算实际区域长宽相对于候选区域长宽的比例,使用 log 减少过大的值
w_offset = math.log(w2 / w1)
h_offset = math.log(h2 / h1)
return (x_offset, y_offset, w_offset, h_offset)
def adjust_box_by_offset(candidate_box, offset):
"""根据偏移值调整候选区域"""
x1, y1, w1, h1 = candidate_box
x_offset, y_offset, w_offset, h_offset = offset
w2 = math.exp(w_offset) * w1
h2 = math.exp(h_offset) * h1
x2 = x1 + w1 * x_offset - w2 // 2
y2 = y1 + h1 * y_offset - h2 // 2
x2 = min(IMAGE_SIZE[0]-1, x2)
y2 = min(IMAGE_SIZE[1]-1, y2)
w2 = min(IMAGE_SIZE[0]-x2, w2)
h2 = min(IMAGE_SIZE[1]-y2, h2)
return (x2, y2, w2, h2)
生成用于训练的实际输出
决定了锚点与调整区域范围的算法以后,我们可以根据训练使用的数据集生成实际的输出结果,训练使用的数据集需要包含:
- 图片
- 包含的对象,可以有多个
- 对象的范围
- 对象的分类
数据集准备好以后,我们比对锚点范围列表与数据集中对象的范围,然后针对每张图片的每个锚点范围生成以下数据:
- 是否对象
- 区域偏移 x
- 区域偏移 y
- 区域偏移 w
- 区域偏移 h
- 分类 1 的可能性
- 分类 2 的可能性
- 分类 3 的可能性
是否对象只有 0 或 1 两个值,如果锚点范围包含对象中心并且锚点范围与对象范围的重叠率 (IOU) 大于阈值 (例如 30%),则为 1,否则为 0。注意如果是否对象为 0,那么后面的区域偏移和各个分类的可能性不需要计算 (例如设置为 0),计算损失的时候也会除掉它们。
四个区域偏移会根据锚点范围与对象范围计算,算法参考上面的说明。
各个分类的可能性按对象的分类计算,如果对象的分类为 "人",而三个分类分别为 "人 猫 狗" 那么分类 1 的可能性为 1,分类 2 与分类 3 的可能性为 0。此外 YOLO 还支持多分类 (要求计算损失的时候用 BinaryCrossEntropy),如果分类为 "人 男人 女人 猪 公猪 母猪" 并且对象是 "母猪" 时,那么各个分类的可能性就是 "0 0 0 1 0 1"。需要注意这里计算出来的值是供模型学习的,模型学习完以后可能会输出 "0.9 0.2 0.0" 这样的浮点数,需要判断最大的值找出最可能的分类,并且根据值的大小判断模型对结果有多少把握。
如果你记得前一篇介绍 Faster-RCNN 模型的文章,应该会想到有一个表示 "非对象" 的分类,Faster-RCNN 的区域生成网络首先会判断一次是否对象,之后的标签分类网络会再次去掉归为非对象分类的结果,这样的做法让识别的精度提升了很多。然而 YOLO 模型只有单步,原则上是不需要非对象分类的,即使加上非对象分类也不会提升判断 "是否对象" 的精度。但如果数据量不足,添加非对象分类可以帮助更好的识别分类。举个例子,例如图片中有棕色的猫和红色的猪,模型可能会判断棕色的都是猫,红色的都是猪,但添加非对象分类以后,如果图片还包含棕色的凳子和红色的电饭锅,那么模型就不会只根据颜色来判断。因此,下面识别人脸位置的例子会添加非对象分类。
具体的代码参考后面的 prepare 函数吧🤒。
计算特征
原始的 YOLO 模型计算特征使用的是叫做 Darknet 的网络,这个网络是 YOLO 作者用 C 语言实现的,算是 YOLO 作者对自己写的框架的宣传吧😤。不过只要理解 YOLO 模型的原理,用其他网络也可以实现差不多的效果 (虽然作者为了刷分做出了很多调整,只是套用其他网络的话正确度追不上),这里我用了目前用的最广泛的 Resnet 模型,代码如下:
self.previous_channels_out = 4
self.resnet_models = nn.ModuleList([
nn.Sequential(
nn.Conv2d(3, self.previous_channels_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.previous_channels_out),
nn.ReLU(inplace=True),
self._make_layer(BasicBlock, channels_out=16, num_blocks=2, stride=1),
self._make_layer(BasicBlock, channels_out=32, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=64, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=128, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=256, num_blocks=2, stride=2)),
self._make_layer(BasicBlock, channels_out=256, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=256, num_blocks=2, stride=2)
])
_make_layer 与 BasicBlock 的代码和之前文章给出的一样,你也可以参考下面的完整代码。
这里定义的 resnet_models 包含了三个子模型,第一个模型会输出维度为 批次大小,256,图片宽度/16,图片高度/16 的结果,第二个模型会接收第一个模型的结果然后输出维度为 批次大小,256,图片宽度/32,图片高度/32 的结果,第三个模型会接收第二个模型的结果然后输出维度为 批次大小,256,图片宽度/64,图片高度/64 的结果。这三个结果分别代表把图片分割为 16x16,32x32,64x64 个区域以后,各个区域对应的特征。
输出三个特征的使用的代码如下:
def forward(self, x):
features_list = []
resnet_input = x
for m in self.resnet_models:
resnet_input = m(resnet_input)
features_list.append(resnet_input)
根据特征预测输出
上一步我们得出了三个特征,接下来就可以根据这三个特征预测三个尺度中的各个区域是否包含对象与对象的分类了。流程和上面介绍的一样,需要分成三步:
- 进一步处理特征 (长宽不变)
- 扩大特征长宽,并且合并到下一个尺度 (更细的尺度) 的特征
- 判断是否对象中心与标签分类
模型代码:
self.yolo_detectors = nn.ModuleList([
# 进一步处理特征
nn.ModuleList([nn.Sequential(
nn.Conv2d(256 if index == 0 else 512, 256, kernel_size=1, stride=1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0, bias=True),
nn.ReLU(inplace=True)),
# 扩大特征长宽
nn.Upsample(scale_factor=2, mode="nearest"),
# 判断是否对象中心与标签分类
nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(256, MyModel.AnchorTotalOutputs, kernel_size=1, stride=1, padding=0, bias=True))])
for index in range(len(self.resnet_models))
])
"判断是否对象中心与标签分类" 的部分可以用 CNN 模型也可以用线性模型,多个不改变长宽的卷积层组合起来可以做到与多层线性模型接近的效果。如果用 CNN 模型可以把维度是 (B, C, W, H) 的输入转换到维度是 (B, O, W, H) 的结果,如果用线性模型则需要先把输入变形到 (B*W*H, C) 然后再通过线性模型转换到维度是 (B*W*H, O) 的结果,再变形到 (B, O, W, H)。前一篇文章介绍的 Faster-RCNN 实现用了线性模型,而这篇使用 CNN 模型,原则上用哪种都可以🤒。
处理特征的代码:
previous_upsampled_feature = None
outputs = []
for index, feature in enumerate(reversed(features_list)):
if previous_upsampled_feature is not None:
# 合并大的锚点距离抽取的特征到小的锚点距离抽取的特征
feature = torch.cat((feature, previous_upsampled_feature), dim=1)
# 计算用于合并的特征
hidden = self.yolo_detectors[index][0](feature)
# 放大特征 (用于下一次处理时合并)
upsampled = self.yolo_detectors[index][1](hidden)
# 计算最终的预测输出
output = self.yolo_detectors[index][2](hidden)
previous_upsampled_feature = upsampled
outputs.append(output)
之后 outputs 会包含三个结果,维度是 (批次大小, (5+分类数量)*形状数量, 尺度对应的宽度, 尺度对应的高度),把这三个结果连起来数量会刚好等于之前生成的锚点数量。连接三个结果的代码如下,注意顺序需要与生成锚点时使用的顺序一样,这样连接后的结果和锚点范围就可以有一对一的关系。
outputs_flatten = []
# 前面处理特征的时候用了 reversed,这里需要再次用 reversed 把顺序调换回来
# 调换以后的三个结果顺序应该与 AnchorSpans 一致
for output in reversed(outputs):
# 变形到 (批次大小, 尺度对应的宽度, 尺度对应的高度, (5+分类数量)*形状数量)
output = output.permute(0, 2, 3, 1)
# 变形到 (批次大小, 宽度*高度*形状数量, 5+分类数量)
# 生成锚点时使用的顺序是 宽度 => 高度 => 形状
output = output.reshape(output.shape[0], -1, MyModel.AnchorOutputs)
outputs_flatten.append(output)
# 连接以后维度是 (批次大小, 尺度数量*宽度*高度*形状数量, 5+分类数量)
# 即 (批次大小, 锚点数量, 5+分类数量)
outputs_all = torch.cat(outputs_flatten, dim=1)
在返回 outputs_all 之前,还需要用 sigmoid 来让是否对象中心与各个分类的可能性对应的值落在 0 ~ 1 之间。注意部分 YOLO 的实现会用 sigmoid 来处理区域偏移 x 和区域偏移 y,因为这两个值也应该落在 0 ~ 1 之间,但我个人认为 sigmoid 只适合处理预期结果是二进制 (0 或 1) 的值,而区域偏移预期结果平均分布在 0 ~ 1 之间,不能起到归并的作用,效果会跟 hardtanh 差不多。
# 是否对象中心应该在 0 ~ 1 之间,使用 sigmoid 处理
outputs_all[:,:,:1] = self.sigmoid(outputs_all[:,:,:1])
# 分类应该在 0 ~ 1 之间,使用 sigmoid 处理
outputs_all[:,:,5:] = self.sigmoid(outputs_all[:,:,5:])
处理完以后,outputs_all 就是 YOLO 模型返回的结果了,它在训练的时候会用于计算损失并调整参数,在实际预测的时候会配合之前生成的锚点列表得出包含对象的区域与对象分类,并标记到图片或者视频上。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 129
- 统信桌面专业版【全盘安装UOS系统】介绍 128
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 119
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 108
- 麒麟系统连接打印机常见问题及解决方法 20
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
