写给程序员的机器学习入门 (十) - 对象识别 Faster-RCNN - 识别人脸位置与是否戴口罩 (二)
根据特征识别分类
接下来就是根据特征识别分类了🥳,处理上与之前的 Fast-RCNN 基本上相同,除了 Faster-RCNN 在生成范围调整参数的时候会针对每个分类分别生成,如果有 5 个分类,那么就会有 5 * 4 = 20 个输出,这会让范围调整变得更准确。
标签分类网络的具体实现架构如下,最终会输出包含对象的范围与各个范围对应的分类,整个 Faster-RCNN 的处理就到此为止了😤。
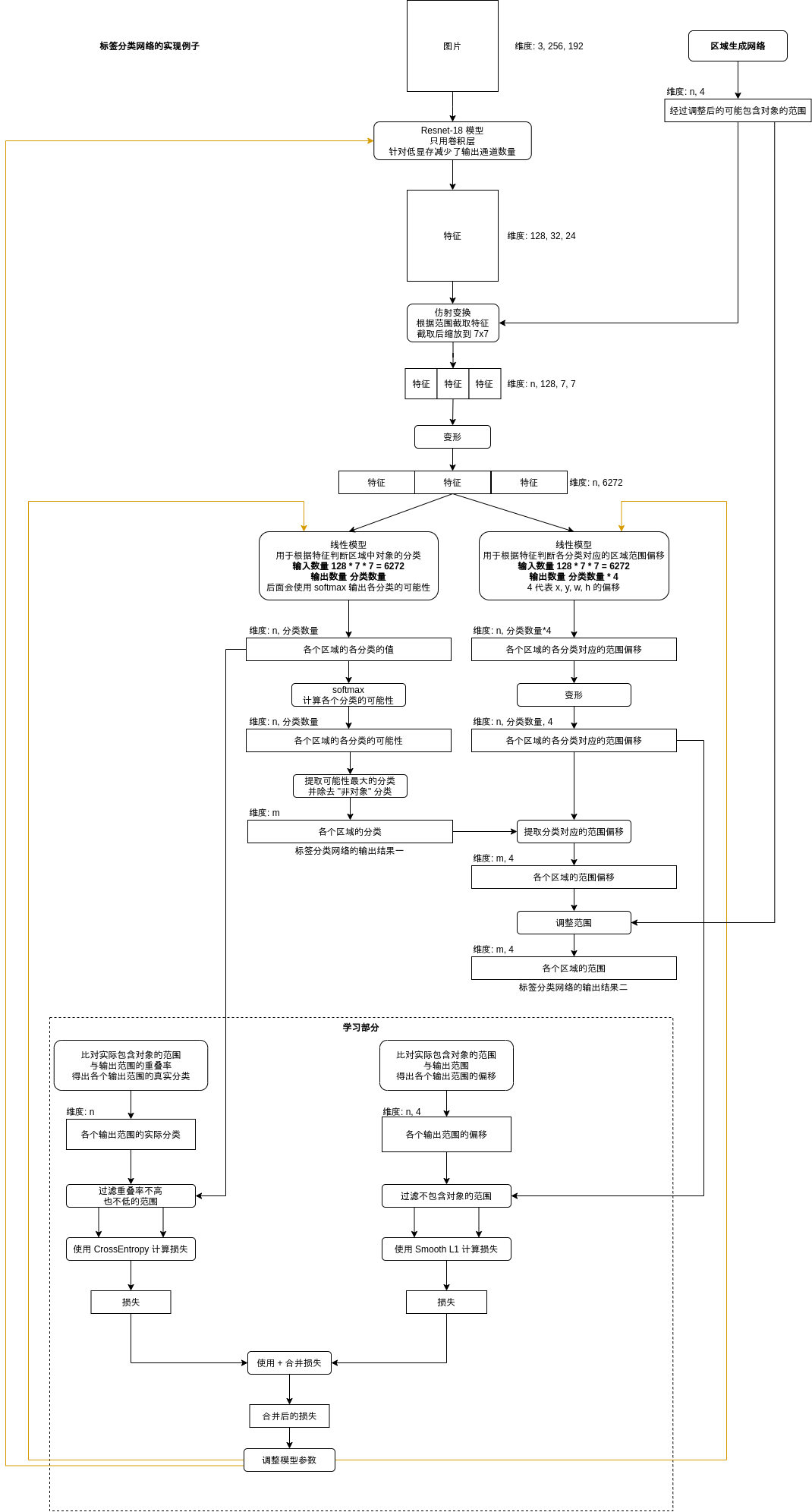
有一点需要注意的是,标签分类网络使用的分类需要额外包含一个 "非对象" 分类,例如原有分类列表为 [戴口罩人脸,不戴口罩人脸] 时,实际判断分类列表应该为 [非人脸, 戴口罩人脸,不戴口罩人脸]。这是因为标签分类网络的特征截取范围比区域生成网络要大,范围也更准确,标签范围网络可以根据更准确的特征来排除那些区域生成网络以为是对象但实际不是对象的范围。
计算损失
到此为止我们看到了以下的损失:
- 区域生成网络判断是否对象的损失
- 区域生成网络的范围调整参数的损失 (仅针对是对象的范围计算)
- 标签分类网络判断对象所属分类的损失
- 标签分类网络的范围调整参数的损失 (仅针对是对象,并且可能性最大的分类计算)
这些损失可以通过 + 合并,然后再通过 backward 反馈到各个网络的 CNN 模型与线性模型。需要注意的是,在批量训练的时候因为各个图片的输出范围数量不一样,上面的损失会先根据各张图片计算后再平均。你可能记得上一篇 Fast-RCNN 计算损失的时候需要根据正负样本分别计算,这一篇不需要,Faster-RCNN 的区域生成网络输出的范围比较准确,很少会出现来源特征相同但同时输出 "是对象" 和 "非对象" 结果的情况。此外,如前文所提到的,区域生成网络与标签分类网络应该使用不同的 CNN 模型生成不同的特征,以避免通过损失调整模型参数时发生干扰。
计算范围调整损失的时候用的是 Smooth L1 函数,这个函数我们之前没有看到过,所以我再简单介绍一下它的计算方法:

简单的来说就是如果预测输出和实际输出之间的差距比较小的时候,反过来增加损失使得调整速度更快,因为区域范围偏移需要让预测输出在数值上更接近实际输出 (不像标签分类可以只调整方向不管具体值),使用 Smooth L1 调整起来效果会更好。
合并结果区域
Faster-RCNN 可能会针对同一个对象输出多个重合的范围,但因为 Faster-RCNN 的精确度比较高,这些重合的范围的重叠率应该也比较高,我们可以结合这些范围得出结果范围:
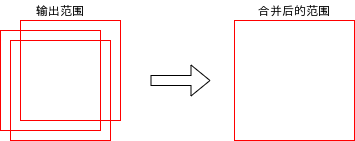
好了,对 Faster-RCNN 的介绍就到此为止了🤗,接下来我们看看代码实现吧。
使用 Faster-RCNN 识别人脸位置与是否戴口罩
这次的任务是识别图片中人脸的位置,与判断是否有正确佩戴口罩,一共有以下的分类:
- 非人脸: other
- 戴口罩: with_mask
- 没戴口罩: without_mask
- 戴了口罩但姿势不正确: mask_weared_incorrect
训练使用的数据也是来源于 kaggle,下载需要注册帐号但不用给钱:
https://www.kaggle.com/andrewmvd/face-mask-detection
例如下面这张图片:

如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 129
- 统信桌面专业版【全盘安装UOS系统】介绍 128
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 119
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 108
- 麒麟系统连接打印机常见问题及解决方法 22
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
