写给程序员的机器学习入门 (十) - 对象识别 Faster-RCNN - 识别人脸位置与是否戴口罩 (一)
RCNN, Fast-RCNN 的弱点
我在上一篇文章介绍了对象识别使用的 RCNN, Fast-RCNN 模型,在这里我简单总结一下它们的缺点,Faster-RCNN 将会克服它们:
- 选取区域使用的算法是固定的,不参与学习
- 选取区域的算法本身消耗比较高 (搜索选择法)
- 选取区域的算法选出来的区域大部分都是重合的,并且只有很小一部分包含我们想要识别的对象
- 区域范围的精度比较低 (即使经过调整)
- 判断分类有时只能使用部分包含对象的区域 (例如选取区域的算法给出左半张脸所在的区域,那么就只能使用左半张脸判断分类)
Faster-RCNN 概览
Faster-RCNN 是 RCNN 和 Fast-RCNN 的进化版,最大的特征是引入了区域生成网络 (RPN - Region Proposal Network),区域生成网络支持使用机器学习代替固定的算法找出图片中可能包含对象的区域,精度比固定的算法要高很多,而且速度也变快了。
Faster-RCNN 的结构如下图所示,分成了两大部分,第一部分是区域生成网络,首先会把图片划分为多个小区域 (大小依赖于图片大小和 CNN 网络结构,详细会在后面说明),每个小区域都对应一个锚点 (Anchor),区域生成网络会判断锚点所在的区域是否包含对象,与包含的对象的形状 (例如只包含鼻子,就大约可以估计周围的几个区域是脸);第二部分是标签分类网络,与上一篇文章介绍的 Fast-RCNN 基本上相同,会根据区域生成网络的输出截取特征,并根据特征判断属于什么分类。
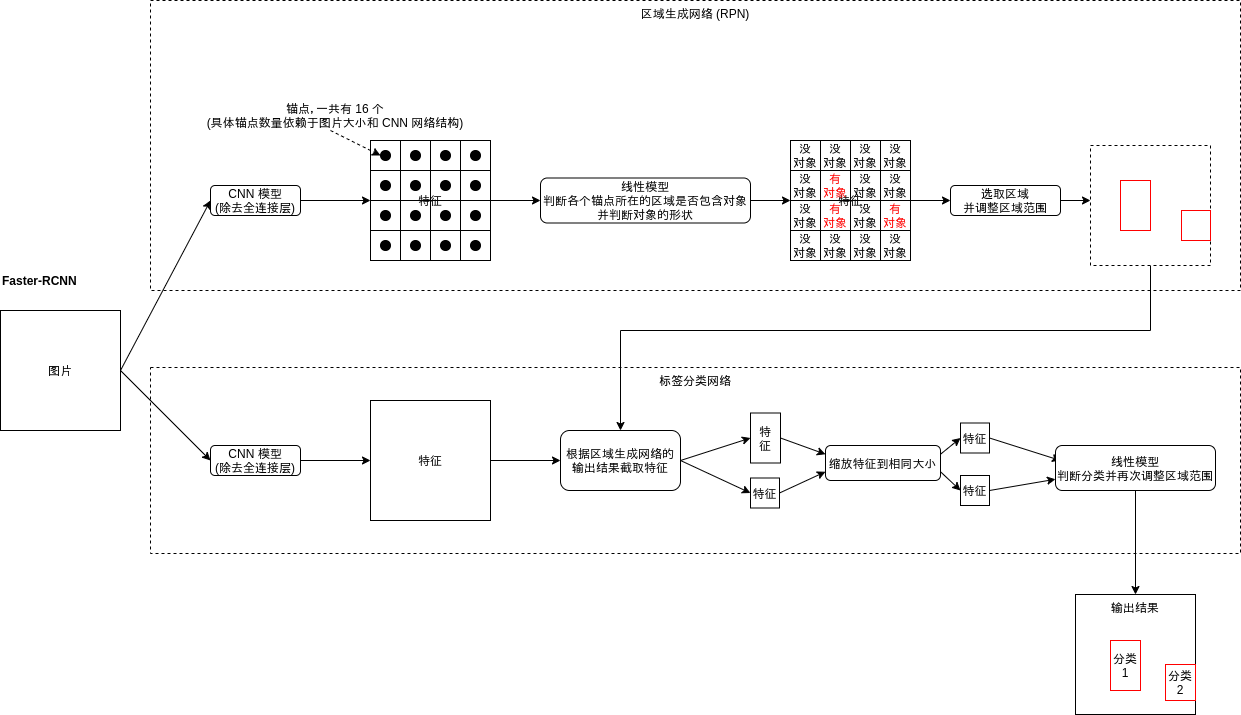
因为区域生成网络可以参与学习,我们可以定制一个只识别某几种对象的网络,例如图片中有人,狗,车,树,房子的时候,固定的算法可能会把他们全部提取出来,但区域生成网络经过训练可以只提取人所在的区域,其他对象所在的区域都会当作背景处理,这样区域生成网络输出的区域数量将会少很多,而且包含对象的可能性会很高。
Faster-RCNN 另一个比较强大的特征是会分两步来识别区域是否包含对象与调整区域范围,第一步在区域生成网络,第二步在标签分类网络。举一个通俗的例子,如果区域生成网络选取了某个包含了脸的左半部分的区域,它会判断这个区域可能包含对象,并且要求区域范围向右扩大一些,接下来标签分类网络会截取范围扩大之后的区域,这个区域会同时包含脸的左半部分和右半部分,也就是截取出来的特征会包含更多的信息,这时标签分类网络可以使用特征进一步判断这张脸所属的分类,如果范围扩大以后发现这不是一张脸而是别的什么东西那么区域分类网络会输出 "非对象" 的分类排除这个区域,如果判断是脸那么标签分类网络会进一步的调整区域范围,使得范围更精准。而 Fast-RCNN 遇到同样的情况只能根据脸的左半部分对应的特征判断分类,信息量不足可能会导致结果不准确。这种做法使得 Faster-RCNN 的识别精度相对于之前的模型提升了很多。
接下来看看 Faster-RCNN 的实现细节吧,部分内容有一定难度🤕,如果觉得难以理解可以先跳过去后面再参考代码实现。
Faster-RCNN 的原始论文在这里,有兴趣的可以看看😈。
Faster-RCNN 的实现
这篇给出的代码会使用 Pillow 类库实现,代替之前的 opencv,所以部分处理相同的步骤也会给出新的代码例子。
缩放来源图片
和 Fast-RCNN 一样,Faster-RCNN 也会使用 CNN 模型针对整张图片生成各个区域的特征,所以我们需要缩放原图片。(尽管 CNN 模型支持非固定大小的来源,但统一大小可以让后续的处理更简单,并且也可以批量处理大小不一样的图片。)
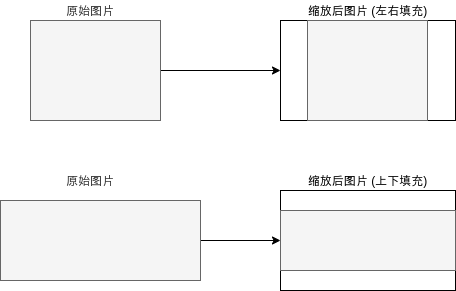
这篇文章会使用 Pillow 代替 opencv,缩放图片的代码如下所示:
# 缩放图片的大小
IMAGE_SIZE = (256, 192)
def calc_resize_parameters(sw, sh):
"""计算缩放图片的参数"""
sw_new, sh_new = sw, sh
dw, dh = IMAGE_SIZE
pad_w, pad_h = 0, 0
if sw / sh < dw / dh:
sw_new = int(dw / dh * sh)
pad_w = (sw_new - sw) // 2 # 填充左右
else:
sh_new = int(dh / dw * sw)
pad_h = (sh_new - sh) // 2 # 填充上下
return sw_new, sh_new, pad_w, pad_h
def resize_image(img):
"""缩放图片,比例不一致时填充"""
sw, sh = img.size
sw_new, sh_new, pad_w, pad_h = calc_resize_parameters(sw, sh)
img_new = Image.new("RGB", (sw_new, sh_new))
img_new.paste(img, (pad_w, pad_h))
img_new = img_new.resize(IMAGE_SIZE)
return img_new
计算区域特征
与 Fast-RCNN 一样,Faster-RCNN 计算区域特征的时候也会使用除去全连接层的 CNN 模型,例如 Resnet-18 模型在原图大小为 3,256,256 的时候 (3 代表 RGB 三通道)会输出 512,32,32 的矩阵,通道数量变多,长宽变为原有的 1/8,也就是每个 8x8 的区域经过处理以后都对应 512 个特征,如下图所示:
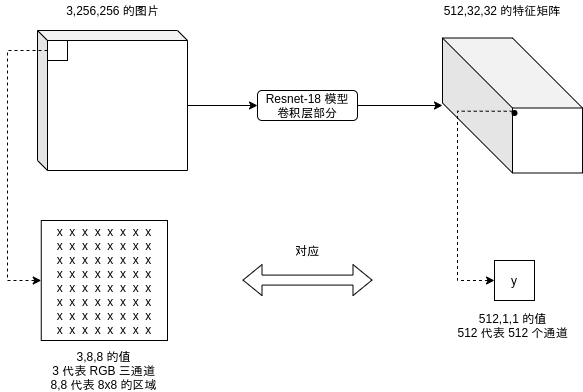
对 CNN 模型不熟悉的可以复习这个系列的第八篇文章,详细介绍了 Resnet-18 的结构与计算流程。
上一篇文章的 Fast-RCNN 例子改动了 Resnet 模型使得输出的特征矩阵长宽与原图相同,以方便后面提取特征 (ROI Pooling) 的处理,这篇将不需要这么做,这篇使用的模型会输出长宽为原有的 1/8 的特征矩阵,但为了适应显存比较低的机器会减少输出的通道数量,具体请参考后面的实现代码。
定义锚点 (Anchor)
Faster-RCNN 的区域生成网络会基于锚点 (Anchor) 判断某个区域是否包含对象,与对象相对于锚点的形状。锚点对应的区域大小其实就是上面特征矩阵中每个点对应的区域大小,如下图所示:
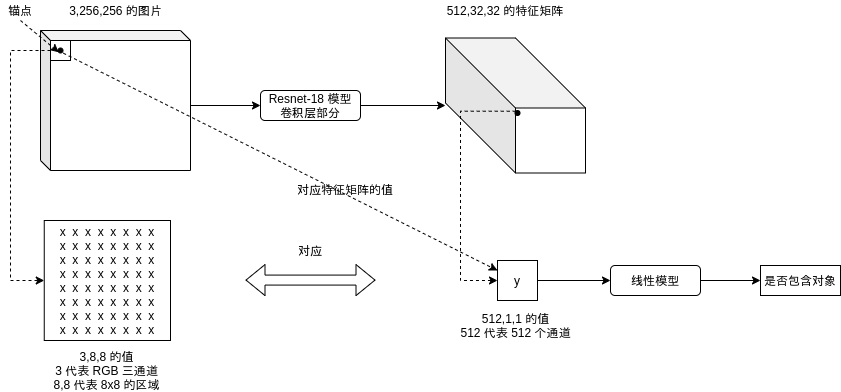
上面的例子中应该有 32x32 个锚点,每个锚点对应 512,1,1 的值。
之后各个锚点对应的值会交给线性模型,判断锚点所在的区域是否包含对象,如下图所示 (为了简化这张图用了 4x4 个锚点,红色的锚点代表包含对象):
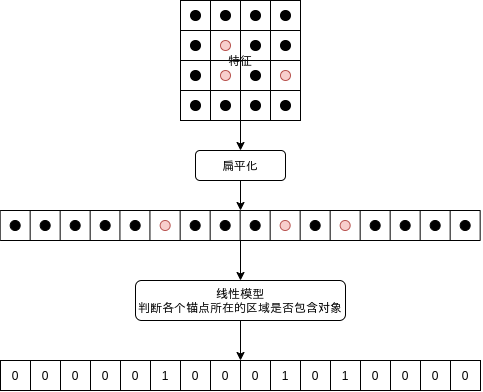
当然的,锚点所在的区域与对象实际所在的区域范围并不会完全一样,锚点所在的区域可能只包含对象的左半部分,右半部分,或者中心部分,对象可能比锚点所在区域大很多,也可能比锚点所在区域小,只判断锚点所在的区域是否包含对象并不够准确。
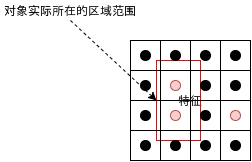
为了解决这个问题,Faster-RCNN 的区域生成网络为每个锚点定义了几个固定的形状,形状有两个参数,一个是大小比例,一个是长宽比例,如下图所示,对比上面的实际区域可以发现形状 6 和形状 7 的重叠率 (IOU) 是比较高的:
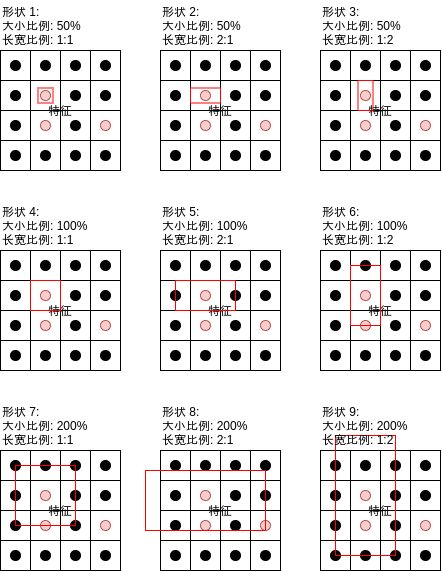
之后区域生成网络的线性模型可以分别判断各个形状是否包含对象:
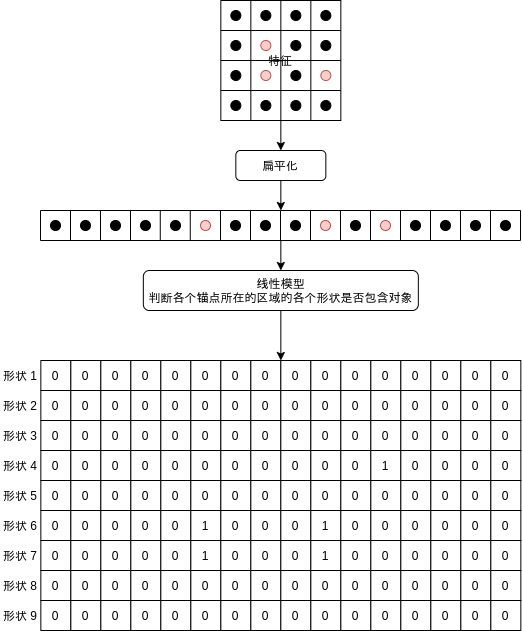
再输出各个形状对应的范围调整值,即可给出可能包含对象的区域。在上述的例子中,如果区域生成网络学习得当,形状 6 和形状 7 经过区域范围调整以后应该会输出很接近的区域。
需要注意的是,虽然锚点支持判断比自己对应的区域更大的范围是否包含对象,但判断的依据只来源于自己对应的区域。举例来说如果锚点对应的区域只包含鼻子,那么它可以判断形状 7 可能包含对象,之后再交给标签分类网络作进一步判断。如果扩大以后发现其实不是人脸,而是别的什么东西,那么标签分类网络将会输出 "非对象" 标签来排除这个区域,如前文介绍的一样。
生成锚点的代码如下,每个锚点会对应 7 * 3 = 21 个形状,span 代表 原图片长宽 / CNN 模型输出长宽:
# 缩放图片的大小
IMAGE_SIZE = (256, 192)
# 锚点对应区域的缩放比例列表
AnchorScales = (0.5, 1, 2, 3, 4, 5, 6)
# 锚点对应区域的长宽比例列表
AnchorAspects = ((1, 2), (1, 1), (2, 1))
def generate_anchors(span):
"""根据锚点和形状生成锚点范围列表"""
w, h = IMAGE_SIZE
anchors = []
for x in range(0, w, span):
for y in range(0, h, span):
xcenter, ycenter = x + span / 2, y + span / 2
for scale in AnchorScales:
for ratio in AnchorAspects:
ww = span * scale * ratio[0]
hh = span * scale * ratio[1]
xx = xcenter - ww / 2
yy = ycenter - hh / 2
xx = max(int(xx), 0)
yy = max(int(yy), 0)
ww = min(int(ww), w - xx)
hh = min(int(hh), h - yy)
anchors.append((xx, yy, ww, hh))
return anchors
Anchors = generate_anchors(8)
区域生成网络 (RPN)
看完上一段关于锚点的定义你应该对区域生成网络的工作方式有个大概的印象,这里我再给出区域生成网络的具体实现架构,这个架构跟后面的代码例子相同。
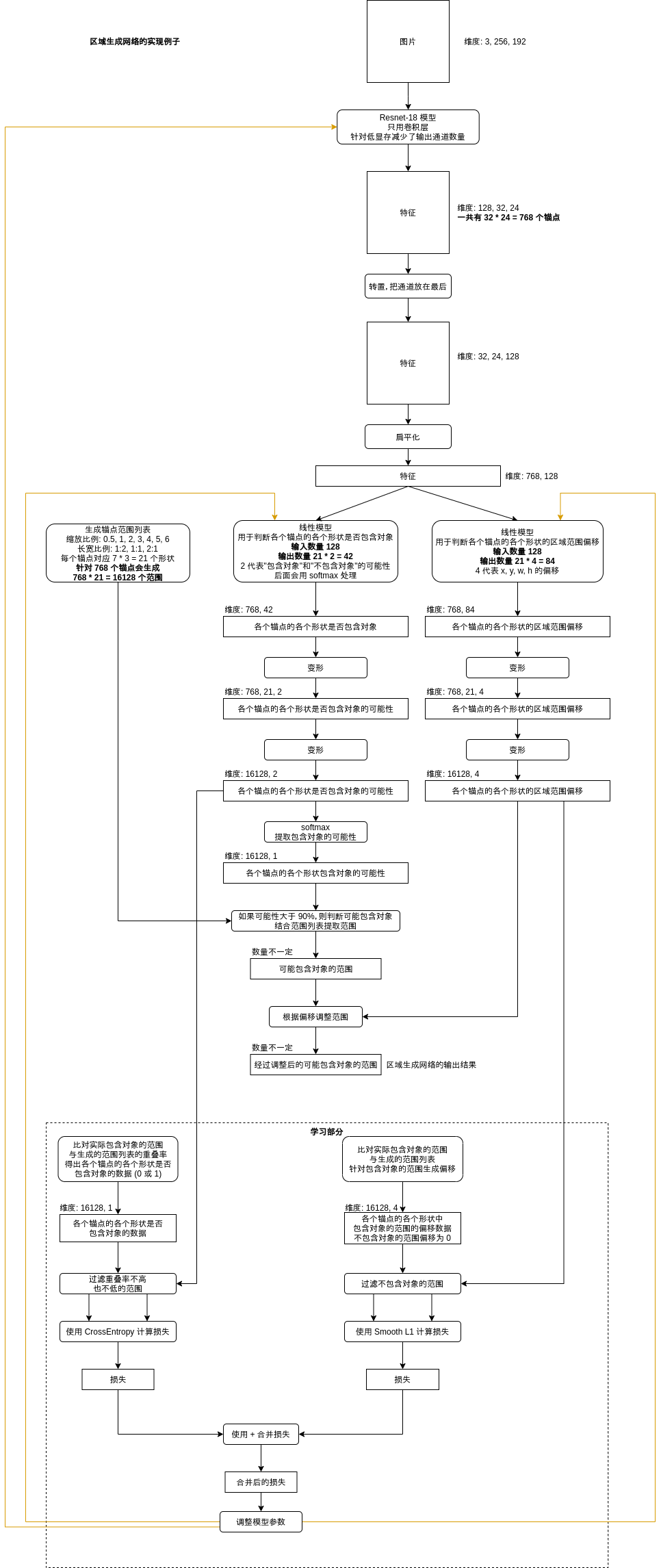
区域生成网络的处理本身应该不需要多解释了🤒,如果觉得难以理解请重新阅读这一篇前面的部分和上一篇文章,特别是上一篇文章的以下部分:
- 按重叠率 (IOU) 判断每个区域是否包含对象
- 调整区域范围
计算区域范围偏移的损失这里使用了 Smooth L1 (上一篇是 MSELoss),具体的计算方法会在后面计算损失的部分介绍。
区域生成网络最终会输出不定数量的可能包含对象的区域,接下来就是提取这些区域对应的特征了,注意区域生成网络使用的特征和标签分类网络使用的特征需要分开,很多文章或者实现介绍 Faster-RCNN 的时候都让两个网络使用相同的特征,但经过我实测使用相同的特征会在调整参数的时候发生干扰导致无法学习,与上一篇文章正负样本的损失需要分开计算的原因一样。部分实现的确使用了相同的特征,但这些实现调整参数使用的 backward 是自己手写的,可能这里有什么秘密吧🥺。
从区域提取特征 - 仿射变换 (ROI Pooling - Affine Transformation)
上一篇介绍的 Fast-RCNN 在生成特征的时候让长宽与原图片相同,所以 ROI 层提取特征只需要使用 [] 操作符,但这一篇生成特征的时候长宽变为了原来的 1/8,那么需要怎样提取特征呢?
最简单的方法是把坐标和长宽除以 8 再使用 [] 操作符提取,然后使用 AdaptiveMaxPool 缩放到固定的大小。但这里我要介绍一个更高级的方法,即仿射变换 (Affine Transformation),使用仿射变换可以非常高效的对图片进行批量截取、缩放与旋转等操作。
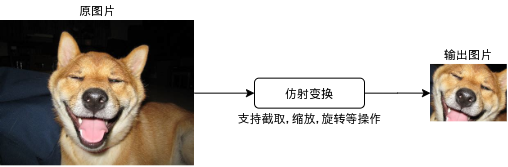
仿射变换的原理是给原图片和输出图片之间的像素坐标建立对应关系,一共有 6 个参数,其中 4 个参数用于给坐标做矩阵乘法 (支持缩放与旋转等变形操作),2 个参数用于做完矩阵乘法以后相加 (支持平移等操作),计算公式如下:

需要注意的是,仿射变换里面不会直接计算坐标的绝对值,而是把图片的左上角当作 (-1, -1),右下角当作 (1, 1) 然后转换坐标到这个尺度里面,再进行计算。
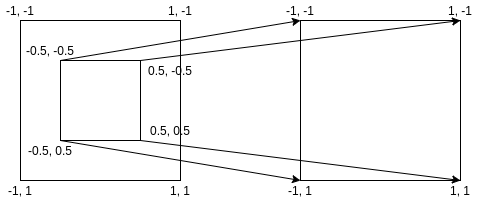
举例来说,如果想把原图片的中心部分放大两倍到输出图片,可以使用以下参数:
0.5, 0, 0
0, 0.5, 0
效果如下,如果你拿输出图片的四个角的坐标结合上面的参数计算,可以得出原图中心部分的范围:
更多例子可以参考这篇文章,对理解仿射变换非常有帮助。
那么从区域提取特征的时候,应该使用怎样的参数呢?计算参数的公式推导过程如下😫:
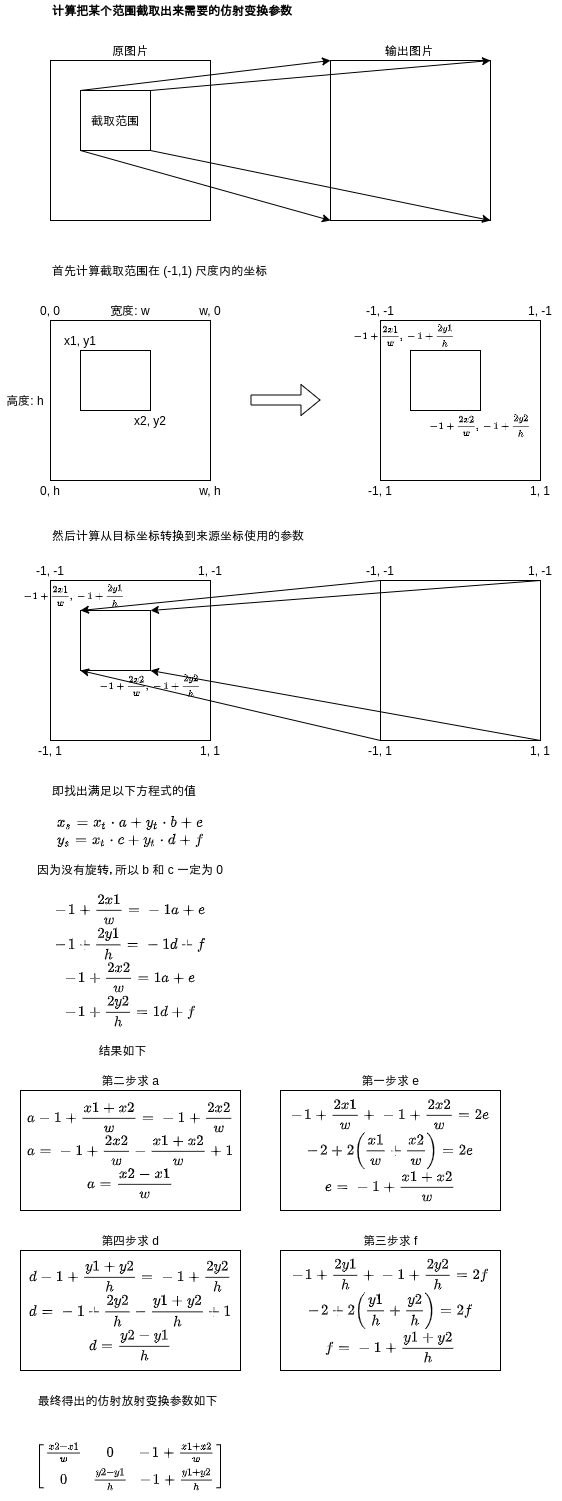
使用 pytorch 实现如下,注意 pytorch 的仿射变换要求数据维度是 (C, H, W),而我们使用的数据维度是 (C, W, H),所以需要调换参数的位置,pooling_size 代表输出图片的大小,这样仿射变换不仅可以截取范围还能帮我们缩放到指定的大小:
# 缩放图片的大小
IMAGE_SIZE = (256, 192)
def roi_crop(features, rois, pooling_size):
"""根据区域截取特征,每次只能处理单张图片"""
width, height = IMAGE_SIZE
theta = []
results = []
for roi in rois:
x1, y1, w, h = roi
x2, y2 = x1 + w, y1 + h
theta = [[
[
(y2 - y1) / height,
0,
(y2 + y1) / height - 1
],
[
0,
(x2 - x1) / width,
(x2 + x1) / width - 1
]
]]
theta_tensor = torch.tensor(theta)
grid = nn.functional.affine_grid(
theta_tensor,
torch.Size((1, 1, pooling_size, pooling_size)),
align_corners=False).to(device)
result = nn.functional.grid_sample(
features.unsqueeze(0), grid, align_corners=False)
results.append(result)
if not results:
return None
results = torch.cat(results, dim=0)
return results
如果 pooling_size 为 7,那么 results 的维度就是 范围的数量, 7, 7。
仿射变换本来是用在 STN 网络里的,用于把旋转变形以后的图片还原。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 129
- 统信桌面专业版【全盘安装UOS系统】介绍 128
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 119
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 108
- 麒麟系统连接打印机常见问题及解决方法 23
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
