写给程序员的机器学习入门 (九) - 对象识别 RCNN 与 Fast-RCNN (三)
计算损失
Fast-RCNN 模型会针对各个区域输出两个结果,第一个是区域对应的标签 (人脸,非人脸),第二个是上面提到的区域偏移,调整参数的时候也需要同时根据这两个结果调整。实现同时调整多个结果可以把损失相加起来再计算各个参数的导函数值:
各个区域的特征 = ROI层(CNN模型(图片数据))
计算标签的线性模型(各个区域的特征) - 真实标签 = 标签损失
计算偏移的线性模型(各个区域的特征) - 真实偏移 = 偏移损失
损失 = 标签损失 + 偏移损失
有一个需要注意的地方是,在这个例子里计算标签损失需要分别根据正负样本计算,否则模型在经过调整以后只会输出负结果。这是因为线性模型计算抽取出来的特征时有可能输出正 (人脸),也有可能输出负 (非人脸),而 ROI 层抽取的特征很多是重合的,也就是来源相同,当负样本比正样本要多的时候,结果的方向就会更偏向于负,这样每次调整参数的时候都会向输出负的方向调整。如果把损失分开计算,那么不重合的特征可以分别向输出正负的方向调整,从而达到学习的效果。
此外,偏移损失只应该根据正样本计算,负样本没有必要学习偏移。
最终的损失计算处理如下:
各个区域的特征 = ROI层(CNN模型(图片数据))
计算标签的线性模型(各个区域的特征)[正样本] - 真实标签[正样本] = 正样本标签损失
计算标签的线性模型(各个区域的特征)[负样本] - 真实标签[负样本] = 负样本标签损失
计算偏移的线性模型(各个区域的特征)[正样本] - 真实偏移[正样本] = 正样本偏移损失
损失 = 正样本标签损失 + 负样本标签损失 + 正样本偏移损失
合并结果区域
因为选取区域的算法本来就会返回很多重合的区域,可能会有有好几个区域同时和真实区域重叠率大于一定值 (70%),导致这几个区域都会被认为是包含对象的区域:
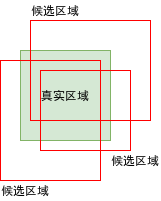
模型经过学习后,针对图片预测得出结果时也有可能返回这样的重合区域,合并这样的区域有几种方法:
- 使用最左,最右,最上,或者最下的区域
- 使用第一个区域 (区域选取算法会按出现对象的可能性排序)
- 结合所有重合的区域 (如果区域调整效果不行,则可能出现结果区域比真实区域大很多的问题)
上面给出的 RCNN 代码例子已经使用第二个方法合并结果区域,下面给出的例子也会使用同样的方法。但下一篇文章的 Faster-RCNN 则会使用第三个方法,因为 Faster-RCNN 的区域调整效果相对比较好。
原始论文
如果你想看 Fast-RCNN 的原始论文可以到以下的地址:
https://arxiv.org/pdf/1504.08083.pdf
使用 Fast-RCNN 识别图片中的人脸
代码时间到了😱,这份代码会使用 Fast-RCNN 模型来图片中的人脸,使用的数据集和前面的例子一样。
import os
import sys
import torch
import gzip
import itertools
import random
import numpy
import math
import pandas
import cv2
from torch import nn
from matplotlib import pyplot
from collections import defaultdict
# 缩放图片的大小
IMAGE_SIZE = (256, 256)
# 分析目标的图片所在的文件夹
IMAGE_DIR = "./784145_1347673_bundle_archive/train/image_data"
# 定义各个图片中人脸区域的 CSV 文件
BOX_CSV_PATH = "./784145_1347673_bundle_archive/train/bbox_train.csv"
# 用于启用 GPU 支持
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class BasicBlock(nn.Module):
"""ResNet 使用的基础块"""
expansion = 1 # 定义这个块的实际出通道是 channels_out 的几倍,这里的实现固定是一倍
def __init__(self, channels_in, channels_out, stride):
super().__init__()
# 生成 3x3 的卷积层
# 处理间隔 stride = 1 时,输出的长宽会等于输入的长宽,例如 (32-3+2)//1+1 == 32
# 处理间隔 stride = 2 时,输出的长宽会等于输入的长宽的一半,例如 (32-3+2)//2+1 == 16
# 此外 resnet 的 3x3 卷积层不使用偏移值 bias
self.conv1 = nn.Sequential(
nn.Conv2d(channels_in, channels_out, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(channels_out))
# 再定义一个让输出和输入维度相同的 3x3 卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(channels_out, channels_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(channels_out))
# 让原始输入和输出相加的时候,需要维度一致,如果维度不一致则需要整合
self.identity = nn.Sequential()
if stride != 1 or channels_in != channels_out * self.expansion:
self.identity = nn.Sequential(
nn.Conv2d(channels_in, channels_out * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels_out * self.expansion))
def forward(self, x):
# x => conv1 => relu => conv2 => + => relu
# | ^
# |==============================|
tmp = self.conv1(x)
tmp = nn.functional.relu(tmp, inplace=True)
tmp = self.conv2(tmp)
tmp += self.identity(x)
y = nn.functional.relu(tmp, inplace=True)
return y
class MyModel(nn.Module):
"""Fast-RCNN (基于 ResNet-18 的变种)"""
def __init__(self):
super().__init__()
# 记录上一层的出通道数量
self.previous_channels_out = 4
# 把 3 通道转换到 4 通道,长宽不变
self.conv1 = nn.Sequential(
nn.Conv2d(3, self.previous_channels_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.previous_channels_out))
# 抽取图片各个区域特征的 ResNet (除去 AvgPool 和全连接层)
# 和原始的 Resnet 不一样的是输出的长宽和输入的长宽会相等,以便 ROI 层按区域抽取R征
# 此外,为了可以让模型跑在 4GB 显存上,这里减少了模型的通道数量
self.layer1 = self._make_layer(BasicBlock, channels_out=4, num_blocks=2, stride=1)
self.layer2 = self._make_layer(BasicBlock, channels_out=4, num_blocks=2, stride=1)
self.layer3 = self._make_layer(BasicBlock, channels_out=8, num_blocks=2, stride=1)
self.layer4 = self._make_layer(BasicBlock, channels_out=8, num_blocks=2, stride=1)
# ROI 层抽取各个子区域特征后转换到固定大小
self.roi_pool = nn.AdaptiveMaxPool2d((5, 5))
# 输出两个分类 [非人脸, 人脸]
self.fc_labels_model = nn.Sequential(
nn.Linear(8*5*5, 32),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(32, 2))
# 计算区域偏移,分别输出 x, y, w, h 的偏移
self.fc_offsets_model = nn.Sequential(
nn.Linear(8*5*5, 128),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(128, 4))
def _make_layer(self, block_type, channels_out, num_blocks, stride):
blocks = []
# 添加第一个块
blocks.append(block_type(self.previous_channels_out, channels_out, stride))
self.previous_channels_out = channels_out * block_type.expansion
# 添加剩余的块,剩余的块固定处理间隔为 1,不会改变长宽
for _ in range(num_blocks-1):
blocks.append(block_type(self.previous_channels_out, self.previous_channels_out, 1))
self.previous_channels_out *= block_type.expansion
return nn.Sequential(*blocks)
def _roi_pooling(self, feature_mapping, roi_boxes):
result = []
for box in roi_boxes:
image_index, x, y, w, h = map(int, box.tolist())
feature_sub_region = feature_mapping[image_index][:,x:x+w,y:y+h]
fixed_features = self.roi_pool(feature_sub_region).reshape(-1) # 顺道扁平化
result.append(fixed_features)
return torch.stack(result)
def forward(self, x):
images_tensor = x[0]
candidate_boxes_tensor = x[1]
# 转换出通道
tmp = self.conv1(images_tensor)
tmp = nn.functional.relu(tmp)
# 应用 ResNet 的各个层
# 结果维度是 B,32,W,H
tmp = self.layer1(tmp)
tmp = self.layer2(tmp)
tmp = self.layer3(tmp)
tmp = self.layer4(tmp)
# 使用 ROI 层抽取各个子区域的特征并转换到固定大小
# 结果维度是 B,32*9*9
tmp = self._roi_pooling(tmp, candidate_boxes_tensor)
# 根据抽取出来的子区域特征分别计算分类 (是否人脸) 和区域偏移
labels = self.fc_labels_model(tmp)
offsets = self.fc_offsets_model(tmp)
y = (labels, offsets)
return y
def save_tensor(tensor, path):
"""保存 tensor 对象到文件"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""从文件读取 tensor 对象"""
return torch.load(gzip.GzipFile(path, "rb"))
def calc_resize_parameters(sw, sh):
"""计算缩放图片的参数"""
sw_new, sh_new = sw, sh
dw, dh = IMAGE_SIZE
pad_w, pad_h = 0, 0
if sw / sh < dw / dh:
sw_new = int(dw / dh * sh)
pad_w = (sw_new - sw) // 2 # 填充左右
else:
sh_new = int(dh / dw * sw)
pad_h = (sh_new - sh) // 2 # 填充上下
return sw_new, sh_new, pad_w, pad_h
def resize_image(img):
"""缩放 opencv 图片,比例不一致时填充"""
sh, sw, _ = img.shape
sw_new, sh_new, pad_w, pad_h = calc_resize_parameters(sw, sh)
img = cv2.copyMakeBorder(img, pad_h, pad_h, pad_w, pad_w, cv2.BORDER_CONSTANT, (0, 0, 0))
img = cv2.resize(img, dsize=IMAGE_SIZE)
return img
def image_to_tensor(img):
"""转换 opencv 图片对象到 tensor 对象"""
# 注意 opencv 是 BGR,但对训练没有影响所以不用转为 RGB
arr = numpy.asarray(img)
t = torch.from_numpy(arr)
t = t.transpose(0, 2) # 转换维度 H,W,C 到 C,W,H
t = t / 255.0 # 正规化数值使得范围在 0 ~ 1
return t
def map_box_to_resized_image(box, sw, sh):
"""把原始区域转换到缩放后的图片对应的区域"""
x, y, w, h = box
sw_new, sh_new, pad_w, pad_h = calc_resize_parameters(sw, sh)
scale = IMAGE_SIZE[0] / sw_new
x = int((x + pad_w) * scale)
y = int((y + pad_h) * scale)
w = int(w * scale)
h = int(h * scale)
if x + w > IMAGE_SIZE[0] or y + h > IMAGE_SIZE[1] or w == 0 or h == 0:
return 0, 0, 0, 0
return x, y, w, h
def map_box_to_original_image(box, sw, sh):
"""把缩放后图片对应的区域转换到缩放前的原始区域"""
x, y, w, h = box
sw_new, sh_new, pad_w, pad_h = calc_resize_parameters(sw, sh)
scale = IMAGE_SIZE[0] / sw_new
x = int(x / scale - pad_w)
y = int(y / scale - pad_h)
w = int(w / scale)
h = int(h / scale)
if x + w > sw or y + h > sh or x < 0 or y < 0 or w == 0 or h == 0:
return 0, 0, 0, 0
return x, y, w, h
def calc_iou(rect1, rect2):
"""计算两个区域重叠部分 / 合并部分的比率 (intersection over union)"""
x1, y1, w1, h1 = rect1
x2, y2, w2, h2 = rect2
xi = max(x1, x2)
yi = max(y1, y2)
wi = min(x1+w1, x2+w2) - xi
hi = min(y1+h1, y2+h2) - yi
if wi > 0 and hi > 0: # 有重叠部分
area_overlap = wi*hi
area_all = w1*h1 + w2*h2 - area_overlap
iou = area_overlap / area_all
else: # 没有重叠部分
iou = 0
return iou
def calc_box_offset(candidate_box, true_box):
"""计算候选区域与实际区域的偏移值"""
# 这里计算出来的偏移值基于比例,而不受具体位置和大小影响
# w h 使用 log 是为了减少过大的值的影响
x1, y1, w1, h1 = candidate_box
x2, y2, w2, h2 = true_box
x_offset = (x2 - x1) / w1
y_offset = (y2 - y1) / h1
w_offset = math.log(w2 / w1)
h_offset = math.log(h2 / h1)
return (x_offset, y_offset, w_offset, h_offset)
def adjust_box_by_offset(candidate_box, offset):
"""根据偏移值调整候选区域"""
x1, y1, w1, h1 = candidate_box
x_offset, y_offset, w_offset, h_offset = offset
x2 = w1 * x_offset + x1
y2 = h1 * y_offset + y1
w2 = math.exp(w_offset) * w1
h2 = math.exp(h_offset) * h1
return (x2, y2, w2, h2)
def selective_search(img):
"""计算 opencv 图片中可能出现对象的区域,只返回头 2000 个区域"""
# 算法参考 https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/
s = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
s.setBaseImage(img)
s.switchToSelectiveSearchFast()
boxes = s.process()
return boxes[:2000]
def prepare_save_batch(batch, image_tensors, image_candidate_boxes, image_labels, image_box_offsets):
"""准备训练 - 保存单个批次的数据"""
# 按索引值列表生成输入和输出 tensor 对象的函数
def split_dataset(indices):
image_in = []
candidate_boxes_in = []
labels_out = []
offsets_out = []
for new_image_index, original_image_index in enumerate(indices):
image_in.append(image_tensors[original_image_index])
for box, label, offset in zip(image_candidate_boxes, image_labels, image_box_offsets):
box_image_index, x, y, w, h = box
if box_image_index == original_image_index:
candidate_boxes_in.append((new_image_index, x, y, w, h))
labels_out.append(label)
offsets_out.append(offset)
# 检查计算是否有问题
# for box, label in zip(candidate_boxes_in, labels_out):
# image_index, x, y, w, h = box
# child_img = image_in[image_index][:, x:x+w, y:y+h].transpose(0, 2) * 255
# cv2.imwrite(f"{image_index}_{x}_{y}_{w}_{h}_{label}.png", child_img.numpy())
tensor_image_in = torch.stack(image_in) # 维度: B,C,W,H
tensor_candidate_boxes_in = torch.tensor(candidate_boxes_in, dtype=torch.float) # 维度: N,5 (index, x, y, w, h)
tensor_labels_out = torch.tensor(labels_out, dtype=torch.long) # 维度: N
tensor_box_offsets_out = torch.tensor(offsets_out, dtype=torch.float) # 维度: N,4 (x_offset, y_offset, ..)
return (tensor_image_in, tensor_candidate_boxes_in), (tensor_labels_out, tensor_box_offsets_out)
# 切分训练集 (80%),验证集 (10%) 和测试集 (10%)
random_indices = torch.randperm(len(image_tensors))
training_indices = random_indices[:int(len(random_indices)*0.8)]
validating_indices = random_indices[int(len(random_indices)*0.8):int(len(random_indices)*0.9):]
testing_indices = random_indices[int(len(random_indices)*0.9):]
training_set = split_dataset(training_indices)
validating_set = split_dataset(validating_indices)
testing_set = split_dataset(testing_indices)
# 保存到硬盘
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def prepare():
"""准备训练"""
# 数据集转换到 tensor 以后会保存在 data 文件夹下
if not os.path.isdir("data"):
os.makedirs("data")
# 加载 csv 文件,构建图片到区域列表的索引 { 图片名: [ 区域, 区域, .. ] }
box_map = defaultdict(lambda: [])
df = pandas.read_csv(BOX_CSV_PATH)
for row in df.values:
filename, width, height, x1, y1, x2, y2 = row[:7]
box_map[filename].append((x1, y1, x2-x1, y2-y1))
# 从图片里面提取人脸 (正样本) 和非人脸 (负样本) 的图片
batch_size = 50
max_samples = 10
batch = 0
image_tensors = [] # 图片列表
image_candidate_boxes = [] # 各个图片的候选区域列表
image_labels = [] # 各个图片的候选区域对应的标签 (1 人脸 0 非人脸)
image_box_offsets = [] # 各个图片的候选区域与真实区域的偏移值
for filename, true_boxes in box_map.items():
path = os.path.join(IMAGE_DIR, filename)
img_original = cv2.imread(path) # 加载原始图片
sh, sw, _ = img_original.shape # 原始图片大小
img = resize_image(img_original) # 缩放图片
candidate_boxes = selective_search(img) # 查找候选区域
true_boxes = [ map_box_to_resized_image(b, sw, sh) for b in true_boxes ] # 缩放实际区域
image_index = len(image_tensors) # 图片在批次中的索引值
image_tensors.append(image_to_tensor(img.copy()))
positive_samples = 0
negative_samples = 0
for candidate_box in candidate_boxes:
# 如果候选区域和任意一个实际区域重叠率大于 70%,则认为是正样本
# 如果候选区域和所有实际区域重叠率都小于 30%,则认为是负样本
# 每个图片最多添加正样本数量 + 10 个负样本,需要提供足够多负样本避免伪阳性判断
iou_list = [ calc_iou(candidate_box, true_box) for true_box in true_boxes ]
positive_index = next((index for index, iou in enumerate(iou_list) if iou > 0.70), None)
is_negative = all(iou < 0.30 for iou in iou_list)
result = None
if positive_index is not None:
result = True
positive_samples += 1
elif is_negative and negative_samples < positive_samples + 10:
result = False
negative_samples += 1
if result is not None:
x, y, w, h = candidate_box
# 检验计算是否有问题
# child_img = img[y:y+h, x:x+w].copy()
# cv2.imwrite(f"{filename}_{x}_{y}_{w}_{h}_{int(result)}.png", child_img)
image_candidate_boxes.append((image_index, x, y, w, h))
image_labels.append(int(result))
if positive_index is not None:
image_box_offsets.append(calc_box_offset(
candidate_box, true_boxes[positive_index])) # 正样本添加偏移值
else:
image_box_offsets.append((0, 0, 0, 0)) # 负样本无偏移
if positive_samples >= max_samples:
break
# 保存批次
if len(image_tensors) >= batch_size:
prepare_save_batch(batch, image_tensors, image_candidate_boxes, image_labels, image_box_offsets)
image_tensors.clear()
image_candidate_boxes.clear()
image_labels.clear()
image_box_offsets.clear()
batch += 1
# 保存剩余的批次
if len(image_tensors) > 10:
prepare_save_batch(batch, image_tensors, image_candidate_boxes, image_labels, image_box_offsets)
def train():
"""开始训练"""
# 创建模型实例
model = MyModel().to(device)
# 创建多任务损失计算器
celoss = torch.nn.CrossEntropyLoss()
mseloss = torch.nn.MSELoss()
def loss_function(predicted, actual):
# 标签损失必须根据正负样本分别计算,否则会导致预测结果总是为负的问题
positive_indices = actual[0].nonzero(as_tuple=True)[0] # 正样本的索引值列表
negative_indices = (actual[0] == 0).nonzero(as_tuple=True)[0] # 负样本的索引值列表
loss1 = celoss(predicted[0][positive_indices], actual[0][positive_indices]) # 正样本标签的损失
loss2 = celoss(predicted[0][negative_indices], actual[0][negative_indices]) # 负样本标签的损失
loss3 = mseloss(predicted[1][positive_indices], actual[1][positive_indices]) # 偏移值的损失,仅针对正样本计算
return loss1 + loss2 + loss3
# 创建参数调整器
optimizer = torch.optim.Adam(model.parameters())
# 记录训练集和验证集的正确率变化
training_label_accuracy_history = []
training_offset_accuracy_history = []
validating_label_accuracy_history = []
validating_offset_accuracy_history = []
# 记录最高的验证集正确率
validating_label_accuracy_highest = -1
validating_label_accuracy_highest_epoch = 0
validating_offset_accuracy_highest = -1
validating_offset_accuracy_highest_epoch = 0
# 读取批次的工具函数
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield [ [ tt.to(device) for tt in t ] for t in load_tensor(path) ]
# 计算正确率的工具函数
def calc_accuracy(actual, predicted):
# 标签正确率,正样本和负样本的正确率分别计算再平均
predicted_i = torch.max(predicted[0], 1).indices
acc_positive = ((actual[0] > 0.5) & (predicted_i > 0.5)).sum().item() / ((actual[0] > 0.5).sum().item() + 0.00001)
acc_negative = ((actual[0] <= 0.5) & (predicted_i <= 0.5)).sum().item() / ((actual[0] <= 0.5).sum().item() + 0.00001)
acc_label = (acc_positive + acc_negative) / 2
# print(acc_positive, acc_negative)
# 偏移值正确率
valid_indices = actual[1].nonzero(as_tuple=True)[0]
if valid_indices.shape[0] == 0:
acc_offset = 1
else:
acc_offset = (1 - (predicted[1][valid_indices] - actual[1][valid_indices]).abs().mean()).item()
acc_offset = max(acc_offset, 0)
return acc_label, acc_offset
# 开始训练过程
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
model.train()
training_label_accuracy_list = []
training_offset_accuracy_list = []
for batch_index, batch in enumerate(read_batches("data/training_set")):
# 划分输入和输出
batch_x, batch_y = batch
# 计算预测值
predicted = model(batch_x)
# 计算损失
loss = loss_function(predicted, batch_y)
# 从损失自动微分求导函数值
loss.backward()
# 使用参数调整器调整参数
optimizer.step()
# 清空导函数值
optimizer.zero_grad()
# 记录这一个批次的正确率,torch.no_grad 代表临时禁用自动微分功能
with torch.no_grad():
training_batch_label_accuracy, training_batch_offset_accuracy = calc_accuracy(batch_y, predicted)
# 输出批次正确率
training_label_accuracy_list.append(training_batch_label_accuracy)
training_offset_accuracy_list.append(training_batch_offset_accuracy)
print(f"epoch: {epoch}, batch: {batch_index}: " +
f"batch label accuracy: {training_batch_label_accuracy}, offset accuracy: {training_batch_offset_accuracy}")
training_label_accuracy = sum(training_label_accuracy_list) / len(training_label_accuracy_list)
training_offset_accuracy = sum(training_offset_accuracy_list) / len(training_offset_accuracy_list)
training_label_accuracy_history.append(training_label_accuracy)
training_offset_accuracy_history.append(training_offset_accuracy)
print(f"training label accuracy: {training_label_accuracy}, offset accuracy: {training_offset_accuracy}")
# 检查验证集
model.eval()
validating_label_accuracy_list = []
validating_offset_accuracy_list = []
for batch in read_batches("data/validating_set"):
batch_x, batch_y = batch
predicted = model(batch_x)
validating_batch_label_accuracy, validating_batch_offset_accuracy = calc_accuracy(batch_y, predicted)
validating_label_accuracy_list.append(validating_batch_label_accuracy)
validating_offset_accuracy_list.append(validating_batch_offset_accuracy)
validating_label_accuracy = sum(validating_label_accuracy_list) / len(validating_label_accuracy_list)
validating_offset_accuracy = sum(validating_offset_accuracy_list) / len(validating_offset_accuracy_list)
validating_label_accuracy_history.append(validating_label_accuracy)
validating_offset_accuracy_history.append(validating_offset_accuracy)
print(f"validating label accuracy: {validating_label_accuracy}, offset accuracy: {validating_offset_accuracy}")
# 记录最高的验证集正确率与当时的模型状态,判断是否在 20 次训练后仍然没有刷新记录
if validating_label_accuracy > validating_label_accuracy_highest:
validating_label_accuracy_highest = validating_label_accuracy
validating_label_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest label validating accuracy updated")
elif validating_offset_accuracy > validating_offset_accuracy_highest:
validating_offset_accuracy_highest = validating_offset_accuracy
validating_offset_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest offset validating accuracy updated")
elif (epoch - validating_label_accuracy_highest_epoch > 20 and
epoch - validating_offset_accuracy_highest_epoch > 20):
# 在 20 次训练后仍然没有刷新记录,结束训练
print("stop training because highest validating accuracy not updated in 20 epoches")
break
# 使用达到最高正确率时的模型状态
print(f"highest label validating accuracy: {validating_label_accuracy_highest}",
f"from epoch {validating_label_accuracy_highest_epoch}")
print(f"highest offset validating accuracy: {validating_offset_accuracy_highest}",
f"from epoch {validating_offset_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 检查测试集
testing_label_accuracy_list = []
testing_offset_accuracy_list = []
for batch in read_batches("data/testing_set"):
batch_x, batch_y = batch
predicted = model(batch_x)
testing_batch_label_accuracy, testing_batch_offset_accuracy = calc_accuracy(batch_y, predicted)
testing_label_accuracy_list.append(testing_batch_label_accuracy)
testing_offset_accuracy_list.append(testing_batch_offset_accuracy)
testing_label_accuracy = sum(testing_label_accuracy_list) / len(testing_label_accuracy_list)
testing_offset_accuracy = sum(testing_offset_accuracy_list) / len(testing_offset_accuracy_list)
print(f"testing label accuracy: {testing_label_accuracy}, offset accuracy: {testing_offset_accuracy}")
# 显示训练集和验证集的正确率变化
pyplot.plot(training_label_accuracy_history, label="training_label_accuracy")
pyplot.plot(training_offset_accuracy_history, label="training_offset_accuracy")
pyplot.plot(validating_label_accuracy_history, label="validing_label_accuracy")
pyplot.plot(validating_offset_accuracy_history, label="validing_offset_accuracy")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用训练好的模型"""
# 创建模型实例,加载训练好的状态,然后切换到验证模式
model = MyModel().to(device)
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 询问图片路径,并显示所有可能是人脸的区域
while True:
try:
# 选取可能出现对象的区域一览
image_path = input("Image path: ")
if not image_path:
continue
img_original = cv2.imread(image_path) # 加载原始图片
sh, sw, _ = img_original.shape # 原始图片大小
img = resize_image(img_original) # 缩放图片
candidate_boxes = selective_search(img) # 查找候选区域
# 构建输入
image_tensor = image_to_tensor(img).unsqueeze(dim=0).to(device) # 维度: 1,C,W,H
candidate_boxes_tensor = torch.tensor(
[ (0, x, y, w, h) for x, y, w, h in candidate_boxes ],
dtype=torch.float).to(device) # 维度: N,5
tensor_in = (image_tensor, candidate_boxes_tensor)
# 预测输出
labels, offsets = model(tensor_in)
labels = nn.functional.softmax(labels, dim=1)
labels = labels[:,1].resize(labels.shape[0])
# 判断概率大于 90% 的是人脸,按偏移值调整区域,添加边框到图片并保存
img_output = img_original.copy()
for box, label, offset in zip(candidate_boxes, labels, offsets):
if label.item() <= 0.99:
continue
box = adjust_box_by_offset(box, offset.tolist())
x, y, w, h = map_box_to_original_image(box, sw, sh)
if w == 0 or h == 0:
continue
print(x, y, w, h)
cv2.rectangle(img_output, (x, y), (x+w, y+h), (0, 0, 0xff), 1)
cv2.imwrite("img_output.png", img_output)
print("saved to img_output.png")
print()
except Exception as e:
print("error:", e)
def main():
"""主函数"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 给随机数生成器分配一个初始值,使得每次运行都可以生成相同的随机数
# 这是为了让过程可重现,你也可以选择不这样做
random.seed(0)
torch.random.manual_seed(0)
# 根据命令行参数选择操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
执行以下命令以后:
python3 example.py prepare
python3 example.py train
在 31 轮训练以后的输出如下 (因为训练时间实在长,这里偷懒了🥺):
epoch: 31, batch: 112: batch label accuracy: 0.9805490565092065, offset accuracy: 0.9293316006660461
epoch: 31, batch: 113: batch label accuracy: 0.9776784565994586, offset accuracy: 0.9191392660140991
epoch: 31, batch: 114: batch label accuracy: 0.9469732184008024, offset accuracy: 0.9101274609565735
training label accuracy: 0.9707166603858259, offset accuracy: 0.9191886570142663
validating label accuracy: 0.9306134214845806, offset accuracy: 0.9205827381299889
highest offset validating accuracy updated
执行以下命令,再输入图片路径可以使用学习好的模型识别图片:
python3 example.py eval
以下是部分识别结果:
调整区域前

调整区域后

调整区域前
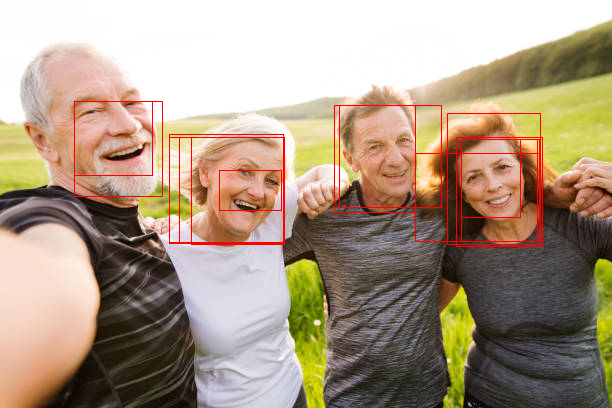
调整区域后
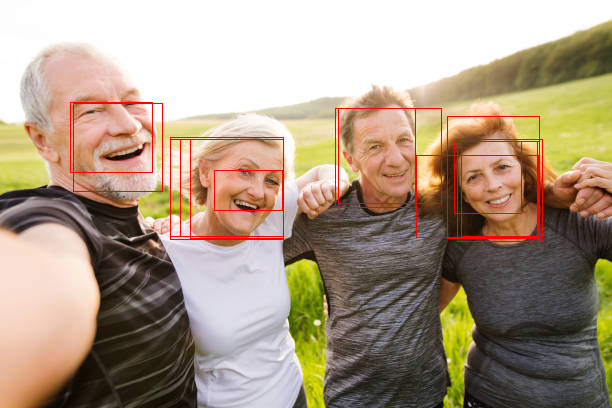
精度和 RCNN 差不多,甚至有些降低了 (为了支持 4G 显存缩放图片了)。不过识别速度有很大的提升,在同一个环境下,Fast-RCNN 处理单张图片只需要 0.4~0.5 秒,而 RCNN 则需要 2 秒左右。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 129
- 统信桌面专业版【全盘安装UOS系统】介绍 128
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 119
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 108
- 麒麟系统连接打印机常见问题及解决方法 20
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
