写给程序员的机器学习入门 (八) - 卷积神经网络 (CNN) - 图片分类和验证码识别(二)
使用 CNN 实现图片分类 (LeNet)
接下来我们试试使用 CNN 实现图片分类,也就是给出一张图片让程序识别里面的是什么东西,使用的数据集是 cifar-10,这是一个很经典的数据集,包含了 60000 张 32x32 的小图片,图片有十个分类 (飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船,货车),官方下载地址在这里。

需要注意的是,官方下载地址只包含二进制数据,通常很多文章或者教程都会让我们使用 torchvision.datasets.CIFAR10 等现成的加载器来加载这个数据集,但我不推荐使用这种方法,因为如果我们需要训练实际业务上的数据,那么肯定不会有现成的加载器可以用,还是得一张张图片的加载和转换。所以这里我使用了 cifar-10 的原始图片库,然后演示怎样从代码加载图片和标签,然后转换到训练使用的 tensor 对象。
以下的代码使用了 LeNet 模型,这是 30 年前就已经被提出的模型,结构和本文第一个图片介绍的一样。此外还有一些需要注意的地方:
- cifar-10 官方默认划分了 50000 张图片作为训练集,10000 张图片作为验证集;而我的代码划分了 48000 张图片作为训练集,6000 张图片作为验证集,6000 张图片作为测试集,所以正确率等数据会和其他文章或者论文不一致
- 训练时的损失计算器使用了
CrossEntropyLoss, 这个计算器的特征是要求预测输出是 onehot,实际输出是索引值 (只有一个分类是正确输出),例如图片分类为鸟时,预测输出应该为[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]实际输出应该为2 - 转换各个分类的数值到概率使用了 Softmax 函数, 这个函数必须放在模型之外,如果放在模型内部会导致训练效果变差,因为
CrossEntropyLoss损失计算器会尽量让正确输出的数值更高,错误输出的数值更低,而不是分别接近 1 和 0,使用 softmax 会干扰损失的计算
import os
import sys
import torch
import gzip
import itertools
import random
import numpy
import json
from PIL import Image
from torch import nn
from matplotlib import pyplot
# 分析目标的图片大小,全部图片都会先缩放到这个大小
IMAGE_SIZE = (32, 32)
# 分析目标的图片所在的文件夹
IMAGE_DIR = "./cifar"
# 包含所有图片标签的文本文件
IMAGE_LABELS_PATH = "./cifar/labels.txt"
class MyModel(nn.Module):
"""图片分类 (LeNet)"""
def __init__(self, num_labels):
super().__init__()
# 卷积层和池化层
self.cnn_model = nn.Sequential(
nn.Conv2d(3, 6, kernel_size=5), # 维度: B,3,32,32 => B,6,28,28
nn.ReLU(),
nn.MaxPool2d(2, stride=2), # 维度: B,6,14,14
nn.Conv2d(6, 16, kernel_size=5), # 维度: B,16,10,10
nn.ReLU(),
nn.MaxPool2d(2, stride=2) # 维度: B,16,5,5
)
# 全连接层
self.fc_model = nn.Sequential(
nn.Linear(16 * 5 * 5, 120), # 维度: B,120
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(120, 60), # 维度: B,60
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(60, num_labels), # 维度: B,num_labels
)
def forward(self, x):
# 应用卷积层和池化层
cnn_features = self.cnn_model(x)
# 扁平化输出的特征
cnn_features_flatten = cnn_features.view(cnn_features.shape[0], -1)
# 应用全连接层
y = self.fc_model(cnn_features_flatten)
return y
def save_tensor(tensor, path):
"""保存 tensor 对象到文件"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""从文件读取 tensor 对象"""
return torch.load(gzip.GzipFile(path, "rb"))
def image_to_tensor(img):
"""转换图片对象到 tensor 对象"""
in_img = img.resize(IMAGE_SIZE)
arr = numpy.asarray(in_img)
t = torch.from_numpy(arr)
t = t.transpose(0, 2) # 转换维度 H,W,C 到 C,W,H
t = t / 255.0 # 正规化数值使得范围在 0 ~ 1
return t
def load_image_labels():
"""读取图片分类列表"""
return list(filter(None, open(IMAGE_LABELS_PATH).read().split()))
def prepare_save_batch(batch, tensor_in, tensor_out):
"""准备训练 - 保存单个批次的数据"""
# 切分训练集 (80%),验证集 (10%) 和测试集 (10%)
random_indices = torch.randperm(tensor_in.shape[0])
training_indices = random_indices[:int(len(random_indices)*0.8)]
validating_indices = random_indices[int(len(random_indices)*0.8):int(len(random_indices)*0.9):]
testing_indices = random_indices[int(len(random_indices)*0.9):]
training_set = (tensor_in[training_indices], tensor_out[training_indices])
validating_set = (tensor_in[validating_indices], tensor_out[validating_indices])
testing_set = (tensor_in[testing_indices], tensor_out[testing_indices])
# 保存到硬盘
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def prepare():
"""准备训练"""
# 数据集转换到 tensor 以后会保存在 data 文件夹下
if not os.path.isdir("data"):
os.makedirs("data")
# 准备图片分类到序号的索引
labels_to_index = { label: index for index, label in enumerate(load_image_labels()) }
# 查找所有图片
image_paths = []
for root, dirs, files in os.walk(IMAGE_DIR):
for filename in files:
path = os.path.join(root, filename)
if not path.endswith(".png"):
continue
# 分类名称在文件名中,例如
# 2598_cat.png => cat
label = filename.split(".")[0].split("_")[1]
label_index = labels_to_index.get(label)
if label_index is None:
continue
image_paths.append((path, label_index))
# 打乱图片顺序
random.shuffle(image_paths)
# 分批读取和保存图片
batch_size = 1000
for batch in range(0, len(image_paths) // batch_size):
image_tensors = []
image_labels = []
for path, label_index in image_paths[batch*batch_size:(batch+1)*batch_size]:
with Image.open(path) as img:
t = image_to_tensor(img)
image_tensors.append(t)
image_labels.append(label_index)
tensor_in = torch.stack(image_tensors) # 维度: B,C,W,H
tensor_out = torch.tensor(image_labels) # 维度: B
prepare_save_batch(batch, tensor_in, tensor_out)
def train():
"""开始训练"""
# 创建模型实例
num_labels = len(load_image_labels())
model = MyModel(num_labels)
# 创建损失计算器
# 计算单分类输出最好使用 CrossEntropyLoss, 多分类输出最好使用 BCELoss
# 使用 CrossEntropyLoss 时实际输出应该为标签索引值,不需要转换为 onehot
loss_function = torch.nn.CrossEntropyLoss()
# 创建参数调整器
optimizer = torch.optim.Adam(model.parameters())
# 记录训练集和验证集的正确率变化
training_accuracy_history = []
validating_accuracy_history = []
# 记录最高的验证集正确率
validating_accuracy_highest = -1
validating_accuracy_highest_epoch = 0
# 读取批次的工具函数
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 计算正确率的工具函数
def calc_accuracy(actual, predicted):
# 把最大的值当作正确分类,然后比对有多少个分类相等
predicted_labels = predicted.argmax(dim=1)
acc = (actual == predicted_labels).sum().item() / actual.shape[0]
return acc
# 划分输入和输出的工具函数
def split_batch_xy(batch, begin=None, end=None):
# shape = batch_size, channels, width, height
batch_x = batch[0][begin:end]
# shape = batch_size
batch_y = batch[1][begin:end]
return batch_x, batch_y
# 开始训练过程
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
# 切换模型到训练模式,将会启用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.train()
training_accuracy_list = []
for batch_index, batch in enumerate(read_batches("data/training_set")):
# 切分小批次,有助于泛化模型
training_batch_accuracy_list = []
for index in range(0, batch[0].shape[0], 100):
# 划分输入和输出
batch_x, batch_y = split_batch_xy(batch, index, index+100)
# 计算预测值
predicted = model(batch_x)
# 计算损失
loss = loss_function(predicted, batch_y)
# 从损失自动微分求导函数值
loss.backward()
# 使用参数调整器调整参数
optimizer.step()
# 清空导函数值
optimizer.zero_grad()
# 记录这一个批次的正确率,torch.no_grad 代表临时禁用自动微分功能
with torch.no_grad():
training_batch_accuracy_list.append(calc_accuracy(batch_y, predicted))
# 输出批次正确率
training_batch_accuracy = sum(training_batch_accuracy_list) / len(training_batch_accuracy_list)
training_accuracy_list.append(training_batch_accuracy)
print(f"epoch: {epoch}, batch: {batch_index}: batch accuracy: {training_batch_accuracy}")
training_accuracy = sum(training_accuracy_list) / len(training_accuracy_list)
training_accuracy_history.append(training_accuracy)
print(f"training accuracy: {training_accuracy}")
# 检查验证集
# 切换模型到验证模式,将会禁用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
batch_x, batch_y = split_batch_xy(batch)
predicted = model(batch_x)
validating_accuracy_list.append(calc_accuracy(batch_y, predicted))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 记录最高的验证集正确率与当时的模型状态,判断是否在 20 次训练后仍然没有刷新记录
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 20:
# 在 20 次训练后仍然没有刷新记录,结束训练
print("stop training because highest validating accuracy not updated in 20 epoches")
break
# 使用达到最高正确率时的模型状态
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 检查测试集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
batch_x, batch_y = split_batch_xy(batch)
predicted = model(batch_x)
testing_accuracy_list.append(calc_accuracy(batch_y, predicted))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 显示训练集和验证集的正确率变化
pyplot.plot(training_accuracy_history, label="training")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用训练好的模型"""
# 创建模型实例,加载训练好的状态,然后切换到验证模式
labels = load_image_labels()
num_labels = len(labels)
model = MyModel(num_labels)
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 询问图片路径,并显示可能的分类一览
while True:
try:
# 构建输入
image_path = input("Image path: ")
if not image_path:
continue
with Image.open(image_path) as img:
tensor_in = image_to_tensor(img).unsqueeze(0) # 维度 C,W,H => 1,C,W,H
# 预测输出
tensor_out = model(tensor_in)
# 转换到各个分类对应的概率
tensor_out = nn.functional.softmax(tensor_out, dim=1)
# 显示按概率排序后的分类一览
rates = (t.item() for t in tensor_out[0])
label_with_rates = list(zip(labels, rates))
label_with_rates.sort(key=lambda p:-p[1])
for label, rate in label_with_rates[:5]:
rate = rate * 100
print(f"{label}: {rate:0.2f}%")
print()
except Exception as e:
print("error:", e)
def main():
"""主函数"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 给随机数生成器分配一个初始值,使得每次运行都可以生成相同的随机数
# 这是为了让过程可重现,你也可以选择不这样做
random.seed(0)
torch.random.manual_seed(0)
# 根据命令行参数选择操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
准备训练使用的数据和开始训练需要分别执行以下命令:
python3 example.py prepare
python3 example.py train
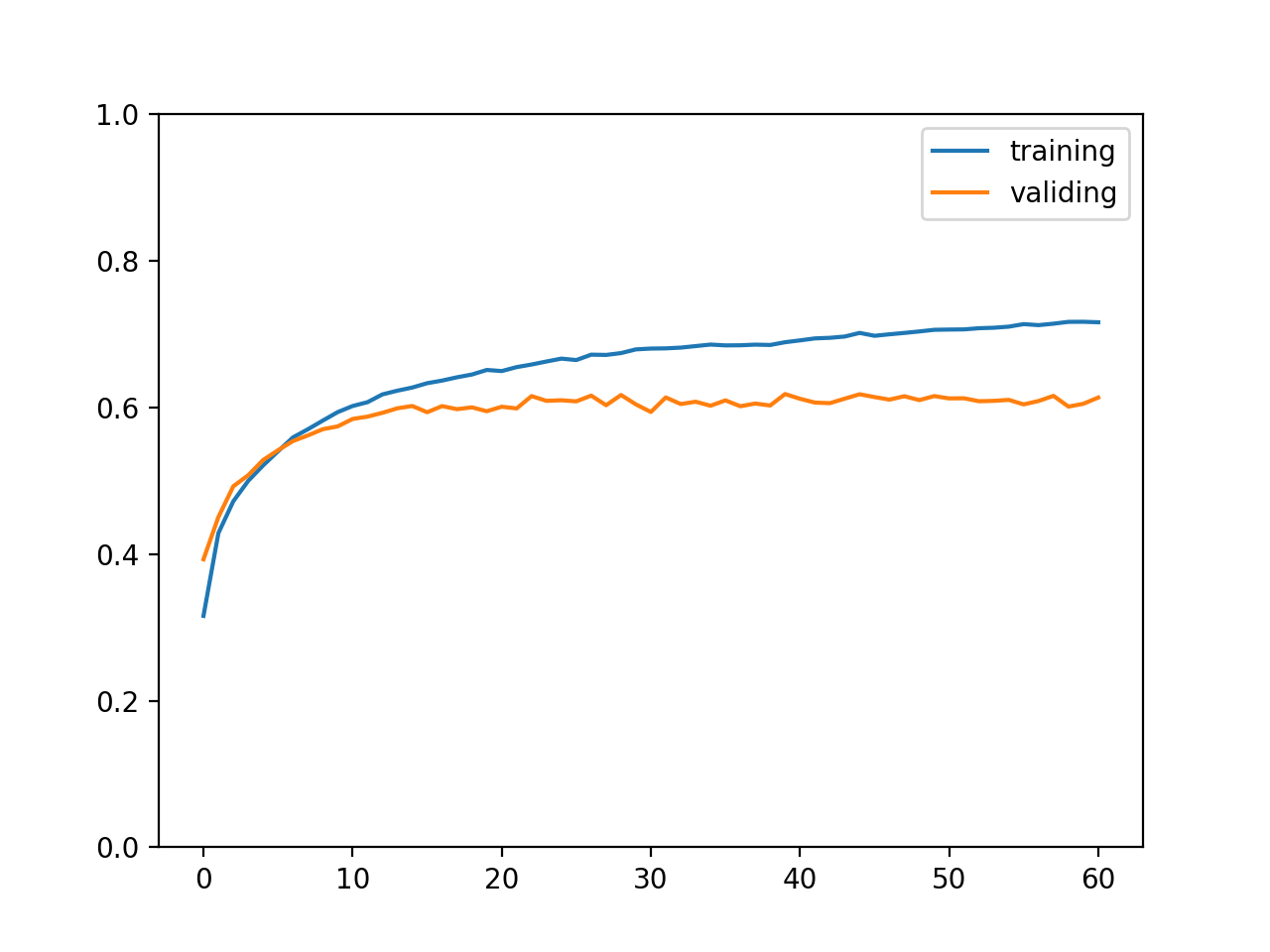
最终输出结果如下,可以看到训练集正确率达到了 71%,验证集和测试集正确率达到了 61%,这个正确率代表可以精准说出图片所属的分类,也称 top 1 正确率;此外计算正确分类在概率排前三的分类之中的比率称为 top 3 正确率,如果是电商上传图片以后给出三个可能的商品分类让商家选择,那么计算 top 3 正确率就有意义了。
training accuracy: 0.7162083333333331
validating accuracy: 0.6134999999999998
stop training because highest validating accuracy not updated in 20 epoches
highest validating accuracy: 0.6183333333333333 from epoch 40
testing accuracy: 0.6168333333333332
训练集与验证集正确率变化如下图所示:
实际使用模型的例子如下,输出代表预测图片有 79.23% 的概率是飞机,你也可以试试在互联网上随便找一张图片让这个模型识别:
$ python3 example.py eval
Image path: ./cifar/test/2257_airplane.png
airplane: 79.23%
deer: 6.06%
automobile: 4.04%
cat: 2.89%
frog: 2.11%
使用 CNN 实现图片分类 (ResNet)
上述的模型 top 1 正确率只达到了 61%, 毕竟是 30 年前的老模型了🧔,这里我再介绍一个相对比较新的模型,ResNet 是在 2015 年中提出的模型,论文地址在这里,特征是会把输入和输出结合在一块,例如原来计算 y = f(x) 会变为 y = f(x) + x,从而抵消层数变多带来的梯度消失问题 (参考我之前写的训练过程中常用的技巧)。
下图是 ResNet-18 模型的结构,内部可以分为 4 组,每个组都包括 2 个基础块和 4 个卷积层,并且每个基础块会把输入和输出结合在一起,层数合计一共有 16,加上最开始转换输入的层和全连接层一共有 18 层,所以称为 ResNet-18,除此之外还有 ResNet-34,ResNet-50 等等变种,如果有兴趣可以参考本节末尾给出的 torchvision 的实现代码。

从图中可以看到,从第二组开始会把长宽变为一半,同时通道数增加一倍,然后维持通道数和长宽不变,所有组结束后使用一个 AvgPool2d 来让长宽强制变为 1x1,最后交给全连接层。计算卷积层输出长宽的公式是 (长度 - 内核大小 + 填充量*2) / 处理间隔 + 1,让长宽变为一半会使用内核大小 3,填充量 1,处理间隔 2 ,例如长度为 32 可以计算得出 (32 - 3 + 2) / 2 + 1 == 16;而维持长宽的则会使用内核大小 3,填充量 1,处理间隔 1,例如长度为 32 可以计算得出 (32 - 3 + 2) / 1 + 1 == 32。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 127
- 统信桌面专业版【全盘安装UOS系统】介绍 122
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 114
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
