写给程序员的机器学习入门 (八) - 卷积神经网络 (CNN) - 图片分类和验证码识别(一)
使用 Python 处理图片
在具体介绍 CNN 之前,我们先来看看怎样使用 Python 处理图片。Python 处理图片最主要使用的类库是 Pillow (Python2 PIL 的 fork),使用以下命令即可安装:
pip3 install Pillow
一些简单操作的例子如下,如果你想了解更多可以参考 Pillow 的文档:
# 打开图片
>>> from PIL import Image
>>> img = Image.open("1.png")
# 查看图片信息
>>> img.size
(175, 230)
>>> img.mode
'RGB'
>>> img
<PIL.PngImagePlugin.PngImageFile image mode=RGB size=175x230 at 0x10B807B50>
# 缩放图片
>>> img1 = img.resize((20, 30))
>>> img1
<PIL.Image.Image image mode=RGB size=20x30 at 0x106426FD0>
# 裁剪图片
>>> img2 = img.crop((0, 0, 16, 16))
>>> img2
<PIL.Image.Image image mode=RGB size=16x16 at 0x105E0EFD0>
# 保存图片
>>> img1.save("11.png")
>>> img2.save("12.png")
使用 pytorch 处理图片时要首先获取图片的数据,即各个像素对应的颜色值,例如大小为 175 * 230,模式是 RGB 的图片会拥有 175 * 230 * 3 的数据,3 分别代表红绿蓝的值,范围是 0 ~ 255,把图片转换为 pytorch 的 tensor 对象需要经过 numpy 中转,以下是转换的例子:
>>> import numpy
>>> import torch
>>> v = numpy.asarray(img)
>>> t = torch.tensor(v)
>>> t
tensor([[[255, 253, 254],
[255, 253, 254],
[255, 253, 254],
...,
[255, 253, 254],
[255, 253, 254],
[255, 253, 254]],
[[255, 253, 254],
[255, 253, 254],
[255, 253, 254],
...,
[255, 253, 254],
[255, 253, 254],
[255, 253, 254]],
[[255, 253, 254],
[255, 253, 254],
[255, 253, 254],
...,
[255, 253, 254],
[255, 253, 254],
[255, 253, 254]],
...,
[[255, 253, 254],
[255, 253, 254],
[255, 253, 254],
...,
[255, 253, 254],
[255, 253, 254],
[255, 253, 254]],
[[255, 253, 254],
[255, 253, 254],
[255, 253, 254],
...,
[255, 253, 254],
[255, 253, 254],
[255, 253, 254]],
[[255, 253, 254],
[255, 253, 254],
[255, 253, 254],
...,
[255, 253, 254],
[255, 253, 254],
[255, 253, 254]]], dtype=torch.uint8)
>>> t.shape
torch.Size([230, 175, 3])
可以看到 tensor 的维度是 高度 x 宽度 x 通道数 (RGB 图片为 3,黑白图片为 1),可是 pytorch 的 CNN 模型会要求维度为 通道数 x 宽度 x 高度,并且数值应该正规化到 0 ~ 1 的范围内,使用以下代码可以实现:
# 交换维度 0 (高度) 和 维度 2 (通道数)
>>> t1 = t.transpose(0, 2)
>>> t1.shape
torch.Size([3, 175, 230])
>>> t2 = t1 / 255.0
>>> t2
tensor([[[1.0000, 1.0000, 1.0000, ..., 1.0000, 1.0000, 1.0000],
[1.0000, 1.0000, 1.0000, ..., 1.0000, 1.0000, 1.0000],
[1.0000, 1.0000, 1.0000, ..., 1.0000, 1.0000, 1.0000],
...,
[1.0000, 1.0000, 1.0000, ..., 1.0000, 1.0000, 1.0000],
[1.0000, 1.0000, 1.0000, ..., 1.0000, 1.0000, 1.0000],
[1.0000, 1.0000, 1.0000, ..., 1.0000, 1.0000, 1.0000]],
[[0.9922, 0.9922, 0.9922, ..., 0.9922, 0.9922, 0.9922],
[0.9922, 0.9922, 0.9922, ..., 0.9922, 0.9922, 0.9922],
[0.9922, 0.9922, 0.9922, ..., 0.9922, 0.9922, 0.9922],
...,
[0.9922, 0.9922, 0.9922, ..., 0.9922, 0.9922, 0.9922],
[0.9922, 0.9922, 0.9922, ..., 0.9922, 0.9922, 0.9922],
[0.9922, 0.9922, 0.9922, ..., 0.9922, 0.9922, 0.9922]],
[[0.9961, 0.9961, 0.9961, ..., 0.9961, 0.9961, 0.9961],
[0.9961, 0.9961, 0.9961, ..., 0.9961, 0.9961, 0.9961],
[0.9961, 0.9961, 0.9961, ..., 0.9961, 0.9961, 0.9961],
...,
[0.9961, 0.9961, 0.9961, ..., 0.9961, 0.9961, 0.9961],
[0.9961, 0.9961, 0.9961, ..., 0.9961, 0.9961, 0.9961],
[0.9961, 0.9961, 0.9961, ..., 0.9961, 0.9961, 0.9961]]])
之后就可以围绕类似上面例子中 t2 这样的 tensor 对象做文章了🥳。
卷积神经网络 (CNN)
卷积神经网络 (CNN) 会从图片的各个部分提取特征,然后再从一级特征提取二级特征,如有必要再提取三级特征 (以此类推),提取结束以后扁平化到最终特征,然后使用多层或单层线性模型来实现分类识别。提取各级特征会使用卷积层 (Convolution Layer) 和池化层 (Pooling Layer),提取特征时可以选择添加通道数量以增加各个部分的信息量,分类识别最终特征使用的线性模型又称全连接层 (Fully Connected Layer),下图是流程示例:
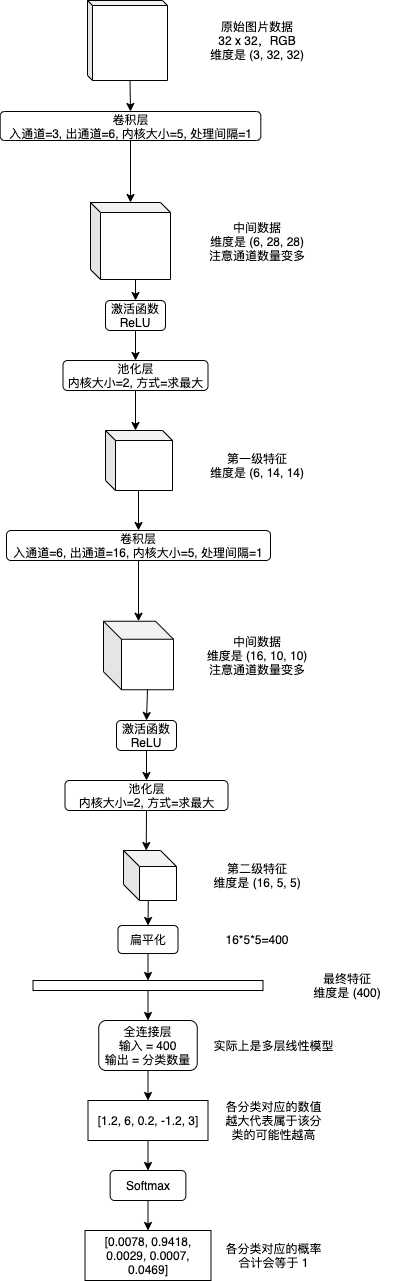
之前的文章介绍线性模型和递归模型的时候我使用了数学公式,但只用数学公式说明 CNN 将会非常难以理解,所以接下来我会伴随例子逐步讲解各个层具体做了怎样的运算。
卷积层 (Convolution Layer)
卷积层会对图片的各个部分做矩阵乘法操作,然后把结果作为一个新的矩阵,每个卷积层有两个主要的参数,一个是内核大小 (kernel_size),一个是处理间隔 (stride),下图是一个非常简单的计算流程例子:
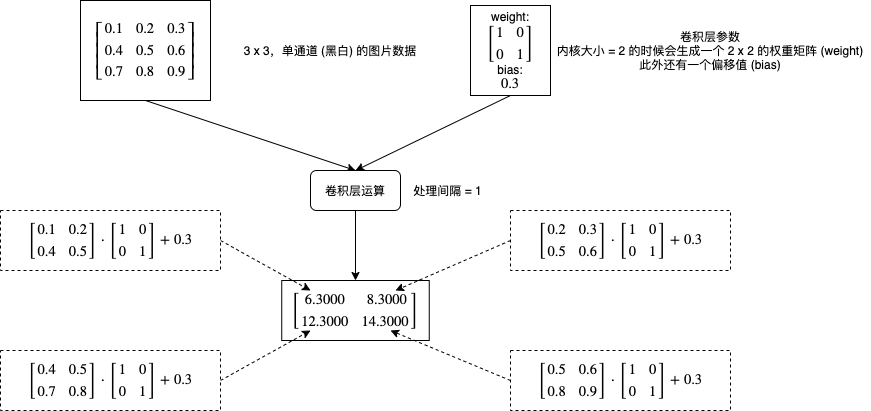
如果增加处理间隔会怎样呢?下图展示了不同处理间隔的计算部分和输出结果维度的区别:

我们可以看到处理间隔决定了每次向右或者向下移动的距离,输出长度可以使用公式 (长度 - 内核大小) / 处理间隔 + 1 计算,输出宽度可以使用公式 (长度 - 内核大小) / 处理间隔 + 1 计算。
现在再来看看 pytorch 中怎样使用卷积层,创建卷积层可以使用 torch.nn.Conv2d:
# 创建卷积层,入通道 = 1,出通道 = 1,内核大小 = 2,处理间隔 = 1
>>> conv2d = torch.nn.Conv2d(in_channels = 1, out_channels = 1, kernel_size = 2, stride = 1)
# 查看卷积层内部的参数,第一个是内核对应的权重矩阵,第二个是偏移值
>>> p = list(conv2d.parameters())
>>> p
[Parameter containing:
tensor([[[[-0.0650, -0.0575],
[-0.0313, -0.3539]]]], requires_grad=True), Parameter containing:
tensor([0.1482], requires_grad=True)]
# 现在生成一个 5 x 5,单通道的图片数据,为了方便理解这里使用了 1 ~ 25,实际应该使用 0 ~ 1 之间的值
>>> x = torch.tensor(list(range(1, 26)), dtype=torch.float).reshape(1, 1, 5, 5)
>>> x
tensor([[[[ 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10.],
[11., 12., 13., 14., 15.],
[16., 17., 18., 19., 20.],
[21., 22., 23., 24., 25.]]]])
# 使用卷积层计算输出
>>> y = conv2d(x)
>>> y
tensor([[[[ -2.6966, -3.2043, -3.7119, -4.2196],
[ -5.2349, -5.7426, -6.2502, -6.7579],
[ -7.7732, -8.2809, -8.7885, -9.2962],
[-10.3115, -10.8192, -11.3268, -11.8345]]]],
grad_fn=<MkldnnConvolutionBackward>)
# 我们可以模拟一下处理单个部分的计算,看看和上面的输出是否一致
# 第 1 部分
>>> x[0,0,0:2,0:2]
tensor([[1., 2.],
[6., 7.]])
>>> (p[0][0,0,:,:] * x[0,0,0:2,0:2]).sum() + p[1]
tensor([-2.6966], grad_fn=<AddBackward0>)
# 第 2 部分
>>> x[0,0,0:2,1:3]
tensor([[2., 3.],
[7., 8.]])
>>> (p[0][0,0,:,:] * x[0,0,0:2,1:3]).sum() + p[1]
tensor([-3.2043], grad_fn=<AddBackward0>)
# 第 3 部分
>>> (p[0][0,0,:,:] * x[0,0,0:2,2:4]).sum() + p[1]
tensor([-3.7119], grad_fn=<AddBackward0>)
# 一致吧🥳
到这里你应该了解单通道的卷积层是怎样计算的,那么多通道呢?如果有多个入通道,那么卷积层的权重矩阵会相应有多份,如果有多个出通道,那么卷积层的权重矩阵数量也会乘以出通道的倍数,例如有 3 个入通道,2 个出通道时,卷积层的权重矩阵会有 6 个 (3 * 2),偏移值会有 2 个,计算规则如下:
部分输出[出通道1] = 部分输入[入通道1] * 权重矩阵[0][0] + 部分输入[入通道2] * 权重矩阵[0][1] + 部分输入[入通道3] * 权重矩阵[0][2] + 偏移值1
部分输出[出通道2] = 部分输入[入通道1] * 权重矩阵[1][0] + 部分输入[入通道2] * 权重矩阵[1][1] + 部分输入[入通道3] * 权重矩阵[1][2] + 偏移值2
从计算规则可以看出,出通道越多每个部分可提取的特征数量 (信息量) 也就越多,但计算量也会相应增大。
最后看看卷积层的数学公式 (基本和 pytorch 文档的公式相同),现在应该可以理解了吧🤢?

池化层 (Pooling Layer)
池化层的处理比较好理解,它会对每个图片每个区域进行求最大值或者求平均值等运算,如下图所示:
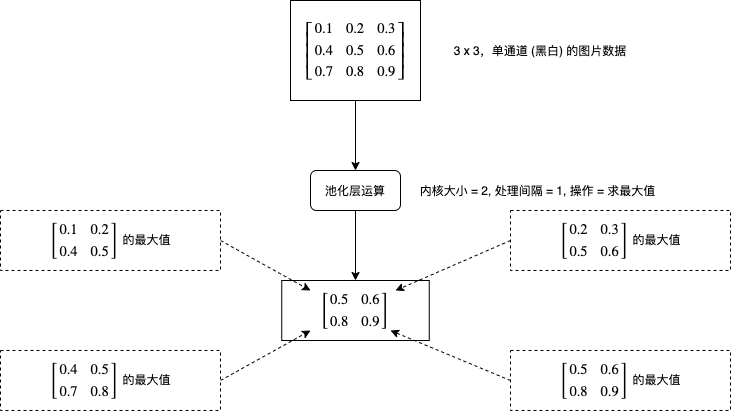
现在再来看看 pytorch 中怎样使用卷积层,创建求最大值的池化层可以使用 torch.nn.MaxPool2d,创建求平均值的池化层可以使用 torch.nn.AvgPool2d:
# 创建池化层,内核大小 = 2,处理间隔 = 2
>>> maxPool = torch.nn.MaxPool2d(2, stride=2)
# 生成一个 6 x 6,单通道的图片数据
>>> x = torch.tensor(range(1, 37), dtype=float).reshape(1, 1, 6, 6)
>>> x
tensor([[[[ 1., 2., 3., 4., 5., 6.],
[ 7., 8., 9., 10., 11., 12.],
[13., 14., 15., 16., 17., 18.],
[19., 20., 21., 22., 23., 24.],
[25., 26., 27., 28., 29., 30.],
[31., 32., 33., 34., 35., 36.]]]], dtype=torch.float64)
# 使用池化层计算输出
>>> maxPool(x)
tensor([[[[ 8., 10., 12.],
[20., 22., 24.],
[32., 34., 36.]]]], dtype=torch.float64)
# 很好理解吧🥳
# 创建和使用求平均值的池化层也很简单
>>> avgPool = torch.nn.AvgPool2d(2, stride=2)
>>> avgPool(x)
tensor([[[[ 4.5000, 6.5000, 8.5000],
[16.5000, 18.5000, 20.5000],
[28.5000, 30.5000, 32.5000]]]], dtype=torch.float64)
全连接层 (Fully Connected Layer)
全连接层实际上就是多层或单层线性模型,但把特征传到全连接层之前还需要进行扁平化 (Flatten),例子如下所示:
# 模拟创建一个批次数量为 2,通道数为 3,长宽各为 2 的特征
>>> x = torch.rand((2, 3, 2, 2))
>>> x
tensor([[[[0.6395, 0.6240],
[0.4194, 0.6054]],
[[0.4798, 0.4690],
[0.2647, 0.6087]],
[[0.5727, 0.7567],
[0.8287, 0.1382]]],
[[[0.7903, 0.8635],
[0.0053, 0.6417]],
[[0.7093, 0.7740],
[0.3115, 0.7587]],
[[0.5875, 0.8268],
[0.2923, 0.6016]]]])
# 对它进行扁平化,维度会变为 批次数量, 通道数*长*宽
>>> x_flatten = x.view(x.shape[0], -1)
>>> x_flatten
tensor([[0.6395, 0.6240, 0.4194, 0.6054, 0.4798, 0.4690, 0.2647, 0.6087, 0.5727,
0.7567, 0.8287, 0.1382],
[0.7903, 0.8635, 0.0053, 0.6417, 0.7093, 0.7740, 0.3115, 0.7587, 0.5875,
0.8268, 0.2923, 0.6016]])
# 之后再传给线性模型即可
>>> linear = torch.nn.Linear(in_features=12, out_features=2)
>>> linear(x_flatten)
tensor([[-0.3067, -0.5534],
[-0.1876, -0.6523]], grad_fn=<AddmmBackward>)
填充处理
在看前面提到的卷积层操作的时候,你可能会发现如果处理间隔 (stride) 小于内核大小 (kernel_size),那么图片边缘的像素参与运算的次数会比图片中间的像素要少,也就是说图片边缘对运算结果的影响会更小,如果图片边缘的信息同样比较重要,那么就会影响预测输出的精度。为了解决这个问题发明的就是填充处理,填充处理简单的来说就是在卷积层初期前给图片的周边添加 0,如果填充量等于 1,那么长宽会各增加 2,如下图所示:

在 pytorch 中添加填充处理可以在创建 Conv2d 的时候指定 padding 参数:
# 创建卷积层,入通道 = 1,出通道 = 1,内核大小 = 2,处理间隔 = 1, 填充量 = 1
>>> conv2d = torch.nn.Conv2d(in_channels = 1, out_channels = 1, kernel_size = 2, stride = 1, padding = 1)如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 127
- 统信桌面专业版【全盘安装UOS系统】介绍 122
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 114
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
