写给程序员的机器学习入门 (六) - 应用递归模型的例子(二)
例子② - 预测股价走势
如果你是一个股民,你可能会试图找出那些涨涨跌跌之间的规律,包括使用 MACD, KDJ 等指标,这里我们试试应用机器学习预测股价走势,看看结果如何。
训练和验证使用的数据是中国银行 (601988) 的每日收盘价和交易量,可以从以下地址下载:
- (最新数据) https://finance.yahoo.com/quote/601988.SS/history?period1=1152057600&period2=1589500800&interval=1d&filter=history&frequency=1d
- (这篇文章使用的数据) https://github.com/303248153/BlogArchive/tree/master/ml-06/601988.SS.csv
csv 中包含了 日期,开盘价,最高价,最低价,收盘价,调整后收盘价,交易量,输入和输出规定如下
- 输入: 收盘价 (标准化除以 100), 交易量 (标准化除以 1 亿)
- 输出: T+2 的涨跌 (涨 1 跌 0, T+2 指下下个交易日)
模型是 GRU + 2 层线性模型,最终使用 sigmoid 转换输出到 0 ~ 1 之间的值,数据划分训练集包含 1500 条数据,验证集和测试集包含 100 条数据,时序按 训练集 => 验证集 => 测试集 排列。
注意传递数据给模型的时候会按 32 条数据分批传递,模型需要保留隐藏状态使得分批传递与完整传递可以得出相同的结果。
训练和使用模型的代码如下:
import os
import sys
import torch
import gzip
import itertools
import random
import pandas
import math
from torch import nn
from matplotlib import pyplot
CSV_FILENAME = "601988.SS.csv"
TRAINING_RECORDS = 1500
VALIDATING_RECORDS = 100
TESTING_RECORDS = 100
class MyModel(nn.Module):
"""根据历史收盘价和成交量预测股价走势"""
def __init__(self):
super().__init__()
self.rnn = nn.GRU(
input_size = 2,
hidden_size = 50,
num_layers = 1,
batch_first = True
)
self.linear = nn.Sequential(
nn.Linear(in_features=50, out_features=20),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(in_features=20, out_features=1),
nn.Sigmoid())
self.reset_hidden()
def forward(self, x):
# 调整维度
x = x.reshape(1, x.shape[0], x.shape[1])
# 使用递归模型计算,需要所有输出,并且还需要保存隐藏状态
# 保存隐藏状态时需要使用 detach 切断内部的计算路径
output, hidden = self.rnn(x, self.rnn_hidden)
self.rnn_hidden = hidden.detach()
# 转换输出的维度到 批次大小, 隐藏值数量
output = output.reshape(output.shape[1], output.shape[2])
# 使用多层线性模型计算递归模型返回的输出
y = self.linear(output)
return y
def reset_hidden(self):
"""重置隐藏状态"""
self.rnn_hidden = torch.zeros(1, 1, 50)
def save_tensor(tensor, path):
"""保存 tensor 对象到文件"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""从文件读取 tensor 对象"""
return torch.load(gzip.GzipFile(path, "rb"))
def prepare():
"""准备训练"""
# 数据集转换到 tensor 以后会保存在 data 文件夹下
if not os.path.isdir("data"):
os.makedirs("data")
# 从 csv 读取原始数据集
df = pandas.read_csv(CSV_FILENAME)
in_list = [] # 收盘价和成交量作为输入
out_list = [] # T+2 的涨跌作为输出
for value in df.values:
volume = value[-1] / 100000000 # 成交量除以一亿
price = value[-3] / 100 # 收盘价除以 100
if math.isnan(volume) or math.isnan(price):
continue # 原始数据中是 null
in_list.append((price, volume))
for index in range(len(in_list)-2):
price_t0 = in_list[index][0]
price_t2 = in_list[index+2][0]
out_list.append(1. if price_t2 > price_t0 else 0.)
in_list = in_list[:len(out_list)]
# 生成输入和输出
in_tensor = torch.tensor(in_list)
out_tensor = torch.tensor(out_list).reshape(-1, 1)
# 划分训练集,验证集和测试集
testing_start = -TESTING_RECORDS
validating_start = testing_start - VALIDATING_RECORDS
training_start = validating_start - TRAINING_RECORDS
training_in = in_tensor[training_start:validating_start]
training_out = out_tensor[training_start:validating_start]
validating_in = in_tensor[validating_start:testing_start]
validating_out = out_tensor[validating_start:testing_start]
testing_in = in_tensor[testing_start:]
testing_out = out_tensor[testing_start:]
# 保存到硬盘
save_tensor((training_in, training_out), f"data/training_set.pt")
save_tensor((validating_in, validating_out), f"data/validating_set.pt")
save_tensor((testing_in, testing_out), f"data/testing_set.pt")
print("saved dataset")
def train():
"""开始训练"""
# 创建模型实例
model = MyModel()
# 创建损失计算器
loss_function = torch.nn.MSELoss()
# 创建参数调整器
optimizer = torch.optim.Adadelta(model.parameters())
# 记录训练集和验证集的正确率变化
training_accuracy_history = []
validating_accuracy_history = []
# 记录最高的验证集正确率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 计算正确率的工具函数
def calc_accuracy(actual, predicted):
return ((actual >= 0.5) == (predicted >= 0.5)).sum().item() / actual.shape[0]
# 开始训练过程
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 重置模型的隐藏状态
model.reset_hidden()
# 根据训练集训练并修改参数
# 切换模型到训练模式,将会启用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.train()
training_accuracy_list = []
training_in, training_out = load_tensor("data/training_set.pt")
for index in range(0, training_in.shape[0], 32):
# 划分输入和输出
batch_x = training_in[index:index+32]
batch_y = training_out[index:index+32]
# 计算预测值
predicted = model(batch_x)
# 计算损失
loss = loss_function(predicted, batch_y)
# 从损失自动微分求导函数值
loss.backward()
# 使用参数调整器调整参数
optimizer.step()
# 清空导函数值
optimizer.zero_grad()
# 记录这一个批次的正确率,torch.no_grad 代表临时禁用自动微分功能
with torch.no_grad():
training_accuracy_list.append(calc_accuracy(batch_y, predicted))
training_accuracy = sum(training_accuracy_list) / len(training_accuracy_list)
training_accuracy_history.append(training_accuracy)
print(f"training accuracy: {training_accuracy}")
# 检查验证集
# 切换模型到验证模式,将会禁用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.eval()
validating_in, validating_out = load_tensor("data/validating_set.pt")
predicted = model(validating_in)
validating_accuracy = calc_accuracy(validating_out, predicted)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 记录最高的验证集正确率与当时的模型状态,判断是否在 200 次训练后仍然没有刷新记录
# 因为数据量很少,仅在训练集正确率超过 70% 时执行这里的逻辑
if training_accuracy > 0.7:
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 200:
# 在 200 次训练后仍然没有刷新记录,结束训练
print("stop training because highest validating accuracy not updated in 200 epoches")
break
# 使用达到最高正确率时的模型状态
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 检查测试集
testing_in, testing_out = load_tensor("data/testing_set.pt")
predicted = model(testing_in)
testing_accuracy = calc_accuracy(testing_out, predicted)
print(f"testing accuracy: {testing_accuracy}")
# 显示训练集的误差变化
pyplot.plot(training_accuracy_history, label="training")
pyplot.plot(validating_accuracy_history, label="validating")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用训练好的模型"""
# 创建模型实例,加载训练好的状态,然后切换到验证模式
model = MyModel()
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 加载历史数据
training_in, _ = load_tensor("data/training_set.pt")
model(training_in)
# 预测未来数据
price_list = []
trend_list = []
df = pandas.read_csv(CSV_FILENAME)
for value in df.values[-TESTING_RECORDS-VALIDATING_RECORDS:]:
volume = float(value[-1])
price = float(value[-3])
if math.isnan(volume) or math.isnan(price):
continue # 原始数据中是 null
in_tensor = torch.tensor([[price / 100, volume / 100000000]])
trend = model(in_tensor)[0].item()
price_list.append(price)
trend_list.append(trend)
# 根据预测数据模拟买卖 100 万
# 规则为预测 T+2 涨则买入,预测 T+2 跌则卖出,不计算印花税和分红
money = 1000000
stock = 0
matched = 0
total = 0
buy_list = []
sell_list = []
for index in range(len(price_list)):
price = price_list[index]
trend = trend_list[index]
will_rise = trend > 0.5
will_drop = trend < 0.5
if stock == 0 and will_rise:
unit = int(money / price / 100) # 1 手 100 股
money -= price * unit * 100
stock += unit
buy_list.append(price)
sell_list.append(0)
print(f"buy {unit}, money {money}, stock {stock}")
elif stock != 0 and will_drop:
unit = stock
money += price * unit * 100
stock -= unit
buy_list.append(0)
sell_list.append(price)
print(f"sell {unit}, money {money}, stock {stock}")
else:
buy_list.append(0)
sell_list.append(0)
money_final = money + price_list[-1] * stock * 100
print(f"final money {money_final}")
print(f"stock price goes from {price_list[0]} to {price_list[-1]} in this range")
# 显示为图表
pyplot.plot(price_list, label="price")
pyplot.plot(buy_list, label="buy", marker="$b$", linestyle = "None")
pyplot.plot(sell_list, label="sell", marker="$s$", linestyle = "None")
pyplot.ylim(min(price_list) - 0.05, max(price_list) + 0.05)
pyplot.legend()
pyplot.show()
def main():
"""主函数"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 给随机数生成器分配一个初始值,使得每次运行都可以生成相同的随机数
# 这是为了让过程可重现,你也可以选择不这样做
random.seed(0)
torch.random.manual_seed(0)
# 根据命令行参数选择操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
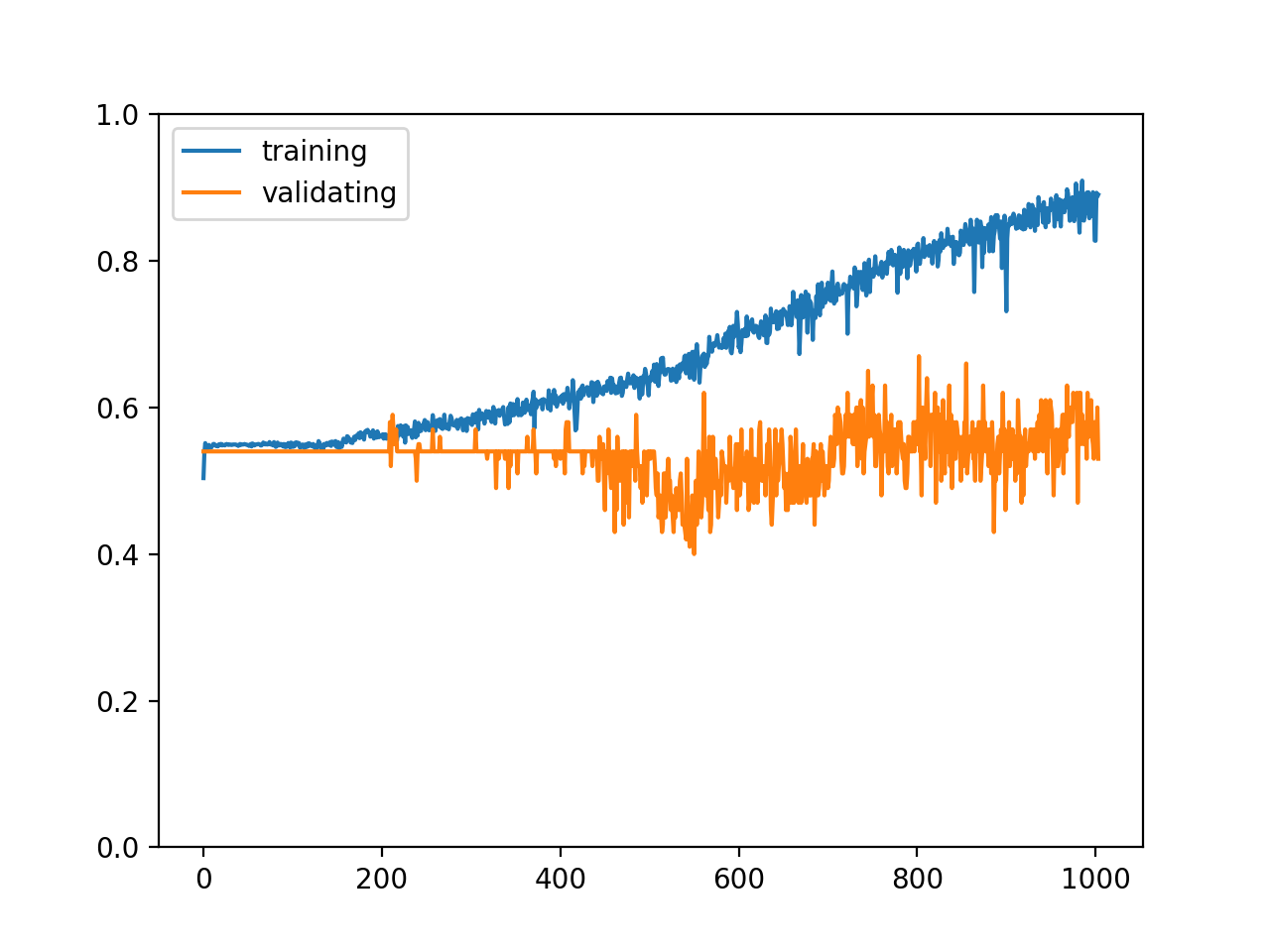
训练结束以后的输出如下,这不是一个理想的结果🙄:
epoch: 1004
training accuracy: 0.8902925531914894
validating accuracy: 0.53
stop training because highest validating accuracy not updated in 200 epoches
highest validating accuracy: 0.67 from epoch 803
testing accuracy: 0.5
训练集和验证集的正确率变化如下:
验证模型的部分会基于没有训练过的未知数据 (合计 200 条) 模拟交易,首先准备 100 万,预测 T+2 涨就买,预测 T+2 跌就卖,一天只操作一次,每次买卖都是最大数量,不考虑印花税和分红,模拟结果如下:
final money 1089605.9999999998
stock price goes from 3.67 to 3.45 in this range
模拟交易的图表表现如下:
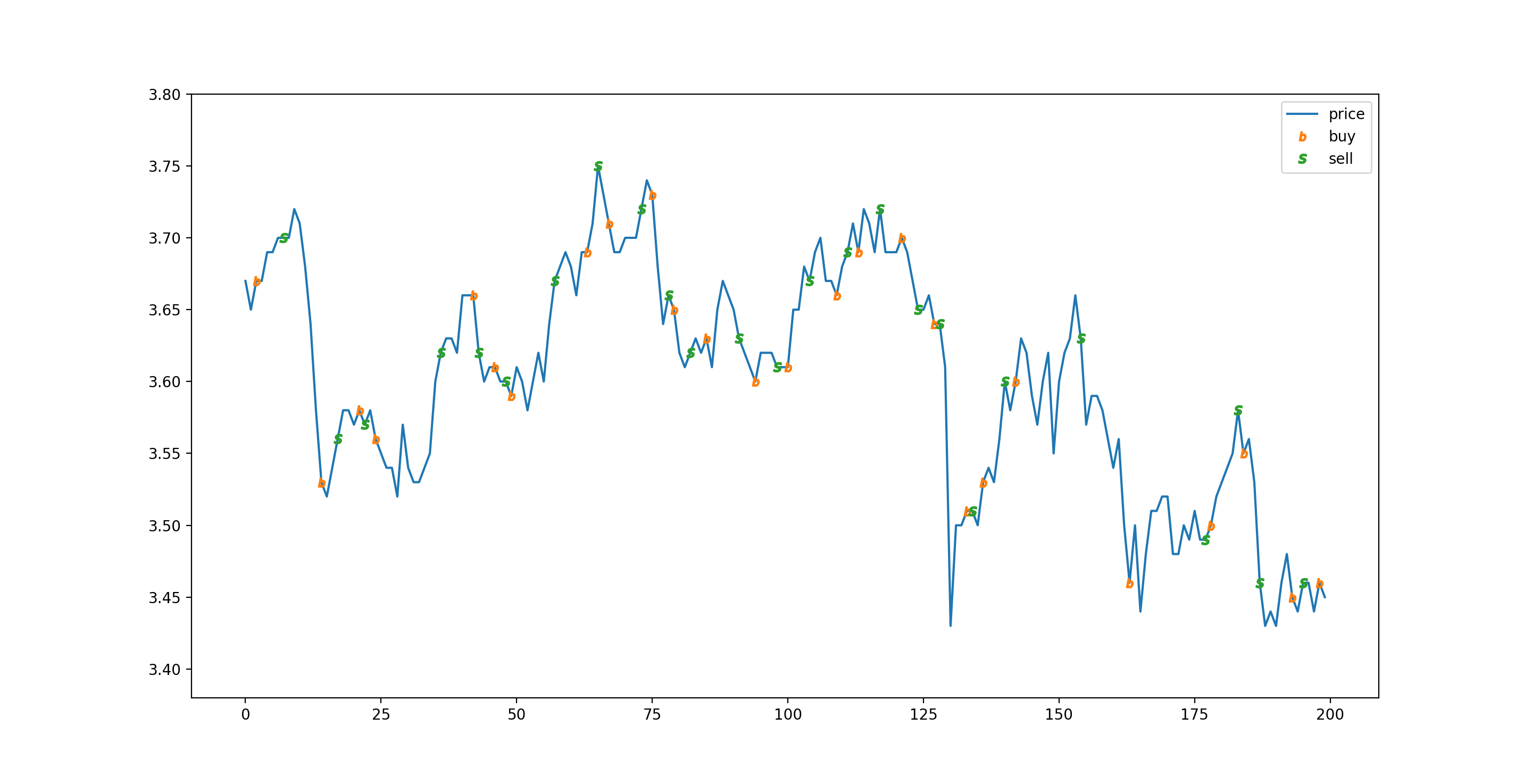
只看模拟结果可能会觉得模型很厉害,但实际上这只是个偶然,这次训练不能算是成功,因为正确率不高,和瞎猜差不多🤢。训练没有成功的原因有下:
- 股价的不确定因素太多了,只靠每天的收盘价和交易量是没有办法正确预测出趋势的
- 一般来说股价趋势短期预测比长期预测的准确率要高很多,因为短期预测的不确定因素比较少,但我没有找到公开的高频股价数据
- 单只股票的数据量很少,而且每只股票的股性都不一样 (依赖于操盘手),很难训练出通用的模型
除了上面的模型以外我还试了很多方式,例如把涨跌幅作为输入或者输出与加大减少模型的结构,但都没有找到可以确切预测出走势的模型。
你可能会忍不住去试试更多方式,甚至找到效果比较好的模型,但我作为一个老股民劝你一句,股海无边,回头是岸呀🤕。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 130
- 统信桌面专业版【全盘安装UOS系统】介绍 128
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 120
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 108
- 麒麟系统连接打印机常见问题及解决方法 28
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
