神经网络初探
1 有一个n维输入的单层感知机
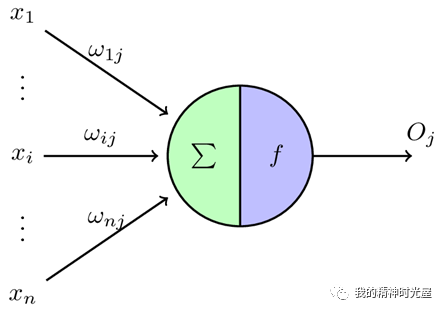
x1 至 x n x_nxn 为 n 维输入向量的各个分量,w 1 j w_{1j}w1j 至 w n j w_{nj}wnj为各个输入分量连接到感知机的权量(或称权值),theta 为阈值,f 为激活函数(又称为激励函数或传递函数),o 为标量输出。理想的激活函数通常为阶跃函数或者sigmoid函数。感知机的输出是输入向量x与权重向量w求得内积后,经激活函数f所得到的标量。
2 多层感知机
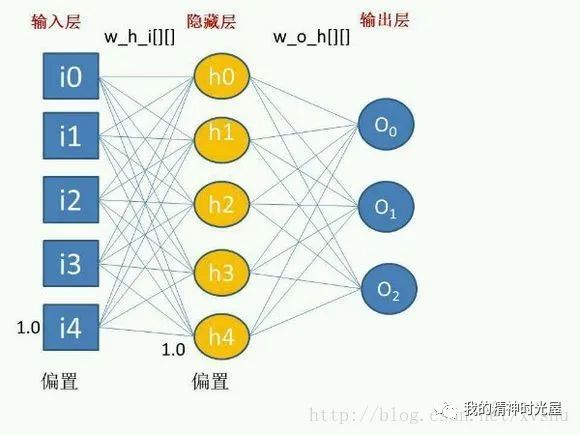
3 前向传播
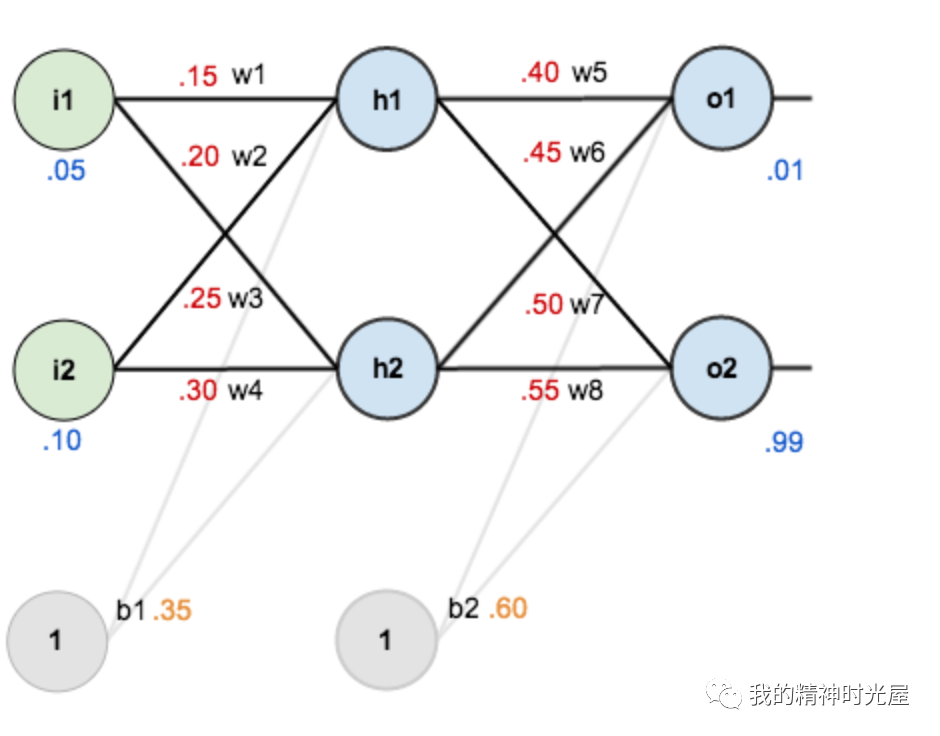
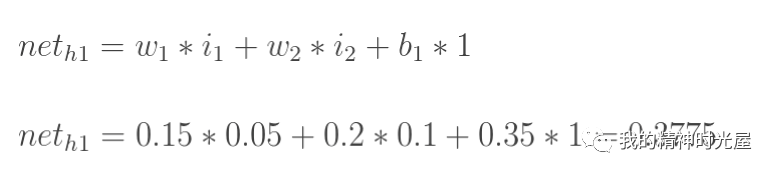
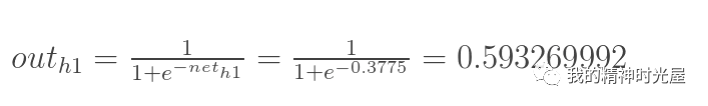
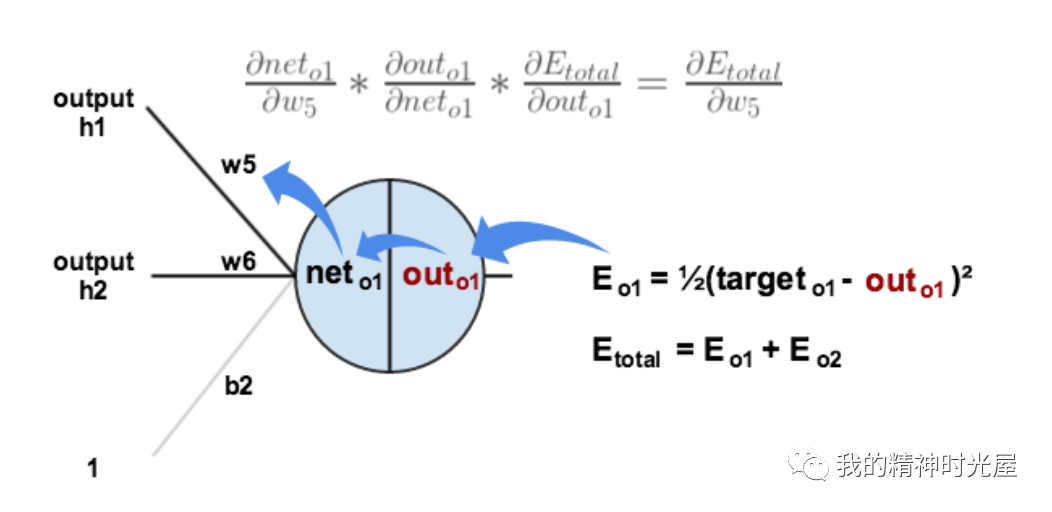
4 反向传播
5 卷积神经网络
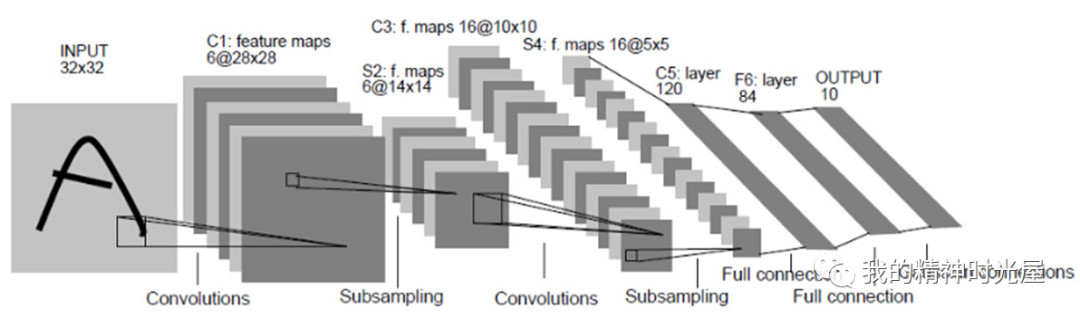
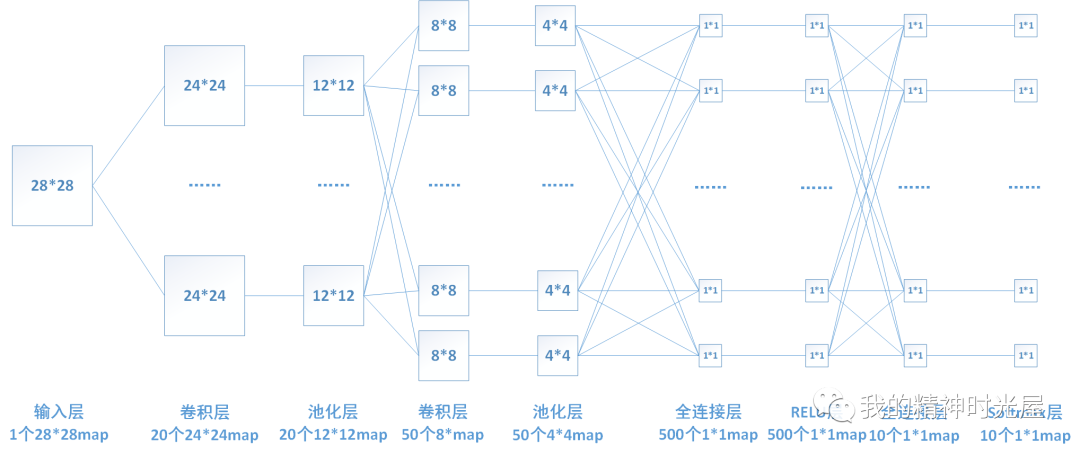
看图说话,这是一张卷积神经网络的图片,按顺序来是输入层,卷积层,池化层,卷积和池化层可以重复N次,然后是全连接层。
卷积层:用于对图像进行特征提取操作,其卷积核权重是共享权值的,对应的相关概念还包括步长,填充。
池化层:用于降低特征图大小,降低后续操作的计算量和参数量
全连接层:最终进行分类输出使用,本质就是多层感知机
6 卷积的过程是这样的

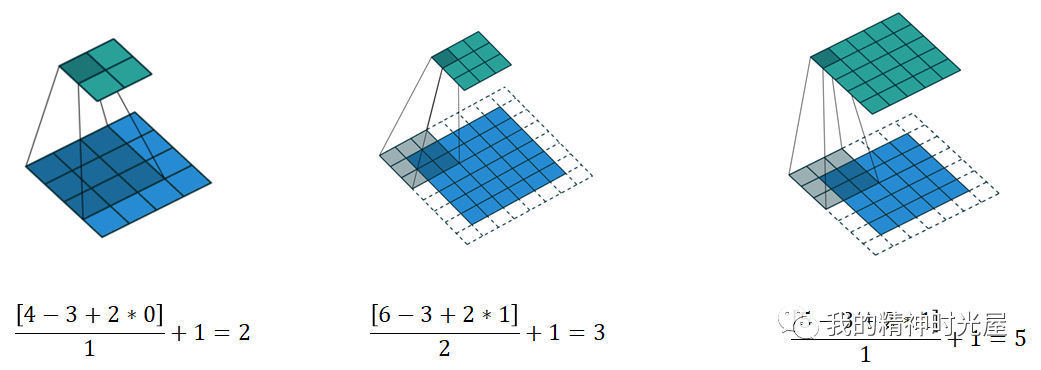
卷积需要注意的是填充(Padding)和步长(Stride)
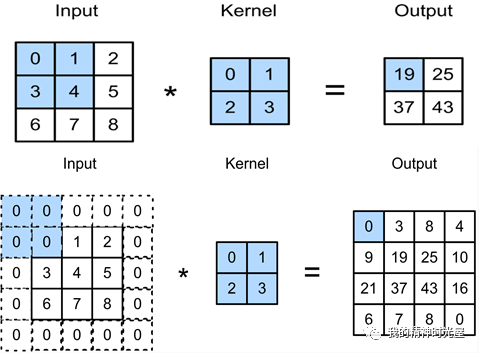
如图所示
7 池化的过程是这样的
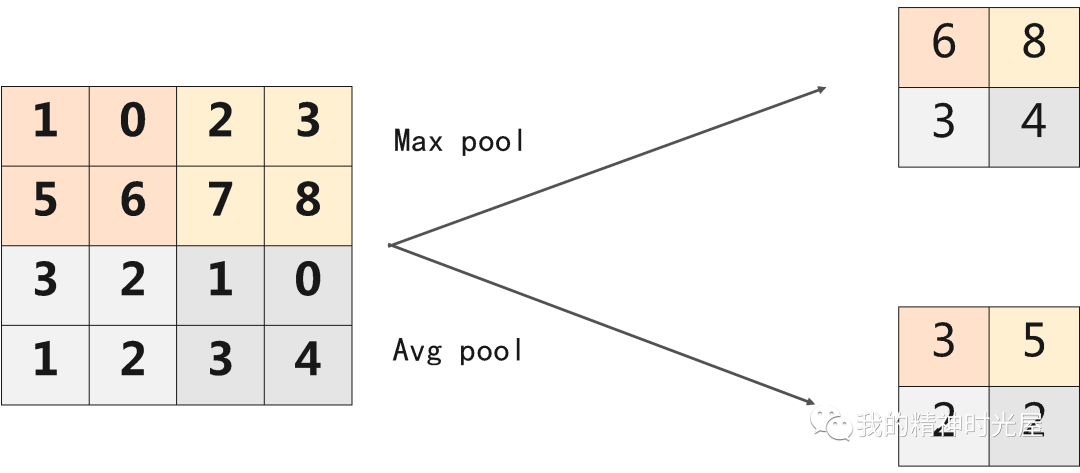
池化层的作用:使特征图变小,简化网络计算复杂度;压缩特征,提取主要特征
8 全连接层
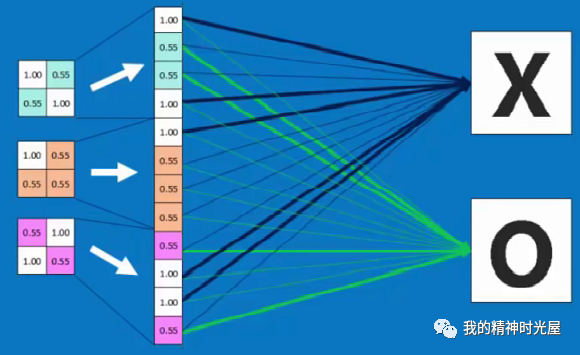
全连接一般会把卷积输出的二维特征图转化成一维的一个向量。
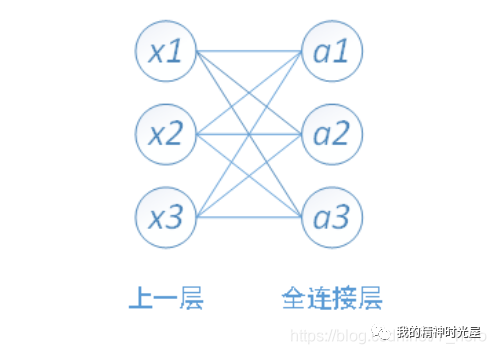
其中,x1、x2、x3为全连接层的输入,a1、a2、a3为输出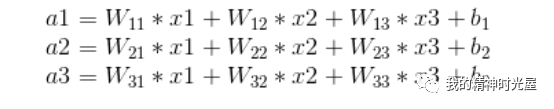
可以写成如下矩阵形式:
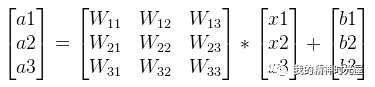
9 激活函数
激活函数是用来加入非线性因素的,因为线性模型的表达力不够。
假设如果没有激活函数的出现,你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,也就是说没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。那么网络的逼近能力就相当有限。正因为上面的原因,我们决定引入非线性函数作为激活函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可逼近任意函数)
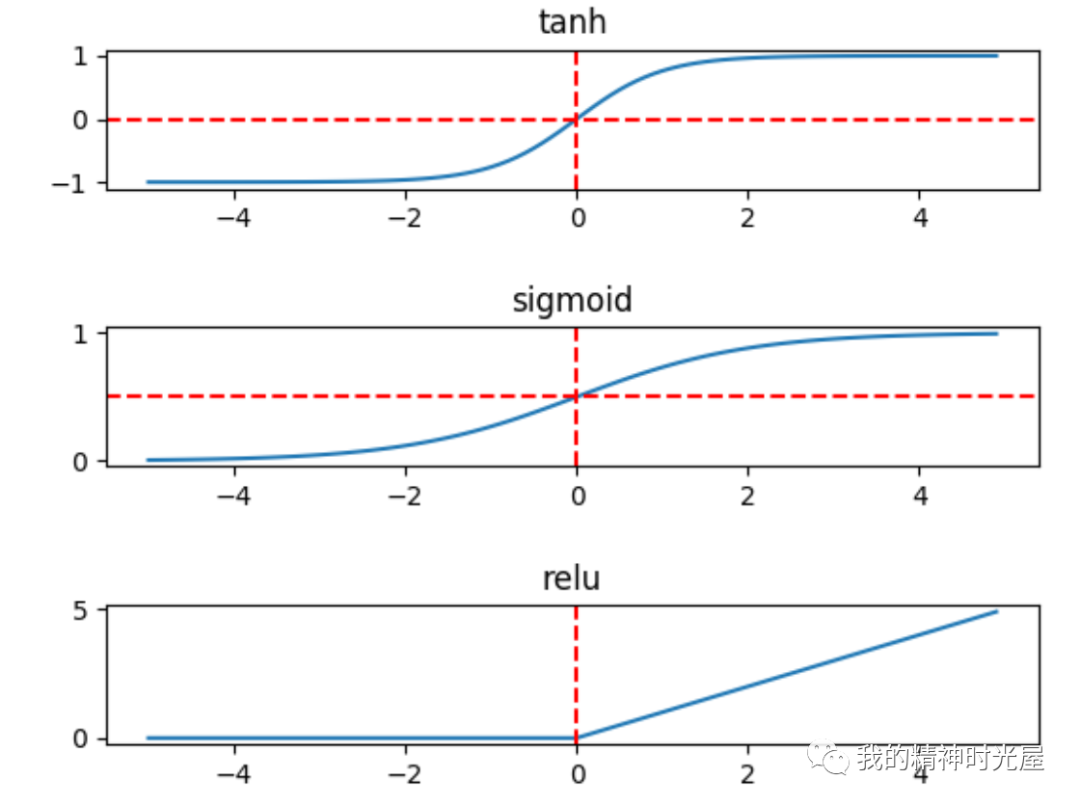
常见的激活函数有sigmoid、tanh和relu三种非线性函数
-
sigmoid: y = 1/(1 + e-x)
-
tanh: y = (ex - e-x)/(ex + e-x)
-
relu: y = max(0, x)
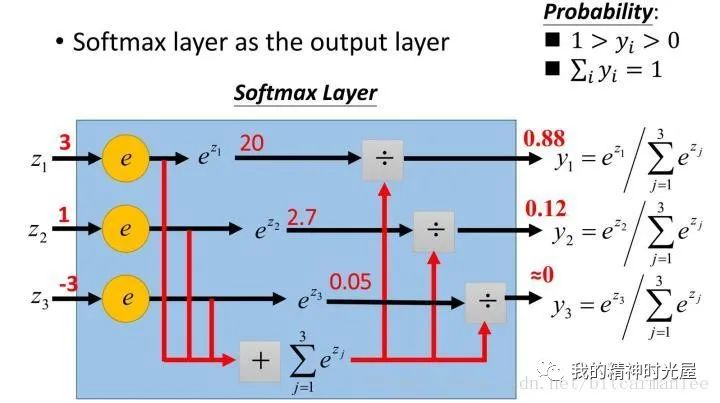
10 softmax函数
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
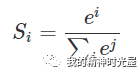
更形象的如下图表示:
11 dropout层
我们知道如果要训练一个大型的网络,而训练数据很少的话,那么很容易引起过拟合,一般情况我们会想到用正则化、或者减小网络规模。然而Hinton在2012年文献:《Improving neural networks by preventing co-adaptation of feature detectors》提出了,在每次训练的时候,随机让一半的特征检测器停过工作,这样可以提高网络的泛化能力,Hinton又把它称之为dropout。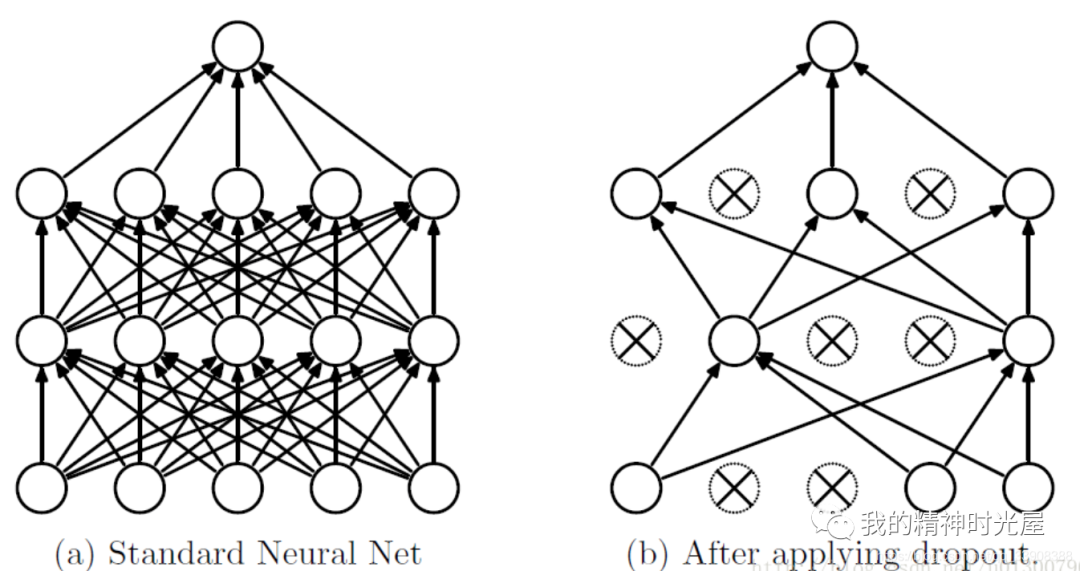
Hinton认为,过拟合可以通过阻止某些特征的协同作用来缓解。
12 为什么要用卷积来学习呢?
图像都是用方形矩阵来表达的,学习的本质就是要抽象出特征,以边缘检测为例。它就是识别数字图像中亮度变化明显的点,这些点连接起来往往是物体的边缘。
传统的边缘检测常用的方法包括一阶和二阶导数法,本质上都是利用一个卷积核在原图上进行滑动,只是其中各个位置的系数不同,比如3×3的sobel算子计算x方向的梯度幅度,使用的就是下面的卷积核算子。

如果要用sobel算子完成一次完整的边缘检测,就要同时检测x方向和y方向,然后进行融合。这就是两个通道的卷积,先用两个卷积核进行通道内的信息提取,再进行通道间的信息融合。
这就是卷积提取特征的本质,而所有基于卷积神经网络来学习的图像算法,都是通过不断的卷积来进行特征的抽象,直到实现网络的目标。
13 sobel算子

如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 分享如何统信UOS系统在屏蔽mysql显性的用户名称以及密码 614
- 分享免费开源高速下载器 577
- 分享如何在银河麒麟高级服务器操作系统V10SP3中需要启用内核审计功能。 572
- 通过shell脚本在统信UOS/麒麟系统中安装nginx 504
- 分享如何查看网卡中断的数量 422
- 分享查询网卡所在PCI插槽链路能力及当前链路状态 420
- 麒麟系统进行内存清理 413
- 统信UOS常见问题小总结 411
- 麒麟系统资源下载合集(适配各类cpu) 410
- winrar绿色无广告版分享 393
- 最近下载排行榜
- 分享如何统信UOS系统在屏蔽mysql显性的用户名称以及密码 0
- 分享免费开源高速下载器 0
- 分享如何在银河麒麟高级服务器操作系统V10SP3中需要启用内核审计功能。 0
- 通过shell脚本在统信UOS/麒麟系统中安装nginx 0
- 分享如何查看网卡中断的数量 0
- 分享查询网卡所在PCI插槽链路能力及当前链路状态 0
- 麒麟系统进行内存清理 0
- 统信UOS常见问题小总结 0
- 麒麟系统资源下载合集(适配各类cpu) 0
- winrar绿色无广告版分享 0

prtyaa 收益395.97元

zlj141319 收益228.77元

IT-feng 收益214.92元

1843880570 收益214.2元

风晓 收益208.24元

777 收益173.02元

哆啦漫漫喵 收益131.6元

Fhawking 收益106.6元

信创来了 收益105.97元

克里斯蒂亚诺诺 收益91.08元
