CoreCLR源码探索(六) NullReferenceException是如何发生的(二)
CoreCLR中的处理 (Linux, OSX)
我们先来看Linux上CoreCLR是如何处理的, 以下代码来源于CoreCLR 1.1.0, OSX上的处理逻辑和Linux一样.
首先CoreCLR会注册SIGSEGV的处理器, 在pal\src\exception\signal.cpp中可以找到以下的代码
BOOL SEHInitializeSignals(DWORD flags)
{
TRACE("Initializing signal handlers\n");
/* we call handle_signal for every possible signal, even
if we don't provide a signal handler.
handle_signal will set SA_RESTART flag for specified signal.
Therefore, all signals will have SA_RESTART flag set, preventing
slow Unix system calls from being interrupted. On systems without
siginfo_t, SIGKILL and SIGSTOP can't be restarted, so we don't
handle those signals. Both the Darwin and FreeBSD man pages say
that SIGKILL and SIGSTOP can't be handled, but FreeBSD allows us
to register a handler for them anyway. We don't do that.
see sigaction man page for more details
*/
handle_signal(SIGILL, sigill_handler, &g_previous_sigill);
handle_signal(SIGTRAP, sigtrap_handler, &g_previous_sigtrap);
handle_signal(SIGFPE, sigfpe_handler, &g_previous_sigfpe);
handle_signal(SIGBUS, sigbus_handler, &g_previous_sigbus);
handle_signal(SIGSEGV, sigsegv_handler, &g_previous_sigsegv);
handle_signal(SIGINT, sigint_handler, &g_previous_sigint);
handle_signal(SIGQUIT, sigquit_handler, &g_previous_sigquit);
这里除了注册SIGSEGV以外还会注册其他信号的处理器, 接下来看sigsegv_handler的内容:
static void sigsegv_handler(int code, siginfo_t *siginfo, void *context)
{
if (PALIsInitialized())
{
// TODO: First variable parameter says whether a read (0) or write (non-0) caused the
// fault. We must disassemble the instruction at record.ExceptionAddress
// to correctly fill in this value.
if (common_signal_handler(code, siginfo, context, 2, (size_t)0, (size_t)siginfo->si_addr))
{
return;
}
}
if (g_previous_sigsegv.sa_sigaction != NULL)
{
g_previous_sigsegv.sa_sigaction(code, siginfo, context);
}
else
{
// Restore the original or default handler and restart h/w exception
restore_signal(code, &g_previous_sigsegv);
}
PROCNotifyProcessShutdown();
}
common_signal_handler的内容:
static bool common_signal_handler(int code, siginfo_t *siginfo, void *sigcontext, int numParams, ...)
{
sigset_t signal_set;
CONTEXT *contextRecord;
EXCEPTION_RECORD *exceptionRecord;
native_context_t *ucontext;
ucontext = (native_context_t *)sigcontext;
AllocateExceptionRecords(&exceptionRecord, &contextRecord);
// 把信号转换为例外代码, 这里的例外代码等于windows上的STATUS_ACCESS_VIOLATION (0xC0000005L)
exceptionRecord->ExceptionCode = CONTEXTGetExceptionCodeForSignal(siginfo, ucontext);
exceptionRecord->ExceptionFlags = EXCEPTION_IS_SIGNAL;
exceptionRecord->ExceptionRecord = NULL;
exceptionRecord->ExceptionAddress = GetNativeContextPC(ucontext);
exceptionRecord->NumberParameters = numParams;
va_list params;
va_start(params, numParams);
for (int i = 0; i < numParams; i++)
{
exceptionRecord->ExceptionInformation[i] = va_arg(params, size_t);
}
// 捕捉例外发生时的上下文
// Pre-populate context with data from current frame, because ucontext doesn't have some data (e.g. SS register)
// which is required for restoring context
RtlCaptureContext(contextRecord);
ULONG contextFlags = CONTEXT_CONTROL | CONTEXT_INTEGER | CONTEXT_FLOATING_POINT;
#if defined(_AMD64_)
contextFlags |= CONTEXT_XSTATE;
#endif
// Fill context record with required information. from pal.h:
// On non-Win32 platforms, the CONTEXT pointer in the
// PEXCEPTION_POINTERS will contain at least the CONTEXT_CONTROL registers.
CONTEXTFromNativeContext(ucontext, contextRecord, contextFlags);
/* Unmask signal so we can receive it again */
sigemptyset(&signal_set);
sigaddset(&signal_set, code);
int sigmaskRet = pthread_sigmask(SIG_UNBLOCK, &signal_set, NULL);
if (sigmaskRet != 0)
{
ASSERT("pthread_sigmask failed; error number is %d\n", sigmaskRet);
}
contextRecord->ContextFlags |= CONTEXT_EXCEPTION_ACTIVE;
// The exception object takes ownership of the exceptionRecord and contextRecord
PAL_SEHException exception(exceptionRecord, contextRecord);
// 转换为和windows一致的SEH例外类型并继续处理
if (SEHProcessException(&exception))
{
// Exception handling may have modified the context, so update it.
CONTEXTToNativeContext(contextRecord, ucontext);
return true;
}
return false;
}
继续追下去会很长, 这里就只贴跟踪的调用流程了:
触发 sigsegv_handler (pal\src\exception\signal.cpp)
调用 common_signal_handler (pal\src\exception\signal.cpp)
调用 SEHProcessException (pal\src\exception\seh.cpp)
调用 HandleHardwareException (vm\exceptionhandling.cpp)
调用 DispatchManagedException (vm\exceptionhandling.cpp)
调用 UnwindManagedExceptionPass1 (vm\exceptionhandling.cpp:4503)
调用 ProcessCLRException (vm\exceptionhandling.cpp:751)
调用 UnwindManagedExceptionPass2 (vm\exceptionhandling.cpp:4357)
调用 ProcessCLRException (vm\exceptionhandling.cpp:751)
调用 ExceptionTracker::GetOrCreateTracker (vm\exceptionhandling.cpp:3613)
调用 ExceptionTracker::CreateThrowable (vm\exceptionhandling.cpp:4004)
调用 CreateCOMPlusExceptionObject (vm\excep.cpp:6978)
调用 MapWin32FaultToCOMPlusException (vm\excep.cpp:6996)
在这里会把STATUS_ACCESS_VIOLATION转换为NullReferenceException
转换到的NullReferenceException是一个预先分配好的全局对象
调用 ExceptionTracker::ProcessOSExceptionNotification (vm\exceptionhandling.cpp:1589)
这个函数会调用finally中的代码
调用 ExceptionTracker::ProcessManagedCallFrame (vm\exceptionhandling.cpp:2321)
调用 ExceptionTracker::CallHandler (vm\exceptionhandling.cpp:3273)
调用 ExceptionTracker::ResumeExecution (vm\exceptionhandling.cpp:3972)
调用 RtlRestoreContext (pal\src\arch\i386\context2.S)
在这里会跳到对应的处理例外(catch)的代码
跳过去以后会继续处理, 不再返回
总结:
- 在Linux上
- 如果对象是null并且访问对象的函数或者成员, 会触发SIGSEGV信号
- CoreCLR捕捉到SIGSEGV信号后会根据信号生成类似Windows形式的EXCEPTION_POINTERS结构体
- 这是为了可以和Windows共享处理的代码
- 处理例外时, 根据例外代码(0xC0000005L)转换为CLR中的NullReferenceException的对象
- 回滚堆栈和调用finally中的代码
- 跳到对应的处理例外(catch)的代码
例外处理不是这一篇的重点所以这里我就不详细解释了(目前还未弄清楚).
CoreCLR中的处理 (Windows)
在Windows上CoreCLR会注册一个VectoredHandler用于处理硬件例外:
这是vm\excep.cpp中的CLRAddVectoredHandlers函数, 启动时会调用
void CLRAddVectoredHandlers(void)
{
#ifndef FEATURE_PAL
// We now install a vectored exception handler on all supporting Windows architectures.
g_hVectoredExceptionHandler = AddVectoredExceptionHandler(TRUE, (PVECTORED_EXCEPTION_HANDLER)CLRVectoredExceptionHandlerShim);
if (g_hVectoredExceptionHandler == NULL)
{
LOG((LF_EH, LL_INFO100, "CLRAddVectoredHandlers: AddVectoredExceptionHandler() failed\n"));
COMPlusThrowHR(E_FAIL);
}
LOG((LF_EH, LL_INFO100, "CLRAddVectoredHandlers: AddVectoredExceptionHandler() succeeded\n"));
#endif // !FEATURE_PAL
}
当硬件异常发生时会调用这个处理器, 代码同样在vm\excep.cpp, 如下:
LONG WINAPI CLRVectoredExceptionHandlerShim(PEXCEPTION_POINTERS pExceptionInfo)
{
//
// HandleManagedFault will take a Crst that causes an unbalanced
// notrigger scope, and this contract will whack the thread's
// ClrDebugState to what it was on entry in the dtor, which causes
// us to assert when we finally release the Crst later on.
//
// CONTRACTL
// {
// NOTHROW;
// GC_NOTRIGGER;
// MODE_ANY;
// }
// CONTRACTL_END;
//
// WARNING WARNING WARNING WARNING WARNING WARNING WARNING
//
// o This function should not call functions that acquire
// synchronization objects or allocate memory, because this
// can cause problems. <-- quoteth MSDN -- probably for
// the same reason as we cannot use LOG(); we'll recurse
// into a stack overflow.
//
// o You cannot use LOG() in here because that will trigger an
// exception which will cause infinite recursion with this
// function. We work around this by ignoring all non-error
// exception codes, which serves as the base of the recursion.
// That way, we can LOG() from the rest of the function
//
// The same goes for any function called by this
// function.
//
// WARNING WARNING WARNING WARNING WARNING WARNING WARNING
//
// If exceptions (or runtime) have been disabled, then simply return.
if (g_fForbidEnterEE || g_fNoExceptions)
{
return EXCEPTION_CONTINUE_SEARCH;
}
// WARNING
//
// We must preserve this so that GCStress=4 eh processing doesnt kill last error.
// Note that even GetThread below can affect the LastError.
// Keep this in mind when adding code above this line!
//
// WARNING
DWORD dwLastError = GetLastError();
#if defined(_TARGET_X86_)
// Capture the FPU state before we do anything involving floating point instructions
FPUStateHolder captureFPUState;
#endif // defined(_TARGET_X86_)
#ifdef FEATURE_INTEROP_DEBUGGING
// For interop debugging we have a fancy exception queueing stunt. When the debugger
// initially gets the first chance exception notification it may not know whether to
// continue it handled or unhandled, but it must continue the process to allow the
// in-proc helper thread to work. What it does is continue the exception unhandled which
// will let the thread immediately execute to this point. Inside this worker the thread
// will block until the debugger knows how to continue the exception. If it decides the
// exception was handled then we immediately resume execution as if the exeption had never
// even been allowed to run into this handler. If it is unhandled then we keep processing
// this handler
//
// WARNING: This function could potentially throw an exception, however it should only
// be able to do so when an interop debugger is attached
if(g_pDebugInterface != NULL)
{
if(g_pDebugInterface->FirstChanceSuspendHijackWorker(pExceptionInfo->ContextRecord,
pExceptionInfo->ExceptionRecord) == EXCEPTION_CONTINUE_EXECUTION)
return EXCEPTION_CONTINUE_EXECUTION;
}
#endif
// 获取例外代码
DWORD dwCode = pExceptionInfo->ExceptionRecord->ExceptionCode;
if (dwCode == DBG_PRINTEXCEPTION_C || dwCode == EXCEPTION_VISUALCPP_DEBUGGER)
{
return EXCEPTION_CONTINUE_SEARCH;
}
#if defined(_TARGET_X86_)
if (dwCode == EXCEPTION_BREAKPOINT || dwCode == EXCEPTION_SINGLE_STEP)
{
// For interop debugging, debugger bashes our managed exception handler.
// Interop debugging does not work with real vectored exception handler :(
return EXCEPTION_CONTINUE_SEARCH;
}
#endif
bool bIsGCMarker = false;
#ifdef USE_REDIRECT_FOR_GCSTRESS
// This is AMD64 & ARM specific as the macro above is defined for AMD64 & ARM only
bIsGCMarker = IsGcMarker(dwCode, pExceptionInfo->ContextRecord);
#elif defined(_TARGET_X86_) && defined(HAVE_GCCOVER)
// This is the equivalent of the check done in COMPlusFrameHandler, incase the exception is
// seen by VEH first on x86.
bIsGCMarker = IsGcMarker(dwCode, pExceptionInfo->ContextRecord);
#endif // USE_REDIRECT_FOR_GCSTRESS
// Do not update the TLS with exception details for exceptions pertaining to GCStress
// as they are continueable in nature.
if (!bIsGCMarker)
{
SaveCurrentExceptionInfo(pExceptionInfo->ExceptionRecord, pExceptionInfo->ContextRecord);
}
LONG result = EXCEPTION_CONTINUE_SEARCH;
// If we cannot obtain a Thread object, then we have no business processing any
// exceptions on this thread. Indeed, even checking to see if the faulting
// address is in JITted code is problematic if we have no Thread object, since
// this thread will bypass all our locks.
Thread *pThread = GetThread();
// Also check if the exception was in the EE or not
BOOL fExceptionInEE = FALSE;
if (!pThread)
{
// Check if the exception was in EE only if Thread object isnt available.
// This will save us from unnecessary checks
fExceptionInEE = IsIPInEE(pExceptionInfo->ExceptionRecord->ExceptionAddress);
}
// We are going to process the exception only if one of the following conditions is true:
//
// 1) We have a valid Thread object (implies exception on managed thread)
// 2) Not a valid Thread object but the IP is in the execution engine (implies native thread within EE faulted)
// 如果例外来源是运行引擎中的代码(托管代码), 或者有Thread对象(pinvoke代码)则继续处理
if (pThread || fExceptionInEE)
{
if (!bIsGCMarker)
result = CLRVectoredExceptionHandler(pExceptionInfo);
else
result = EXCEPTION_CONTINUE_EXECUTION;
if (EXCEPTION_EXECUTE_HANDLER == result)
{
result = EXCEPTION_CONTINUE_SEARCH;
}
#ifdef _DEBUG
#ifndef FEATURE_PAL
#ifndef WIN64EXCEPTIONS
{
CantAllocHolder caHolder;
PEXCEPTION_REGISTRATION_RECORD pRecord = GetCurrentSEHRecord();
while (pRecord != EXCEPTION_CHAIN_END)
{
STRESS_LOG2(LF_EH, LL_INFO10000, "CLRVectoredExceptionHandlerShim: FS:0 %p:%p\n",
pRecord, pRecord->Handler);
pRecord = pRecord->Next;
}
}
#endif // WIN64EXCEPTIONS
{
// The call to "CLRVectoredExceptionHandler" above can return EXCEPTION_CONTINUE_SEARCH
// for different scenarios like StackOverFlow/SOFT_SO, or if it is forbidden to enter the EE.
// Thus, if we dont have a Thread object for the thread that has faulted and we came this far
// because the fault was in MSCORWKS, then we work with the frame chain below only if we have
// valid Thread object.
if (pThread)
{
CantAllocHolder caHolder;
TADDR* sp;
sp = (TADDR*)&sp;
DWORD count = 0;
void* stopPoint = pThread->GetCachedStackBase();
// If Frame chain is corrupted, we may get AV while accessing frames, and this function will be
// called recursively. We use Frame chain to limit our search range. It is not disaster if we
// can not use it.
if (!(dwCode == STATUS_ACCESS_VIOLATION &&
IsIPInEE(pExceptionInfo->ExceptionRecord->ExceptionAddress)))
{
// Find the stop point (most jitted function)
Frame* pFrame = pThread->GetFrame();
for(;;)
{
// skip GC frames
if (pFrame == 0 || pFrame == (Frame*) -1)
break;
Frame::ETransitionType type = pFrame->GetTransitionType();
if (type == Frame::TT_M2U || type == Frame::TT_InternalCall)
{
stopPoint = pFrame;
break;
}
pFrame = pFrame->Next();
}
}
STRESS_LOG0(LF_EH, LL_INFO100, "CLRVectoredExceptionHandlerShim: stack");
while (count < 20 && sp < stopPoint)
{
if (IsIPInEE((BYTE*)*sp))
{
STRESS_LOG1(LF_EH, LL_INFO100, "%pK\n", *sp);
count ++;
}
sp += 1;
}
}
}
#endif // !FEATURE_PAL
#endif // _DEBUG
#ifndef WIN64EXCEPTIONS
{
CantAllocHolder caHolder;
STRESS_LOG1(LF_EH, LL_INFO1000, "CLRVectoredExceptionHandlerShim: returning %d\n", result);
}
#endif // WIN64EXCEPTIONS
}
SetLastError(dwLastError);
return result;
}
同样的, 继续跟下去会非常长我就只贴跟踪流程了:
CLRVectoredExceptionHandlerShim (vm\excep.cpp:8171)
调用 CLRVectoredExceptionHandler (vm\excep.cpp:7464)
调用 CLRVectoredExceptionHandlerPhase2 (vm\excep.cpp:7622)
调用 CLRVectoredExceptionHandlerPhase3 (vm\excep:7803)
调用 HandleManagedFault (vm\excep:7311)
调用 SetNakedThrowHelperArgRegistersInContext (vm\excep:7297)
把引发例外的指令地址存到rcx (第一个参数)
设置IP到NakedThrowHelper (vm\amd64\RedirectedHandledJITCase.asm)
NakedThrowHelper (vm\amd64\RedirectedHandledJITCase.asm)
调用 LinkFrameAndThrow (vm\excep.cpp:7278)
调用 RaiseException (https://msdn.microsoft.com/en-us/library/windows/desktop/ms680552(v=vs.85).aspx)
NakedThrowHelper 经过包装
GenerateRedirectedStubWithFrame NakedThrowHelper, FixContextHandler, NakedThrowHelper2 (vm\amd64\RedirectedHandledJITCase.asm)
RaiseException时会使用FixContextHandler处理
宏GenerateRedirectedStubWithFrame使用了宏NESTED_ENTRY, 可以参考vm\amd64\AsmMacros.inc
FixContextHandler (vm\exceptionhandler.cpp:5631)
调用 FixupDispatcherContext (vm\exceptionhandler.cpp:5525)
调用 FixupDispatcherContext 的另一个重载 (vm\exceptionhandler.cpp:5399)
设置 pDispatcherContext->LanguageHandler = (PEXCEPTION_ROUTINE)GetEEFuncEntryPoint(ProcessCLRException);
ProcessCLRException (vm\exceptionhandling.cpp:751)
调用 ExceptionTracker::GetOrCreateTracker (vm\exceptionhandling.cpp:3613)
调用 ExceptionTracker::CreateThrowable (vm\exceptionhandling.cpp:4004)
调用 CreateCOMPlusExceptionObject (vm\excep.cpp:6978)
调用 MapWin32FaultToCOMPlusException (vm\excep.cpp:6996)
在这里会把STATUS_ACCESS_VIOLATION转换为NullReferenceException
转换到的NullReferenceException是一个预先分配好的全局对象
调用 ExceptionTracker::ProcessOSExceptionNotification (vm\exceptionhandling.cpp:1589)
这个函数会调用finally中的代码
调用 ExceptionTracker::ProcessManagedCallFrame (vm\exceptionhandling.cpp:2321)
调用 ExceptionTracker::CallHandler (vm\exceptionhandling.cpp:3273)
调用 ClrUnwindEx (vm\exceptionhandling.cpp:5229)
调用 RtlUnwindEx (Windows自带的API)
在这里会跳到对应的处理例外(catch)的代码
跳过去以后会继续处理, 不再返回
总结:
- 在Windows上
- 如果对象是null并且访问对象的函数或者成员, 会触发硬件异常
- CoreCLR通过CLRVectoredExceptionHandlerShim捕捉到异常
- 调用原生的RaiseException抛出例外给ProcessCLRException处理
- 处理例外时, 根据例外代码(0xC0000005L)转换为CLR中的NullReferenceException的对象
- 回滚堆栈和调用finally中的代码
- 跳到对应的处理例外(catch)的代码
特殊情况的null检查
注意到上面第二份代码中的访问异常是在访问了0x8的时候出现的吗?
想想如果成员在更后面的位置, 例如0x10000, 并且在0x10000有内容存在的时候还可以检测出来吗?
这里我模拟一下特殊情况下的null检查, 看看CoreCLR是否可以正确处理.
测试使用的代码:
using System;
using System.Diagnostics;
using System.Reflection;
using System.Runtime.InteropServices;
namespace ConsoleApp1
{
class Program
{
struct st_32 { long a; long b; long c; long d; }
struct st_128 { st_32 a; st_32 b; st_32 c; st_32 d; }
struct st_512 { st_128 a; st_128 b; st_128 c; st_128 d; }
struct st_2048 { st_512 a; st_512 b; st_512 c; st_512 d; }
struct st_10240 { st_2048 a; st_2048 b; st_2048 c; st_2048 d; st_2048 e; }
struct st_51200 { st_10240 a; st_10240 b; st_10240 c; st_10240 d; st_10240 e; }
struct st_65536 { st_51200 a; st_10240 b; st_2048 c; st_2048 d; }
struct padding { st_10240 a; st_10240 b; st_10240 c; public int x; }
class A
{
public padding a;
}
const uint PAGE_EXECUTE_READWRITE = 0x40;
const uint MEM_COMMIT = 0x1000;
const uint MEM_RESERVE = 0x2000;
[DllImport("kernel32.dll", SetLastError = true)]
static extern IntPtr VirtualAlloc(IntPtr lpAddress, uint dwSize, uint flAllocationType, uint flProtect);
static void Main(string[] args)
{
var body = new byte[4] { 1, 0, 0, 0 };
IntPtr buf = VirtualAlloc((IntPtr)0x10000, 1024, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE);
buf = (IntPtr)0x10008; // 10000 + 8, 8是method table指针的大小
Marshal.Copy(body, 0, buf, body.Length);
var a = new A();
a = null;
Console.WriteLine(a.a.x);
}
}
}
运行时的汇编代码:
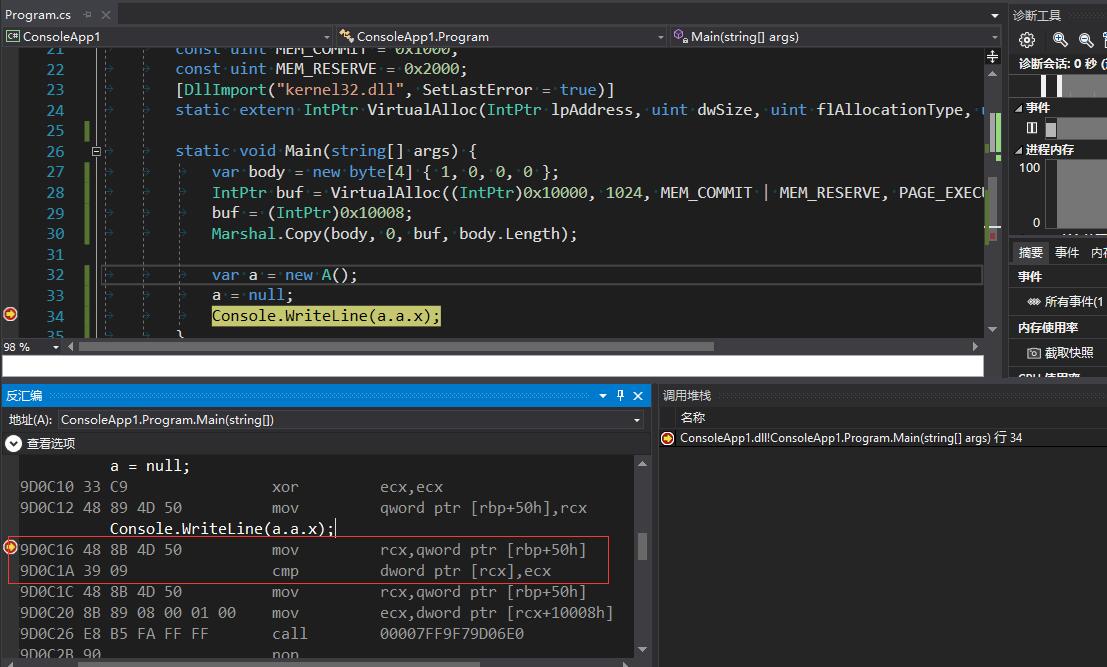
注意图中红框的部分, CoreCLR加了额外的cmp, 成功避过了使用VirtualAlloc设下的陷阱.
你也可能会问, 如果使用VirtualAlloc来在0x8分配内存可以骗过CoreCLR吗?
事实上VirtualAlloc不能在0x8分配内存, 可以分配到的虚拟内存地址有范围限制,
如果成员的位置大于最小可以分配的虚拟内存地址, 则CoreCLR会插入一个额外的检查, 所以这种情况是骗不过CoreCLR的.
性能测试
我们再来测下自动抛出NullReferenceException和手动抛出NullReferenceException性能有多大的差别
测试的代码如下:
public static string GetString()
{
return null;
}
public static void BenchmarkNullReferenceException()
{
for (int x = 0; x < 100000; ++x)
{
try
{
string str = GetString();
int length = str.Length;
}
catch (Exception ex)
{
}
}
}
public static void BenchmarkManualNullReferenceException() {
for (int x = 0; x < 100000; ++x)
{
try
{
string str = GetString();
if (str == null)
{
throw new NullReferenceException();
}
int length = str.Length;
}
catch (Exception ex)
{
}
}
}
测试结果:
BenchmarkNullReferenceException: 0.9024312s
BenchmarkManualNullReferenceException: 0.9746265s
测试的结果比较出乎意料,
BenchmarkNullReferenceException和BenchmarkManualNullReferenceException在Debug和Release配置下所花的时间都是1秒左右,
这也说明了处理硬件异常的消耗相对于处理CLR异常的消耗并不大, 甚至还比手动抛出的消耗更小.
为什么要这样实现null检查
最常见也是最容易理解的null检查可能是在底层生成类似test rcx, rcx; jne 1f; call ThrowNullReferenceException; 1:的代码,
然而CoreCLR并不采用这种办法, 我个人推测有这些原因:
- 可以节省生成的代码大小, 一条检查用的cmp指令只占2个字节
- 可以提升检查性能, 例如访问成员时直接使用
mov 寄存器, [对象寄存器+成员偏移值]即可同时取出值并检查是否null, 不需要额外的检查指令 - 可以捕捉非托管代码中的异常, 调用使用c写的代码中发生了内存访问错误也可以捕捉到
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 123
- 统信桌面专业版【全盘安装UOS系统】介绍 118
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 109
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 102
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
