CoreCLR源码探索(三) GC内存分配器的内部实现 (一)
服务器GC和工作站GC
关于服务器GC和工作站GC的区别, 网上已经有很多资料讲解这篇就不再说明了.
我们来看服务器GC和工作站GC的代码是怎么区别开来的.
默认编译CoreCLR会对同一份代码以使用服务器GC还是工作站GC的区别编译两次, 分别在SVR和WKS命名空间中:
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcsvr.cpp
#define SERVER_GC 1
namespace SVR {
#include "gcimpl.h"
#include "gc.cpp"
}
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcwks.cpp
#ifdef SERVER_GC
#undef SERVER_GC
#endif
namespace WKS {
#include "gcimpl.h"
#include "gc.cpp"
}
当定义了SERVER_GC时, MULTIPLE_HEAPS和会被同时定义.
定义了MULTIPLE_HEAPS会使用多个堆(Heap), 服务器GC每个cpu核心都会对应一个堆(默认), 工作站GC则全局使用同一个堆.
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcimpl.h
#ifdef SERVER_GC
#define MULTIPLE_HEAPS 1
#endif // SERVER_GC
后台GC无论是服务器GC还是工作站GC都会默认支持, 但运行时不一定会启用.
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcpriv.h
#define BACKGROUND_GC //concurrent background GC (requires WRITE_WATCH)
我们从https://www.microsoft.com/net下回来的CoreCLR安装包中已经包含了服务器GC和后台GC的支持,但默认不会开启.
开启它们可以修改project.json中的·runtimeOptions·节, 例子如下:
{
"runtimeOptions": {
"configProperties": {
"System.GC.Server": true,
"System.GC.Concurrent": true
}
}
}
设置后发布项目可以看到coreapp.runtimeconfig.json, 运行时会只看这个文件.
微软官方的文档: https://docs.microsoft.com/en-us/dotnet/articles/core/tools/project-json
GC相关的类和它们的关系
我先用两张图来解释服务器GC和工作站GC下GC相关的类的关系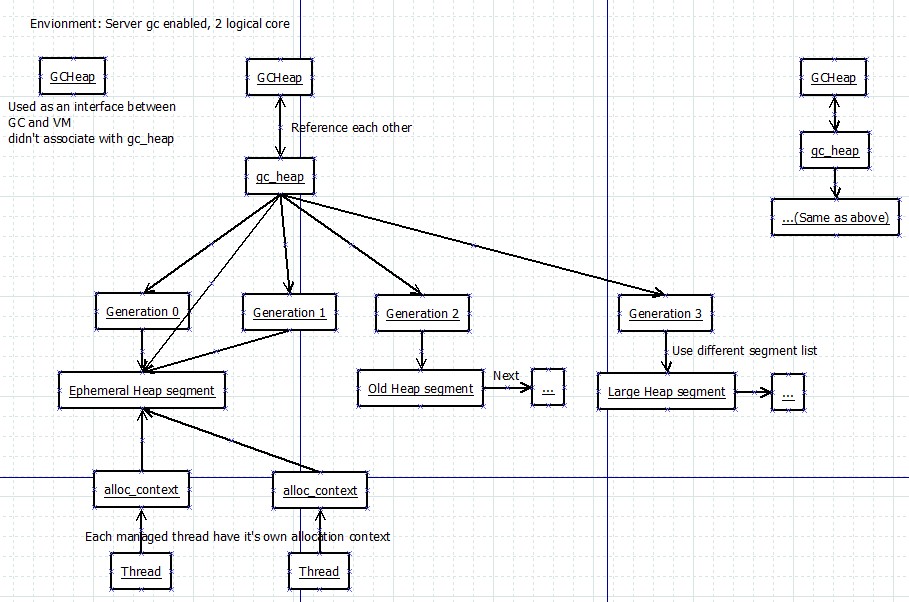
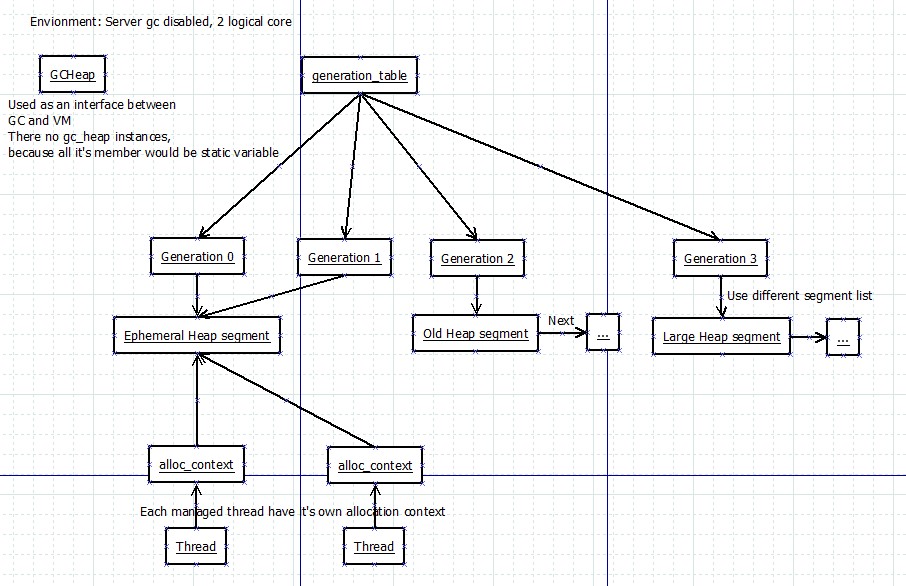
图中一共有5个类型
- GCHeap
- 实现了IGCHeap接口, 公开GC层的接口给EE(运行引擎)层调用
- 在工作站GC下只有一个实例, 不会关联gc_heap对象, 因为工作站GC下gc_heap的所有成员都会被定义为静态变量
- 在服务器GC下有1+cpu核心数个实例(默认), 第一个实例用于当接口, 其它对应cpu核心的实例都会各关联一个gc_heap实例
- gc_heap
- 内部的使用的堆类型, 用于负责内存的分配和回收
- 在工作站GC下无实例, 所有成员都会定义为静态变量
- 在工作站GC下generation_table这个成员不会被定义, 而是使用全局变量generation_table
- 在服务器GC下有cpu核心数个实例(默认), 各关联一个GCHeap实例
- generation
- 储存各个代的信息, 例如地址范围和使用的段
- 储存在generation_table中, 一个generation_table包含了5个generation, 前面的是0 1 2 3代, 最后一个不会被初始化和使用
- 在工作站GC下只有1个generation_table, 就是全局变量generation_table
- 在服务器GC下generation_table是gc_heap的成员, 有多少个gc_heap就有多少个generation_table
- heap_segment
- 堆段, 供分配器使用的一段内存, 用链表形式保存
- 每个gc_heap中都有一个或一个以上的segment
- 每个gc_heap中都有一个ephemeral heap segment(用于存放最年轻对象)
- 每个gc_heap中都有一个large heap segment(用于存放大对象)
- 在工作站GC下segment的默认大小是256M(0x10000000字节)
- 在服务器GC下segment的默认大小是4G(0x100000000字节)
- alloc_context
- 分配上下文, 指向segment中的一个范围, 用于实际分配对象
- 每个线程都有自己的分配上下文, 因为指向的范围不一样所以只要当前范围还有足够空间, 分配对象时不需要线程锁
- 分配上下文的默认范围是8K, 也叫分配单位(Allocation Quantum)
- 分配小对象时会从这8K中分配, 分配大对象时则会直接从段(segment)中分配
- 代0(gen 0)还有一个默认的分配上下文供内部使用, 和线程无关
GCHeap的源代码摘要:
GCHeap的定义: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcimpl.h#L61
这里我只列出这篇文章涉及到的成员
// WKS::GCHeap或SVR::GCHeap继承全局命名空间下的GCHeap
class GCHeap : public ::GCHeap
{
#ifdef MULTIPLE_HEAPS
// 服务器GC每个GCHeap实例都会和一个gc_heap实例互相关联
gc_heap* pGenGCHeap;
#else
// 工作站GC下gc_heap所有字段和函数都是静态的, 所以可以用((gc_heap*)nullptr)->xxx来访问
// 严格来说是UB(未定义动作), 但是实际可以工作
#define pGenGCHeap ((gc_heap*)0)
#endif //MULTIPLE_HEAPS
};
全局的GCHeap实例: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gc.h#L105
这里是1.1.0的代码, 1.2.0全局GCHeap会分别保存到gcheaputilities.h(g_pGCHeap)和gc.cpp(g_theGCHeap), 两处地方都指向同一个实例.
// 相当于extern GCHeap* g_pGCHeap;
GPTR_DECL(GCHeap, g_pGCHeap);
gc_heap的源代码摘要:
gc_heap的定义: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcpriv.h#L1079
这个类有300多个成员(从ephemeral_low开始), 这里我只列出这篇文章涉及到的成员
class gc_heap
{
#ifdef MULTIPLE_HEAPS
// 对应的GCHeap实例
PER_HEAP GCHeap* vm_heap;
// 序号
PER_HEAP int heap_number;
// 给分配上下文设置内存范围的次数
PER_HEAP VOLATILE(int) alloc_context_count;
#else //MULTIPLE_HEAPS
// 工作站GC时对应全局的GCHeap实例
#define vm_heap ((GCHeap*) g_pGCHeap)
// 工作站GC时序号为0
#define heap_number (0)
#endif //MULTIPLE_HEAPS
#ifndef MULTIPLE_HEAPS
// 当前使用的短暂的堆段(用于分配新对象的堆段)
SPTR_DECL(heap_segment,ephemeral_heap_segment);
#else
// 同上
PER_HEAP heap_segment* ephemeral_heap_segment;
#endif // !MULTIPLE_HEAPS
// 全局GC线程锁, 静态变量
PER_HEAP_ISOLATED GCSpinLock gc_lock; //lock while doing GC
// 分配上下文用完, 需要为分配上下文指定新的范围时使用的线程锁
PER_HEAP GCSpinLock more_space_lock; //lock while allocating more space
#ifdef MULTIPLE_HEAPS
// 储存各个代的信息
// NUMBERGENERATIONS+1=5, 代分别有0 1 2 3, 最后一个元素不会被使用
// 工作站GC时不会定义, 而是使用全局变量generation_table
PER_HEAP generation generation_table [NUMBERGENERATIONS+1];
#endif
#ifdef MULTIPLE_HEAPS
// 全局gc_heap的数量, 静态变量
// 服务器GC默认是cpu核心数, 工作站GC是0
SVAL_DECL(int, n_heaps);
// 全局gc_heap的数组, 静态变量
SPTR_DECL(PTR_gc_heap, g_heaps);
#endif
};
generation的源代码摘要:
generation的定义: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcpriv.h#L754
这里我只列出这篇文章涉及到的成员
class generation
{
public:
// 默认的分配上下文
alloc_context allocation_context;
// 用于分配的最新的堆段
heap_segment* allocation_segment;
// 开始的堆段
PTR_heap_segment start_segment;
// 用于区分对象在哪个代的指针, 在此之后的对象都属于这个代, 或比这个代更年轻的代
uint8_t* allocation_start;
// 用于储存和分配自由对象(Free Object, 又名Unused Array, 可以理解为碎片空间)的分配器
allocator free_list_allocator;
// 这个代是第几代
int gen_num;
};
heap_segment的源代码摘要:
heap_segment的定义: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcpriv.h#L4166
这里我只列出这篇文章涉及到的成员
class heap_segment
{
public:
// 已实际分配地址 (mem + 已分配大小)
// 更新有可能会延迟
uint8_t* allocated;
// 已提交到物理内存的地址 (this + SEGMENT_INITIAL_COMMIT)
uint8_t* committed;
// 预留到的分配地址 (this + size)
uint8_t* reserved;
// 已使用地址 (mem + 已分配大小 - 对象头大小)
uint8_t* used;
// 初始分配地址 (服务器gc开启时: this + OS_PAGE_SIZE, 否则: this + sizeof(*this) + alignment)
uint8_t* mem;
// 下一个堆段
PTR_heap_segment next;
// 属于的gc_heap实例
gc_heap* heap;
};
alloc_context的源代码摘要:
alloc_context的定义: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gc.h#L162
这里是1.1.0的代码, 1.2.0这些成员移动到了gcinterface.h的gc_alloc_context, 但是成员还是一样的
struct alloc_context
{
// 下一次分配对象的开始地址
uint8_t* alloc_ptr;
// 可以分配到的最终地址
uint8_t* alloc_limit;
// 历史分配的小对象大小合计
int64_t alloc_bytes; //Number of bytes allocated on SOH by this context
// 历史分配的大对象大小合计
int64_t alloc_bytes_loh; //Number of bytes allocated on LOH by this context
#if defined(FEATURE_SVR_GC)
// 空间不够需要获取更多空间时使用的GCHeap
// 分alloc_heap和home_heap的作用是平衡各个heap的使用量,这样并行回收时可以减少处理各个heap的时间差异
SVR::GCHeap* alloc_heap;
// 原来的GCHeap
SVR::GCHeap* home_heap;
#endif // defined(FEATURE_SVR_GC)
// 历史分配对象次数
int alloc_count;
};
堆段的物理结构
为了更好理解下面即将讲解的代码,请先看这两张图片

分配对象内存的代码流程
还记得上篇我提到过的AllocateObject函数吗? 这个函数由JIT_New调用, 负责分配一个普通的对象.
让我们来继续跟踪这个函数的内部吧:
AllocateObject函数的内容: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/gchelpers.cpp#L931
AllocateObject的其他版本同样也会调用AllocAlign8或Alloc函数, 下面就不再贴出其他版本的函数代码了.
OBJECTREF AllocateObject(MethodTable *pMT
#ifdef FEATURE_COMINTEROP
, bool fHandleCom
#endif
)
{
// 省略部分代码......
Object *orObject = NULL;
// 调用gc的帮助函数分配内存,如果需要向8对齐则调用AllocAlign8,否则调用Alloc
if (pMT->RequiresAlign8())
{
// 省略部分代码......
orObject = (Object *) AllocAlign8(baseSize,
pMT->HasFinalizer(),
pMT->ContainsPointers(),
pMT->IsValueType());
}
else
{
orObject = (Object *) Alloc(baseSize,
pMT->HasFinalizer(),
pMT->ContainsPointers());
}
// 省略部分代码......
return UNCHECKED_OBJECTREF_TO_OBJECTREF(oref);
}
Alloc函数的内容: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/gchelpers.cpp#L931
inline Object* Alloc(size_t size, BOOL bFinalize, BOOL bContainsPointers )
{
// 省略部分代码......
// 如果启用分配上下文,则使用当前线程的分配上下文进行分配
// 否则使用代(generation)中默认的分配上下文进行分配
// 按官方的说法绝大部分情况下都会启用分配上下文
// 实测的机器上UseAllocationContexts函数会不经过判断直接返回true
if (GCHeap::UseAllocationContexts())
retVal = GCHeap::GetGCHeap()->Alloc(GetThreadAllocContext(), size, flags);
else
retVal = GCHeap::GetGCHeap()->Alloc(size, flags);
// 省略部分代码......
return retVal;
}
GetGCHeap函数的内容: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gc.h#L377
static GCHeap *GetGCHeap()
{
LIMITED_METHOD_CONTRACT;
// 返回全局的GCHeap实例
// 注意这个实例只作为接口使用,不和具体的gc_heap实例关联
_ASSERTE(g_pGCHeap != NULL);
return g_pGCHeap;
}
GetThreadAllocContext函数的内容: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/gchelpers.cpp#L54
inline alloc_context* GetThreadAllocContext()
{
WRAPPER_NO_CONTRACT;
assert(GCHeap::UseAllocationContexts());
// 获取当前线程并返回m_alloc_context成员的地址
return & GetThread()->m_alloc_context;
}
GCHeap::Alloc函数的内容: https://raw.githubusercontent.com/dotnet/coreclr/release/1.1.0/src/gc/gc.cpp
Object*
GCHeap::Alloc(alloc_context* acontext, size_t size, uint32_t flags REQD_ALIGN_DCL)
{
// 省略部分代码......
Object* newAlloc = NULL;
// 如果分配上下文是第一次使用,使用AssignHeap函数先给它对应一个GCHeap实例
#ifdef MULTIPLE_HEAPS
if (acontext->alloc_heap == 0)
{
AssignHeap (acontext);
assert (acontext->alloc_heap);
}
#endif //MULTIPLE_HEAPS
// 必要时触发GC
#ifndef FEATURE_REDHAWK
GCStress<gc_on_alloc>::MaybeTrigger(acontext);
#endif // FEATURE_REDHAWK
// 服务器GC使用GCHeap对应的gc_heap, 工作站GC使用nullptr
#ifdef MULTIPLE_HEAPS
gc_heap* hp = acontext->alloc_heap->pGenGCHeap;
#else
gc_heap* hp = pGenGCHeap;
// 省略部分代码......
#endif //MULTIPLE_HEAPS
// 分配小对象时使用allocate函数, 分配大对象时使用allocate_large_object函数
if (size < LARGE_OBJECT_SIZE)
{
#ifdef TRACE_GC
AllocSmallCount++;
#endif //TRACE_GC
// 分配小对象内存
newAlloc = (Object*) hp->allocate (size + ComputeMaxStructAlignPad(requiredAlignment), acontext);
#ifdef FEATURE_STRUCTALIGN
// 对齐指针
newAlloc = (Object*) hp->pad_for_alignment ((uint8_t*) newAlloc, requiredAlignment, size, acontext);
#endif // FEATURE_STRUCTALIGN
// ASSERT (newAlloc);
}
else
{
// 分配大对象内存
newAlloc = (Object*) hp->allocate_large_object (size + ComputeMaxStructAlignPadLarge(requiredAlignment), acontext->alloc_bytes_loh);
#ifdef FEATURE_STRUCTALIGN
// 对齐指针
newAlloc = (Object*) hp->pad_for_alignment_large ((uint8_t*) newAlloc, requiredAlignment, size);
#endif // FEATURE_STRUCTALIGN
}
// 省略部分代码......
return newAlloc;
}
分配小对象内存的代码流程
让我们来看一下小对象的内存是如何分配的
allocate函数的内容: https://raw.githubusercontent.com/dotnet/coreclr/release/1.1.0/src/gc/gc.cpp
这个函数尝试从分配上下文分配内存, 失败时调用allocate_more_space为分配上下文指定新的空间
这里的前半部分的处理还有汇编版本, 可以看上一篇分析的JIT_TrialAllocSFastMP_InlineGetThread函数
inline
CObjectHeader* gc_heap::allocate (size_t jsize, alloc_context* acontext)
{
size_t size = Align (jsize);
assert (size >= Align (min_obj_size));
{
retry:
// 尝试把对象分配到alloc_ptr
uint8_t* result = acontext->alloc_ptr;
acontext->alloc_ptr+=size;
// 如果alloc_ptr + 对象大小 > alloc_limit, 则表示这个分配上下文是第一次使用或者剩余空间已经不够用了
if (acontext->alloc_ptr <= acontext->alloc_limit)
{
// 分配成功, 这里返回的地址就是+=size之前的alloc_ptr
CObjectHeader* obj = (CObjectHeader*)result;
assert (obj != 0);
return obj;
}
else
{
// 分配失败, 把size减回去
acontext->alloc_ptr -= size;
#ifdef _MSC_VER
#pragma inline_depth(0)
#endif //_MSC_VER
// 尝试为分配上下文重新指定一块范围
if (! allocate_more_space (acontext, size, 0))
return 0;
#ifdef _MSC_VER
#pragma inline_depth(20)
#endif //_MSC_VER
// 重试
goto retry;
}
}
}
allocate_more_space函数的内容: https://raw.githubusercontent.com/dotnet/coreclr/release/1.1.0/src/gc/gc.cpp
这个函数会在有多个heap时调用balance_heaps平衡各个heap的使用量, 然后再调用try_allocate_more_space函数
BOOL gc_heap::allocate_more_space(alloc_context* acontext, size_t size,
int alloc_generation_number)
{
int status;
do
{
// 如果有多个heap需要先平衡它们的使用量以减少并行回收时的处理时间差
#ifdef MULTIPLE_HEAPS
if (alloc_generation_number == 0)
{
// 平衡各个heap的使用量
balance_heaps (acontext);
// 调用try_allocate_more_space函数
status = acontext->alloc_heap->pGenGCHeap->try_allocate_more_space (acontext, size, alloc_generation_number);
}
else
{
// 平衡各个heap的使用量(大对象)
gc_heap* alloc_heap = balance_heaps_loh (acontext, size);
// 调用try_allocate_more_space函数
status = alloc_heap->try_allocate_more_space (acontext, size, alloc_generation_number);
}
#else
// 只有一个heap时直接调用try_allocate_more_space函数
status = try_allocate_more_space (acontext, size, alloc_generation_number);
#endif //MULTIPLE_HEAPS
}
while (status == -1);
return (status != 0);
}
try_allocate_more_space函数的内容: https://raw.githubusercontent.com/dotnet/coreclr/release/1.1.0/src/gc/gc.cpp
这个函数会获取MSL锁, 检查是否有必要触发GC, 然后根据gen_number参数调用allocate_small或allocate_large函数
int gc_heap::try_allocate_more_space (alloc_context* acontext, size_t size,
int gen_number)
{
// gc已经开始时等待gc完成并重试
// allocate函数会跑到retry再调用这个函数
if (gc_heap::gc_started)
{
wait_for_gc_done();
return -1;
}
// 获取more_space_lock锁
// 并且统计获取锁需要的时间是否多或者少
#ifdef SYNCHRONIZATION_STATS
unsigned int msl_acquire_start = GetCycleCount32();
#endif //SYNCHRONIZATION_STATS
enter_spin_lock (&more_space_lock);
add_saved_spinlock_info (me_acquire, mt_try_alloc);
dprintf (SPINLOCK_LOG, ("[%d]Emsl for alloc", heap_number));
#ifdef SYNCHRONIZATION_STATS
unsigned int msl_acquire = GetCycleCount32() - msl_acquire_start;
total_msl_acquire += msl_acquire;
num_msl_acquired++;
if (msl_acquire > 200)
{
num_high_msl_acquire++;
}
else
{
num_low_msl_acquire++;
}
#endif //SYNCHRONIZATION_STATS
// 这部分的代码被注释了
// 因为获取msl(more space lock)锁已经可以防止问题出现
/*
// We are commenting this out 'cause we don't see the point - we already
// have checked gc_started when we were acquiring the msl - no need to check
// again. This complicates the logic in bgc_suspend_EE 'cause that one would
// need to release msl which causes all sorts of trouble.
if (gc_heap::gc_started)
{
#ifdef SYNCHRONIZATION_STATS
good_suspension++;
#endif //SYNCHRONIZATION_STATS
BOOL fStress = (g_pConfig->GetGCStressLevel() & EEConfig::GCSTRESS_TRANSITION) != 0;
if (!fStress)
{
//Rendez vous early (MP scaling issue)
//dprintf (1, ("[%d]waiting for gc", heap_number));
wait_for_gc_done();
#ifdef MULTIPLE_HEAPS
return -1;
#endif //MULTIPLE_HEAPS
}
}
*/
dprintf (3, ("requested to allocate %d bytes on gen%d", size, gen_number));
// 获取对齐使用的值
// 小对象3(0b11)或者7(0b111), 大对象7(0b111)
int align_const = get_alignment_constant (gen_number != (max_generation+1));
// 必要时触发GC
if (fgn_maxgen_percent)
{
check_for_full_gc (gen_number, size);
}
// 再次检查必要时触发GC
if (!(new_allocation_allowed (gen_number)))
{
if (fgn_maxgen_percent && (gen_number == 0))
{
// We only check gen0 every so often, so take this opportunity to check again.
check_for_full_gc (gen_number, size);
}
// 后台GC运行中并且物理内存占用率在95%以上时等待后台GC完成
#ifdef BACKGROUND_GC
wait_for_bgc_high_memory (awr_gen0_alloc);
#endif //BACKGROUND_GC
#ifdef SYNCHRONIZATION_STATS
bad_suspension++;
#endif //SYNCHRONIZATION_STATS
dprintf (/*100*/ 2, ("running out of budget on gen%d, gc", gen_number));
// 必要时原地触发GC
if (!settings.concurrent || (gen_number == 0))
{
vm_heap->GarbageCollectGeneration (0, ((gen_number == 0) ? reason_alloc_soh : reason_alloc_loh));
#ifdef MULTIPLE_HEAPS
// 触发GC后会释放MSL锁, 需要重新获取
enter_spin_lock (&more_space_lock);
add_saved_spinlock_info (me_acquire, mt_try_budget);
dprintf (SPINLOCK_LOG, ("[%d]Emsl out budget", heap_number));
#endif //MULTIPLE_HEAPS
}
}
// 根据是第几代调用不同的函数, 函数里面会给分配上下文指定新的范围
// 参数gen_number只能是0或者3
BOOL can_allocate = ((gen_number == 0) ?
allocate_small (gen_number, size, acontext, align_const) :
allocate_large (gen_number, size, acontext, align_const));
// 成功时检查是否要触发ETW(Event Tracing for Windows)事件
if (can_allocate)
{
// 记录给了分配上下文多少字节
//ETW trace for allocation tick
size_t alloc_context_bytes = acontext->alloc_limit + Align (min_obj_size, align_const) - acontext->alloc_ptr;
int etw_allocation_index = ((gen_number == 0) ? 0 : 1);
etw_allocation_running_amount[etw_allocation_index] += alloc_context_bytes;
// 超过一定量时触发ETW事件
if (etw_allocation_running_amount[etw_allocation_index] > etw_allocation_tick)
{
#ifdef FEATURE_REDHAWK
FireEtwGCAllocationTick_V1((uint32_t)etw_allocation_running_amount[etw_allocation_index],
((gen_number == 0) ? ETW::GCLog::ETW_GC_INFO::AllocationSmall : ETW::GCLog::ETW_GC_INFO::AllocationLarge),
GetClrInstanceId());
#else
// Unfortunately some of the ETW macros do not check whether the ETW feature is enabled.
// The ones that do are much less efficient.
#if defined(FEATURE_EVENT_TRACE)
if (EventEnabledGCAllocationTick_V2())
{
fire_etw_allocation_event (etw_allocation_running_amount[etw_allocation_index], gen_number, acontext->alloc_ptr);
}
#endif //FEATURE_EVENT_TRACE
#endif //FEATURE_REDHAWK
// 重置量
etw_allocation_running_amount[etw_allocation_index] = 0;
}
}
return (int)can_allocate;
}
allocate_small函数的内容: https://raw.githubusercontent.com/dotnet/coreclr/release/1.1.0/src/gc/gc.cpp
循环尝试进行各种回收内存的处理和调用soh_try_fit函数, soh_try_fit函数分配成功或手段已经用尽时跳出循环
BOOL gc_heap::allocate_small (int gen_number,
size_t size,
alloc_context* acontext,
int align_const)
{
// 工作站GC且后台GC运行时140次(bgc_alloc_spin_count)休眠1次, 休眠时间2ms(bgc_alloc_spin)
#if defined (BACKGROUND_GC) && !defined (MULTIPLE_HEAPS)
if (recursive_gc_sync::background_running_p())
{
background_soh_alloc_count++;
if ((background_soh_alloc_count % bgc_alloc_spin_count) == 0)
{
Thread* current_thread = GetThread();
add_saved_spinlock_info (me_release, mt_alloc_small);
dprintf (SPINLOCK_LOG, ("[%d]spin Lmsl", heap_number));
leave_spin_lock (&more_space_lock);
BOOL cooperative_mode = enable_preemptive (current_thread);
GCToOSInterface::Sleep (bgc_alloc_spin);
disable_preemptive (current_thread, cooperative_mode);
enter_spin_lock (&more_space_lock);
add_saved_spinlock_info (me_acquire, mt_alloc_small);
dprintf (SPINLOCK_LOG, ("[%d]spin Emsl", heap_number));
}
else
{
//GCToOSInterface::YieldThread (0);
}
}
#endif //BACKGROUND_GC && !MULTIPLE_HEAPS
gc_reason gr = reason_oos_soh;
oom_reason oom_r = oom_no_failure;
// No variable values should be "carried over" from one state to the other.
// That's why there are local variable for each state
allocation_state soh_alloc_state = a_state_start;
// 开始循环切换状态, 请关注soh_alloc_state
// If we can get a new seg it means allocation will succeed.
while (1)
{
dprintf (3, ("[h%d]soh state is %s", heap_number, allocation_state_str[soh_alloc_state]));
switch (soh_alloc_state)
{
// 成功或失败时跳出循环
case a_state_can_allocate:
case a_state_cant_allocate:
{
goto exit;
}
// 开始时切换状态到a_state_try_fit
case a_state_start:
{
soh_alloc_state = a_state_try_fit;
break;
}
// 调用soh_try_fit函数
// 成功时切换状态到a_state_can_allocate
// 失败时切换状态到a_state_trigger_full_compact_gc或a_state_trigger_ephemeral_gc
case a_state_try_fit:
{
BOOL commit_failed_p = FALSE;
BOOL can_use_existing_p = FALSE;
can_use_existing_p = soh_try_fit (gen_number, size, acontext,
align_const, &commit_failed_p,
NULL);
soh_alloc_state = (can_use_existing_p ?
a_state_can_allocate :
(commit_failed_p ?
a_state_trigger_full_compact_gc :
a_state_trigger_ephemeral_gc));
break;
}
// 后台GC完成后调用soh_try_fit函数
// 成功时切换状态到a_state_can_allocate
// 失败时切换状态到a_state_trigger_2nd_ephemeral_gc或a_state_trigger_full_compact_gc
case a_state_try_fit_after_bgc:
{
BOOL commit_failed_p = FALSE;
BOOL can_use_existing_p = FALSE;
BOOL short_seg_end_p = FALSE;
can_use_existing_p = soh_try_fit (gen_number, size, acontext,
align_const, &commit_failed_p,
&short_seg_end_p);
soh_alloc_state = (can_use_existing_p ?
a_state_can_allocate :
(short_seg_end_p ?
a_state_trigger_2nd_ephemeral_gc :
a_state_trigger_full_compact_gc));
break;
}
// 压缩GC完成后调用soh_try_fit函数
// 如果压缩后仍分配失败则切换状态到a_state_cant_allocate
// 成功时切换状态到a_state_can_allocate
case a_state_try_fit_after_cg:
{
BOOL commit_failed_p = FALSE;
BOOL can_use_existing_p = FALSE;
BOOL short_seg_end_p = FALSE;
can_use_existing_p = soh_try_fit (gen_number, size, acontext,
align_const, &commit_failed_p,
&short_seg_end_p);
if (short_seg_end_p)
{
soh_alloc_state = a_state_cant_allocate;
oom_r = oom_budget;
}
else
{
if (can_use_existing_p)
{
soh_alloc_state = a_state_can_allocate;
}
else
{
#ifdef MULTIPLE_HEAPS
if (!commit_failed_p)
{
// some other threads already grabbed the more space lock and allocated
// so we should attemp an ephemeral GC again.
assert (heap_segment_allocated (ephemeral_heap_segment) < alloc_allocated);
soh_alloc_state = a_state_trigger_ephemeral_gc;
}
else
#endif //MULTIPLE_HEAPS
{
assert (commit_failed_p);
soh_alloc_state = a_state_cant_allocate;
oom_r = oom_cant_commit;
}
}
}
break;
}
// 等待后台GC完成
// 如果执行了压缩则切换状态到a_state_try_fit_after_cg
// 否则切换状态到a_state_try_fit_after_bgc
case a_state_check_and_wait_for_bgc:
{
BOOL bgc_in_progress_p = FALSE;
BOOL did_full_compacting_gc = FALSE;
bgc_in_progress_p = check_and_wait_for_bgc (awr_gen0_oos_bgc, &did_full_compacting_gc);
soh_alloc_state = (did_full_compacting_gc ?
a_state_try_fit_after_cg :
a_state_try_fit_after_bgc);
break;
}
// 触发第0和1代的GC
// 如果有压缩则切换状态到a_state_try_fit_after_cg
// 否则重试soh_try_fit, 成功时切换状态到a_state_can_allocate, 失败时切换状态到等待后台GC或触发其他GC
case a_state_trigger_ephemeral_gc:
{
BOOL commit_failed_p = FALSE;
BOOL can_use_existing_p = FALSE;
BOOL short_seg_end_p = FALSE;
BOOL bgc_in_progress_p = FALSE;
BOOL did_full_compacting_gc = FALSE;
did_full_compacting_gc = trigger_ephemeral_gc (gr);
if (did_full_compacting_gc)
{
soh_alloc_state = a_state_try_fit_after_cg;
}
else
{
can_use_existing_p = soh_try_fit (gen_number, size, acontext,
align_const, &commit_failed_p,
&short_seg_end_p);
#ifdef BACKGROUND_GC
bgc_in_progress_p = recursive_gc_sync::background_running_p();
#endif //BACKGROUND_GC
if (short_seg_end_p)
{
soh_alloc_state = (bgc_in_progress_p ?
a_state_check_and_wait_for_bgc :
a_state_trigger_full_compact_gc);
if (fgn_maxgen_percent)
{
dprintf (2, ("FGN: doing last GC before we throw OOM"));
send_full_gc_notification (max_generation, FALSE);
}
}
else
{
if (can_use_existing_p)
{
soh_alloc_state = a_state_can_allocate;
}
else
{
#ifdef MULTIPLE_HEAPS
if (!commit_failed_p)
{
// some other threads already grabbed the more space lock and allocated
// so we should attemp an ephemeral GC again.
assert (heap_segment_allocated (ephemeral_heap_segment) < alloc_allocated);
soh_alloc_state = a_state_trigger_ephemeral_gc;
}
else
#endif //MULTIPLE_HEAPS
{
soh_alloc_state = a_state_trigger_full_compact_gc;
if (fgn_maxgen_percent)
{
dprintf (2, ("FGN: failed to commit, doing full compacting GC"));
send_full_gc_notification (max_generation, FALSE);
}
}
}
}
}
break;
}
// 第二次触发第0和1代的GC
// 如果有压缩则切换状态到a_state_try_fit_after_cg
// 否则重试soh_try_fit, 成功时切换状态到a_state_can_allocate, 失败时切换状态到a_state_trigger_full_compact_gc
case a_state_trigger_2nd_ephemeral_gc:
{
BOOL commit_failed_p = FALSE;
BOOL can_use_existing_p = FALSE;
BOOL short_seg_end_p = FALSE;
BOOL did_full_compacting_gc = FALSE;
did_full_compacting_gc = trigger_ephemeral_gc (gr);
if (did_full_compacting_gc)
{
soh_alloc_state = a_state_try_fit_after_cg;
}
else
{
can_use_existing_p = soh_try_fit (gen_number, size, acontext,
align_const, &commit_failed_p,
&short_seg_end_p);
if (short_seg_end_p || commit_failed_p)
{
soh_alloc_state = a_state_trigger_full_compact_gc;
}
else
{
assert (can_use_existing_p);
soh_alloc_state = a_state_can_allocate;
}
}
break;
}
// 触发第0和1和2代的压缩GC
// 成功时切换状态到a_state_try_fit_after_cg, 失败时切换状态到a_state_cant_allocate
case a_state_trigger_full_compact_gc:
{
BOOL got_full_compacting_gc = FALSE;
got_full_compacting_gc = trigger_full_compact_gc (gr, &oom_r);
soh_alloc_state = (got_full_compacting_gc ? a_state_try_fit_after_cg : a_state_cant_allocate);
break;
}
default:
{
assert (!"Invalid state!");
break;
}
}
}
exit:
// 分配失败时处理OOM(Out Of Memory)
if (soh_alloc_state == a_state_cant_allocate)
{
assert (oom_r != oom_no_failure);
handle_oom (heap_number,
oom_r,
size,
heap_segment_allocated (ephemeral_heap_segment),
heap_segment_reserved (ephemeral_heap_segment));
dprintf (SPINLOCK_LOG, ("[%d]Lmsl for oom", heap_number));
add_saved_spinlock_info (me_release, mt_alloc_small_cant);
leave_spin_lock (&more_space_lock);
}
return (soh_alloc_state == a_state_can_allocate);
}
soh_try_fit函数的内容: https://raw.githubusercontent.com/dotnet/coreclr/release/1.1.0/src/gc/gc.cpp
这个函数会先尝试调用a_fit_free_list_p从自由对象列表中分配, 然后尝试调用a_fit_segment_end_p从堆段结尾分配
BOOL gc_heap::soh_try_fit (int gen_number,
size_t size,
alloc_context* acontext,
int align_const,
BOOL* commit_failed_p, // 返回参数, 把虚拟内存提交到物理内存是否失败(物理内存不足)
BOOL* short_seg_end_p) // 返回参数, 堆段的结尾是否不够用
{
BOOL can_allocate = TRUE;
// 有传入short_seg_end_p时先设置它的值为false
if (short_seg_end_p)
{
*short_seg_end_p = FALSE;
}
// 先尝试从自由对象列表中分配
can_allocate = a_fit_free_list_p (gen_number, size, acontext, align_const);
if (!can_allocate)
{
// 不能从自由对象列表中分配, 尝试从堆段的结尾分配
// 检查ephemeral_heap_segment的结尾空间是否足够
if (short_seg_end_p)
{
*short_seg_end_p = short_on_end_of_seg (gen_number, ephemeral_heap_segment, align_const);
}
// 如果空间足够, 或者调用时不传入short_seg_end_p参数(传入nullptr), 则调用a_fit_segment_end_p函数
// If the caller doesn't care, we always try to fit at the end of seg;
// otherwise we would only try if we are actually not short at end of seg.
if (!short_seg_end_p || !(*short_seg_end_p))
{
can_allocate = a_fit_segment_end_p (gen_number, ephemeral_heap_segment, size,
acontext, align_const, commit_failed_p);
}
}
return can_allocate;
}
a_fit_free_list_p函数的内容: https://raw.githubusercontent.com/dotnet/coreclr/release/1.1.0/src/gc/gc.cpp
这个函数会尝试从自由对象列表中找到足够大小的空间, 如果找到则把分配上下文指向这个空间
inline
BOOL gc_heap::a_fit_free_list_p (int gen_number,
size_t size,
alloc_context* acontext,
int align_const)
{
BOOL can_fit = FALSE;
// 获取指定的代中的自由对象列表
generation* gen = generation_of (gen_number);
allocator* gen_allocator = generation_allocator (gen);
// 列表会按大小分为多个bucket(用链表形式链接)
// 大小会*2递增, 例如first_bucket的大小是256那第二个bucket的大小则为512
size_t sz_list = gen_allocator->first_bucket_size();
for (unsigned int a_l_idx = 0; a_l_idx < gen_allocator->number_of_buckets(); a_l_idx++)
{
if ((size < sz_list) || (a_l_idx == (gen_allocator->number_of_buckets()-1)))
{
uint8_t* free_list = gen_allocator->alloc_list_head_of (a_l_idx);
uint8_t* prev_free_item = 0;
while (free_list != 0)
{
dprintf (3, ("considering free list %Ix", (size_t)free_list));
size_t free_list_size = unused_array_size (free_list);
if ((size + Align (min_obj_size, align_const)) <= free_list_size)
{
dprintf (3, ("Found adequate unused area: [%Ix, size: %Id",
(size_t)free_list, free_list_size));
// 大小足够时从该bucket的链表中pop出来
gen_allocator->unlink_item (a_l_idx, free_list, prev_free_item, FALSE);
// We ask for more Align (min_obj_size)
// to make sure that we can insert a free object
// in adjust_limit will set the limit lower
size_t limit = limit_from_size (size, free_list_size, gen_number, align_const);
uint8_t* remain = (free_list + limit);
size_t remain_size = (free_list_size - limit);
// 如果分配完还有剩余空间, 在剩余空间生成一个自由对象并塞回自由对象列表
if (remain_size >= Align(min_free_list, align_const))
{
make_unused_array (remain, remain_size);
gen_allocator->thread_item_front (remain, remain_size);
assert (remain_size >= Align (min_obj_size, align_const));
}
else
{
//absorb the entire free list
limit += remain_size;
}
generation_free_list_space (gen) -= limit;
// 给分配上下文设置新的范围
adjust_limit_clr (free_list, limit, acontext, 0, align_const, gen_number);
// 分配成功跳出循环
can_fit = TRUE;
goto end;
}
else if (gen_allocator->discard_if_no_fit_p())
{
assert (prev_free_item == 0);
dprintf (3, ("couldn't use this free area, discarding"));
generation_free_obj_space (gen) += free_list_size;
gen_allocator->unlink_item (a_l_idx, free_list, prev_free_item, FALSE);
generation_free_list_space (gen) -= free_list_size;
}
else
{
prev_free_item = free_list;
}
// 同一bucket的下一个自由对象
free_list = free_list_slot (free_list);
}
}
// 当前bucket的大小不够, 下一个bucket的大小会是当前bucket的两倍
sz_list = sz_list * 2;
}
end:
return can_fit;
}如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 125
- 统信桌面专业版【全盘安装UOS系统】介绍 119
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 111
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
