CoreCLR源码探索(四) GC内存收集器的内部实现 分析篇(一)
需要的预备知识
- 对c中的指针有一定了解
- 对常用数据结构有一定了解, 例如链表
- 对基础c++语法有一定了解, 高级语法和STL不需要因为微软只用了低级语法
GC的触发
GC一般在已预留的内存不够用或者已经分配量超过阈值时触发,场景包括:
不能给分配上下文指定新的空间时
当调用try_allocate_more_space不能从segment结尾或自由对象列表获取新的空间时会触发GC, 详细可以看我上一篇中分析的代码。
分配的数据量达到一定阈值时
阈值储存在各个heap的dd_min_gc_size(初始值), dd_desired_allocation(动态调整值), dd_new_allocation(消耗值)中,每次给分配上下文指定空间时会减少dd_new_allocation。
如果dd_new_allocation变为负数或者与dd_desired_allocation的比例小于一定值则触发GC,
触发完GC以后会重新调整dd_new_allocation到dd_desired_allocation。
参考new_allocation_limit, new_allocation_allowed和check_for_full_gc函数。
值得一提的是可以在.Net程序中使用GC.RegisterForFullGCNotification可以设置触发GC需要的dd_new_allocation / dd_desired_allocation的比例(会储存在fgn_maxgen_percent和fgn_loh_percent中), 设置一个大于0的比例可以让GC触发的更加频繁。
StressGC
允许手动设置特殊的GC触发策略, 参考这个文档
作为例子,你可以试着在运行程序前运行export COMPlus_GCStress=1
GCStrees会通过调用GCStress<gc_on_alloc>::MaybeTrigger(acontext)触发,
如果你设置了COMPlus_GCStressStart环境变量,在调用MaybeTrigger一定次数后会强制触发GC,另外还有COMPlus_GCStressStartAtJit等参数,请参考上面的文档。
默认StressGC不会启用。
手动触发GC
在.Net程序中使用GC.Collect可以触发手动触发GC,我相信你们都知道。
调用.Net中的GC.Collect会调用CoreCLR中的GCHeap::GarbageCollect => GarbageCollectTry => GarbageCollectGeneration。
GC的处理
以下函数大部分都在gc.cpp里,在这个文件里的函数我就不一一标出文件了。
GC的入口点
GC的入口点是GCHeap::GarbageCollectGeneration函数,这个函数的主要作用是停止运行引擎和调用各个gc_heap的gc_heap::garbage_collect函数
因为这一篇重点在于GC做出的处理,我将不对如何停止运行引擎和后台GC做出详细的解释,希望以后可以再写一篇文章讲述
// 第一个参数是回收垃圾的代, 例如等于1时会回收gen 0和gen 1的垃圾
// 第二个参数是触发GC的原因
size_t
GCHeap::GarbageCollectGeneration (unsigned int gen, gc_reason reason)
{
dprintf (2, ("triggered a GC!"));
// 获取gc_heap实例,意义不大
#ifdef MULTIPLE_HEAPS
gc_heap* hpt = gc_heap::g_heaps[0];
#else
gc_heap* hpt = 0;
#endif //MULTIPLE_HEAPS
// 获取当前线程和dd数据
Thread* current_thread = GetThread();
BOOL cooperative_mode = TRUE;
dynamic_data* dd = hpt->dynamic_data_of (gen);
size_t localCount = dd_collection_count (dd);
// 获取GC锁, 防止重复触发GC
enter_spin_lock (&gc_heap::gc_lock);
dprintf (SPINLOCK_LOG, ("GC Egc"));
ASSERT_HOLDING_SPIN_LOCK(&gc_heap::gc_lock);
//don't trigger another GC if one was already in progress
//while waiting for the lock
{
size_t col_count = dd_collection_count (dd);
if (localCount != col_count)
{
#ifdef SYNCHRONIZATION_STATS
gc_lock_contended++;
#endif //SYNCHRONIZATION_STATS
dprintf (SPINLOCK_LOG, ("no need GC Lgc"));
leave_spin_lock (&gc_heap::gc_lock);
// We don't need to release msl here 'cause this means a GC
// has happened and would have release all msl's.
return col_count;
}
}
// 统计GC的开始时间(包括停止运行引擎使用的时间)
#ifdef COUNT_CYCLES
int gc_start = GetCycleCount32();
#endif //COUNT_CYCLES
#ifdef TRACE_GC
#ifdef COUNT_CYCLES
AllocDuration += GetCycleCount32() - AllocStart;
#else
AllocDuration += clock() - AllocStart;
#endif //COUNT_CYCLES
#endif //TRACE_GC
// 设置触发GC的原因
gc_heap::g_low_memory_status = (reason == reason_lowmemory) ||
(reason == reason_lowmemory_blocking) ||
g_bLowMemoryFromHost;
if (g_bLowMemoryFromHost)
reason = reason_lowmemory_host;
gc_trigger_reason = reason;
// 重设GC结束的事件
// 以下说的"事件"的作用和"信号量", .Net中的"Monitor"一样
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < gc_heap::n_heaps; i++)
{
gc_heap::g_heaps[i]->reset_gc_done();
}
#else
gc_heap::reset_gc_done();
#endif //MULTIPLE_HEAPS
// 标记gc已开始, 全局静态变量
gc_heap::gc_started = TRUE;
// 停止运行引擎
{
init_sync_log_stats();
#ifndef MULTIPLE_HEAPS
// 让当前线程进入preemptive模式
// 最终会调用Thread::EnablePreemptiveGC
// 设置线程的m_fPreemptiveGCDisabled等于0
cooperative_mode = gc_heap::enable_preemptive (current_thread);
dprintf (2, ("Suspending EE"));
BEGIN_TIMING(suspend_ee_during_log);
// 停止运行引擎,这里我只做简单解释
// - 调用ThreadSuspend::SuspendEE
// - 调用LockThreadStore锁住线程集合直到RestartEE
// - 设置GCHeap中全局事件WaitForGCEvent
// - 调用ThreadStore::TrapReturingThreads
// - 设置全局变量g_TrapReturningThreads,jit会生成检查这个全局变量的代码
// - 调用SuspendRuntime, 停止除了当前线程以外的线程,如果线程在cooperative模式则劫持并停止,如果线程在preemptive模式则阻止进入cooperative模式
GCToEEInterface::SuspendEE(GCToEEInterface::SUSPEND_FOR_GC);
END_TIMING(suspend_ee_during_log);
// 再次判断是否应该执行gc
// 目前如果设置了NoGCRegion(gc_heap::settings.pause_mode == pause_no_gc)则会进一步检查
// https://msdn.microsoft.com/en-us/library/system.runtime.gclatencymode(v=vs.110).aspx
gc_heap::proceed_with_gc_p = gc_heap::should_proceed_with_gc();
// 设置当前线程离开preemptive模式
gc_heap::disable_preemptive (current_thread, cooperative_mode);
if (gc_heap::proceed_with_gc_p)
pGenGCHeap->settings.init_mechanisms();
else
gc_heap::update_collection_counts_for_no_gc();
#endif //!MULTIPLE_HEAPS
}
// MAP_EVENT_MONITORS(EE_MONITOR_GARBAGE_COLLECTIONS, NotifyEvent(EE_EVENT_TYPE_GC_STARTED, 0));
// 统计GC的开始时间
#ifdef TRACE_GC
#ifdef COUNT_CYCLES
unsigned start;
unsigned finish;
start = GetCycleCount32();
#else
clock_t start;
clock_t finish;
start = clock();
#endif //COUNT_CYCLES
PromotedObjectCount = 0;
#endif //TRACE_GC
// 当前收集代的序号
// 后面看到condemned generation时都表示"当前收集代"
unsigned int condemned_generation_number = gen;
// We want to get a stack from the user thread that triggered the GC
// instead of on the GC thread which is the case for Server GC.
// But we are doing it for Workstation GC as well to be uniform.
FireEtwGCTriggered((int) reason, GetClrInstanceId());
// 进入GC处理
// 如果有多个heap(服务器GC),可以使用各个heap的线程并行处理
// 如果只有一个heap(工作站GC),直接在当前线程处理
#ifdef MULTIPLE_HEAPS
GcCondemnedGeneration = condemned_generation_number;
// 当前线程进入preemptive模式
cooperative_mode = gc_heap::enable_preemptive (current_thread);
BEGIN_TIMING(gc_during_log);
// gc_heap::gc_thread_function在收到这个信号以后会进入GC处理
// 在里面也会判断proceed_with_gc_p
gc_heap::ee_suspend_event.Set();
// 等待所有线程处理完毕
gc_heap::wait_for_gc_done();
END_TIMING(gc_during_log);
// 当前线程离开preemptive模式
gc_heap::disable_preemptive (current_thread, cooperative_mode);
condemned_generation_number = GcCondemnedGeneration;
#else
// 在当前线程中进入GC处理
if (gc_heap::proceed_with_gc_p)
{
BEGIN_TIMING(gc_during_log);
pGenGCHeap->garbage_collect (condemned_generation_number);
END_TIMING(gc_during_log);
}
#endif //MULTIPLE_HEAPS
// 统计GC的结束时间
#ifdef TRACE_GC
#ifdef COUNT_CYCLES
finish = GetCycleCount32();
#else
finish = clock();
#endif //COUNT_CYCLES
GcDuration += finish - start;
dprintf (3,
("<GC# %d> Condemned: %d, Duration: %d, total: %d Alloc Avg: %d, Small Objects:%d Large Objects:%d",
VolatileLoad(&pGenGCHeap->settings.gc_index), condemned_generation_number,
finish - start, GcDuration,
AllocCount ? (AllocDuration / AllocCount) : 0,
AllocSmallCount, AllocBigCount));
AllocCount = 0;
AllocDuration = 0;
#endif // TRACE_GC
#ifdef BACKGROUND_GC
// We are deciding whether we should fire the alloc wait end event here
// because in begin_foreground we could be calling end_foreground
// if we need to retry.
if (gc_heap::alloc_wait_event_p)
{
hpt->fire_alloc_wait_event_end (awr_fgc_wait_for_bgc);
gc_heap::alloc_wait_event_p = FALSE;
}
#endif //BACKGROUND_GC
// 重启运行引擎
#ifndef MULTIPLE_HEAPS
#ifdef BACKGROUND_GC
if (!gc_heap::dont_restart_ee_p)
{
#endif //BACKGROUND_GC
BEGIN_TIMING(restart_ee_during_log);
// 重启运行引擎,这里我只做简单解释
// - 调用SetGCDone
// - 调用ResumeRuntime
// - 调用UnlockThreadStore
GCToEEInterface::RestartEE(TRUE);
END_TIMING(restart_ee_during_log);
#ifdef BACKGROUND_GC
}
#endif //BACKGROUND_GC
#endif //!MULTIPLE_HEAPS
#ifdef COUNT_CYCLES
printf ("GC: %d Time: %d\n", GcCondemnedGeneration,
GetCycleCount32() - gc_start);
#endif //COUNT_CYCLES
// 设置gc_done_event事件和释放gc锁
// 如果有多个heap, 这里的处理会在gc_thread_function中完成
#ifndef MULTIPLE_HEAPS
process_sync_log_stats();
gc_heap::gc_started = FALSE;
gc_heap::set_gc_done();
dprintf (SPINLOCK_LOG, ("GC Lgc"));
leave_spin_lock (&gc_heap::gc_lock);
#endif //!MULTIPLE_HEAPS
#ifdef FEATURE_PREMORTEM_FINALIZATION
if ((!pGenGCHeap->settings.concurrent && pGenGCHeap->settings.found_finalizers) ||
FinalizerThread::HaveExtraWorkForFinalizer())
{
FinalizerThread::EnableFinalization();
}
#endif // FEATURE_PREMORTEM_FINALIZATION
return dd_collection_count (dd);
}
以下是gc_heap::garbage_collect函数,这个函数也是GC的入口点函数,
主要作用是针对gc_heap做gc开始前和结束后的清理工作,例如重设各个线程的分配上下文和修改gc参数
// 第一个参数是回收垃圾的代
int gc_heap::garbage_collect (int n)
{
// 枚举线程
// - 统计目前用的分配上下文数量
// - 在分配上下文的alloc_ptr和limit之间创建free object
// - 设置所有分配上下文的alloc_ptr和limit到0
//reset the number of alloc contexts
alloc_contexts_used = 0;
fix_allocation_contexts (TRUE);
// 清理在gen 0范围的brick table
// brick table将在下面解释
#ifdef MULTIPLE_HEAPS
clear_gen0_bricks();
#endif //MULTIPLE_HEAPS
// 如果开始了NoGCRegion,并且disallowFullBlockingGC等于true,则跳过这次GC
// https://msdn.microsoft.com/en-us/library/dn906204(v=vs.110).aspx
if ((settings.pause_mode == pause_no_gc) && current_no_gc_region_info.minimal_gc_p)
{
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_minimal_gc);
if (gc_t_join.joined())
{
#endif //MULTIPLE_HEAPS
#ifdef MULTIPLE_HEAPS
// this is serialized because we need to get a segment
for (int i = 0; i < n_heaps; i++)
{
if (!(g_heaps[i]->expand_soh_with_minimal_gc()))
current_no_gc_region_info.start_status = start_no_gc_no_memory;
}
#else
if (!expand_soh_with_minimal_gc())
current_no_gc_region_info.start_status = start_no_gc_no_memory;
#endif //MULTIPLE_HEAPS
update_collection_counts_for_no_gc();
#ifdef MULTIPLE_HEAPS
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
goto done;
}
// 清空gc_data_per_heap和fgm_result
init_records();
memset (&fgm_result, 0, sizeof (fgm_result));
// 设置收集理由到settings成员中
// settings成员的类型是gc_mechanisms, 里面的值已在前面初始化过,将会贯穿整个gc过程使用
settings.reason = gc_trigger_reason;
verify_pinned_queue_p = FALSE;
#if defined(ENABLE_PERF_COUNTERS) || defined(FEATURE_EVENT_TRACE)
num_pinned_objects = 0;
#endif //ENABLE_PERF_COUNTERS || FEATURE_EVENT_TRACE
#ifdef STRESS_HEAP
if (settings.reason == reason_gcstress)
{
settings.reason = reason_induced;
settings.stress_induced = TRUE;
}
#endif // STRESS_HEAP
#ifdef MULTIPLE_HEAPS
// 根据环境重新决定应该收集的代
// 这里的处理比较杂,大概包括了以下的处理
// - 备份dd_new_allocation到dd_gc_new_allocation
// - 必要时修改收集的代, 例如最大代的阈值用完或者需要低延迟的时候
// - 必要时设置settings.promotion = true (启用对象升代, 例如代0对象gc后变代1)
// - 算法是 通过卡片标记的对象 / 通过卡片扫描的对象 < 30% 则启用对象升代(dt_low_card_table_efficiency_p)
// - 这个比例储存在`generation_skip_ratio`中
// - Card Table将在下面解释,意义是如果前一代的对象不够多则需要把后一代的对象升代
//align all heaps on the max generation to condemn
dprintf (3, ("Joining for max generation to condemn"));
condemned_generation_num = generation_to_condemn (n,
&blocking_collection,
&elevation_requested,
FALSE);
gc_t_join.join(this, gc_join_generation_determined);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
// 判断是否要打印更多的除错信息,除错用
#ifdef TRACE_GC
int gc_count = (int)dd_collection_count (dynamic_data_of (0));
if (gc_count >= g_pConfig->GetGCtraceStart())
trace_gc = 1;
if (gc_count >= g_pConfig->GetGCtraceEnd())
trace_gc = 0;
#endif //TRACE_GC
// 复制(合并)各个heap的card table和brick table到全局
#ifdef MULTIPLE_HEAPS
#if !defined(SEG_MAPPING_TABLE) && !defined(FEATURE_BASICFREEZE)
// 释放已删除的segment索引的节点
//delete old slots from the segment table
seg_table->delete_old_slots();
#endif //!SEG_MAPPING_TABLE && !FEATURE_BASICFREEZE
for (int i = 0; i < n_heaps; i++)
{
//copy the card and brick tables
if (g_card_table != g_heaps[i]->card_table)
{
g_heaps[i]->copy_brick_card_table();
}
g_heaps[i]->rearrange_large_heap_segments();
if (!recursive_gc_sync::background_running_p())
{
g_heaps[i]->rearrange_small_heap_segments();
}
}
#else //MULTIPLE_HEAPS
#ifdef BACKGROUND_GC
//delete old slots from the segment table
#if !defined(SEG_MAPPING_TABLE) && !defined(FEATURE_BASICFREEZE)
// 释放已删除的segment索引的节点
seg_table->delete_old_slots();
#endif //!SEG_MAPPING_TABLE && !FEATURE_BASICFREEZE
// 删除空segment
rearrange_large_heap_segments();
if (!recursive_gc_sync::background_running_p())
{
rearrange_small_heap_segments();
}
#endif //BACKGROUND_GC
// check for card table growth
if (g_card_table != card_table)
copy_brick_card_table();
#endif //MULTIPLE_HEAPS
// 合并各个heap的elevation_requested和blocking_collection选项
BOOL should_evaluate_elevation = FALSE;
BOOL should_do_blocking_collection = FALSE;
#ifdef MULTIPLE_HEAPS
int gen_max = condemned_generation_num;
for (int i = 0; i < n_heaps; i++)
{
if (gen_max < g_heaps[i]->condemned_generation_num)
gen_max = g_heaps[i]->condemned_generation_num;
if ((!should_evaluate_elevation) && (g_heaps[i]->elevation_requested))
should_evaluate_elevation = TRUE;
if ((!should_do_blocking_collection) && (g_heaps[i]->blocking_collection))
should_do_blocking_collection = TRUE;
}
settings.condemned_generation = gen_max;
//logically continues after GC_PROFILING.
#else //MULTIPLE_HEAPS
// 单gc_heap(工作站GC)时的处理
// 根据环境重新决定应该收集的代,解释看上面
settings.condemned_generation = generation_to_condemn (n,
&blocking_collection,
&elevation_requested,
FALSE);
should_evaluate_elevation = elevation_requested;
should_do_blocking_collection = blocking_collection;
#endif //MULTIPLE_HEAPS
settings.condemned_generation = joined_generation_to_condemn (
should_evaluate_elevation,
settings.condemned_generation,
&should_do_blocking_collection
STRESS_HEAP_ARG(n)
);
STRESS_LOG1(LF_GCROOTS|LF_GC|LF_GCALLOC, LL_INFO10,
"condemned generation num: %d\n", settings.condemned_generation);
record_gcs_during_no_gc();
// 如果收集代大于1(目前只有2,也就是full gc)则启用对象升代
if (settings.condemned_generation > 1)
settings.promotion = TRUE;
#ifdef HEAP_ANALYZE
// At this point we've decided what generation is condemned
// See if we've been requested to analyze survivors after the mark phase
if (AnalyzeSurvivorsRequested(settings.condemned_generation))
{
heap_analyze_enabled = TRUE;
}
#endif // HEAP_ANALYZE
// 统计GC性能的处理,这里不分析
#ifdef GC_PROFILING
// If we're tracking GCs, then we need to walk the first generation
// before collection to track how many items of each class has been
// allocated.
UpdateGenerationBounds();
GarbageCollectionStartedCallback(settings.condemned_generation, settings.reason == reason_induced);
{
BEGIN_PIN_PROFILER(CORProfilerTrackGC());
size_t profiling_context = 0;
#ifdef MULTIPLE_HEAPS
int hn = 0;
for (hn = 0; hn < gc_heap::n_heaps; hn++)
{
gc_heap* hp = gc_heap::g_heaps [hn];
// When we're walking objects allocated by class, then we don't want to walk the large
// object heap because then it would count things that may have been around for a while.
hp->walk_heap (&AllocByClassHelper, (void *)&profiling_context, 0, FALSE);
}
#else
// When we're walking objects allocated by class, then we don't want to walk the large
// object heap because then it would count things that may have been around for a while.
gc_heap::walk_heap (&AllocByClassHelper, (void *)&profiling_context, 0, FALSE);
#endif //MULTIPLE_HEAPS
// Notify that we've reached the end of the Gen 0 scan
g_profControlBlock.pProfInterface->EndAllocByClass(&profiling_context);
END_PIN_PROFILER();
}
#endif // GC_PROFILING
// 后台GC的处理,这里不分析
#ifdef BACKGROUND_GC
if ((settings.condemned_generation == max_generation) &&
(recursive_gc_sync::background_running_p()))
{
//TODO BACKGROUND_GC If we just wait for the end of gc, it won't woork
// because we have to collect 0 and 1 properly
// in particular, the allocation contexts are gone.
// For now, it is simpler to collect max_generation-1
settings.condemned_generation = max_generation - 1;
dprintf (GTC_LOG, ("bgc - 1 instead of 2"));
}
if ((settings.condemned_generation == max_generation) &&
(should_do_blocking_collection == FALSE) &&
gc_can_use_concurrent &&
!temp_disable_concurrent_p &&
((settings.pause_mode == pause_interactive) || (settings.pause_mode == pause_sustained_low_latency)))
{
keep_bgc_threads_p = TRUE;
c_write (settings.concurrent, TRUE);
}
#endif //BACKGROUND_GC
// 当前gc的标识序号(会在gc1 => update_collection_counts函数里面更新)
settings.gc_index = (uint32_t)dd_collection_count (dynamic_data_of (0)) + 1;
// 通知运行引擎GC开始工作
// 这里会做出一些处理例如释放JIT中已删除的HostCodeHeap的内存
// Call the EE for start of GC work
// just one thread for MP GC
GCToEEInterface::GcStartWork (settings.condemned_generation,
max_generation);
// TODO: we could fire an ETW event to say this GC as a concurrent GC but later on due to not being able to
// create threads or whatever, this could be a non concurrent GC. Maybe for concurrent GC we should fire
// it in do_background_gc and if it failed to be a CGC we fire it in gc1... in other words, this should be
// fired in gc1.
// 更新一些统计用计数器和数据
do_pre_gc();
// 继续(唤醒)后台GC线程
#ifdef MULTIPLE_HEAPS
gc_start_event.Reset();
//start all threads on the roots.
dprintf(3, ("Starting all gc threads for gc"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
// 更新统计数据
{
int gen_num_for_data = max_generation + 1;
for (int i = 0; i <= gen_num_for_data; i++)
{
gc_data_per_heap.gen_data[i].size_before = generation_size (i);
generation* gen = generation_of (i);
gc_data_per_heap.gen_data[i].free_list_space_before = generation_free_list_space (gen);
gc_data_per_heap.gen_data[i].free_obj_space_before = generation_free_obj_space (gen);
}
}
// 打印出错信息
descr_generations (TRUE);
// descr_card_table();
// 如果不使用Write Barrier而是Write Watch时则需要更新Card Table
// 默认windows和linux编译的CoreCLR都会使用Write Barrier
// Write Barrier和Card Table将在下面解释
#ifdef NO_WRITE_BARRIER
fix_card_table();
#endif //NO_WRITE_BARRIER
// 检查gc_heap的状态,除错用
#ifdef VERIFY_HEAP
if ((g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_GC) &&
!(g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_POST_GC_ONLY))
{
verify_heap (TRUE);
}
if (g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_BARRIERCHECK)
checkGCWriteBarrier();
#endif // VERIFY_HEAP
// 调用GC的主函数`gc1`
// 后台GC的处理我在这一篇中将不会解释,希望以后可以专门写一篇解释后台GC
#ifdef BACKGROUND_GC
if (settings.concurrent)
{
// We need to save the settings because we'll need to restore it after each FGC.
assert (settings.condemned_generation == max_generation);
settings.compaction = FALSE;
saved_bgc_settings = settings;
#ifdef MULTIPLE_HEAPS
if (heap_number == 0)
{
for (int i = 0; i < n_heaps; i++)
{
prepare_bgc_thread (g_heaps[i]);
}
dprintf (2, ("setting bgc_threads_sync_event"));
bgc_threads_sync_event.Set();
}
else
{
bgc_threads_sync_event.Wait(INFINITE, FALSE);
dprintf (2, ("bgc_threads_sync_event is signalled"));
}
#else
prepare_bgc_thread(0);
#endif //MULTIPLE_HEAPS
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_start_bgc);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
do_concurrent_p = TRUE;
do_ephemeral_gc_p = FALSE;
#ifdef MULTIPLE_HEAPS
dprintf(2, ("Joined to perform a background GC"));
for (int i = 0; i < n_heaps; i++)
{
gc_heap* hp = g_heaps[i];
if (!(hp->bgc_thread) || !hp->commit_mark_array_bgc_init (hp->mark_array))
{
do_concurrent_p = FALSE;
break;
}
else
{
hp->background_saved_lowest_address = hp->lowest_address;
hp->background_saved_highest_address = hp->highest_address;
}
}
#else
do_concurrent_p = (!!bgc_thread && commit_mark_array_bgc_init (mark_array));
if (do_concurrent_p)
{
background_saved_lowest_address = lowest_address;
background_saved_highest_address = highest_address;
}
#endif //MULTIPLE_HEAPS
if (do_concurrent_p)
{
#ifdef FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
SoftwareWriteWatch::EnableForGCHeap();
#endif //FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < n_heaps; i++)
g_heaps[i]->current_bgc_state = bgc_initialized;
#else
current_bgc_state = bgc_initialized;
#endif //MULTIPLE_HEAPS
int gen = check_for_ephemeral_alloc();
// always do a gen1 GC before we start BGC.
// This is temporary for testing purpose.
//int gen = max_generation - 1;
dont_restart_ee_p = TRUE;
if (gen == -1)
{
// If we decide to not do a GC before the BGC we need to
// restore the gen0 alloc context.
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < n_heaps; i++)
{
generation_allocation_pointer (g_heaps[i]->generation_of (0)) = 0;
generation_allocation_limit (g_heaps[i]->generation_of (0)) = 0;
}
#else
generation_allocation_pointer (youngest_generation) = 0;
generation_allocation_limit (youngest_generation) = 0;
#endif //MULTIPLE_HEAPS
}
else
{
do_ephemeral_gc_p = TRUE;
settings.init_mechanisms();
settings.condemned_generation = gen;
settings.gc_index = (size_t)dd_collection_count (dynamic_data_of (0)) + 2;
do_pre_gc();
// TODO BACKGROUND_GC need to add the profiling stuff here.
dprintf (GTC_LOG, ("doing gen%d before doing a bgc", gen));
}
//clear the cards so they don't bleed in gen 1 during collection
// shouldn't this always be done at the beginning of any GC?
//clear_card_for_addresses (
// generation_allocation_start (generation_of (0)),
// heap_segment_allocated (ephemeral_heap_segment));
if (!do_ephemeral_gc_p)
{
do_background_gc();
}
}
else
{
settings.compaction = TRUE;
c_write (settings.concurrent, FALSE);
}
#ifdef MULTIPLE_HEAPS
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
if (do_concurrent_p)
{
// At this point we are sure we'll be starting a BGC, so save its per heap data here.
// global data is only calculated at the end of the GC so we don't need to worry about
// FGCs overwriting it.
memset (&bgc_data_per_heap, 0, sizeof (bgc_data_per_heap));
memcpy (&bgc_data_per_heap, &gc_data_per_heap, sizeof(gc_data_per_heap));
if (do_ephemeral_gc_p)
{
dprintf (2, ("GC threads running, doing gen%d GC", settings.condemned_generation));
gen_to_condemn_reasons.init();
gen_to_condemn_reasons.set_condition (gen_before_bgc);
gc_data_per_heap.gen_to_condemn_reasons.init (&gen_to_condemn_reasons);
gc1();
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_bgc_after_ephemeral);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
#ifdef MULTIPLE_HEAPS
do_post_gc();
#endif //MULTIPLE_HEAPS
settings = saved_bgc_settings;
assert (settings.concurrent);
do_background_gc();
#ifdef MULTIPLE_HEAPS
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
}
}
else
{
dprintf (2, ("couldn't create BGC threads, reverting to doing a blocking GC"));
gc1();
}
}
else
#endif //BACKGROUND_GC
{
gc1();
}
#ifndef MULTIPLE_HEAPS
allocation_running_time = (size_t)GCToOSInterface::GetLowPrecisionTimeStamp();
allocation_running_amount = dd_new_allocation (dynamic_data_of (0));
fgn_last_alloc = dd_new_allocation (dynamic_data_of (0));
#endif //MULTIPLE_HEAPS
done:
if (settings.pause_mode == pause_no_gc)
allocate_for_no_gc_after_gc();
int gn = settings.condemned_generation;
return gn;
}
GC的主函数
GC的主函数是gc1,包含了GC中最关键的处理,也是这一篇中需要重点讲解的部分。
gc1中的总体流程在BOTR文档已经有初步的介绍:
- 首先是
mark phase,标记存活的对象 - 然后是
plan phase,决定要压缩还是要清扫 - 如果要压缩则进入
relocate phase和compact phase - 如果要清扫则进入
sweep phase
在看具体的代码之前让我们一起复习之前讲到的Object的结构
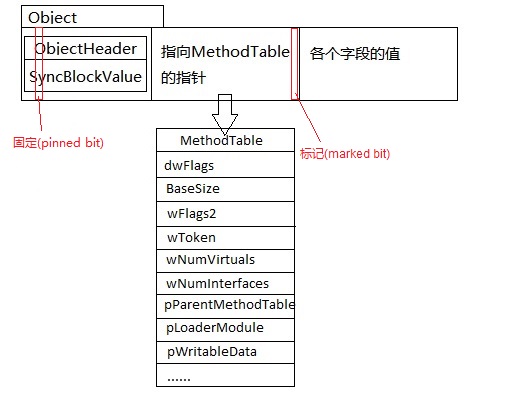
GC使用其中的2个bit来保存标记(marked)和固定(pinned)
标记(marked)表示对象是存活的,不应该被收集,储存在MethodTable指针 & 1中固定(pinned)表示对象不能被移动(压缩时不要移动这个对象), 储存在对象头 & 0x20000000中
这两个bit会在mark_phase中被标记,在plan_phase中被清除,不会残留到GC结束后
再复习堆段(heap segment)的结构
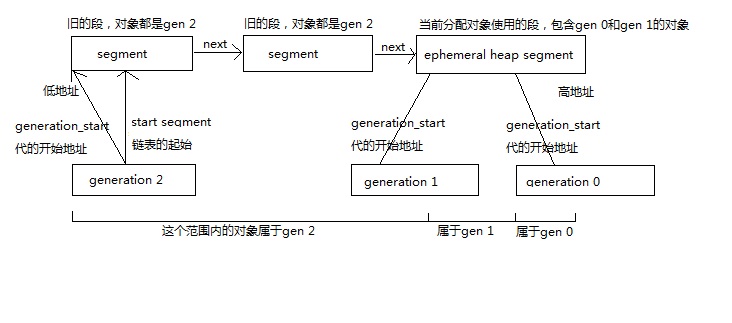
一个gc_heap中有两个segment链表,一个是小对象(gen 0~gen 2)用的链表,一个是大对象(gen 3)用的链表,
其中链表的最后一个节点是ephemeral heap segment,只用来保存gen 0和gen 1的对象,各个代都有一个开始地址,在开始地址之后的对象属于这个代或更年轻的代。
gc_heap::gc1函数的代码如下
//internal part of gc used by the serial and concurrent version
void gc_heap::gc1()
{
#ifdef BACKGROUND_GC
assert (settings.concurrent == (uint32_t)(bgc_thread_id.IsCurrentThread()));
#endif //BACKGROUND_GC
// 开始统计各个阶段的时间,这些是全局变量
#ifdef TIME_GC
mark_time = plan_time = reloc_time = compact_time = sweep_time = 0;
#endif //TIME_GC
// 验证小对象的segment列表(gen0~2的segment),除错用
verify_soh_segment_list();
int n = settings.condemned_generation;
// gc的标识序号+1
update_collection_counts ();
// 调用mark_phase和plan_phase(包括relocate, compact, sweep)
// 后台GC这一篇不解释,请跳到#endif //BACKGROUND_GC
#ifdef BACKGROUND_GC
bgc_alloc_lock->check();
#endif //BACKGROUND_GC
// 打印除错信息
free_list_info (max_generation, "beginning");
// 设置当前收集代
vm_heap->GcCondemnedGeneration = settings.condemned_generation;
assert (g_card_table == card_table);
{
// 设置收集范围
// 如果收集gen 2则从最小的地址一直到最大的地址
// 否则从收集代的开始地址一直到短暂的堆段(ephemeral heap segment)的预留地址
if (n == max_generation)
{
gc_low = lowest_address;
gc_high = highest_address;
}
else
{
gc_low = generation_allocation_start (generation_of (n));
gc_high = heap_segment_reserved (ephemeral_heap_segment);
}
#ifdef BACKGROUND_GC
if (settings.concurrent)
{
#ifdef TRACE_GC
time_bgc_last = GetHighPrecisionTimeStamp();
#endif //TRACE_GC
fire_bgc_event (BGCBegin);
concurrent_print_time_delta ("BGC");
//#ifdef WRITE_WATCH
//reset_write_watch (FALSE);
//#endif //WRITE_WATCH
concurrent_print_time_delta ("RW");
background_mark_phase();
free_list_info (max_generation, "after mark phase");
background_sweep();
free_list_info (max_generation, "after sweep phase");
}
else
#endif //BACKGROUND_GC
{
// 调用mark_phase标记存活的对象
// 请看下面的详解
mark_phase (n, FALSE);
// 设置对象结构有可能不合法,因为plan_phase中可能会对对象做出临时性的破坏
GCScan::GcRuntimeStructuresValid (FALSE);
// 调用plan_phase计划是否要压缩还是清扫
// 这个函数内部会完成压缩或者清扫,请看下面的详解
plan_phase (n);
// 重新设置对象结构合法
GCScan::GcRuntimeStructuresValid (TRUE);
}
}
// 记录gc结束时间
size_t end_gc_time = GetHighPrecisionTimeStamp();
// printf ("generation: %d, elapsed time: %Id\n", n, end_gc_time - dd_time_clock (dynamic_data_of (0)));
// 调整generation_pinned_allocated(固定对象的大小)和generation_allocation_size(分配的大小)
//adjust the allocation size from the pinned quantities.
for (int gen_number = 0; gen_number <= min (max_generation,n+1); gen_number++)
{
generation* gn = generation_of (gen_number);
if (settings.compactin)
{
generation_pinned_allocated (gn) += generation_pinned_allocation_compact_size (gn);
generation_allocation_size (generation_of (gen_number)) += generation_pinned_allocation_compact_size (gn);
}
else
{
generation_pinned_allocated (gn) += generation_pinned_allocation_sweep_size (gn);
generation_allocation_size (generation_of (gen_number)) += generation_pinned_allocation_sweep_size (gn);
}
generation_pinned_allocation_sweep_size (gn) = 0;
generation_pinned_allocation_compact_size (gn) = 0;
}
// 更新gc_data_per_heap, 和打印除错信息
#ifdef BACKGROUND_GC
if (settings.concurrent)
{
dynamic_data* dd = dynamic_data_of (n);
dd_gc_elapsed_time (dd) = end_gc_time - dd_time_clock (dd);
free_list_info (max_generation, "after computing new dynamic data");
gc_history_per_heap* current_gc_data_per_heap = get_gc_data_per_heap();
for (int gen_number = 0; gen_number < max_generation; gen_number++)
{
dprintf (2, ("end of BGC: gen%d new_alloc: %Id",
gen_number, dd_desired_allocation (dynamic_data_of (gen_number))));
current_gc_data_per_heap->gen_data[gen_number].size_after = generation_size (gen_number);
current_gc_data_per_heap->gen_data[gen_number].free_list_space_after = generation_free_list_space (generation_of (gen_number));
current_gc_data_per_heap->gen_data[gen_number].free_obj_space_after = generation_free_obj_space (generation_of (gen_number));
}
}
else
#endif //BACKGROUND_GC
{
free_list_info (max_generation, "end");
for (int gen_number = 0; gen_number <= n; gen_number++)
{
dynamic_data* dd = dynamic_data_of (gen_number);
dd_gc_elapsed_time (dd) = end_gc_time - dd_time_clock (dd);
compute_new_dynamic_data (gen_number);
}
if (n != max_generation)
{
int gen_num_for_data = ((n < (max_generation - 1)) ? (n + 1) : (max_generation + 1));
for (int gen_number = (n + 1); gen_number <= gen_num_for_data; gen_number++)
{
get_gc_data_per_heap()->gen_data[gen_number].size_after = generation_size (gen_number);
get_gc_data_per_heap()->gen_data[gen_number].free_list_space_after = generation_free_list_space (generation_of (gen_number));
get_gc_data_per_heap()->gen_data[gen_number].free_obj_space_after = generation_free_obj_space (generation_of (gen_number));
}
}
get_gc_data_per_heap()->maxgen_size_info.running_free_list_efficiency = (uint32_t)(generation_allocator_efficiency (generation_of (max_generation)) * 100);
free_list_info (max_generation, "after computing new dynamic data");
if (heap_number == 0)
{
dprintf (GTC_LOG, ("GC#%d(gen%d) took %Idms",
dd_collection_count (dynamic_data_of (0)),
settings.condemned_generation,
dd_gc_elapsed_time (dynamic_data_of (0))));
}
for (int gen_number = 0; gen_number <= (max_generation + 1); gen_number++)
{
dprintf (2, ("end of FGC/NGC: gen%d new_alloc: %Id",
gen_number, dd_desired_allocation (dynamic_data_of (gen_number))));
}
}
// 更新收集代+1代的动态数据(dd)
if (n < max_generation)
{
compute_promoted_allocation (1 + n);
dynamic_data* dd = dynamic_data_of (1 + n);
size_t new_fragmentation = generation_free_list_space (generation_of (1 + n)) +
generation_free_obj_space (generation_of (1 + n));
#ifdef BACKGROUND_GC
if (current_c_gc_state != c_gc_state_planning)
#endif //BACKGROUND_GC
{
if (settings.promotion)
{
dd_fragmentation (dd) = new_fragmentation;
}
else
{
//assert (dd_fragmentation (dd) == new_fragmentation);
}
}
}
// 更新ephemeral_low(gen 1的开始的地址)和ephemeral_high(ephemeral_heap_segment的预留地址)
#ifdef BACKGROUND_GC
if (!settings.concurrent)
#endif //BACKGROUND_GC
{
adjust_ephemeral_limits(!!IsGCThread());
}
#ifdef BACKGROUND_GC
assert (ephemeral_low == generation_allocation_start (generation_of ( max_generation -1)));
assert (ephemeral_high == heap_segment_reserved (ephemeral_heap_segment));
#endif //BACKGROUND_GC
// 如果fgn_maxgen_percent有设置并且收集的是代1则检查是否要收集代2, 否则通知full_gc_end_event事件
if (fgn_maxgen_percent)
{
if (settings.condemned_generation == (max_generation - 1))
{
check_for_full_gc (max_generation - 1, 0);
}
else if (settings.condemned_generation == max_generation)
{
if (full_gc_approach_event_set
#ifdef MULTIPLE_HEAPS
&& (heap_number == 0)
#endif //MULTIPLE_HEAPS
)
{
dprintf (2, ("FGN-GC: setting gen2 end event"));
full_gc_approach_event.Reset();
#ifdef BACKGROUND_GC
// By definition WaitForFullGCComplete only succeeds if it's full, *blocking* GC, otherwise need to return N/A
fgn_last_gc_was_concurrent = settings.concurrent ? TRUE : FALSE;
#endif //BACKGROUND_GC
full_gc_end_event.Set();
full_gc_approach_event_set = false;
}
}
}
// 重新决定分配量(allocation_quantum)
// 这里的 dd_new_allocation 已经重新设置过
// 分配量 = 离下次启动gc需要分配的大小 / (2 * 已用的分配上下文数量), 最小1K, 最大8K
// 如果很快就要重新启动gc, 或者用的分配上下文较多(浪费较多), 则需要减少分配量
// 大部分情况下这里的分配量都会设置为默认的8K
#ifdef BACKGROUND_GC
if (!settings.concurrent)
#endif //BACKGROUND_GC
{
//decide on the next allocation quantum
if (alloc_contexts_used >= 1)
{
allocation_quantum = Align (min ((size_t)CLR_SIZE,
(size_t)max (1024, get_new_allocation (0) / (2 * alloc_contexts_used))),
get_alignment_constant(FALSE));
dprintf (3, ("New allocation quantum: %d(0x%Ix)", allocation_quantum, allocation_quantum));
}
}
// 重设Write Watch,默认会用Write barrier所以这里不会被调用
#ifdef NO_WRITE_BARRIER
reset_write_watch(FALSE);
#endif //NO_WRITE_BARRIER
// 打印出错信息
descr_generations (FALSE);
descr_card_table();
// 验证小对象的segment列表(gen0~2的segment),除错用
verify_soh_segment_list();
#ifdef BACKGROUND_GC
add_to_history_per_heap();
if (heap_number == 0)
{
add_to_history();
}
#endif // BACKGROUND_GC
#ifdef GC_STATS
if (GCStatistics::Enabled() && heap_number == 0)
g_GCStatistics.AddGCStats(settings,
dd_gc_elapsed_time(dynamic_data_of(settings.condemned_generation)));
#endif // GC_STATS
#ifdef TIME_GC
fprintf (stdout, "%d,%d,%d,%d,%d,%d\n",
n, mark_time, plan_time, reloc_time, compact_time, sweep_time);
#endif //TIME_GC
#ifdef BACKGROUND_GC
assert (settings.concurrent == (uint32_t)(bgc_thread_id.IsCurrentThread()));
#endif //BACKGROUND_GC
// 检查heap状态,除错用
// 如果是后台gc还需要停止运行引擎,验证完以后再重启
#if defined(VERIFY_HEAP) || (defined (FEATURE_EVENT_TRACE) && defined(BACKGROUND_GC))
if (FALSE
#ifdef VERIFY_HEAP
// Note that right now g_pConfig->GetHeapVerifyLevel always returns the same
// value. If we ever allow randomly adjusting this as the process runs,
// we cannot call it this way as joins need to match - we must have the same
// value for all heaps like we do with bgc_heap_walk_for_etw_p.
|| (g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_GC)
#endif
#if defined(FEATURE_EVENT_TRACE) && defined(BACKGROUND_GC)
|| (bgc_heap_walk_for_etw_p && settings.concurrent)
#endif
)
{
#ifdef BACKGROUND_GC
Thread* current_thread = GetThread();
BOOL cooperative_mode = TRUE;
if (settings.concurrent)
{
cooperative_mode = enable_preemptive (current_thread);
#ifdef MULTIPLE_HEAPS
bgc_t_join.join(this, gc_join_suspend_ee_verify);
if (bgc_t_join.joined())
{
bgc_threads_sync_event.Reset();
dprintf(2, ("Joining BGC threads to suspend EE for verify heap"));
bgc_t_join.restart();
}
if (heap_number == 0)
{
suspend_EE();
bgc_threads_sync_event.Set();
}
else
{
bgc_threads_sync_event.Wait(INFINITE, FALSE);
dprintf (2, ("bgc_threads_sync_event is signalled"));
}
#else
suspend_EE();
#endif //MULTIPLE_HEAPS
//fix the allocation area so verify_heap can proceed.
fix_allocation_contexts (FALSE);
}
#endif //BACKGROUND_GC
#ifdef BACKGROUND_GC
assert (settings.concurrent == (uint32_t)(bgc_thread_id.IsCurrentThread()));
#ifdef FEATURE_EVENT_TRACE
if (bgc_heap_walk_for_etw_p && settings.concurrent)
{
make_free_lists_for_profiler_for_bgc();
}
#endif // FEATURE_EVENT_TRACE
#endif //BACKGROUND_GC
#ifdef VERIFY_HEAP
if (g_pConfig->GetHeapVerifyLevel() & EEConfig::HEAPVERIFY_GC)
verify_heap (FALSE);
#endif // VERIFY_HEAP
#ifdef BACKGROUND_GC
if (settings.concurrent)
{
repair_allocation_contexts (TRUE);
#ifdef MULTIPLE_HEAPS
bgc_t_join.join(this, gc_join_restart_ee_verify);
if (bgc_t_join.joined())
{
bgc_threads_sync_event.Reset();
dprintf(2, ("Joining BGC threads to restart EE after verify heap"));
bgc_t_join.restart();
}
if (heap_number == 0)
{
restart_EE();
bgc_threads_sync_event.Set();
}
else
{
bgc_threads_sync_event.Wait(INFINITE, FALSE);
dprintf (2, ("bgc_threads_sync_event is signalled"));
}
#else
restart_EE();
#endif //MULTIPLE_HEAPS
disable_preemptive (current_thread, cooperative_mode);
}
#endif //BACKGROUND_GC
}
#endif // defined(VERIFY_HEAP) || (defined(FEATURE_EVENT_TRACE) && defined(BACKGROUND_GC))
// 如果有多个heap(服务器GC),平均各个heap的阈值(dd_gc_new_allocation, dd_new_allocation, dd_desired_allocation)
// 其他服务器GC和工作站GC的共通处理请跳到#else看
#ifdef MULTIPLE_HEAPS
if (!settings.concurrent)
{
gc_t_join.join(this, gc_join_done);
if (gc_t_join.joined ())
{
gc_heap::internal_gc_done = false;
//equalize the new desired size of the generations
int limit = settings.condemned_generation;
if (limit == max_generation)
{
limit = max_generation+1;
}
for (int gen = 0; gen <= limit; gen++)
{
size_t total_desired = 0;
for (int i = 0; i < gc_heap::n_heaps; i++)
{
gc_heap* hp = gc_heap::g_heaps[i];
dynamic_data* dd = hp->dynamic_data_of (gen);
size_t temp_total_desired = total_desired + dd_desired_allocation (dd);
if (temp_total_desired < total_desired)
{
// we overflowed.
total_desired = (size_t)MAX_PTR;
break;
}
total_desired = temp_total_desired;
}
size_t desired_per_heap = Align (total_desired/gc_heap::n_heaps,
get_alignment_constant ((gen != (max_generation+1))));
if (gen == 0)
{
#if 1 //subsumed by the linear allocation model
// to avoid spikes in mem usage due to short terms fluctuations in survivorship,
// apply some smoothing.
static size_t smoothed_desired_per_heap = 0;
size_t smoothing = 3; // exponential smoothing factor
if (smoothing > VolatileLoad(&settings.gc_index))
smoothing = VolatileLoad(&settings.gc_index);
smoothed_desired_per_heap = desired_per_heap / smoothing + ((smoothed_desired_per_heap / smoothing) * (smoothing-1));
dprintf (1, ("sn = %Id n = %Id", smoothed_desired_per_heap, desired_per_heap));
desired_per_heap = Align(smoothed_desired_per_heap, get_alignment_constant (true));
#endif //0
// if desired_per_heap is close to min_gc_size, trim it
// down to min_gc_size to stay in the cache
gc_heap* hp = gc_heap::g_heaps[0];
dynamic_data* dd = hp->dynamic_data_of (gen);
size_t min_gc_size = dd_min_gc_size(dd);
// if min GC size larger than true on die cache, then don't bother
// limiting the desired size
if ((min_gc_size <= GCToOSInterface::GetLargestOnDieCacheSize(TRUE) / GCToOSInterface::GetLogicalCpuCount()) &&
desired_per_heap <= 2*min_gc_size)
{
desired_per_heap = min_gc_size;
}
#ifdef BIT64
desired_per_heap = joined_youngest_desired (desired_per_heap);
dprintf (2, ("final gen0 new_alloc: %Id", desired_per_heap));
#endif // BIT64
gc_data_global.final_youngest_desired = desired_per_heap;
}
#if 1 //subsumed by the linear allocation model
if (gen == (max_generation + 1))
{
// to avoid spikes in mem usage due to short terms fluctuations in survivorship,
// apply some smoothing.
static size_t smoothed_desired_per_heap_loh = 0;
size_t smoothing = 3; // exponential smoothing factor
size_t loh_count = dd_collection_count (dynamic_data_of (max_generation));
if (smoothing > loh_count)
smoothing = loh_count;
smoothed_desired_per_heap_loh = desired_per_heap / smoothing + ((smoothed_desired_per_heap_loh / smoothing) * (smoothing-1));
dprintf( 2, ("smoothed_desired_per_heap_loh = %Id desired_per_heap = %Id", smoothed_desired_per_heap_loh, desired_per_heap));
desired_per_heap = Align(smoothed_desired_per_heap_loh, get_alignment_constant (false));
}
#endif //0
for (int i = 0; i < gc_heap::n_heaps; i++)
{
gc_heap* hp = gc_heap::g_heaps[i];
dynamic_data* dd = hp->dynamic_data_of (gen);
dd_desired_allocation (dd) = desired_per_heap;
dd_gc_new_allocation (dd) = desired_per_heap;
dd_new_allocation (dd) = desired_per_heap;
if (gen == 0)
{
hp->fgn_last_alloc = desired_per_heap;
}
}
}
#ifdef FEATURE_LOH_COMPACTION
BOOL all_heaps_compacted_p = TRUE;
#endif //FEATURE_LOH_COMPACTION
for (int i = 0; i < gc_heap::n_heaps; i++)
{
gc_heap* hp = gc_heap::g_heaps[i];
hp->decommit_ephemeral_segment_pages();
hp->rearrange_large_heap_segments();
#ifdef FEATURE_LOH_COMPACTION
all_heaps_compacted_p &= hp->loh_compacted_p;
#endif //FEATURE_LOH_COMPACTION
}
#ifdef FEATURE_LOH_COMPACTION
check_loh_compact_mode (all_heaps_compacted_p);
#endif //FEATURE_LOH_COMPACTION
fire_pevents();
gc_t_join.restart();
}
alloc_context_count = 0;
heap_select::mark_heap (heap_number);
}
#else
// 以下处理服务器GC和工作站共通,你可以在#else上面找到对应的代码
// 设置统计数据(最年轻代的gc阈值)
gc_data_global.final_youngest_desired =
dd_desired_allocation (dynamic_data_of (0));
// 如果大对象的堆(loh)压缩模式是仅1次(once)且所有heap的loh都压缩过则重置loh的压缩模式
check_loh_compact_mode (loh_compacted_p);
// 释放ephemeral segment中未用到的内存(页)
decommit_ephemeral_segment_pages();
// 触发etw事件,统计用
fire_pevents();
if (!(settings.concurrent))
{
// 删除空的大对象segment
rearrange_large_heap_segments();
// 通知运行引擎GC已完成(GcDone, 目前不会做出实质的处理)并且更新一些统计数据
do_post_gc();
}
#ifdef BACKGROUND_GC
recover_bgc_settings();
#endif //BACKGROUND_GC
#endif //MULTIPLE_HEAPS
}
接下来我们将分别分析GC中的五个阶段(mark_phase, plan_phase, relocate_phase, compact_phase, sweep_phase)的内部处理
标记阶段(mark_phase)
这个阶段的作用是找出收集垃圾的范围(gc_low ~ gc_high)中有哪些对象是存活的,如果存活则标记(m_pMethTab |= 1),
另外还会根据GC Handle查找有哪些对象是固定的(pinned),如果对象固定则标记(m_uSyncBlockValue |= 0x20000000)。
简单解释下GC Handle和Pinned Object,GC Handle用于在托管代码中调用非托管代码时可以决定传递的指针的处理,
一个类型是Pinned的GC Handle可以防止GC在压缩时移动对象,这样非托管代码中保存的指针地址不会失效,详细可以看微软的文档。
在继续看代码之前我们先来了解Card Table的概念:
Card Table
如果你之前已经了解过GC,可能知道有的语言实现GC会有一个根对象,从根对象一直扫描下去可以找到所有存活的对象。
但这样有一个缺陷,如果对象很多,扫描的时间也会相应的变长,为了提高效率,CoreCLR使用了分代GC(包括之前的.Net Framework都是分代GC),
分代GC可以只选择扫描一部分的对象(年轻的对象更有可能被回收)而不是全部对象,那么分代GC的扫描是如何实现的?
在CoreCLR中对象之间的引用(例如B是A的成员或者B在数组A中,可以称作A引用B)一般包含以下情况
- 各个线程栈(stack)和寄存器(register)中的对象引用堆段(heap segment)中的对象
- CoreCLR有办法可以检测到Managed Thread中在栈和寄存器中的对象
- 这些对象是根对象(GC Root)的一种
- GC Handle表中的句柄引用堆段(heap segment)中的对象
- 这些对象也是根对象的一种
- 析构队列中的对象引用堆段(heap segment)中的对象
- 这些对象也是根对象的一种
- 同代对象之间的引用
- 隔代对象之间的引用
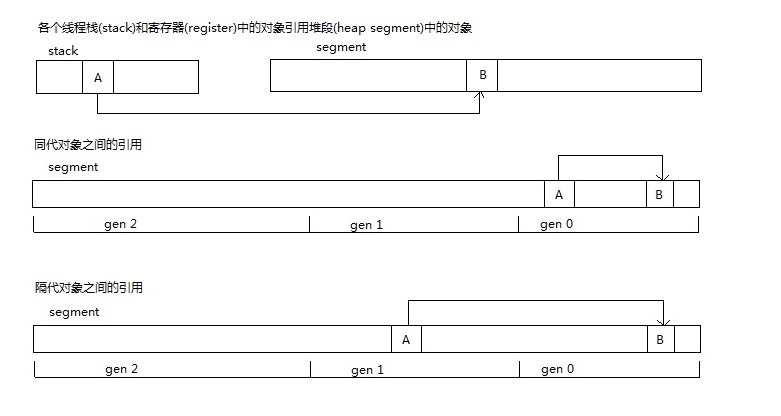
请考虑下图的情况,我们这次只想扫描gen 0,栈中的对象A引用了gen 1的对象B,对象B引用了gen 0的对象C,
在扫描的时候因为B不在扫描范围(gc_low ~ gc_high)中,CoreCLR不会去继续跟踪B的引用,
如果这时候gen 0中无其他对象引用对象C,是否会导致对象C被误回收?
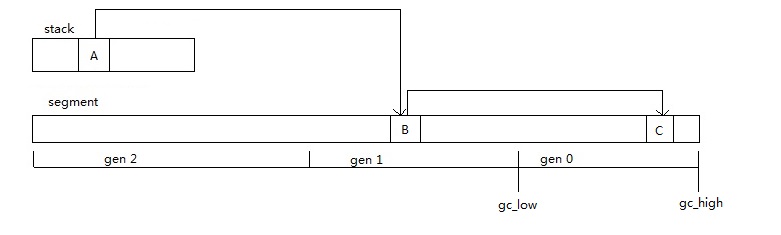
为了解决这种情况导致的问题,CoreCLR使用了Card Table,所谓Card Table就是专门记录跨代引用的一个数组
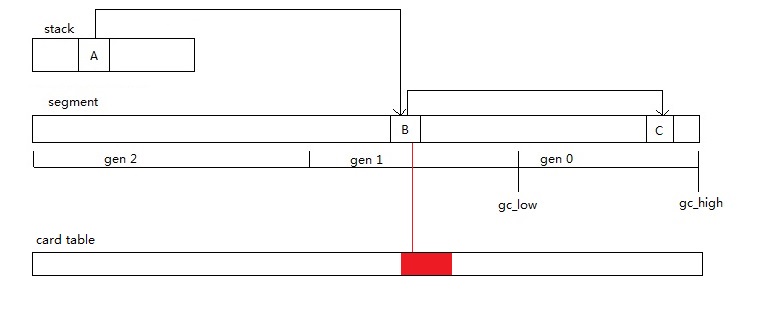
当我们设置B.member = C的时候,JIT会把赋值替换为JIT_WriteBarrier(&B.member, C)(或同等的其他函数)JIT_WriteBarrier函数中会设置*dst = ref,并且如果ref在ephemeral heap segment中(ref可能是gen 0或gen 1的对象)时,
设置dst在Card Table中所属的字节为0xff,Card Table中一个字节默认涵盖的范围在32位下是1024字节,在64位下是2048字节。
需要注意的是这里的dst是B.member的地址而不是B的地址,B.member的地址会是B的地址加一定的偏移值,
而B自身的地址不一定会在Card Table中得到标记,我们之后可以根据B.member的地址得到B的地址(可以看find_first_object函数)。
有了Card Table以后,只回收年轻代(非Full GC)时除了扫描根对象以外我们还需要扫描Card Table中标记的范围来防止误回收对象。
JIT_WriteBarrier函数的代码如下
// This function is a JIT helper, but it must NOT use HCIMPL2 because it
// modifies Thread state that will not be restored if an exception occurs
// inside of memset. A normal EH unwind will not occur.
extern "C" HCIMPL2_RAW(VOID, JIT_WriteBarrier, Object **dst, Object *ref)
{
// Must use static contract here, because if an AV occurs, a normal EH
// unwind will not occur, and destructors will not run.
STATIC_CONTRACT_MODE_COOPERATIVE;
STATIC_CONTRACT_THROWS;
STATIC_CONTRACT_GC_NOTRIGGER;
#ifdef FEATURE_COUNT_GC_WRITE_BARRIERS
IncUncheckedBarrierCount();
#endif
// no HELPER_METHOD_FRAME because we are MODE_COOPERATIVE, GC_NOTRIGGER
*dst = ref;
// If the store above succeeded, "dst" should be in the heap.
assert(GCHeap::GetGCHeap()->IsHeapPointer((void*)dst));
#ifdef WRITE_BARRIER_CHECK
updateGCShadow(dst, ref); // support debugging write barrier
#endif
#ifdef FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
if (SoftwareWriteWatch::IsEnabledForGCHeap())
{
SoftwareWriteWatch::SetDirty(dst, sizeof(*dst));
}
#endif // FEATURE_USE_SOFTWARE_WRITE_WATCH_FOR_GC_HEAP
#ifdef FEATURE_COUNT_GC_WRITE_BARRIERS
if((BYTE*) dst >= g_ephemeral_low && (BYTE*) dst < g_ephemeral_high)
{
UncheckedDestInEphem++;
}
#endif
if((BYTE*) ref >= g_ephemeral_low && (BYTE*) ref < g_ephemeral_high)
{
#ifdef FEATURE_COUNT_GC_WRITE_BARRIERS
UncheckedAfterRefInEphemFilter++;
#endif
BYTE* pCardByte = (BYTE *)VolatileLoadWithoutBarrier(&g_card_table) + card_byte((BYTE *)dst);
if(*pCardByte != 0xFF)
{
#ifdef FEATURE_COUNT_GC_WRITE_BARRIERS
UncheckedAfterAlreadyDirtyFilter++;
#endif
*pCardByte = 0xFF;
}
}
}
HCIMPLEND_RAW
card_byte macro的代码如下
#if defined(_WIN64)
// Card byte shift is different on 64bit.
#define card_byte_shift 11
#else
#define card_byte_shift 10
#endif
#define card_byte(addr) (((size_t)(addr)) >> card_byte_shift)
#define card_bit(addr) (1 << ((((size_t)(addr)) >> (card_byte_shift - 3)) & 7))
标记阶段(mark_phase)的代码
gc_heap::mark_phase函数的代码如下:
void gc_heap::mark_phase (int condemned_gen_number, BOOL mark_only_p)
{
assert (settings.concurrent == FALSE);
// 扫描上下文
ScanContext sc;
sc.thread_number = heap_number;
sc.promotion = TRUE;
sc.concurrent = FALSE;
dprintf(2,("---- Mark Phase condemning %d ----", condemned_gen_number));
// 是否Full GC
BOOL full_p = (condemned_gen_number == max_generation);
// 统计标记阶段的开始时间
#ifdef TIME_GC
unsigned start;
unsigned finish;
start = GetCycleCount32();
#endif //TIME_GC
// 重置动态数据(dd)
int gen_to_init = condemned_gen_number;
if (condemned_gen_number == max_generation)
{
gen_to_init = max_generation + 1;
}
for (int gen_idx = 0; gen_idx <= gen_to_init; gen_idx++)
{
dynamic_data* dd = dynamic_data_of (gen_idx);
dd_begin_data_size (dd) = generation_size (gen_idx) -
dd_fragmentation (dd) -
Align (size (generation_allocation_start (generation_of (gen_idx))));
dprintf (2, ("begin data size for gen%d is %Id", gen_idx, dd_begin_data_size (dd)));
dd_survived_size (dd) = 0;
dd_pinned_survived_size (dd) = 0;
dd_artificial_pinned_survived_size (dd) = 0;
dd_added_pinned_size (dd) = 0;
#ifdef SHORT_PLUGS
dd_padding_size (dd) = 0;
#endif //SHORT_PLUGS
#if defined (RESPECT_LARGE_ALIGNMENT) || defined (FEATURE_STRUCTALIGN)
dd_num_npinned_plugs (dd) = 0;
#endif //RESPECT_LARGE_ALIGNMENT || FEATURE_STRUCTALIGN
}
#ifdef FFIND_OBJECT
if (gen0_must_clear_bricks > 0)
gen0_must_clear_bricks--;
#endif //FFIND_OBJECT
size_t last_promoted_bytes = 0;
// 重设mark stack
// mark_stack_array在GC各个阶段有不同的用途,在mark phase中的用途是用来标记对象时代替递归防止爆栈
promoted_bytes (heap_number) = 0;
reset_mark_stack();
#ifdef SNOOP_STATS
memset (&snoop_stat, 0, sizeof(snoop_stat));
snoop_stat.heap_index = heap_number;
#endif //SNOOP_STATS
// 启用scable marking时
// 服务器GC上会启用,工作站GC上不会启用
// scable marking这篇中不会分析
#ifdef MH_SC_MARK
if (full_p)
{
//initialize the mark stack
for (int i = 0; i < max_snoop_level; i++)
{
((uint8_t**)(mark_stack_array))[i] = 0;
}
mark_stack_busy() = 1;
}
#endif //MH_SC_MARK
static uint32_t num_sizedrefs = 0;
// scable marking的处理
#ifdef MH_SC_MARK
static BOOL do_mark_steal_p = FALSE;
#endif //MH_SC_MARK
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_begin_mark_phase);
if (gc_t_join.joined())
{
#endif //MULTIPLE_HEAPS
num_sizedrefs = SystemDomain::System()->GetTotalNumSizedRefHandles();
#ifdef MULTIPLE_HEAPS
// scable marking的处理
#ifdef MH_SC_MARK
if (full_p)
{
size_t total_heap_size = get_total_heap_size();
if (total_heap_size > (100 * 1024 * 1024))
{
do_mark_steal_p = TRUE;
}
else
{
do_mark_steal_p = FALSE;
}
}
else
{
do_mark_steal_p = FALSE;
}
#endif //MH_SC_MARK
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
{
// 初始化mark list, full gc时不会使用
#ifdef MARK_LIST
//set up the mark lists from g_mark_list
assert (g_mark_list);
#ifdef MULTIPLE_HEAPS
mark_list = &g_mark_list [heap_number*mark_list_size];
#else
mark_list = g_mark_list;
#endif //MULTIPLE_HEAPS
//dont use the mark list for full gc
//because multiple segments are more complex to handle and the list
//is likely to overflow
if (condemned_gen_number != max_generation)
mark_list_end = &mark_list [mark_list_size-1];
else
mark_list_end = &mark_list [0];
mark_list_index = &mark_list [0];
#endif //MARK_LIST
shigh = (uint8_t*) 0;
slow = MAX_PTR;
//%type% category = quote (mark);
// 如果当前是Full GC并且有类型是SizedRef的GC Handle时把它们作为根对象扫描
// 参考https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/objecthandle.h#L177
// SizedRef是一个非公开类型的GC Handle(其他还有RefCounted),目前还看不到有代码使用
if ((condemned_gen_number == max_generation) && (num_sizedrefs > 0))
{
GCScan::GcScanSizedRefs(GCHeap::Promote, condemned_gen_number, max_generation, &sc);
fire_mark_event (heap_number, ETW::GC_ROOT_SIZEDREF, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
#ifdef MULTIPLE_HEAPS
gc_t_join.join(this, gc_join_scan_sizedref_done);
if (gc_t_join.joined())
{
dprintf(3, ("Done with marking all sized refs. Starting all gc thread for marking other strong roots"));
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
}
dprintf(3,("Marking Roots"));
// 扫描根对象(各个线程中栈和寄存器中的对象)
// 这里的GcScanRoots是一个高阶函数,会扫描根对象和根对象引用的对象,并对它们调用传入的`GCHeap::Promote`函数
// 在下面的relocate phase还会传入`GCHeap::Relocate`给`GcScanRoots`
// BOTR中有一份专门的文档介绍了如何实现栈扫描,地址是
// https://github.com/dotnet/coreclr/blob/master/Documentation/botr/stackwalking.md
// 这个函数的内部处理要贴代码的话会非常的长,这里我只贴调用流程
// GcScanRoots的处理
// 枚举线程
// 调用 ScanStackRoots(pThread, fn, sc);
// 调用 pThread->StackWalkFrames
// 调用 StackWalkFramesEx
// 使用 StackFrameIterator 枚举栈中的所有帧
// 调用 StackFrameIterator::Next
// 调用 StackFrameIterator::Filter
// 调用 MakeStackwalkerCallback 处理单帧
// 调用 GcStackCrawlCallBack
// 如果 IsFrameless 则调用 EECodeManager::EnumGcRefs
// 调用 GcInfoDecoder::EnumerateLiveSlots
// 调用 GcInfoDecoder::ReportSlotToGC
// 如果是寄存器中的对象则调用 GcInfoDecoder::ReportRegisterToGC
// 如果是栈上的对象则调用 GcInfoDecoder::ReportStackSlotToGC
// 调用 GcEnumObject
// 调用 GCHeap::Promote, 接下来和下面的一样
// 如果 !IsFrameless 则调用 FrameBase::GcScanRoots
// 继承函数的处理 GCFrame::GcScanRoots
// 调用 GCHeap::Promote
// 调用 gc_heap::mark_object_simple
// 调用 gc_mark1, 第一次标记时会返回true
// 调用 CObjectHeader::IsMarked !!(((size_t)RawGetMethodTable()) & GC_MARKED)
// 调用 CObjectHeader::SetMarked RawSetMethodTable((MethodTable *) (((size_t) RawGetMethodTable()) | GC_MARKED));
// 如果对象未被标记过,调用 go_through_object_cl (macro) 枚举对象的所有成员
// 对成员对象调用mark_object_simple1,和mark_object_simple的区别是,mark_object_simple1使用mark_stack_array来循环标记对象
// 使用mark_stack_array代替递归可以防止爆栈
// 注意mark_stack_array也有大小限制,如果超过了(overflow)不会扩展(grow),而是记录并交给下面的GcDhInitialScan处理
GCScan::GcScanRoots(GCHeap::Promote,
condemned_gen_number, max_generation,
&sc);
// 调用通知事件通知有多少字节在这一次被标记
fire_mark_event (heap_number, ETW::GC_ROOT_STACK, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
#ifdef BACKGROUND_GC
if (recursive_gc_sync::background_running_p())
{
scan_background_roots (GCHeap::Promote, heap_number, &sc);
}
#endif //BACKGROUND_GC
// 扫描当前关键析构(Critical Finalizer)队列中对象的引用
// 非关键析构队列中的对象会在下面的ScanForFinalization中扫描
// 关于析构队列可以参考这些URL
// https://github.com/dotnet/coreclr/blob/master/Documentation/botr/threading.md
// http://stackoverflow.com/questions/1268525/what-are-the-finalizer-queue-and-controlthreadmethodentry
// http://stackoverflow.com/questions/9030126/why-classes-with-finalizers-need-more-than-one-garbage-collection-cycle
// https://msdn.microsoft.com/en-us/library/system.runtime.constrainedexecution.criticalfinalizerobject(v=vs.110).aspx
// https://msdn.microsoft.com/en-us/library/system.runtime.constrainedexecution(v=vs.110).aspx
#ifdef FEATURE_PREMORTEM_FINALIZATION
dprintf(3, ("Marking finalization data"));
finalize_queue->GcScanRoots(GCHeap::Promote, heap_number, 0);
#endif // FEATURE_PREMORTEM_FINALIZATION
// 调用通知事件通知有多少字节在这一次被标记
fire_mark_event (heap_number, ETW::GC_ROOT_FQ, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
// MTHTS
{
// 扫描GC Handle引用的对象
// 如果GC Handle的类型是Pinned同时会设置对象为pinned
// 设置对象为pinned的流程如下
// GCScan::GcScanHandles
// Ref_TracePinningRoots
// HndScanHandlersForGC
// TableScanHandles
// SegmentScanByTypeMap
// BlockScanBlocksEphemeral
// BlockScanBlocksEphemeralWorker
// ScanConsecutiveHandlesWithoutUserData
// PinObject
// GCHeap::Promote(pRef, (ScanContext *)lpl, GC_CALL_PINNED)
// 判断flags包含GC_CALL_PINNED时调用 gc_heap::pin_object
// 如果对象在扫描范围(gc_low ~ gc_high)时调用set_pinned(o)
// GetHeader()->SetGCBit()
// m_uSyncBlockValue |= BIT_SBLK_GC_RESERVE
// 这里会标记包括来源于静态字段的引用
dprintf(3,("Marking handle table"));
GCScan::GcScanHandles(GCHeap::Promote,
condemned_gen_number, max_generation,
&sc);
// 调用通知事件通知有多少字节在这一次被标记
fire_mark_event (heap_number, ETW::GC_ROOT_HANDLES, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
}
// 扫描根对象完成了,如果不是Full GC接下来还需要扫描Card Table
// 记录扫描Card Table之前标记的字节数量(存活的字节数量)
#ifdef TRACE_GC
size_t promoted_before_cards = promoted_bytes (heap_number);
#endif //TRACE_GC
// Full GC不需要扫Card Table
dprintf (3, ("before cards: %Id", promoted_before_cards));
if (!full_p)
{
#ifdef CARD_BUNDLE
#ifdef MULTIPLE_HEAPS
if (gc_t_join.r_join(this, gc_r_join_update_card_bundle))
{
#endif //MULTIPLE_HEAPS
// 从Write Watch更新Card Table的索引(Card Bundles)
// 当内存空间过大时,扫描Card Table的效率会变低,使用Card Bundle可以标记Card Table中的哪些区域需要扫描
// 在作者环境的下Card Bundle不启用
update_card_table_bundle ();
#ifdef MULTIPLE_HEAPS
gc_t_join.r_restart();
}
#endif //MULTIPLE_HEAPS
#endif //CARD_BUNDLE
// 标记对象的函数,需要分析时使用特殊的函数
card_fn mark_object_fn = &gc_heap::mark_object_simple;
#ifdef HEAP_ANALYZE
heap_analyze_success = TRUE;
if (heap_analyze_enabled)
{
internal_root_array_index = 0;
current_obj = 0;
current_obj_size = 0;
mark_object_fn = &gc_heap::ha_mark_object_simple;
}
#endif //HEAP_ANALYZE
// 遍历Card Table标记小对象
// 像之前所说的Card Table中对应的区域包含的是成员的地址,不一定包含来源对象的开始地址,find_first_object函数可以支持找到来源对象的开始地址
// 这个函数除了调用mark_object_simple标记找到的对象以外,还会更新`generation_skip_ratio`这个成员,算法如下
// n_gen 通过卡片标记的对象数量, gc_low ~ gc_high
// n_eph 通过卡片扫描的对象数量, 上一代的开始地址 ~ gc_high (cg_pointers_found的累加)
// 表示扫描的对象中有多少%的对象被标记了
// generation_skip_ratio = (n_eph > 400) ? (n_gen * 1.0 / n_eph * 100) : 100
// `generation_skip_ratio`会影响到对象是否升代,请搜索上面关于`generation_skip_ratio`的注释
dprintf(3,("Marking cross generation pointers"));
mark_through_cards_for_segments (mark_object_fn, FALSE);
// 遍历Card Table标记大对象
// 处理和前面一样,只是扫描的范围是大对象的segment
// 这里也会算出generation_skip_ratio,如果算出的generation_skip_ratio比原来的generation_skip_ratio要小则使用算出的值
dprintf(3,("Marking cross generation pointers for large objects"));
mark_through_cards_for_large_objects (mark_object_fn, FALSE);
// 调用通知事件通知有多少字节在这一次被标记
dprintf (3, ("marked by cards: %Id",
(promoted_bytes (heap_number) - promoted_before_cards)));
fire_mark_event (heap_number, ETW::GC_ROOT_OLDER, (promoted_bytes (heap_number) - last_promoted_bytes));
last_promoted_bytes = promoted_bytes (heap_number);
}
}
// scable marking的处理
#ifdef MH_SC_MARK
if (do_mark_steal_p)
{
mark_steal();
}
#endif //MH_SC_MARK
// 处理HNDTYPE_DEPENDENT类型的GC Handle
// 这个GC Handle的意义是保存两个对象primary和secondary,告诉primary引用了secondary
// 如果primary已标记则secondary也会被标记
// 这里还会处理之前发生的mark_stack_array溢出(循环标记对象时子对象过多导致mark_stack_array容不下)
// 这次不一定会完成,下面还会等待线程同步后(服务器GC下)再扫一遍
// Dependent handles need to be scanned with a special algorithm (see the header comment on
// scan_dependent_handles for more detail). We perform an initial scan without synchronizing with other
// worker threads or processing any mark stack overflow. This is not guaranteed to complete the operation
// but in a common case (where there are no dependent handles that are due to be collected) it allows us
// to optimize away further scans. The call to scan_dependent_handles is what will cycle through more
// iterations if required and will also perform processing of any mark stack overflow once the dependent
// handle table has been fully promoted.
GCScan::GcDhInitialScan(GCHeap::Promote, condemned_gen_number, max_generation, &sc);
scan_dependent_handles(condemned_gen_number, &sc, true);
// 通知标记阶段完成扫描根对象(和Card Table)
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Joining for short weak handle scan"));
gc_t_join.join(this, gc_join_null_dead_short_weak);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
#ifdef HEAP_ANALYZE
heap_analyze_enabled = FALSE;
DACNotifyGcMarkEnd(condemned_gen_number);
#endif // HEAP_ANALYZE
GCToEEInterface::AfterGcScanRoots (condemned_gen_number, max_generation, &sc);
#ifdef MULTIPLE_HEAPS
if (!full_p)
{
// we used r_join and need to reinitialize states for it here.
gc_t_join.r_init();
}
//start all threads on the roots.
dprintf(3, ("Starting all gc thread for short weak handle scan"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
// 处理HNDTYPE_WEAK_SHORT类型的GC Handle
// 设置未被标记的对象的弱引用(Weak Reference)为null
// 这里传的GCHeap::Promote参数不会被用到
// 下面扫描完非关键析构队列还会扫描HNDTYPE_WEAK_LONG类型的GC Handle,请看下面的注释
// null out the target of short weakref that were not promoted.
GCScan::GcShortWeakPtrScan(GCHeap::Promote, condemned_gen_number, max_generation,&sc);
// MTHTS: keep by single thread
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Joining for finalization"));
gc_t_join.join(this, gc_join_scan_finalization);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
#ifdef MULTIPLE_HEAPS
//start all threads on the roots.
dprintf(3, ("Starting all gc thread for Finalization"));
gc_t_join.restart();
#endif //MULTIPLE_HEAPS
}
//Handle finalization.
size_t promoted_bytes_live = promoted_bytes (heap_number);
// 扫描当前非关键析构队列中对象的引用
#ifdef FEATURE_PREMORTEM_FINALIZATION
dprintf (3, ("Finalize marking"));
finalize_queue->ScanForFinalization (GCHeap::Promote, condemned_gen_number, mark_only_p, __this);
#ifdef GC_PROFILING
if (CORProfilerTrackGC())
{
finalize_queue->WalkFReachableObjects (__this);
}
#endif //GC_PROFILING
#endif // FEATURE_PREMORTEM_FINALIZATION
// 再扫一遍HNDTYPE_DEPENDENT类型的GC Handle
// Scan dependent handles again to promote any secondaries associated with primaries that were promoted
// for finalization. As before scan_dependent_handles will also process any mark stack overflow.
scan_dependent_handles(condemned_gen_number, &sc, false);
#ifdef MULTIPLE_HEAPS
dprintf(3, ("Joining for weak pointer deletion"));
gc_t_join.join(this, gc_join_null_dead_long_weak);
if (gc_t_join.joined())
{
//start all threads on the roots.
dprintf(3, ("Starting all gc thread for weak pointer deletion"));
gc_t_join.restart();
}
#endif //MULTIPLE_HEAPS
// 处理HNDTYPE_WEAK_LONG或HNDTYPE_REFCOUNTED类型的GC Handle
// 设置未被标记的对象的弱引用(Weak Reference)为null
// 这里传的GCHeap::Promote参数不会被用到
// HNDTYPE_WEAK_LONG和HNDTYPE_WEAK_SHORT的区别是,HNDTYPE_WEAK_SHORT会忽略从非关键析构队列的引用而HNDTYPE_WEAK_LONG不会
// null out the target of long weakref that were not promoted.
GCScan::GcWeakPtrScan (GCHeap::Promote, condemned_gen_number, max_generation, &sc);
// 如果使用了mark list并且并行化(服务器GC下)这里会进行排序(如果定义了PARALLEL_MARK_LIST_SORT)
// MTHTS: keep by single thread
#ifdef MULTIPLE_HEAPS
#ifdef MARK_LIST
#ifdef PARALLEL_MARK_LIST_SORT
// unsigned long start = GetCycleCount32();
sort_mark_list();
// printf("sort_mark_list took %u cycles\n", GetCycleCount32() - start);
#endif //PARALLEL_MARK_LIST_SORT
#endif //MARK_LIST
dprintf (3, ("Joining for sync block cache entry scanning"));
gc_t_join.join(this, gc_join_null_dead_syncblk);
if (gc_t_join.joined())
#endif //MULTIPLE_HEAPS
{
// 删除不再使用的同步索引块,并且设置对应对象的索引值为0
// scan for deleted entries in the syncblk cache
GCScan::GcWeakPtrScanBySingleThread (condemned_gen_number, max_generation, &sc);
#ifdef FEATURE_APPDOMAIN_RESOURCE_MONITORING
if (g_fEnableARM)
{
size_t promoted_all_heaps = 0;
#ifdef MULTIPLE_HEAPS
for (int i = 0; i < n_heaps; i++)
{
promoted_all_heaps += promoted_bytes (i);
}
#else
promoted_all_heaps = promoted_bytes (heap_number);
#endif //MULTIPLE_HEAPS
// 记录这次标记(存活)的字节数
SystemDomain::RecordTotalSurvivedBytes (promoted_all_heaps);
}
#endif //FEATURE_APPDOMAIN_RESOURCE_MONITORING
#ifdef MULTIPLE_HEAPS
// 以下是服务器GC下的处理
// 如果使用了mark list并且并行化(服务器GC下)这里会进行压缩并排序(如果不定义PARALLEL_MARK_LIST_SORT)
#ifdef MARK_LIST
#ifndef PARALLEL_MARK_LIST_SORT
//compact g_mark_list and sort it.
combine_mark_lists();
#endif //PARALLEL_MARK_LIST_SORT
#endif //MARK_LIST
// 如果之前未决定要升代,这里再给一次机会判断是否要升代
// 算法分析
// dd_min_gc_size是每分配多少byte的对象就触发gc的阈值
// 第0代1倍, 第1代2倍, 再乘以0.1合计
// dd = 上一代的动态数据
// older_gen_size = 上次gc后的对象大小合计 + 从上次gc以来一共新分配了多少byte
// 如果m > 上一代的大小, 或者本次标记的对象大小 > m则启用升代
// 意义是如果上一代过小,或者这次标记(存活)的对象过多则需要升代
//decide on promotion
if (!settings.promotion)
{
size_t m = 0;
for (int n = 0; n <= condemned_gen_number;n++)
{
m += (size_t)(dd_min_gc_size (dynamic_data_of (n))*(n+1)*0.1);
}
for (int i = 0; i < n_heaps; i++)
{
dynamic_data* dd = g_heaps[i]->dynamic_data_of (min (condemned_gen_number +1,
max_generation));
size_t older_gen_size = (dd_current_size (dd) +
(dd_desired_allocation (dd) -
dd_new_allocation (dd)));
if ((m > (older_gen_size)) ||
(promoted_bytes (i) > m))
{
settings.promotion = TRUE;
}
}
}
// scable marking的处理
#ifdef SNOOP_STATS
if (do_mark_steal_p)
{
size_t objects_checked_count = 0;
size_t zero_ref_count = 0;
size_t objects_marked_count = 0;
size_t check_level_count = 0;
size_t busy_count = 0;
size_t interlocked_count = 0;
size_t partial_mark_parent_count = 0;
size_t stolen_or_pm_count = 0;
size_t stolen_entry_count = 0;
size_t pm_not_ready_count = 0;
size_t normal_count = 0;
size_t stack_bottom_clear_count = 0;
for (int i = 0; i < n_heaps; i++)
{
gc_heap* hp = g_heaps[i];
hp->print_snoop_stat();
objects_checked_count += hp->snoop_stat.objects_checked_count;
zero_ref_count += hp->snoop_stat.zero_ref_count;
objects_marked_count += hp->snoop_stat.objects_marked_count;
check_level_count += hp->snoop_stat.check_level_count;
busy_count += hp->snoop_stat.busy_count;
interlocked_count += hp->snoop_stat.interlocked_count;
partial_mark_parent_count += hp->snoop_stat.partial_mark_parent_count;
stolen_or_pm_count += hp->snoop_stat.stolen_or_pm_count;
stolen_entry_count += hp->snoop_stat.stolen_entry_count;
pm_not_ready_count += hp->snoop_stat.pm_not_ready_count;
normal_count += hp->snoop_stat.normal_count;
stack_bottom_clear_count += hp->snoop_stat.stack_bottom_clear_count;
}
fflush (stdout);
printf ("-------total stats-------\n");
printf ("%8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s | %8s\n",
"checked", "zero", "marked", "level", "busy", "xchg", "pmparent", "s_pm", "stolen", "nready", "normal", "clear");
printf ("%8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d | %8d\n",
objects_checked_count,
zero_ref_count,
objects_marked_count,
check_level_count,
busy_count,
interlocked_count,
partial_mark_parent_count,
stolen_or_pm_count,
stolen_entry_count,
pm_not_ready_count,
normal_count,
stack_bottom_clear_count);
}
#endif //SNOOP_STATS
//start all threads.
dprintf(3, ("Starting all threads for end of mark phase"));
gc_t_join.restart();
#else //MULTIPLE_HEAPS
// 以下是工作站GC下的处理
// 如果之前未决定要升代,这里再给一次机会判断是否要升代
// 算法和前面一样,但是不是乘以0.1而是乘以0.06
//decide on promotion
if (!settings.promotion)
{
size_t m = 0;
for (int n = 0; n <= condemned_gen_number;n++)
{
m += (size_t)(dd_min_gc_size (dynamic_data_of (n))*(n+1)*0.06);
}
dynamic_data* dd = dynamic_data_of (min (condemned_gen_number +1,
max_generation));
size_t older_gen_size = (dd_current_size (dd) +
(dd_desired_allocation (dd) -
dd_new_allocation (dd)));
dprintf (2, ("promotion threshold: %Id, promoted bytes: %Id size n+1: %Id",
m, promoted_bytes (heap_number), older_gen_size));
if ((m > older_gen_size) ||
(promoted_bytes (heap_number) > m))
{
settings.promotion = TRUE;
}
}
#endif //MULTIPLE_HEAPS
}
// 如果使用了mark list并且并行化(服务器GC下)这里会进行归并(如果定义了PARALLEL_MARK_LIST_SORT)
#ifdef MULTIPLE_HEAPS
#ifdef MARK_LIST
#ifdef PARALLEL_MARK_LIST_SORT
// start = GetCycleCount32();
merge_mark_lists();
// printf("merge_mark_lists took %u cycles\n", GetCycleCount32() - start);
#endif //PARALLEL_MARK_LIST_SORT
#endif //MARK_LIST
#endif //MULTIPLE_HEAPS
// 统计标记的对象大小
#ifdef BACKGROUND_GC
total_promoted_bytes = promoted_bytes (heap_number);
#endif //BACKGROUND_GC
promoted_bytes (heap_number) -= promoted_bytes_live;
// 统计标记阶段的结束时间
#ifdef TIME_GC
finish = GetCycleCount32();
mark_time = finish - start;
#endif //TIME_GC
dprintf(2,("---- End of mark phase ----"));
}
接下来我们看下GCHeap::Promote函数,在plan_phase中扫描到的对象都会调用这个函数进行标记,
这个函数名称虽然叫Promote但是里面只负责对对象进行标记,被标记的对象不一定会升代
void GCHeap::Promote(Object** ppObject, ScanContext* sc, uint32_t flags)
{
THREAD_NUMBER_FROM_CONTEXT;
#ifndef MULTIPLE_HEAPS
const int thread = 0;
#endif //!MULTIPLE_HEAPS
uint8_t* o = (uint8_t*)*ppObject;
if (o == 0)
return;
#ifdef DEBUG_DestroyedHandleValue
// we can race with destroy handle during concurrent scan
if (o == (uint8_t*)DEBUG_DestroyedHandleValue)
return;
#endif //DEBUG_DestroyedHandleValue
HEAP_FROM_THREAD;
gc_heap* hp = gc_heap::heap_of (o);
dprintf (3, ("Promote %Ix", (size_t)o));
// 如果传入的o不一定是对象的开始地址,则需要重新找到o属于的对象
#ifdef INTERIOR_POINTERS
if (flags & GC_CALL_INTERIOR)
{
if ((o < hp->gc_low) || (o >= hp->gc_high))
{
return;
}
if ( (o = hp->find_object (o, hp->gc_low)) == 0)
{
return;
}
}
#endif //INTERIOR_POINTERS
// 启用conservative GC时有可能会对自由对象调用这个函数,这里需要额外判断
#ifdef FEATURE_CONSERVATIVE_GC
// For conservative GC, a value on stack may point to middle of a free object.
// In this case, we don't need to promote the pointer.
if (g_pConfig->GetGCConservative()
&& ((CObjectHeader*)o)->IsFree())
{
return;
}
#endif
// 验证对象是否可以标记,除错用
#ifdef _DEBUG
((CObjectHeader*)o)->ValidatePromote(sc, flags);
#else
UNREFERENCED_PARAMETER(sc);
#endif //_DEBUG
// 如果需要标记对象固定(pinned)则调用`pin_object`
// 请看上面对`PinObject`函数的描述
// `pin_object`函数会设置对象的同步索引块 |= 0x20000000
if (flags & GC_CALL_PINNED)
hp->pin_object (o, (uint8_t**) ppObject, hp->gc_low, hp->gc_high);
// 如果有特殊的设置则20次固定一次对象
#ifdef STRESS_PINNING
if ((++n_promote % 20) == 1)
hp->pin_object (o, (uint8_t**) ppObject, hp->gc_low, hp->gc_high);
#endif //STRESS_PINNING
#ifdef FEATURE_APPDOMAIN_RESOURCE_MONITORING
size_t promoted_size_begin = hp->promoted_bytes (thread);
#endif //FEATURE_APPDOMAIN_RESOURCE_MONITORING
// 如果对象在gc范围中则调用`mark_object_simple`
// 如果对象不在gc范围则会跳过,这也是前面提到的需要Card Table的原因
if ((o >= hp->gc_low) && (o < hp->gc_high))
{
hpt->mark_object_simple (&o THREAD_NUMBER_ARG);
}
// 记录标记的大小
#ifdef FEATURE_APPDOMAIN_RESOURCE_MONITORING
size_t promoted_size_end = hp->promoted_bytes (thread);
if (g_fEnableARM)
{
if (sc->pCurrentDomain)
{
sc->pCurrentDomain->RecordSurvivedBytes ((promoted_size_end - promoted_size_begin), thread);
}
}
#endif //FEATURE_APPDOMAIN_RESOURCE_MONITORING
STRESS_LOG_ROOT_PROMOTE(ppObject, o, o ? header(o)->GetMethodTable() : NULL);
}
再看下mark_object_simple函数
//this method assumes that *po is in the [low. high[ range
void
gc_heap::mark_object_simple (uint8_t** po THREAD_NUMBER_DCL)
{
uint8_t* o = *po;
#ifdef MULTIPLE_HEAPS
#else //MULTIPLE_HEAPS
const int thread = 0;
#endif //MULTIPLE_HEAPS
{
#ifdef SNOOP_STATS
snoop_stat.objects_checked_count++;
#endif //SNOOP_STATS
// gc_mark1会设置对象中指向Method Table的指针 |= 1
// 如果对象是第一次标记会返回true
if (gc_mark1 (o))
{
// 更新gc_heap的成员slow和shigh(已标记对象的最小和最大地址)
// 如果使用了mark list则把对象加到mark list中
m_boundary (o);
// 记录已标记的对象大小
size_t s = size (o);
promoted_bytes (thread) += s;
{
// 枚举对象o的所有成员,包括o自己
go_through_object_cl (method_table(o), o, s, poo,
{
uint8_t* oo = *poo;
// 如果成员在gc扫描范围中则标记该成员
if (gc_mark (oo, gc_low, gc_high))
{
// 如果使用了mark list则把对象加到mark list中
m_boundary (oo);
// 记录已标记的对象大小
size_t obj_size = size (oo);
promoted_bytes (thread) += obj_size;
// 如果成员下还包含其他可以收集的成员,需要进一步标记
// 因为引用的层数可能很多导致爆栈,mark_object_simple1会使用mark_stack_array循环标记对象而不是用递归
if (contain_pointers_or_collectible (oo))
mark_object_simple1 (oo, oo THREAD_NUMBER_ARG);
}
}
);
}
}
}
}
经过标记阶段以后,在堆中存活的对象都被设置了marked标记,如果对象是固定的还会被设置pinned标记
接下来是计划阶段plan_phase:
计划阶段(plan_phase)
在这个阶段首先会模拟压缩和构建Brick Table,在模拟完成后判断是否应该进行实际的压缩,
如果进行实际的压缩则进入重定位阶段(relocate_phase)和压缩阶段(compact_phase),否则进入清扫阶段(sweep_phase),
在继续看代码之前我们需要先了解计划阶段如何模拟压缩和什么是Brick Table。
计划阶段如何模拟压缩
计划阶段首先会根据相邻的已标记的对象创建plug,用于加快处理速度和减少需要的内存空间,我们假定一段内存中的对象如下图

计划阶段会为这一段对象创建2个unpinned plug和一个pinned plug:

第一个plug是unpinned plug,包含了对象B, C,不固定地址
第二个plug是pinned plug,包含了对象E, F, G,固定地址
第三个plug是unpinned plug,包含了对象H,不固定地址
各个plug的信息保存在开始地址之前的一段内存中,结构如下
struct plug_and_gap
{
// 在这个plug之前有多少空间是未被标记(可回收)的
ptrdiff_t gap;
// 压缩这个plug中的对象时需要移动的偏移值,一般是负数
ptrdiff_t reloc;
union
{
// 左边节点和右边节点
pair m_pair;
int lr; //for clearing the entire pair in one instruction
};
// 填充对象(防止覆盖同步索引块)
plug m_plug;
};
眼尖的会发现上面的图有两个问题
- 对象G不是pinned但是也被归到pinned plug里了
- 这是因为pinned plug会把下一个对象也拉进来防止pinned object的末尾被覆盖,具体请看下面的代码
- 第三个plug把对象G的结尾给覆盖(破坏)了
- 对于这种情况原来的内容会备份到
saved_post_plug中,具体请看下面的代码
- 对于这种情况原来的内容会备份到
多个plug会构建成一棵树,例如上面的三个plug会构建成这样的树:
第一个plug: { gap: 24, reloc: 未定义, m_pair: { left: 0, right: 0 } }
第二个plug: { gap: 132, reloc: 0, m_pair: { left: -356, right: 206 } }
第三个plug: { gap: 24, reloc: 未定义, m_pair: { left: 0, right 0 } }
第二个plug的left和right保存的是离子节点plug的偏移值,
第三个plug的gap比较特殊,可能你们会觉得应该是0但是会被设置为24(sizeof(gap_reloc_pair)),这个大小在实际复制第二个plug(compact_plug)的时候会加回来。
当计划阶段找到一个plug的开始时,
如果这个plug是pinned plug则加到mark_stack_array队列中。
当计划阶段找到一个plug的结尾时,
如果这个plug是pinned plug则设置这个plug的大小并移动队列顶部(mark_stack_tos),
否则使用使用函数allocate_in_condemned_generations计算把这个plug移动到前面(压缩)时的偏移值,
allocate_in_condemned_generations的原理请看下图
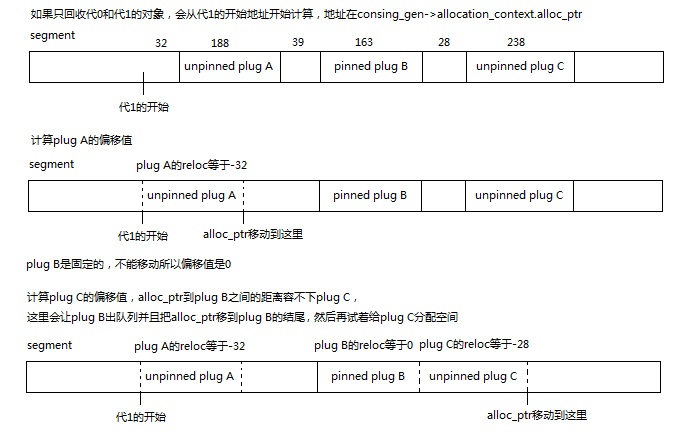
函数allocate_in_condemned_generations不会实际的移动内存和修改指针,它只设置了plug的reloc成员,
这里需要注意的是如果有pinned plug并且前面的空间不够,会从pinned plug的结尾开始计算,
同时出队列以后的plug B在mark_stack_array中的len会被设置为前面一段空间的大小,也就是32+39=71。
现在让我们思考一个问题,如果我们遇到一个对象x,如何求出对象x应该移动到的位置?

我们需要根据对象x找到它所在的plug,然后根据这个plug的reloc移动,查找plug使用的索引就是接下来要说的Brick Table。
Brick Table
brick_table是一个类型为short*的数组,用于快速索引plug,如图
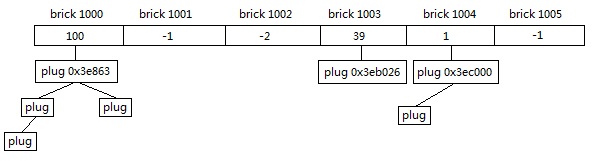
根据所属的brick不同,会构建多个plug树(避免plug树过大),然后设置根节点的信息到brick_table中,
brick中的值如果是正值则表示brick对应的开始地址离根节点plug的偏移值+1,
如果是负值则表示plug树横跨了多个brick,需要到前面的brick查找。
brick_table相关的代码如下,我们可以看到在64位下brick的大小是4096,在32位下brick的大小是2048
#if defined (_TARGET_AMD64_)
#define brick_size ((size_t)4096)
#else
#define brick_size ((size_t)2048)
#endif //_TARGET_AMD64_
inline
size_t gc_heap::brick_of (uint8_t* add)
{
return (size_t)(add - lowest_address) / brick_size;
}
inline
uint8_t* gc_heap::brick_address (size_t brick)
{
return lowest_address + (brick_size * brick);
}
void gc_heap::clear_brick_table (uint8_t* from, uint8_t* end)
{
for (size_t i = brick_of (from);i < brick_of (end); i++)
brick_table[i] = 0;
}
//codes for the brick entries:
//entry == 0 -> not assigned
//entry >0 offset is entry-1
//entry <0 jump back entry bricks
inline
void gc_heap::set_brick (size_t index, ptrdiff_t val)
{
if (val < -32767)
{
val = -32767;
}
assert (val < 32767);
if (val >= 0)
brick_table [index] = (short)val+1;
else
brick_table [index] = (short)val;
}
inline
int gc_heap::brick_entry (size_t index)
{
int val = brick_table [index];
if (val == 0)
{
return -32768;
}
else if (val < 0)
{
return val;
}
else
return val-1;
}
brick_table中出现负值的情况是因为plug横跨幅度比较大,超过了单个brick的时候后面的brick就会设为负值,
如果对象地址在上图的1001或1002,查找这个对象对应的plug会从1000的plug树开始。
另外1002中的值不一定需要是-2,-1也是有效的,如果是-1会一直向前查找直到找到正值的brick。
在上面我们提到的问题可以通过brick_table解决,可以看下面relocate_address函数的代码。brick_table在gc过程中会储存plug树,但是在gc完成后(gc不执行时)会储存各个brick中地址最大的plug,用于给find_first_object等函数定位对象的开始地址使用。
对于Pinned Plug的特殊处理
pinned plug除了会在plug树和brick table中,还会保存在mark_stack_array队列中,类型是mark。
因为unpinned plug和pinned plug相邻会导致原来的内容被plug信息覆盖,mark中还会保存以下的特殊信息
- saved_pre_plug
- 如果这个pinned plug覆盖了上一个unpinned plug的结尾,这里会保存覆盖前的原始内容
- saved_pre_plug_reloc
- 同上,但是这个值用于重定位和压缩阶段(中间会交换)
- saved_post_plug
- 如果这个pinned plug被下一个unpinned plug覆盖了结尾,这里会保存覆盖前的原始内容
- saved_post_plug_reloc
- 同上,但是这个值用于重定位和压缩阶段(中间会交换)
- saved_pre_plug_info_reloc_start
- 被覆盖的saved_pre_plug内容在重定位后的地址,如果重定位未发生则可以直接用(first - sizeof (plug_and_gap))
- saved_post_plug_info_start
- 被覆盖的saved_post_plug内容的地址,注意pinned plug不会被重定位
- saved_pre_p
- 是否保存了saved_pre_plug
- 如果覆盖的内容包含了对象的开头(对象比较小,整个都被覆盖了)
- 这里还会保存对象离各个引用成员的偏移值的bitmap (enque_pinned_plug)
- saved_post_p
- 是否保存了saved_post_p
- 如果覆盖的内容包含了对象的开头(对象比较小,整个都被覆盖了)
- 这里还会保存对象离各个引用成员的偏移值的bitmap (save_post_plug_info)
mark_stack_array中的len意义会在入队和出队时有所改变,
入队时len代表pinned plug的大小,
出队后len代表pinned plug离最后的模拟压缩分配地址的空间(这个空间可以变成free object)。
mark_stack_array
mark_stack_array的结构如下图:

入队时mark_stack_tos增加,出队时mark_stack_bos增加,空间不够时会扩展然后mark_stack_array_length会增加。
计划阶段判断使用压缩(compact)还是清扫(sweep)的依据是什么
计划阶段模拟压缩的时候创建plug,设置reloc等等只是为了接下来的压缩做准备,既不会修改指针地址也不会移动内存。
在做完这些工作之后计划阶段会首先判断应不应该进行压缩,如果不进行压缩而是进行清扫,这些计算结果都会浪费掉。
判断是否使用压缩的根据主要有
- 系统空余空闲是否过少,如果过少触发swap可能会明显的拖低性能,这时候应该尝试压缩
- 碎片空间大小(fragmentation) >= 阈值(dd_fragmentation_limit)
- 碎片空间大小(fragmentation) / 收集代的大小(包括更年轻的代) >= 阈值(dd_fragmentation_burden_limit)
其他还有一些零碎的判断,将在下面的decide_on_compacting函数的代码中讲解。
对象的升代与降代
在很多介绍.Net GC的书籍中都有提到过,经过GC以后对象会升代,例如gen 0中的对象在一次GC后如果存活下来会变为gen 1。
在CoreCLR中,对象的升代需要满足一定条件,某些特殊情况下不会升代,甚至会降代(gen1变为gen0)。
对象升代的条件如下:
- 计划阶段(plan_phase)选择清扫(sweep)时会启用升代
- 入口点(garbage_collect)判断当前是Full GC时会启用升代
dt_low_card_table_efficiency_p成立时会启用升代- 请在前面查找
dt_low_card_table_efficiency_p查看该处的解释
- 请在前面查找
- 计划阶段(plan_phase)判断上一代过小,或者这次标记(存活)的对象过多时启用升代
- 请在后面查找
promoted_bytes (i) > m查看该处的解释
- 请在后面查找
如果升代的条件不满足,则原来在gen 0的对象GC后仍然会在gen 0,
某些特殊条件下还会发生降代,如下图:
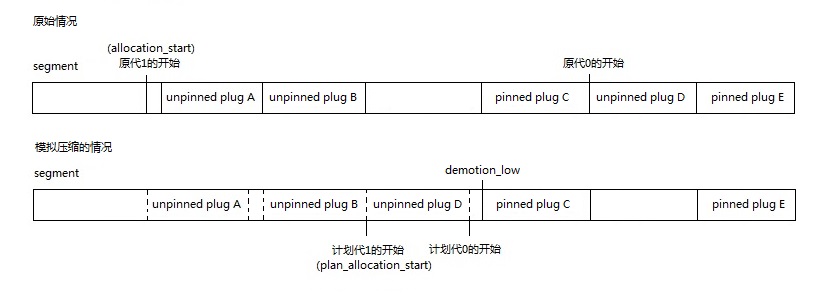
在模拟压缩时,原来在gen 1的对象会归到gen 2(pinned object不一定),原来在gen 0的对象会归到gen 1,
但是如果所有unpinned plug都已经压缩到前面,后面还有残留的pinned plug时,后面残留的pinned plug中的对象则会不升代或者降代,
当这种情况发生时计划阶段会设置demotion_low来标记被降代的范围。
如果最终选择了清扫(sweep)则上图中的情况不会发生。
计划代边界
计划阶段在模拟压缩的时候还会计划代边界(generation::plan_allocation_start),
计划代边界的工作主要在process_ephemeral_boundaries, plan_generation_start, plan_generation_starts函数中完成。
大部分情况下函数process_ephemeral_boundaries会用来计划gen 1的边界,如果不升代这个函数还会计划gen 0的边界,
当判断当前计划的plug大于或等于下一代的边界时,例如大于等于gen 0的边界时则会设置gen 1的边界在这个plug的前面。
最终选择压缩(compact)时,会把新的代边界设置成计划代边界(请看fix_generation_bounds函数),
最终选择清扫(sweep)时,计划代边界不会被使用(请看make_free_lists函数和make_free_list_in_brick函数)。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 125
- 统信桌面专业版【全盘安装UOS系统】介绍 120
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 111
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
