Golang源码探索(三) GC的实现原理(一)
基础概念
内存结构
go在程序启动时会分配一块虚拟内存地址是连续的内存, 结构如下:

这一块内存分为了3个区域, 在X64上大小分别是512M, 16G和512G, 它们的作用如下:
arena
arena区域就是我们通常说的heap, go从heap分配的内存都在这个区域中.
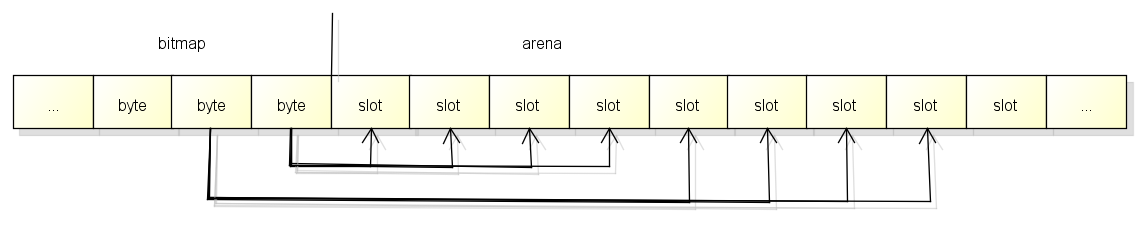
bitmap
bitmap区域用于表示arena区域中哪些地址保存了对象, 并且对象中哪些地址包含了指针.
bitmap区域中一个byte(8 bit)对应了arena区域中的四个指针大小的内存, 也就是2 bit对应一个指针大小的内存.
所以bitmap区域的大小是 512GB / 指针大小(8 byte) / 4 = 16GB.
bitmap区域中的一个byte对应arena区域的四个指针大小的内存的结构如下,
每一个指针大小的内存都会有两个bit分别表示是否应该继续扫描和是否包含指针:
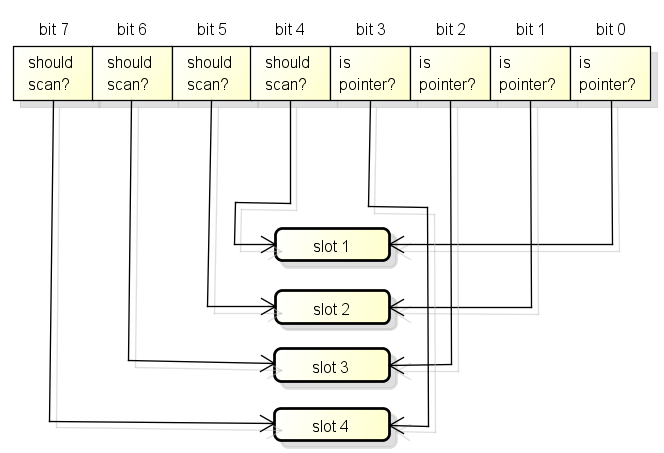
bitmap中的byte和arena的对应关系从末尾开始, 也就是随着内存分配会向两边扩展:
spans
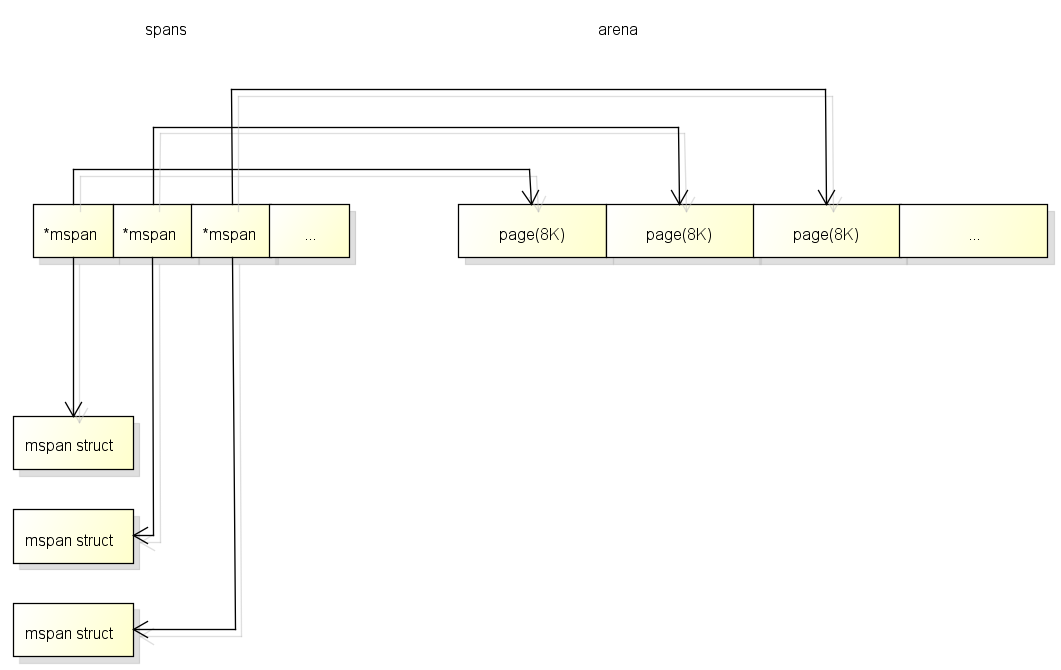
spans区域用于表示arena区中的某一页(Page)属于哪个span, 什么是span将在下面介绍.
spans区域中一个指针(8 byte)对应了arena区域中的一页(在go中一页=8KB).
所以spans的大小是 512GB / 页大小(8KB) * 指针大小(8 byte) = 512MB.
spans区域的一个指针对应arena区域的一页的结构如下, 和bitmap不一样的是对应关系会从开头开始:
什么时候从Heap分配对象
很多讲解go的文章和书籍中都提到过, go会自动确定哪些对象应该放在栈上, 哪些对象应该放在堆上.
简单的来说, 当一个对象的内容可能在生成该对象的函数结束后被访问, 那么这个对象就会分配在堆上.
在堆上分配对象的情况包括:
- 返回对象的指针
- 传递了对象的指针到其他函数
- 在闭包中使用了对象并且需要修改对象
- 使用new
在C语言中函数返回在栈上的对象的指针是非常危险的事情, 但在go中却是安全的, 因为这个对象会自动在堆上分配.
go决定是否使用堆分配对象的过程也叫"逃逸分析".
GC Bitmap
GC在标记时需要知道哪些地方包含了指针, 例如上面提到的bitmap区域涵盖了arena区域中的指针信息.
除此之外, GC还需要知道栈空间上哪些地方包含了指针,
因为栈空间不属于arena区域, 栈空间的指针信息将会在函数信息里面.
另外, GC在分配对象时也需要根据对象的类型设置bitmap区域, 来源的指针信息将会在类型信息里面.
总结起来go中有以下的GC Bitmap:
- bitmap区域: 涵盖了arena区域, 使用2 bit表示一个指针大小的内存
- 函数信息: 涵盖了函数的栈空间, 使用1 bit表示一个指针大小的内存 (位于stackmap.bytedata)
- 类型信息: 在分配对象时会复制到bitmap区域, 使用1 bit表示一个指针大小的内存 (位于_type.gcdata)
Span
span是用于分配对象的区块, 下图是简单说明了Span的内部结构:
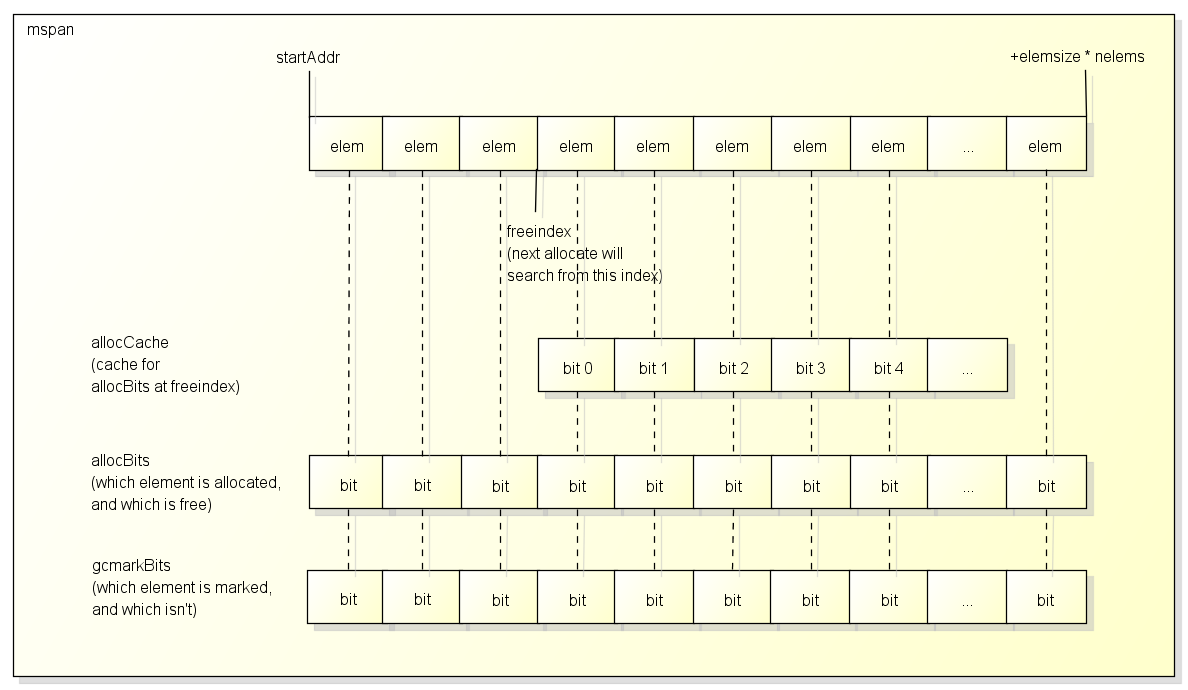
通常一个span包含了多个大小相同的元素, 一个元素会保存一个对象, 除非:
- span用于保存大对象, 这种情况span只有一个元素
- span用于保存极小对象且不包含指针的对象(tiny object), 这种情况span会用一个元素保存多个对象
span中有一个freeindex标记下一次分配对象时应该开始搜索的地址, 分配后freeindex会增加,
在freeindex之前的元素都是已分配的, 在freeindex之后的元素有可能已分配, 也有可能未分配.
span每次GC以后都可能会回收掉一些元素, allocBits用于标记哪些元素是已分配的, 哪些元素是未分配的.
使用freeindex + allocBits可以在分配时跳过已分配的元素, 把对象设置在未分配的元素中,
但因为每次都去访问allocBits效率会比较慢, span中有一个整数型的allocCache用于缓存freeindex开始的bitmap, 缓存的bit值与原值相反.
gcmarkBits用于在gc时标记哪些对象存活, 每次gc以后gcmarkBits会变为allocBits.
需要注意的是span结构本身的内存是从系统分配的, 上面提到的spans区域和bitmap区域都只是一个索引.
Span的类型
span根据大小可以分为67个类型, 如下:
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
// 5 64 8192 128 0 23.44%
// 6 80 8192 102 32 19.07%
// 7 96 8192 85 32 15.95%
// 8 112 8192 73 16 13.56%
// 9 128 8192 64 0 11.72%
// 10 144 8192 56 128 11.82%
// 11 160 8192 51 32 9.73%
// 12 176 8192 46 96 9.59%
// 13 192 8192 42 128 9.25%
// 14 208 8192 39 80 8.12%
// 15 224 8192 36 128 8.15%
// 16 240 8192 34 32 6.62%
// 17 256 8192 32 0 5.86%
// 18 288 8192 28 128 12.16%
// 19 320 8192 25 192 11.80%
// 20 352 8192 23 96 9.88%
// 21 384 8192 21 128 9.51%
// 22 416 8192 19 288 10.71%
// 23 448 8192 18 128 8.37%
// 24 480 8192 17 32 6.82%
// 25 512 8192 16 0 6.05%
// 26 576 8192 14 128 12.33%
// 27 640 8192 12 512 15.48%
// 28 704 8192 11 448 13.93%
// 29 768 8192 10 512 13.94%
// 30 896 8192 9 128 15.52%
// 31 1024 8192 8 0 12.40%
// 32 1152 8192 7 128 12.41%
// 33 1280 8192 6 512 15.55%
// 34 1408 16384 11 896 14.00%
// 35 1536 8192 5 512 14.00%
// 36 1792 16384 9 256 15.57%
// 37 2048 8192 4 0 12.45%
// 38 2304 16384 7 256 12.46%
// 39 2688 8192 3 128 15.59%
// 40 3072 24576 8 0 12.47%
// 41 3200 16384 5 384 6.22%
// 42 3456 24576 7 384 8.83%
// 43 4096 8192 2 0 15.60%
// 44 4864 24576 5 256 16.65%
// 45 5376 16384 3 256 10.92%
// 46 6144 24576 4 0 12.48%
// 47 6528 32768 5 128 6.23%
// 48 6784 40960 6 256 4.36%
// 49 6912 49152 7 768 3.37%
// 50 8192 8192 1 0 15.61%
// 51 9472 57344 6 512 14.28%
// 52 9728 49152 5 512 3.64%
// 53 10240 40960 4 0 4.99%
// 54 10880 32768 3 128 6.24%
// 55 12288 24576 2 0 11.45%
// 56 13568 40960 3 256 9.99%
// 57 14336 57344 4 0 5.35%
// 58 16384 16384 1 0 12.49%
// 59 18432 73728 4 0 11.11%
// 60 19072 57344 3 128 3.57%
// 61 20480 40960 2 0 6.87%
// 62 21760 65536 3 256 6.25%
// 63 24576 24576 1 0 11.45%
// 64 27264 81920 3 128 10.00%
// 65 28672 57344 2 0 4.91%
// 66 32768 32768 1 0 12.50%
以类型(class)为1的span为例,
span中的元素大小是8 byte, span本身占1页也就是8K, 一共可以保存1024个对象.
在分配对象时, 会根据对象的大小决定使用什么类型的span,
例如16 byte的对象会使用span 2, 17 byte的对象会使用span 3, 32 byte的对象会使用span 3.
从这个例子也可以看到, 分配17和32 byte的对象都会使用span 3, 也就是说部分大小的对象在分配时会浪费一定的空间.
有人可能会注意到, 上面最大的span的元素大小是32K, 那么分配超过32K的对象会在哪里分配呢?
超过32K的对象称为"大对象", 分配大对象时, 会直接从heap分配一个特殊的span,
这个特殊的span的类型(class)是0, 只包含了一个大对象, span的大小由对象的大小决定.
特殊的span加上的66个标准的span, 一共组成了67个span类型.
Span的位置
在前一篇中我提到了P是一个虚拟的资源, 同一时间只能有一个线程访问同一个P, 所以P中的数据不需要锁.
为了分配对象时有更好的性能, 各个P中都有span的缓存(也叫mcache), 缓存的结构如下:
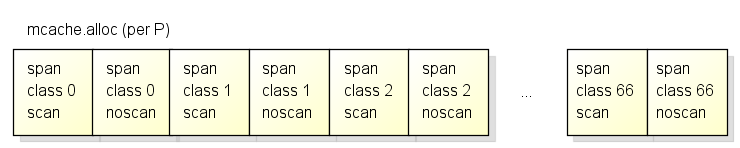
各个P中按span类型的不同, 有67*2=134个span的缓存,
其中scan和noscan的区别在于,
如果对象包含了指针, 分配对象时会使用scan的span,
如果对象不包含指针, 分配对象时会使用noscan的span.
把span分为scan和noscan的意义在于,
GC扫描对象的时候对于noscan的span可以不去查看bitmap区域来标记子对象, 这样可以大幅提升标记的效率.
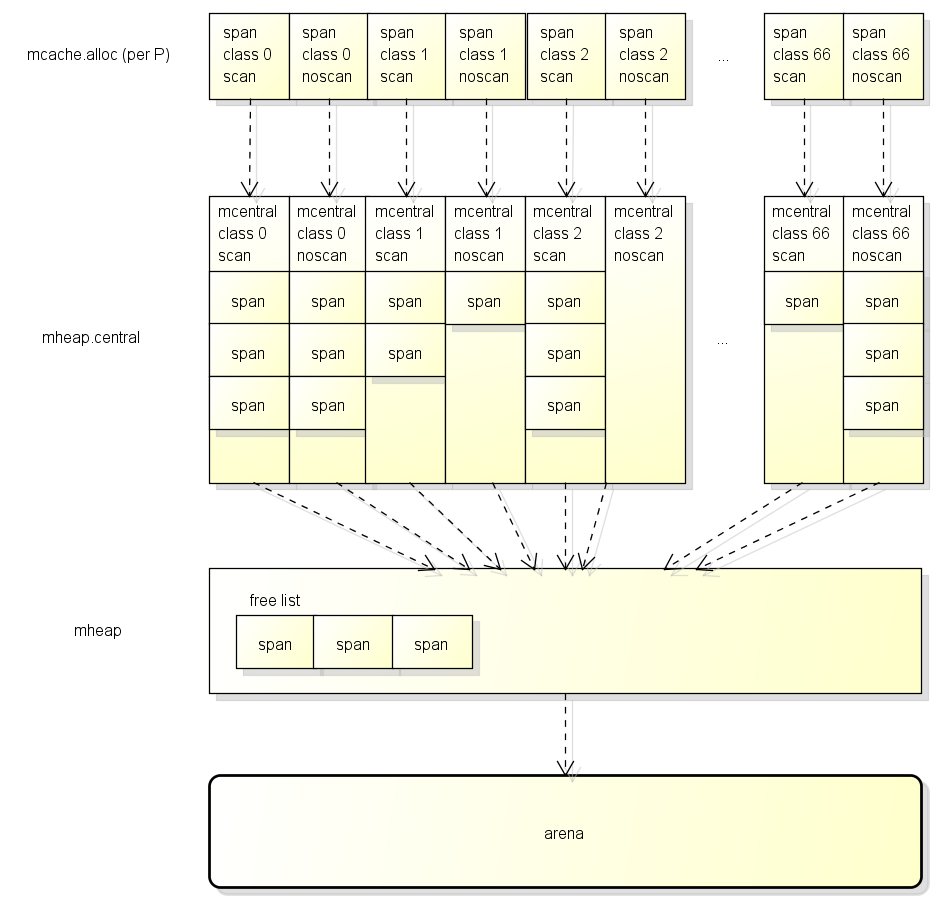
在分配对象时将会从以下的位置获取适合的span用于分配:
- 首先从P的缓存(mcache)获取, 如果有缓存的span并且未满则使用, 这个步骤不需要锁
- 然后从全局缓存(mcentral)获取, 如果获取成功则设置到P, 这个步骤需要锁
- 最后从mheap获取, 获取后设置到全局缓存, 这个步骤需要锁
在P中缓存span的做法跟CoreCLR中线程缓存分配上下文(Allocation Context)的做法相似,
都可以让分配对象时大部分时候不需要线程锁, 改进分配的性能.
分配对象的处理
分配对象的流程
go从堆分配对象时会调用newobject函数, 这个函数的流程大致如下:
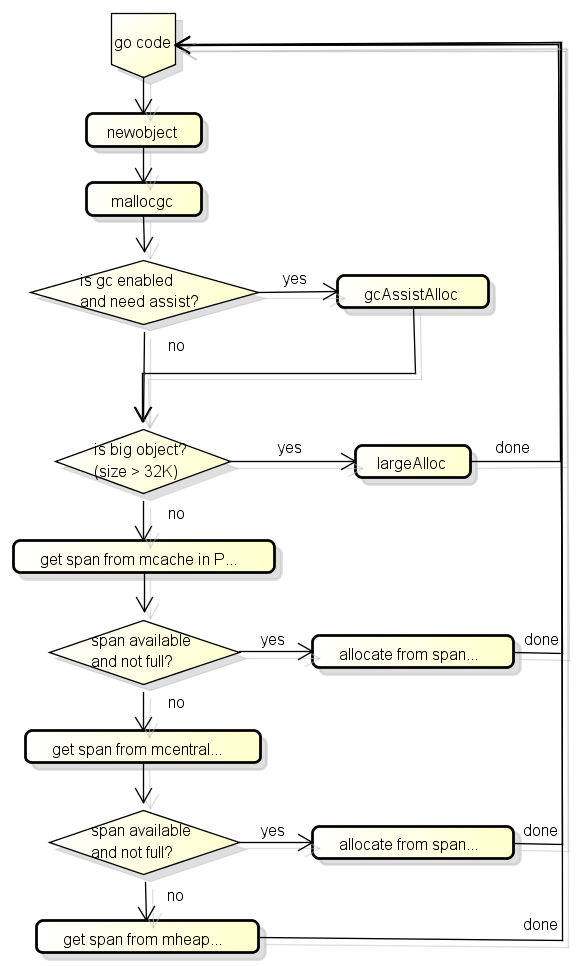
首先会检查GC是否在工作中, 如果GC在工作中并且当前的G分配了一定大小的内存则需要协助GC做一定的工作,
这个机制叫GC Assist, 用于防止分配内存太快导致GC回收跟不上的情况发生.
之后会判断是小对象还是大对象, 如果是大对象则直接调用largeAlloc从堆中分配,
如果是小对象分3个阶段获取可用的span, 然后从span中分配对象:
- 首先从P的缓存(mcache)获取
- 然后从全局缓存(mcentral)获取, 全局缓存中有可用的span的列表
- 最后从mheap获取, mheap中也有span的自由列表, 如果都获取失败则从arena区域分配
这三个阶段的详细结构如下图:
数据类型的定义
分配对象涉及的数据类型包含:
p: 前一篇提到过, P是协程中的用于运行go代码的虚拟资源
m: 前一篇提到过, M目前代表系统线程
g: 前一篇提到过, G就是goroutine
mspan: 用于分配对象的区块
mcentral: 全局的mspan缓存, 一共有67*2=134个
mheap: 用于管理heap的对象, 全局只有一个
源代码分析
go从堆分配对象时会调用newobject函数, 先从这个函数看起:
// implementation of new builtin
// compiler (both frontend and SSA backend) knows the signature
// of this function
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
// Allocate an object of size bytes.
// Small objects are allocated from the per-P cache's free lists.
// Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
if size == 0 {
return unsafe.Pointer(&zerobase)
}
if debug.sbrk != 0 {
align := uintptr(16)
if typ != nil {
align = uintptr(typ.align)
}
return persistentalloc(size, align, &memstats.other_sys)
}
// 判断是否要辅助GC工作
// gcBlackenEnabled在GC的标记阶段会开启
// assistG is the G to charge for this allocation, or nil if
// GC is not currently active.
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
// 会按分配的大小判断需要协助GC完成多少工作
// 具体的算法将在下面讲解收集器时说明
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
// 增加当前G对应的M的lock计数, 防止这个G被抢占
// Set mp.mallocing to keep from being preempted by GC.
mp := acquirem()
if mp.mallocing != 0 {
throw("malloc deadlock")
}
if mp.gsignal == getg() {
throw("malloc during signal")
}
mp.mallocing = 1
shouldhelpgc := false
dataSize := size
// 获取当前G对应的M对应的P的本地span缓存(mcache)
// 因为M在拥有P后会把P的mcache设到M中, 这里返回的是getg().m.mcache
c := gomcache()
var x unsafe.Pointer
noscan := typ == nil || typ.kind&kindNoPointers != 0
// 判断是否小对象, maxSmallSize当前的值是32K
if size <= maxSmallSize {
// 如果对象不包含指针, 并且对象的大小小于16 bytes, 可以做特殊处理
// 这里是针对非常小的对象的优化, 因为span的元素最小只能是8 byte, 如果对象更小那么很多空间都会被浪费掉
// 非常小的对象可以整合在"class 2 noscan"的元素(大小为16 byte)中
if noscan && size < maxTinySize {
// Tiny allocator.
//
// Tiny allocator combines several tiny allocation requests
// into a single memory block. The resulting memory block
// is freed when all subobjects are unreachable. The subobjects
// must be noscan (don't have pointers), this ensures that
// the amount of potentially wasted memory is bounded.
//
// Size of the memory block used for combining (maxTinySize) is tunable.
// Current setting is 16 bytes, which relates to 2x worst case memory
// wastage (when all but one subobjects are unreachable).
// 8 bytes would result in no wastage at all, but provides less
// opportunities for combining.
// 32 bytes provides more opportunities for combining,
// but can lead to 4x worst case wastage.
// The best case winning is 8x regardless of block size.
//
// Objects obtained from tiny allocator must not be freed explicitly.
// So when an object will be freed explicitly, we ensure that
// its size >= maxTinySize.
//
// SetFinalizer has a special case for objects potentially coming
// from tiny allocator, it such case it allows to set finalizers
// for an inner byte of a memory block.
//
// The main targets of tiny allocator are small strings and
// standalone escaping variables. On a json benchmark
// the allocator reduces number of allocations by ~12% and
// reduces heap size by ~20%.
off := c.tinyoffset
// Align tiny pointer for required (conservative) alignment.
if size&7 == 0 {
off = round(off, 8)
} else if size&3 == 0 {
off = round(off, 4)
} else if size&1 == 0 {
off = round(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
// The object fits into existing tiny block.
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.local_tinyallocs++
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
span := c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, _, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// See if we need to replace the existing tiny block with the new one
// based on amount of remaining free space.
if size < c.tinyoffset || c.tiny == 0 {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
} else {
// 否则按普通的小对象分配
// 首先获取对象的大小应该使用哪个span类型
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
size = uintptr(class_to_size[sizeclass])
// 等于sizeclass * 2 + (noscan ? 1 : 0)
spc := makeSpanClass(sizeclass, noscan)
span := c.alloc[spc]
// 尝试快速的从这个span中分配
v := nextFreeFast(span)
if v == 0 {
// 分配失败, 可能需要从mcentral或者mheap中获取
// 如果从mcentral或者mheap获取了新的span, 则shouldhelpgc会等于true
// shouldhelpgc会等于true时会在下面判断是否要触发GC
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else {
// 大对象直接从mheap分配, 这里的s是一个特殊的span, 它的class是0
var s *mspan
shouldhelpgc = true
systemstack(func() {
s = largeAlloc(size, needzero, noscan)
})
s.freeindex = 1
s.allocCount = 1
x = unsafe.Pointer(s.base())
size = s.elemsize
}
// 设置arena对应的bitmap, 记录哪些位置包含了指针, GC会使用bitmap扫描所有可到达的对象
var scanSize uintptr
if !noscan {
// If allocating a defer+arg block, now that we've picked a malloc size
// large enough to hold everything, cut the "asked for" size down to
// just the defer header, so that the GC bitmap will record the arg block
// as containing nothing at all (as if it were unused space at the end of
// a malloc block caused by size rounding).
// The defer arg areas are scanned as part of scanstack.
if typ == deferType {
dataSize = unsafe.Sizeof(_defer{})
}
// 这个函数非常的长, 有兴趣的可以看
// https://github.com/golang/go/blob/go1.9.2/src/runtime/mbitmap.go#L855
// 虽然代码很长但是设置的内容跟上面说过的bitmap区域的结构一样
// 根据类型信息设置scan bit跟pointer bit, scan bit成立表示应该继续扫描, pointer bit成立表示该位置是指针
// 需要注意的地方有
// - 如果一个类型只有开头的地方包含指针, 例如[ptr, ptr, large non-pointer data]
// 那么后面的部分的scan bit将会为0, 这样可以大幅提升标记的效率
// - 第二个slot的scan bit用途比较特殊, 它并不用于标记是否继续scan, 而是标记checkmark
// 什么是checkmark
// - 因为go的并行GC比较复杂, 为了检查实现是否正确, go需要在有一个检查所有应该被标记的对象是否被标记的机制
// 这个机制就是checkmark, 在开启checkmark时go会在标记阶段的最后停止整个世界然后重新执行一次标记
// 上面的第二个slot的scan bit就是用于标记对象在checkmark标记中是否被标记的
// - 有的人可能会发现第二个slot要求对象最少有两个指针的大小, 那么只有一个指针的大小的对象呢?
// 只有一个指针的大小的对象可以分为两种情况
// 对象就是指针, 因为大小刚好是1个指针所以并不需要看bitmap区域, 这时第一个slot就是checkmark
// 对象不是指针, 因为有tiny alloc的机制, 不是指针且只有一个指针大小的对象会分配在两个指针的span中
// 这时候也不需要看bitmap区域, 所以和上面一样第一个slot就是checkmark
heapBitsSetType(uintptr(x), size, dataSize, typ)
if dataSize > typ.size {
// Array allocation. If there are any
// pointers, GC has to scan to the last
// element.
if typ.ptrdata != 0 {
scanSize = dataSize - typ.size + typ.ptrdata
}
} else {
scanSize = typ.ptrdata
}
c.local_scan += scanSize
}
// 内存屏障, 因为x86和x64的store不会乱序所以这里只是个针对编译器的屏障, 汇编中是ret
// Ensure that the stores above that initialize x to
// type-safe memory and set the heap bits occur before
// the caller can make x observable to the garbage
// collector. Otherwise, on weakly ordered machines,
// the garbage collector could follow a pointer to x,
// but see uninitialized memory or stale heap bits.
publicationBarrier()
// 如果当前在GC中, 需要立刻标记分配后的对象为"黑色", 防止它被回收
// Allocate black during GC.
// All slots hold nil so no scanning is needed.
// This may be racing with GC so do it atomically if there can be
// a race marking the bit.
if gcphase != _GCoff {
gcmarknewobject(uintptr(x), size, scanSize)
}
// Race Detector的处理(用于检测线程冲突问题)
if raceenabled {
racemalloc(x, size)
}
// Memory Sanitizer的处理(用于检测危险指针等内存问题)
if msanenabled {
msanmalloc(x, size)
}
// 重新允许当前的G被抢占
mp.mallocing = 0
releasem(mp)
// 除错记录
if debug.allocfreetrace != 0 {
tracealloc(x, size, typ)
}
// Profiler记录
if rate := MemProfileRate; rate > 0 {
if size < uintptr(rate) && int32(size) < c.next_sample {
c.next_sample -= int32(size)
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
// gcAssistBytes减去"实际分配大小 - 要求分配大小", 调整到准确值
if assistG != nil {
// Account for internal fragmentation in the assist
// debt now that we know it.
assistG.gcAssistBytes -= int64(size - dataSize)
}
// 如果之前获取了新的span, 则判断是否需要后台启动GC
// 这里的判断逻辑(gcTrigger)会在下面详细说明
if shouldhelpgc {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(gcBackgroundMode, t)
}
}
return x
}
接下来看看如何从span里面分配对象, 首先会调用nextFreeFast尝试快速分配:
// nextFreeFast returns the next free object if one is quickly available.
// Otherwise it returns 0.
func nextFreeFast(s *mspan) gclinkptr {
// 获取第一个非0的bit是第几个bit, 也就是哪个元素是未分配的
theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?
// 找到未分配的元素
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
// 要求索引值小于元素数量
if result < s.nelems {
// 下一个freeindex
freeidx := result + 1
// 可以被64整除时需要特殊处理(参考nextFree)
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
// 更新freeindex和allocCache(高位都是0, 用尽以后会更新)
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
// 返回元素所在的地址
v := gclinkptr(result*s.elemsize + s.base())
// 添加已分配的元素计数
s.allocCount++
return v
}
}
return 0
}
如果在freeindex后无法快速找到未分配的元素, 就需要调用nextFree做出更复杂的处理:
// nextFree returns the next free object from the cached span if one is available.
// Otherwise it refills the cache with a span with an available object and
// returns that object along with a flag indicating that this was a heavy
// weight allocation. If it is a heavy weight allocation the caller must
// determine whether a new GC cycle needs to be started or if the GC is active
// whether this goroutine needs to assist the GC.
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
// 找到下一个freeindex和更新allocCache
s = c.alloc[spc]
shouldhelpgc = false
freeIndex := s.nextFreeIndex()
// 如果span里面所有元素都已分配, 则需要获取新的span
if freeIndex == s.nelems {
// The span is full.
if uintptr(s.allocCount) != s.nelems {
println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount != s.nelems && freeIndex == s.nelems")
}
// 申请新的span
systemstack(func() {
c.refill(spc)
})
// 获取申请后的新的span, 并设置需要检查是否执行GC
shouldhelpgc = true
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
// 返回元素所在的地址
v = gclinkptr(freeIndex*s.elemsize + s.base())
// 添加已分配的元素计数
s.allocCount++
if uintptr(s.allocCount) > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
return
}
如果mcache中指定类型的span已满, 就需要调用refill函数申请新的span:
// Gets a span that has a free object in it and assigns it
// to be the cached span for the given sizeclass. Returns this span.
func (c *mcache) refill(spc spanClass) *mspan {
_g_ := getg()
// 防止G被抢占
_g_.m.locks++
// Return the current cached span to the central lists.
s := c.alloc[spc]
// 确保当前的span所有元素都已分配
if uintptr(s.allocCount) != s.nelems {
throw("refill of span with free space remaining")
}
// 设置span的incache属性, 除非是全局使用的空span(也就是mcache里面span指针的默认值)
if s != &emptymspan {
s.incache = false
}
// 向mcentral申请一个新的span
// Get a new cached span from the central lists.
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
if uintptr(s.allocCount) == s.nelems {
throw("span has no free space")
}
// 设置新的span到mcache中
c.alloc[spc] = s
// 允许G被抢占
_g_.m.locks--
return s
}
向mcentral申请一个新的span会通过cacheSpan函数:
mcentral首先尝试从内部的链表复用原有的span, 如果复用失败则向mheap申请.
// Allocate a span to use in an MCache.
func (c *mcentral) cacheSpan() *mspan {
// 让当前G协助一部分的sweep工作
// Deduct credit for this span allocation and sweep if necessary.
spanBytes := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) * _PageSize
deductSweepCredit(spanBytes, 0)
// 对mcentral上锁, 因为可能会有多个M(P)同时访问
lock(&c.lock)
traceDone := false
if trace.enabled {
traceGCSweepStart()
}
sg := mheap_.sweepgen
retry:
// mcentral里面有两个span的链表
// - nonempty表示确定该span最少有一个未分配的元素
// - empty表示不确定该span最少有一个未分配的元素
// 这里优先查找nonempty的链表
// sweepgen每次GC都会增加2
// - sweepgen == 全局sweepgen, 表示span已经sweep过
// - sweepgen == 全局sweepgen-1, 表示span正在sweep
// - sweepgen == 全局sweepgen-2, 表示span等待sweep
var s *mspan
for s = c.nonempty.first; s != nil; s = s.next {
// 如果span等待sweep, 尝试原子修改sweepgen为全局sweepgen-1
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
// 修改成功则把span移到empty链表, sweep它然后跳到havespan
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
s.sweep(true)
goto havespan
}
// 如果这个span正在被其他线程sweep, 就跳过
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
// span已经sweep过
// 因为nonempty链表中的span确定最少有一个未分配的元素, 这里可以直接使用它
// we have a nonempty span that does not require sweeping, allocate from it
c.nonempty.remove(s)
c.empty.insertBack(s)
unlock(&c.lock)
goto havespan
}
// 查找empty的链表
for s = c.empty.first; s != nil; s = s.next {
// 如果span等待sweep, 尝试原子修改sweepgen为全局sweepgen-1
if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) {
// 把span放到empty链表的最后
// we have an empty span that requires sweeping,
// sweep it and see if we can free some space in it
c.empty.remove(s)
// swept spans are at the end of the list
c.empty.insertBack(s)
unlock(&c.lock)
// 尝试sweep
s.sweep(true)
// sweep以后还需要检测是否有未分配的对象, 如果有则可以使用它
freeIndex := s.nextFreeIndex()
if freeIndex != s.nelems {
s.freeindex = freeIndex
goto havespan
}
lock(&c.lock)
// the span is still empty after sweep
// it is already in the empty list, so just retry
goto retry
}
// 如果这个span正在被其他线程sweep, 就跳过
if s.sweepgen == sg-1 {
// the span is being swept by background sweeper, skip
continue
}
// 找不到有未分配对象的span
// already swept empty span,
// all subsequent ones must also be either swept or in process of sweeping
break
}
if trace.enabled {
traceGCSweepDone()
traceDone = true
}
unlock(&c.lock)
// 找不到有未分配对象的span, 需要从mheap分配
// 分配完成后加到empty链表中
// Replenish central list if empty.
s = c.grow()
if s == nil {
return nil
}
lock(&c.lock)
c.empty.insertBack(s)
unlock(&c.lock)
// At this point s is a non-empty span, queued at the end of the empty list,
// c is unlocked.
havespan:
if trace.enabled && !traceDone {
traceGCSweepDone()
}
// 统计span中未分配的元素数量, 加到mcentral.nmalloc中
// 统计span中未分配的元素总大小, 加到memstats.heap_live中
cap := int32((s.npages << _PageShift) / s.elemsize)
n := cap - int32(s.allocCount)
if n == 0 || s.freeindex == s.nelems || uintptr(s.allocCount) == s.nelems {
throw("span has no free objects")
}
// Assume all objects from this span will be allocated in the
// mcache. If it gets uncached, we'll adjust this.
atomic.Xadd64(&c.nmalloc, int64(n))
usedBytes := uintptr(s.allocCount) * s.elemsize
atomic.Xadd64(&memstats.heap_live, int64(spanBytes)-int64(usedBytes))
// 跟踪处理
if trace.enabled {
// heap_live changed.
traceHeapAlloc()
}
// 如果当前在GC中, 因为heap_live改变了, 重新调整G辅助标记工作的值
// 详细请参考下面对revise函数的解析
if gcBlackenEnabled != 0 {
// heap_live changed.
gcController.revise()
}
// 设置span的incache属性, 表示span正在mcache中
s.incache = true
// 根据freeindex更新allocCache
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8
// Init alloc bits cache.
s.refillAllocCache(whichByte)
// Adjust the allocCache so that s.freeindex corresponds to the low bit in
// s.allocCache.
s.allocCache >>= s.freeindex % 64
return s
}
mcentral向mheap申请一个新的span会使用grow函数:
// grow allocates a new empty span from the heap and initializes it for c's size class.
func (c *mcentral) grow() *mspan {
// 根据mcentral的类型计算需要申请的span的大小(除以8K = 有多少页)和可以保存多少个元素
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
n := (npages << _PageShift) / size
// 向mheap申请一个新的span, 以页(8K)为单位
s := mheap_.alloc(npages, c.spanclass, false, true)
if s == nil {
return nil
}
p := s.base()
s.limit = p + size*n
// 分配并初始化span的allocBits和gcmarkBits
heapBitsForSpan(s.base()).initSpan(s)
return s
}
mheap分配span的函数是alloc:
func (h *mheap) alloc(npage uintptr, spanclass spanClass, large bool, needzero bool) *mspan {
// 在g0的栈空间中调用alloc_m函数
// 关于systemstack的说明请看前一篇文章
// Don't do any operations that lock the heap on the G stack.
// It might trigger stack growth, and the stack growth code needs
// to be able to allocate heap.
var s *mspan
systemstack(func() {
s = h.alloc_m(npage, spanclass, large)
})
if s != nil {
if needzero && s.needzero != 0 {
memclrNoHeapPointers(unsafe.Pointer(s.base()), s.npages<<_PageShift)
}
s.needzero = 0
}
return s
}
alloc函数会在g0的栈空间中调用alloc_m函数:
// Allocate a new span of npage pages from the heap for GC'd memory
// and record its size class in the HeapMap and HeapMapCache.
func (h *mheap) alloc_m(npage uintptr, spanclass spanClass, large bool) *mspan {
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("_mheap_alloc not on g0 stack")
}
// 对mheap上锁, 这里的锁是全局锁
lock(&h.lock)
// 为了防止heap增速太快, 在分配n页之前要先sweep和回收n页
// 会先枚举busy列表然后再枚举busyLarge列表进行sweep, 具体参考reclaim和reclaimList函数
// To prevent excessive heap growth, before allocating n pages
// we need to sweep and reclaim at least n pages.
if h.sweepdone == 0 {
// TODO(austin): This tends to sweep a large number of
// spans in order to find a few completely free spans
// (for example, in the garbage benchmark, this sweeps
// ~30x the number of pages its trying to allocate).
// If GC kept a bit for whether there were any marks
// in a span, we could release these free spans
// at the end of GC and eliminate this entirely.
if trace.enabled {
traceGCSweepStart()
}
h.reclaim(npage)
if trace.enabled {
traceGCSweepDone()
}
}
// 把mcache中的本地统计数据加到全局
// transfer stats from cache to global
memstats.heap_scan += uint64(_g_.m.mcache.local_scan)
_g_.m.mcache.local_scan = 0
memstats.tinyallocs += uint64(_g_.m.mcache.local_tinyallocs)
_g_.m.mcache.local_tinyallocs = 0
// 调用allocSpanLocked分配span, allocSpanLocked函数要求当前已经对mheap上锁
s := h.allocSpanLocked(npage, &memstats.heap_inuse)
if s != nil {
// Record span info, because gc needs to be
// able to map interior pointer to containing span.
// 设置span的sweepgen = 全局sweepgen
atomic.Store(&s.sweepgen, h.sweepgen)
// 放到全局span列表中, 这里的sweepSpans的长度是2
// sweepSpans[h.sweepgen/2%2]保存当前正在使用的span列表
// sweepSpans[1-h.sweepgen/2%2]保存等待sweep的span列表
// 因为每次gcsweepgen都会加2, 每次gc这两个列表都会交换
h.sweepSpans[h.sweepgen/2%2].push(s) // Add to swept in-use list.
// 初始化span成员
s.state = _MSpanInUse
s.allocCount = 0
s.spanclass = spanclass
if sizeclass := spanclass.sizeclass(); sizeclass == 0 {
s.elemsize = s.npages << _PageShift
s.divShift = 0
s.divMul = 0
s.divShift2 = 0
s.baseMask = 0
} else {
s.elemsize = uintptr(class_to_size[sizeclass])
m := &class_to_divmagic[sizeclass]
s.divShift = m.shift
s.divMul = m.mul
s.divShift2 = m.shift2
s.baseMask = m.baseMask
}
// update stats, sweep lists
h.pagesInUse += uint64(npage)
// 上面grow函数会传入true, 也就是通过grow调用到这里large会等于true
// 添加已分配的span到busy列表, 如果页数超过_MaxMHeapList(128页=8K*128=1M)则放到busylarge列表
if large {
memstats.heap_objects++
mheap_.largealloc += uint64(s.elemsize)
mheap_.nlargealloc++
atomic.Xadd64(&memstats.heap_live, int64(npage<<_PageShift))
// Swept spans are at the end of lists.
if s.npages < uintptr(len(h.busy)) {
h.busy[s.npages].insertBack(s)
} else {
h.busylarge.insertBack(s)
}
}
}
// 如果当前在GC中, 因为heap_live改变了, 重新调整G辅助标记工作的值
// 详细请参考下面对revise函数的解析
// heap_scan and heap_live were updated.
if gcBlackenEnabled != 0 {
gcController.revise()
}
// 跟踪处理
if trace.enabled {
traceHeapAlloc()
}
// h.spans is accessed concurrently without synchronization
// from other threads. Hence, there must be a store/store
// barrier here to ensure the writes to h.spans above happen
// before the caller can publish a pointer p to an object
// allocated from s. As soon as this happens, the garbage
// collector running on another processor could read p and
// look up s in h.spans. The unlock acts as the barrier to
// order these writes. On the read side, the data dependency
// between p and the index in h.spans orders the reads.
unlock(&h.lock)
return s
}
继续查看allocSpanLocked函数:
// Allocates a span of the given size. h must be locked.
// The returned span has been removed from the
// free list, but its state is still MSpanFree.
func (h *mheap) allocSpanLocked(npage uintptr, stat *uint64) *mspan {
var list *mSpanList
var s *mspan
// 尝试在mheap中的自由列表分配
// 页数小于_MaxMHeapList(128页=1M)的自由span都会在free列表中
// 页数大于_MaxMHeapList的自由span都会在freelarge列表中
// Try in fixed-size lists up to max.
for i := int(npage); i < len(h.free); i++ {
list = &h.free[i]
if !list.isEmpty() {
s = list.first
list.remove(s)
goto HaveSpan
}
}
// free列表找不到则查找freelarge列表
// 查找不到就向arena区域申请一个新的span加到freelarge中, 然后再查找freelarge列表
// Best fit in list of large spans.
s = h.allocLarge(npage) // allocLarge removed s from h.freelarge for us
if s == nil {
if !h.grow(npage) {
return nil
}
s = h.allocLarge(npage)
if s == nil {
return nil
}
}
HaveSpan:
// Mark span in use.
if s.state != _MSpanFree {
throw("MHeap_AllocLocked - MSpan not free")
}
if s.npages < npage {
throw("MHeap_AllocLocked - bad npages")
}
// 如果span有已释放(解除虚拟内存和物理内存关系)的页, 提醒这些页会被使用然后更新统计数据
if s.npreleased > 0 {
sysUsed(unsafe.Pointer(s.base()), s.npages<<_PageShift)
memstats.heap_released -= uint64(s.npreleased << _PageShift)
s.npreleased = 0
}
// 如果获取到的span页数比要求的页数多
// 分割剩余的页数到另一个span并且放到自由列表中
if s.npages > npage {
// Trim extra and put it back in the heap.
t := (*mspan)(h.spanalloc.alloc())
t.init(s.base()+npage<<_PageShift, s.npages-npage)
s.npages = npage
p := (t.base() - h.arena_start) >> _PageShift
if p > 0 {
h.spans[p-1] = s
}
h.spans[p] = t
h.spans[p+t.npages-1] = t
t.needzero = s.needzero
s.state = _MSpanManual // prevent coalescing with s
t.state = _MSpanManual
h.freeSpanLocked(t, false, false, s.unusedsince)
s.state = _MSpanFree
}
s.unusedsince = 0
// 设置spans区域, 哪些地址对应哪个mspan对象
p := (s.base() - h.arena_start) >> _PageShift
for n := uintptr(0); n < npage; n++ {
h.spans[p+n] = s
}
// 更新统计数据
*stat += uint64(npage << _PageShift)
memstats.heap_idle -= uint64(npage << _PageShift)
//println("spanalloc", hex(s.start<<_PageShift))
if s.inList() {
throw("still in list")
}
return s
}
继续查看allocLarge函数:
// allocLarge allocates a span of at least npage pages from the treap of large spans.
// Returns nil if no such span currently exists.
func (h *mheap) allocLarge(npage uintptr) *mspan {
// Search treap for smallest span with >= npage pages.
return h.freelarge.remove(npage)
}
freelarge的类型是mTreap, 调用remove函数会在树里面搜索一个至少npage且在树中的最小的span返回:
// remove searches for, finds, removes from the treap, and returns the smallest
// span that can hold npages. If no span has at least npages return nil.
// This is slightly more complicated than a simple binary tree search
// since if an exact match is not found the next larger node is
// returned.
// If the last node inspected > npagesKey not holding
// a left node (a smaller npages) is the "best fit" node.
func (root *mTreap) remove(npages uintptr) *mspan {
t := root.treap
for t != nil {
if t.spanKey == nil {
throw("treap node with nil spanKey found")
}
if t.npagesKey < npages {
t = t.right
} else if t.left != nil && t.left.npagesKey >= npages {
t = t.left
} else {
result := t.spanKey
root.removeNode(t)
return result
}
}
return nil
}
向arena区域申请新span的函数是mheap类的grow函数:
// Try to add at least npage pages of memory to the heap,
// returning whether it worked.
//
// h must be locked.
func (h *mheap) grow(npage uintptr) bool {
// Ask for a big chunk, to reduce the number of mappings
// the operating system needs to track; also amortizes
// the overhead of an operating system mapping.
// Allocate a multiple of 64kB.
npage = round(npage, (64<<10)/_PageSize)
ask := npage << _PageShift
if ask < _HeapAllocChunk {
ask = _HeapAllocChunk
}
// 调用mheap.sysAlloc函数申请
v := h.sysAlloc(ask)
if v == nil {
if ask > npage<<_PageShift {
ask = npage << _PageShift
v = h.sysAlloc(ask)
}
if v == nil {
print("runtime: out of memory: cannot allocate ", ask, "-byte block (", memstats.heap_sys, " in use)\n")
return false
}
}
// 创建一个新的span并加到自由列表中
// Create a fake "in use" span and free it, so that the
// right coalescing happens.
s := (*mspan)(h.spanalloc.alloc())
s.init(uintptr(v), ask>>_PageShift)
p := (s.base() - h.arena_start) >> _PageShift
for i := p; i < p+s.npages; i++ {
h.spans[i] = s
}
atomic.Store(&s.sweepgen, h.sweepgen)
s.state = _MSpanInUse
h.pagesInUse += uint64(s.npages)
h.freeSpanLocked(s, false, true, 0)
return true
}
继续查看mheap的sysAlloc函数:
// sysAlloc allocates the next n bytes from the heap arena. The
// returned pointer is always _PageSize aligned and between
// h.arena_start and h.arena_end. sysAlloc returns nil on failure.
// There is no corresponding free function.
func (h *mheap) sysAlloc(n uintptr) unsafe.Pointer {
// strandLimit is the maximum number of bytes to strand from
// the current arena block. If we would need to strand more
// than this, we fall back to sysAlloc'ing just enough for
// this allocation.
const strandLimit = 16 << 20
// 如果arena区域当前已提交的区域不足, 则调用sysReserve预留更多的空间, 然后更新arena_end
// sysReserve在linux上调用的是mmap函数
// mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if n > h.arena_end-h.arena_alloc {
// If we haven't grown the arena to _MaxMem yet, try
// to reserve some more address space.
p_size := round(n+_PageSize, 256<<20)
new_end := h.arena_end + p_size // Careful: can overflow
if h.arena_end <= new_end && new_end-h.arena_start-1 <= _MaxMem {
// TODO: It would be bad if part of the arena
// is reserved and part is not.
var reserved bool
p := uintptr(sysReserve(unsafe.Pointer(h.arena_end), p_size, &reserved))
if p == 0 {
// TODO: Try smaller reservation
// growths in case we're in a crowded
// 32-bit address space.
goto reservationFailed
}
// p can be just about anywhere in the address
// space, including before arena_end.
if p == h.arena_end {
// The new block is contiguous with
// the current block. Extend the
// current arena block.
h.arena_end = new_end
h.arena_reserved = reserved
} else if h.arena_start <= p && p+p_size-h.arena_start-1 <= _MaxMem && h.arena_end-h.arena_alloc < strandLimit {
// We were able to reserve more memory
// within the arena space, but it's
// not contiguous with our previous
// reservation. It could be before or
// after our current arena_used.
//
// Keep everything page-aligned.
// Our pages are bigger than hardware pages.
h.arena_end = p + p_size
p = round(p, _PageSize)
h.arena_alloc = p
h.arena_reserved = reserved
} else {
// We got a mapping, but either
//
// 1) It's not in the arena, so we
// can't use it. (This should never
// happen on 32-bit.)
//
// 2) We would need to discard too
// much of our current arena block to
// use it.
//
// We haven't added this allocation to
// the stats, so subtract it from a
// fake stat (but avoid underflow).
//
// We'll fall back to a small sysAlloc.
stat := uint64(p_size)
sysFree(unsafe.Pointer(p), p_size, &stat)
}
}
}
// 预留的空间足够时只需要增加arena_alloc
if n <= h.arena_end-h.arena_alloc {
// Keep taking from our reservation.
p := h.arena_alloc
sysMap(unsafe.Pointer(p), n, h.arena_reserved, &memstats.heap_sys)
h.arena_alloc += n
if h.arena_alloc > h.arena_used {
h.setArenaUsed(h.arena_alloc, true)
}
if p&(_PageSize-1) != 0 {
throw("misrounded allocation in MHeap_SysAlloc")
}
return unsafe.Pointer(p)
}
// 预留空间失败后的处理
reservationFailed:
// If using 64-bit, our reservation is all we have.
if sys.PtrSize != 4 {
return nil
}
// On 32-bit, once the reservation is gone we can
// try to get memory at a location chosen by the OS.
p_size := round(n, _PageSize) + _PageSize
p := uintptr(sysAlloc(p_size, &memstats.heap_sys))
if p == 0 {
return nil
}
if p < h.arena_start || p+p_size-h.arena_start > _MaxMem {
// This shouldn't be possible because _MaxMem is the
// whole address space on 32-bit.
top := uint64(h.arena_start) + _MaxMem
print("runtime: memory allocated by OS (", hex(p), ") not in usable range [", hex(h.arena_start), ",", hex(top), ")\n")
sysFree(unsafe.Pointer(p), p_size, &memstats.heap_sys)
return nil
}
p += -p & (_PageSize - 1)
if p+n > h.arena_used {
h.setArenaUsed(p+n, true)
}
if p&(_PageSize-1) != 0 {
throw("misrounded allocation in MHeap_SysAlloc")
}
return unsafe.Pointer(p)
}
以上就是分配对象的完整流程了, 接下来分析GC标记和回收对象的处理.
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 125
- 统信桌面专业版【全盘安装UOS系统】介绍 120
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 111
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
