瀚高数据库备份与恢复实践
1
概述
1.1
数据库备份的重要性
备份数据是维护数据库必不可少的操作,任何数据库都需要备份。
备份就是为了防止原数据丢失,保证数据的安全。当数据库因为某些原因造成部分或者全部数据丢失后,备份文件可以帮我们找回丢失的数据。因此,数据备份是很重要的工作。常见数据库备份的应用场景如下:
数据丢失应用场景:
-
人为操作失误造成某些数据被误操作
-
软件 BUG 造成部分数据或全部数据丢失
-
硬件故障造成数据库部分数据或全部数据丢失
-
安全漏洞被入侵数据恶意破坏
非数据丢失应用场景:
-
特殊应用场景下基于时间点的数据恢复
-
开发测试环境数据库搭建
-
相同数据库的新环境搭建
-
数据库或者数据迁移
以上是一些数据库备份常见的应用场景,数据库备份还有其它应用场景,比如磁盘故障导致整个数据库所有数据丢失,并且无法从已经出现故障的硬盘上面恢复出来时,可以通过最近时间的整个数据库的物理或逻辑备份数据文件,尽可能的将数据恢复到故障之前最近的时间点。
1.2
备份
瀚高数据库系统支持完善的备份策略,用户根据自己的需要,选择不同的备份方式。瀚高数据库可以通过以下四种方式进行备份:
-
SQL转储
这种方式可以在线的进行完整一致的备份,并不阻塞其它用户对数据库的访问。可用于跨瀚高数据库版本,跨系统平台的数据迁移。
-
文件系统级别备份
这种备份方式是冷备份,需要关闭数据库,然后拷贝数据文件的完整目录。恢复数据库时,只需将数据目录复制到原来的位置。该方式实际工作中很少使用。
-
连续归档
这是一种在线物理备份方式,需要数据库开启归档。这种方式的策略是把一个文件系统级别的全量备份和WAL(预写式日志)级别的增量备份结合起来。当需要恢复时,先恢复文件系统级别的备份,然后重放备份的WAL文件,把系统恢复到之前的某个状态。适用于对数据库的常规周期备份,可用于大型数据库的增量备份和恢复,以及构建实时的热备份系统。
-
瀚高db_backup备份工具
db_backup也是一种在线物理备份方式,需要数据库开启归档。工具提供多种备份恢复策略,可以进行全量、增量、归档多种备份方式,另外还提供备份校验、备份集管理功能,通常用于帮助企业级数据库系统制定备份策略。
1.3
恢复
瀚高数据库在数据恢复时,按照原理的不同,将还原与恢复分为逻辑还原和物理恢复。逻辑还原是通过执行逻辑备份文件中SQL语句,重建数据库对象。物理恢复是指根据备份集的内容和归档的日志对数据库集簇进行恢复。使用备份集可以恢复到备份结束时的一致状态;使用备份集和归档日志可以恢复到备份之后某个历史上的时刻的位置(如果恢复到崩溃时刻,称为完全恢复;如果恢复到崩溃之前的某个时刻,称为不完全恢复)。
瀚高数据库系统的数据恢复包括以下方式:
-
基于SQL的逻辑还原
这种方式是基于SQL转储而来的备份集进行的一种逻辑还原方式,能够针对不同的备份粒度,可以对数据库、模式、表等进行还原。可用于跨瀚高数据库版本,跨系统平台的数据迁移。
-
基于文件系统级别备份的物理恢复
这种备份方式在恢复数据库时,只需将备份的数据目录重新复制回原来的位置即可。该方式实际工作中很少使用。
-
基于时间点恢复
这种备份方式是将数据库的状态恢复到当前运行时间前的任何一个状态一致的时间点。日志记录中记录了该操作发生的时间,通过在恢复流程中判断时间可以决定使用哪部分日志做恢复,从而达到恢复数据库到一个特定时间点的目的。基于时间点的恢复也需要使用一个完整的备份集加上若干归档日志。
-
基于db_backup的物理恢复
通过db_backup可以进行完全恢复与选定时间点恢复(不完全恢复)。当发生严重故障丢失数据一般采用完全恢复,使用一个全量备份加上所有归档日志可以恢复日志记录的所有数据。但有时,指定时间点和崩溃前一刻状态之间出现了错误(如数据库某个表被删除,存储介质错误导致日志文件丢失),此时进行完全恢复将没有意义了,需要进行不完全恢复,之所以叫不完全恢复就是不应用所有的日志来恢复数据库。
2
SQL转储与逻辑还原
2.1
命令行方式
瀚高数据库提供pg_dump命令进行数据库的SQL转储。pg_dump是一个瀚高数据库客户端应用,可以在任何可以访问数据库的远端主机上进行备份工作。
pg_dump命令可以选择一个数据库或部分表进行备份,在备份时不会阻塞其他用户对数据库的访问(读和写),因此可以在数据库运行时进行完整一致的备份。pg_dump生成的备份文件可以是一个SQL脚本或归档文件。
-
SQL脚本
SQL脚本是纯文本格式的文件,包含许多SQL命令,通过执行这些SQL命令可以重建数据库。甚至可以在其他机器上重建该数据库,对脚本进行修改后,还可以在非瀚高数据库系统上执行这个SQL脚本文件而重建备份的表。
备份为SQL脚本及还原示例:
备份数据库testdb——pg_dump -U sysdba -d testdb>/backup/testdb.sql还原数据库testdb——psql -U sysdba -d testdb</backup/testdb.sql
可以单独备份某个表。
备份表tb1——pg_dump -U sysdba -d testdb -t tb1>/backup/tb1.sql
-
归档文件
归档格式的备份文件需要与pg_restore命令配合使用,从而提供一种灵活的备份和恢复机制。pg_dump可以将整个瀚高数据库备份到一个归档格式的备份文件中,而pg_restore可以从这个归档格式的备份文件中选择性的恢复部分表或数据库对象。
文档格式的备份又分为自定义格式、目录格式和tar格式三种:
(1) 自定义格式比较灵活,可以对归档元素进行选取和重新排列,默认是压缩的,因此通常使用自定义格式;
(2) 目录格式将创建一个目录,该目录包含一个为每个被转储的表和二进制大对象的文件,这个格式缺省的时候是压缩的,并且也支持并行转储;
(3) tar格式不是压缩的,加载时不能重新排列。
在自定义格式进行备份:
备份数据库testdb自定义格式——pg_dump -Fc -U sysdba -d testdb>/backup/testdb.dmp还原数据库testdb——psql -U sysdba -d testdb</backup/testdb.sql
瀚高数据库系统在目录格式下,支持开启多个线程并行备份恢复:
10线程并行备份——pg_dump -U sysdba -d test -j 10 -F d -f test
2.2
利用图形化管理工具
瀚高数据库开发管理工具为瀚高数据库的各个发行版本提供了图形化操作,在安装瀚高数据库后即可使用,该工具是访问瀚高数据库最简单、最直观的方式,让使用者减少对复杂、枯燥的命令行和sql语句的使用。利用开发管理工具中的备份与恢复功能,也可以方便的执行数据库的SQL转储与还原任务。
-
备份
瀚高数据库开发管理工具的备份功能是通过调用瀚高数据库的pg_dump来执行的。
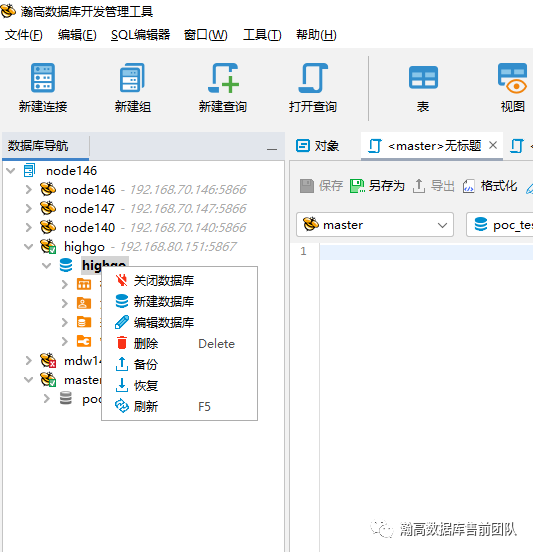
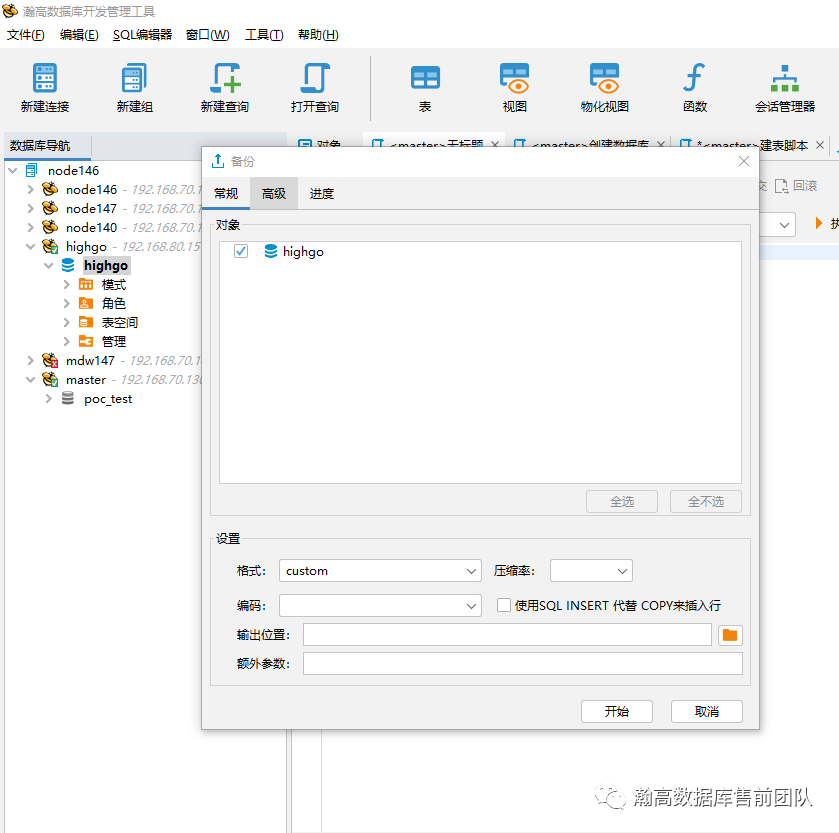
在瀚高数据库开发管理工具中,选中要备份的数据库—右击数据库—选择备份,出现以下对话框,可选项包括备份格式、压缩率、使用的编码、备份输出位置等,设置完成后点击“开始”按钮开始备份。
-
恢复
瀚高数据库开发管理工具的恢复功能是通过调用瀚高数据库的pg_restore执行的。执行恢复操作时,如果数据库中没有要还原的数据库,应该先创建一个名字和备份文件相同的。也可以将数据还原到其他数据库中。
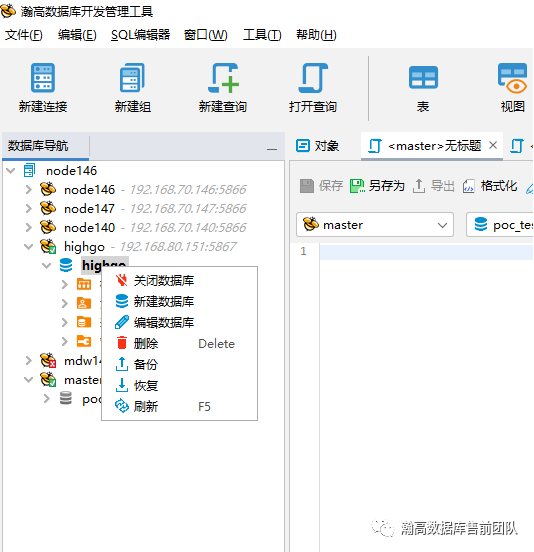
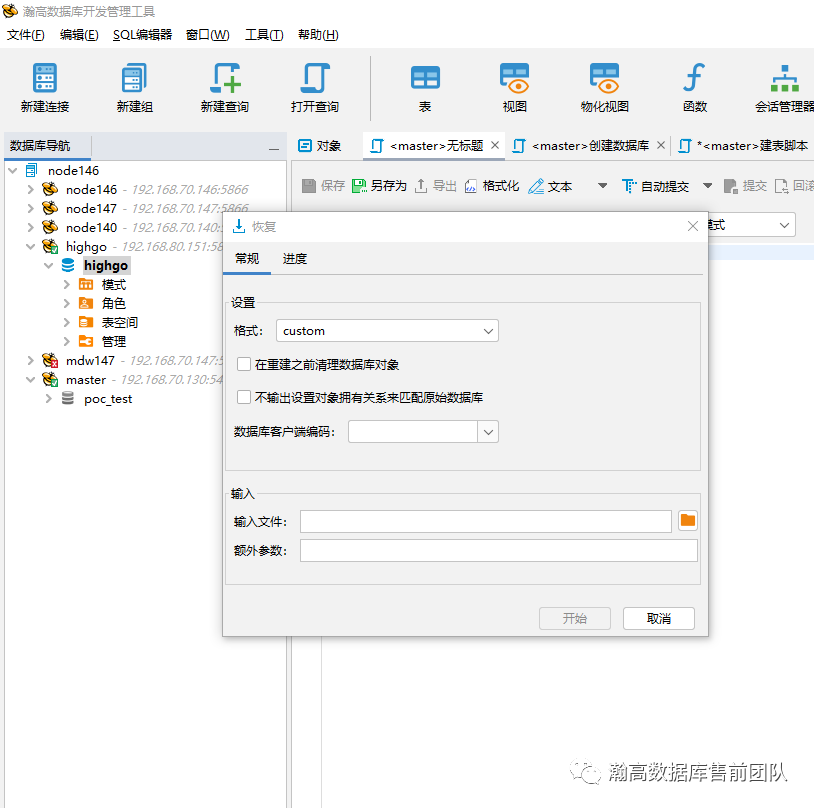
在瀚高数据库开发管理工具中,选中要还原的数据库—右击数据库—选择恢复,出现下面的对话框。然后选择已有的备份文件,进行还原。
3
文件系统级别备份与恢复
文件系统级别备份策略是直接复制瀚高数据库用于存储数据库中数据的文件,可以采用下面方式进行文件系统备份:
tar -cf backup.tar /opt/HighgoDB/data为了完成备份需要关闭数据库,所以生产环境中不建议采用此种备份方式。
另一种文件系统备份方法是在Linux系统下使用LVM的快照功能,这要求瀚高数据库建立在LVM上。用户可以在快照上直接启动数据库或把数据库从快照所在的文件系统中备份出来。下面介绍使用LVM完成瀚高数据库的备份:
1)数据库时安装在Linux的一个LV逻辑卷上,然后对整个逻辑卷创建快照:(创建快照前在数据库中做一下checkpoint)
lvcreate -s -n snap20200327 /dev/VgGroup/lv_data -L 500M-s :表示创建快照
/dev/VgGroup/lv_data :创建快照的逻辑卷
-L :表示快照使用的空间大小(根据实际使用大小判断,否则快照失效)
创建的快照可以用命令lvs查看。
2)创建的快照可以像系统镜像文件一样挂载:
mount -o nouuid /dev/VgGroup/snap20200327 -t xfs /snapdata其中参数nouuid是必须要加的,因为快照的UUID与实际文件系统一致,加此参数不与现有逻辑卷冲突。
3)快照挂载后,进入挂载点,可以将里面的数据库目录打包:
cd /snapdatatar -cvf /data/backup-snap20200327.tar.gz pgsql_data
创建完成后就可以卸载掉快照文件并删除了。
4)压缩的tar包可以放到其他服务器上解压,并通过瀚高数据库进行启动:
tar -xvf backup-snap20211120.tar.gz将解压后的文件也就是data目录放到与原目录相同目录结构上,就可以直接启动:
pg_ctl start -D /opt/HighGo4.5.6-see/data需要注意除了目录结构相同,新服务器上的瀚高数据库版本也要保持一致。最好不要直接在本地打开快照的数据库,因为快照中记录的与实际运行的一样的数据库服务进程,如果自定义了表空间,都会同时指向相同的表空间路径,会与现有的数据库服务冲突。
如果没有使用表空间,还需要注意的事项:
-
打开快照上的数据库之前,需要修改postgresql.conf中配置的端口,防止与主数据库的端口冲突。
-
需要修改一些内存参数,防止占用内存太多。
-
需要将备份中的postmaster.pid删除,因为postmaster.pid中记录了主数据的进程,如果不删除,会误伤主数据。
4
连续归档与基于时间点恢复
有时用户想将数据库回到之前的状态,比如在一个特定的时间点检索数据库,然后重新开始。如果对一个小型数据库,例如几个GB数据量,通常会做全面的备份,一旦出现问题,可以从备份中恢复数据库。但当遇到大数据库,这不是一个可行的解决方案,我们不能频繁的对几百个GB甚至TB的数据库进行全面备份。此时需要求助前一段时间的一个备份,然后将数据库恢复到某个时间点,这就是基于时间点的恢复。恢复时间将取决于我们所需要恢复的内容。
瀚高数据库能够实现连续归档。瀚高数据库始终维护着一个WAL日志文件,该日志文件用于记录数据库数据文件的每次改变。这种文件机制可以在把数据库使用文件系统的方式备份出来的同时把相应的WAL日志也备份出来。因为有了WAL日志,即使备份出来的数据库不一致(例如刚拷贝完前4KB的块,数据库又写了后4KB块内容,那么所拷贝的就不是一个完整的块),也可以重放备份开始后的WAL日志,把备份的内容推到一致的状态。
在备份瀚高数据库时可以通过pg_basebackup物理备份工具,或者简单的cp命令或tar命令等拷贝、备份文件来实现数据库的在线备份,也叫做基础备份。后续WAL日志的备份与此基础备份构成一个完整备份。然后不停重放WAL日志就可以把数据推到备份结束后的任意一个时间点,这就是基于时间点的恢复。
瀚高数据库的用户可以把基础备份恢复到另一台机器,然后不停的从原始数据库机器上接收WAL日志,在新机器上持续重放WAL日志,这样就可以在任何时间内在另一台机器上打开这个新产生的数据库,它拥有当前数据库的最新数据状态。
瀚高数据库通过以下三个选项将数据库还原到特定的时间点:
recovery_target_name:该选项被用于恢复命名的还原点。
pg_create_restore_point:可以用来创建命名的还原点。
recovery_target_time:该选项指定恢复将继续执行的时间戳。这个选项可以用在这种场合:当由于认为的错误发生,并在一段时间后才意识到,同时用户记得删除表或删除记录的大致时间。虽然指定了一个时间戳,但是恢复将仅在那个时间点运行的事务执行后才停止。
recovery_target_xid:如果知道某个事务id之后数据库才损坏,此选项便可恢复到该事务恢复完成的点。
下面是在瀚高数据库中连续归档与基于时间点恢复过程。
4.1
开启WAL日志归档
启用瀚高数据库的WAL连续归档,需设置postgresql.conf文件中WAL相关参数:
wal_level = replicaarchive_mode = onarchive_command = ' cp %p /archive_log/%f '
wal_level = replica表示支持wal归档和复制;archive_mode=on表示打开归档备份;archive_command参数的配置值可以是一个Unix命令,将WAL日志文档拷贝到其他位置,archive_command= ' cp %p /archive_log/%f '表示将归档日志拷贝的路径。使用操作系统命令scp也可以把WAL日志拷贝到其它机器上,从而实现跨机器的归档日志进行备份,如下:
archive_command = ' scp %p root@192.168.70.147:/archive%f '
4.2
制作一个基础备份
基础备份可以通过瀚高数据库提供的pg_basebackup备份工具进行。
pg_basebackup -D /opt/HighGo4.5.6-see/data_bak -Fp -Xs -v -P -h 127.0.0.1 -U sysdba备份完成后会在备份目录中记录一个标签文件backup_label,它包含了开始备份的wal log的位置,checkpoint的位置,备份的方式streamed备份是从哪个服务器上操作的,以及备份的开始的时间。
4.3
基于时间点恢复过程
(1)停数据库
(2)将基础备份的data_bak目录替换为新的data目录
rm -rf datacp -R data_bak datatouch /data/recovery.signal
(3)修改配置文件
vi data/postgresql.confrestore_command = 'cp /archive_log/%f %p'recovery_target_time = '2021-11-24 16:45:46'
restore_command把wal归档拷贝回xlog目录,因为要恢复基础备份后变动的数据,需要使用原来日志进行重放;recovery_target_time指定需要恢复的时间点。
(4)启动数据库,恢复完成。
5
瀚高db_backup备份与恢复
5.1
瀚高db_backup概述
瀚高数据库提供db_backup备份恢复工具进行物理备份与恢复管理,提供一致性备份,能够对单一数据库、数据库集群进行全量、0级和1级增量、归档日志进行物理在线备份,同时具备备份校验、压缩以及备份集管理功能,可以根据不同业务对RPO及RTO需求选择响应的备份或者恢复策略。
目前大多数企业级数据库常规容量普遍都已达到TB级,日增上百GB的数据变化量属于常态,这对日常的数据库备份恢复性能和可靠性提出了更高的要求。db_backup备份恢复能够解决以下问题:
1)强一致性:备份集对数据库实例产生一个标识文件,使之与数据库实例相关联,防止数据备份恢复操作时的数据紊乱;
2)备份校验:通过对文件大小以及CRC来进行备份文件校验,保证备份文件的准确性和恢复的可用性。通过验证的备份才可用于之后的恢复过程。防止备份文件的损坏遗漏;
3)节省空间:db_backup能对每个数据块进行备份,并提供压缩,有效节省存储空间。
5.2
工作原理
-
全量备份
物理备份通常是将$PGDATA目录进行备份作为基础备份,同时将这期间所产生的wal日志也备份下来,这样由基础备份和wal日志组合起来的备份在恢复时才能达到数据的完整性。db_backup会与数据库发起连接,以获取相关参数来判断此次备份是否可以正常运行。在满足备份条件之后,在底层调用了瀚高数据库的pg_start_backup()与pg_stop_backup()函数,来达到在线备份的目的。
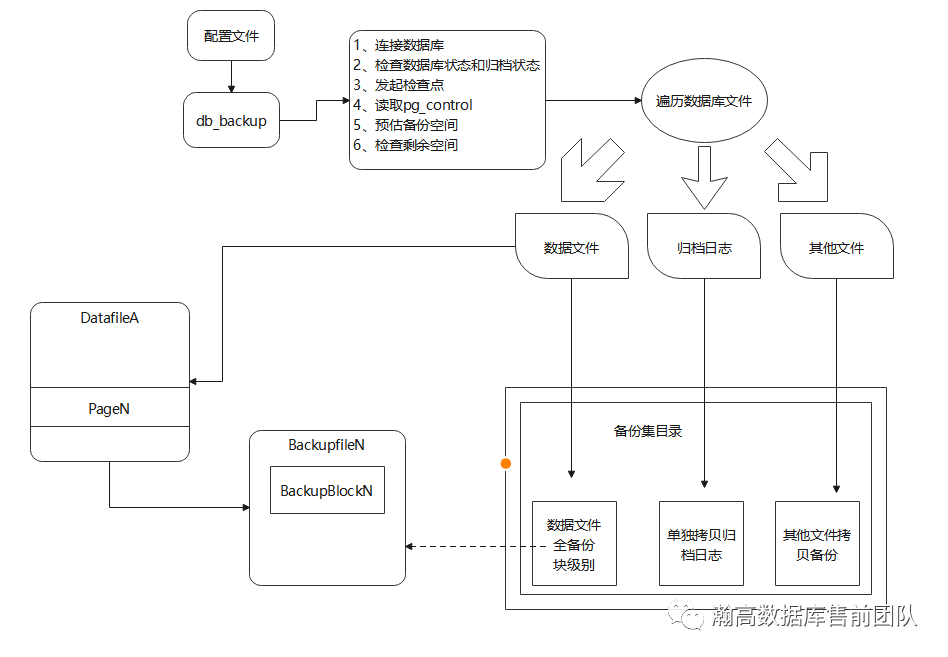
基本流程是对DATA目录下的文件进行遍历,对每一个数据块进行扫描备份,将相关的文件进行备份,并在相关的备份集目录下生成与$PGDATA目录结构相同的目录并存储备份文件,同时会生成与此次备份信息相关的信息文件,例如备份的文件信息,目录信息等,以便于之后的查看和使用。
对于这期间所保持的数据一致性,是由所调用的函数所决定的。当开启在线备份的时候,瀚高数据库会开启整页写入并执行checkpoint命令。对于开启整页写入是保证在wal日志中,checkpoint检查点后保存完整的数据页,在恢复的时候用wal日志中的数据页去替换基础备份中的相同数据块,保证数据页没有损坏,继而保证之后数据恢复的准确性。而执行checkpoint检查点则是保证了数据库中所有缓存的数据都已经存储在磁盘上了,那么之后做的基础备份就是完整的数据库原始数据。当备份过程结束时,db_backup会调用pg_stop_backup(),切换归档日志,将备份期间的保存所有数据以及操作的wal日志进行归档。这两部分的结合就完成了一次在线的全量备份。
-
增量备份
增量备份过程主要是判断哪一些数据文件发生了变化,哪一些数据块的lsn发生了变化。通过和之前记录的文件时间做比对,确定数据文件的变动。通过这个数据文件遍历数据块,找出发生变动的数据块,将其备份,就基本完成了增量备份。
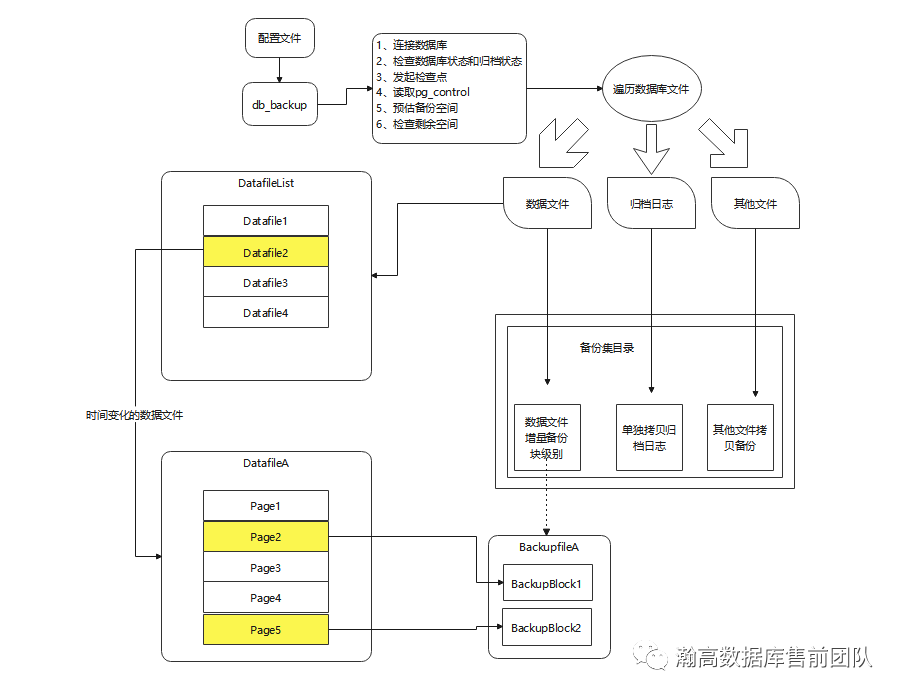
对于0级增量来说,它是基于全量备份,通过对上次全量备份的文件进行时间对比,找出时间变动的数据文件,而后对这些时间发生变化的数据文件进行数据块遍历,这个时候就体现了块级增量备份。由于PostgreSQL数据库在一些操作后,会导致$PGDATA中数据块的lsn发生变化,这个就作为数据块比较的依据。而发生过正常操作的数据块的lsn会变大,那么就根据这个条件筛选出所需要备份的数据块。
对于1级增量备份,它是基于上一次增量备份,过程与上述基本一致,所对比的对象由全量备份的文件列表,转变为上一次增量备份的文件列表,同样是通过文件时间变化来进行数据文件筛选,当数据库操作过后,存储在磁盘的数据文件的时间就会发生变动。而后对这些时间变动的数据文件进行数据块遍历,找出lsn变大的数据块,将这些数据块再进行备份。这样做的情况下使得存储所需的空间进一步减小。1级增量备份的前提是,必须要有一次全量备份和一次增量备份(保证都可以使用)。
而对于其他的一些备份工具,所做的备份为文件级别,会拷贝一些并没有发生变化的数据块,导致备份冗余,增加了备份所需要的存储空间。
5.3
初始化配置
初始化工具前需已经成功安装部署瀚高数据库并开启归档模式,将db_backup安装包解压后创建备份目录以及归档目录。在使用工具之前指定备份目录并初始化。
db_backup init -B /data/db_backup -D /usr/pgsql-12/data
初始化备份目录主要生成一些相关文件:

20210323文件夹:该目录下存储着备份文件的相关信息,以备份开始的时间作为目录结构。
backup文件夹:保存服务器日志和wal日志。
db_backup.ini:文件中保存了归档日志的路径,以及可以实行的备份策略。
system_identifier:数据库系统标识符,在连接数据库的时候需要进行校验,防止数据混乱。
timeline_history:里面存储着时间线的历史文件。
5.4
全量备份
全量备份能够在线备份瀚高数据库所有必要的文件,包括数据文件、归档日志文件,并以相同的目录结构保存在本地服务器上。
db_backup backup -U sysdba -b full
5.5
增量备份
增量备份能够备份自上一次备份以来更改过的所有数据块。提供0级增量和1级增量备份用于制定灵活的备份策略。
(1)0级增量备份
0级增量备份以全量备份为基础进行备份。0级增量备份优点是,恢复所用的备份集少,恢复起来比较简便。缺点是随着产生的备份文件不断增长,所需的备份时间越来越长,因此0级增量备份不适用于数据量大的数据库。
db_backup backup -U sysdba -b incremental --level=0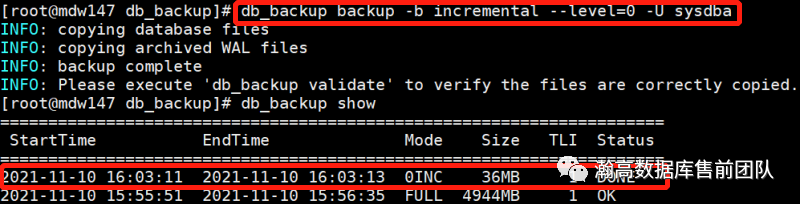
(2)1级增量备份
1级增量备份以上一次增量备份为基础进行备份,1级增量备份的优点是,产生的每个备份集较小,每次备份时间较短,省去很多不必要的重复备份。缺点是恢复时会使用很多备份集,虽然db_backup提供了备份目录管理,但是一但丢失其中一份,那么恢复的数据是不完整的。
db_backup backup -U sysdba -b incremental --level=1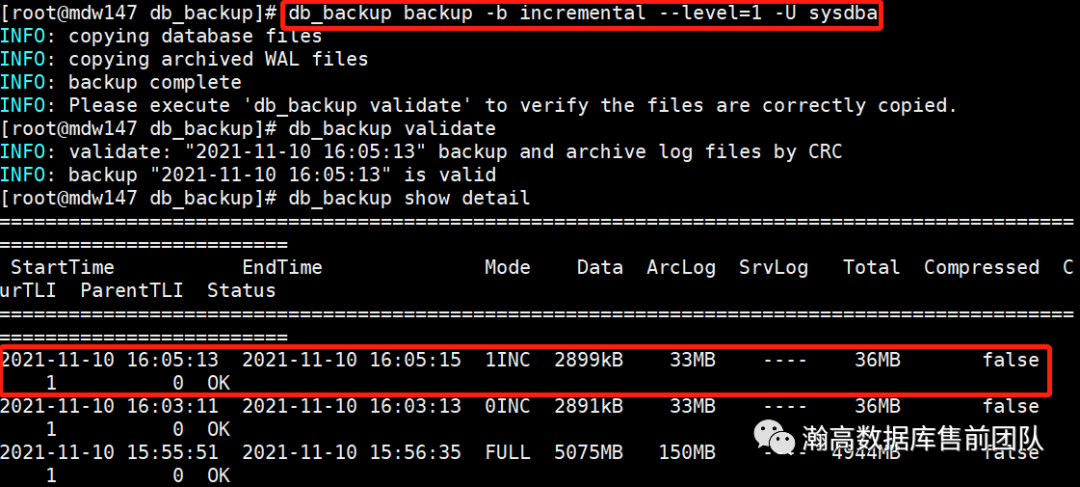
5.6
归档备份
针对于归档日志的备份,对于所产生的归档的wal日志进行备份,在归档目录丢失的情况下也能进行日志恢复。
db_backup backup -U sysdba -b archive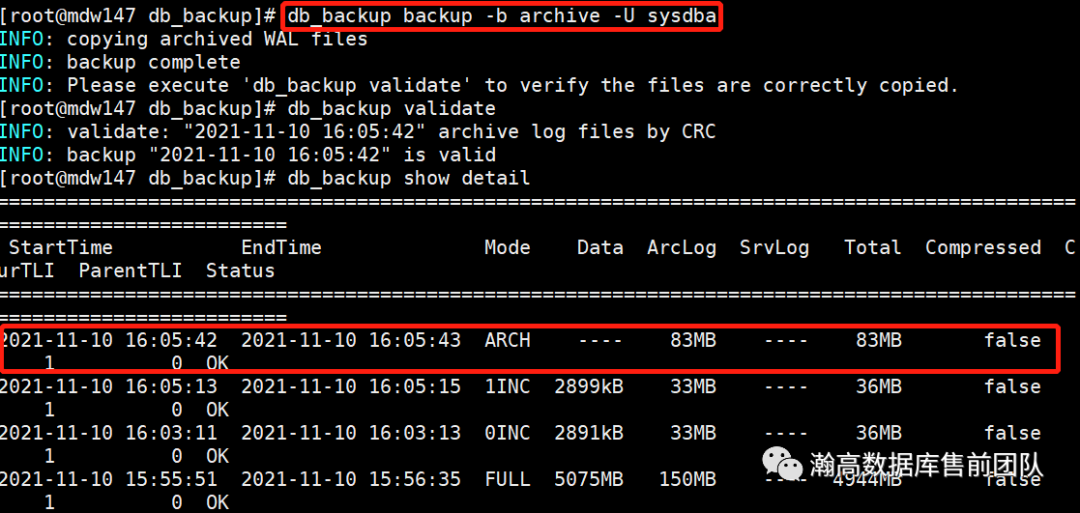
5.7
备份校验
如图3.2.1所示,备份完成后提示“执行validate命令验证文件是否正确备份”,通过show命令查看备份的状态,此时为“DONE”。
db_backup show
db_backup支持CRC方式对备份文件进行校验,校验完成后状态变为“OK”。至此全量备份完毕。
db_backup validate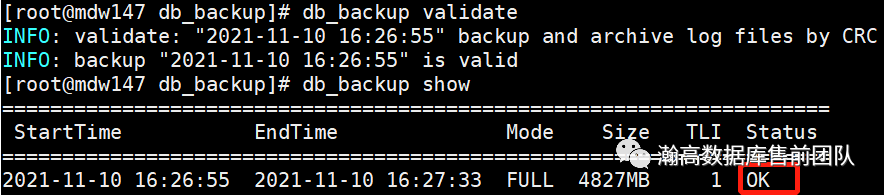
5.8
备份压缩
支持备份时进行压缩,能够有效节省磁盘空间。在进行全备、增量、归档备份时可通过compress-data参数进行压缩备份。
db_backup backup -U sysdba -b full --compress-datadb_backup backup -U sysdba -b incremental --level=0 --compress-datadb_backup backup -U sysdba -b incremental --level=1 --compress-data
下面以全量备份为例查看使用压缩备份与不使用压缩备份的文件大小对比。
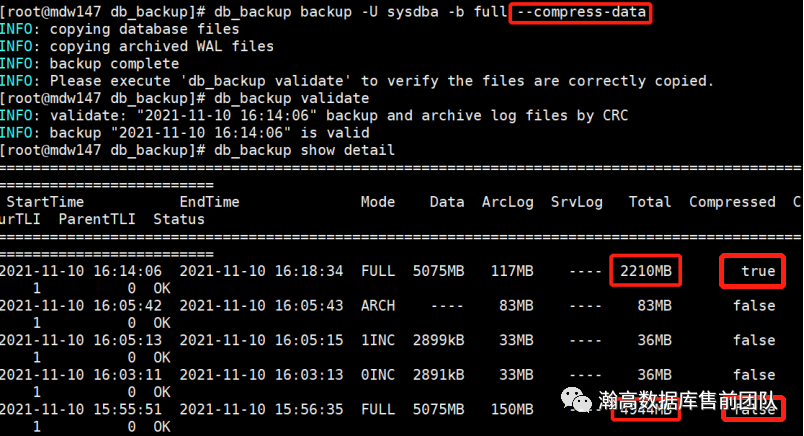
5.9
完全恢复
数据库会完全恢复到最新状态,包括到当前为止提交的所有数据修改,不会出现数据丢失。
db_backup restore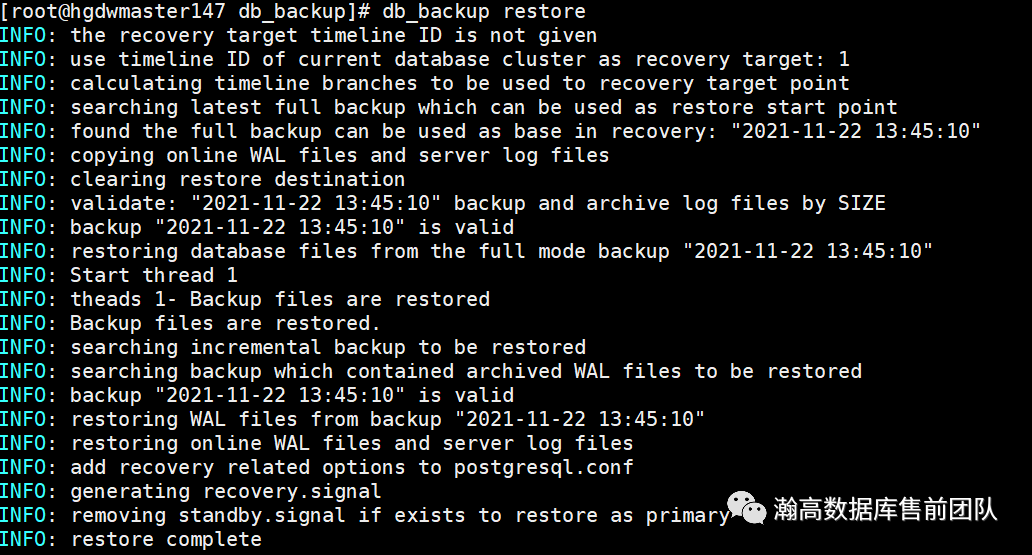
5.10
选定时间点恢复
首先查看备份集中包含时间点的备份,关闭数据库,指定某个时间点进行恢复。
db_backup showdb_backup restore --recovery-target-time “2021-11-22 13:46:02”
重启数据库后进入psql命令行,使数据库从只读模式中恢复。
select pg_wal_replay_resume();
5.11
并行恢复
针对数据库实例恢复串行化执行效率低的问题,db_backup提出一种基于多线程的并行恢复方法。并行恢复方法实现了各阶段的并行化,减少了恢复所需时间,保证了数据库在实际应用中的高效性。用户可以通过调用命令来控制线程数,以达到加快恢复速率的目的,并保证各部分数据的统一性和整体性,同时保证数据库重启后的可用性。
开启5个线程进行数据恢复:
db_backup restore --threads=5 -D /opt/HighGo4.5.6-see/data -B /db_backup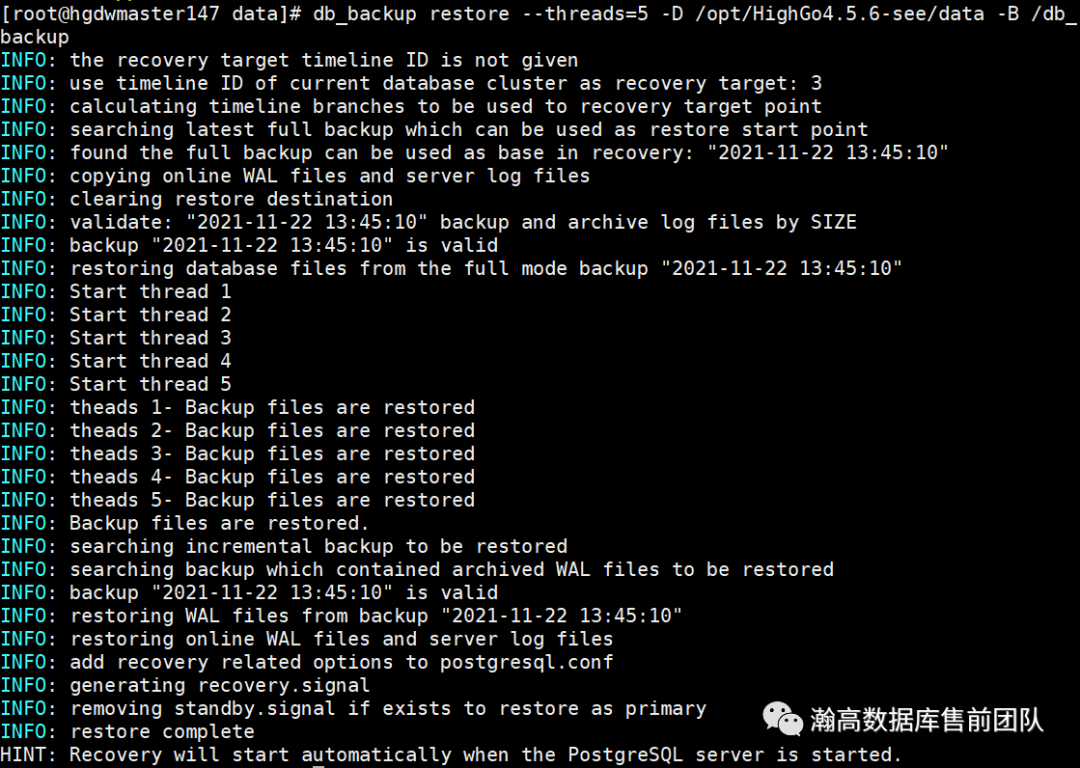
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 国产操作系统环境搭建(内含镜像资源链接和提取码) 96
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 93
- 分享几个在日常办公中可以用到的shell脚本 86
- 以openkylin为例编译安装内核 81
- bat脚本生成查看电脑配置\硬件信息 81
- 常见系统问题及其解决方法 81
- 分享解决宏碁电脑关机时自动重启的方法 78
- loadrunner常见问题整理 74
- 统信uosboot区分未挂载导致更新备份失败 72
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 71
- 最近下载排行榜
- 国产操作系统环境搭建(内含镜像资源链接和提取码) 0
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 0
- 分享几个在日常办公中可以用到的shell脚本 0
- 以openkylin为例编译安装内核 0
- bat脚本生成查看电脑配置\硬件信息 0
- 常见系统问题及其解决方法 0
- 分享解决宏碁电脑关机时自动重启的方法 0
- loadrunner常见问题整理 0
- 统信uosboot区分未挂载导致更新备份失败 0
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 0

prtyaa 收益401.13元

哆啦漫漫喵 收益245.41元

zlj141319 收益238.36元

IT-feng 收益219.97元

1843880570 收益214.2元

风晓 收益208.24元

777 收益173.2元

Fhawking 收益106.6元

信创来了 收益106.03元

克里斯蒂亚诺诺 收益91.08元
