「瀚高数据库技术栈」瀚高db_bulkload
1 瀚高db_bulkload产品简介
2 瀚高db_bulkload架构设计
l postgresql脚本
l db_bulkload程序
用户定义函数pg_bulkload()主要由读、写两个模块组成,其基本架构图如下:
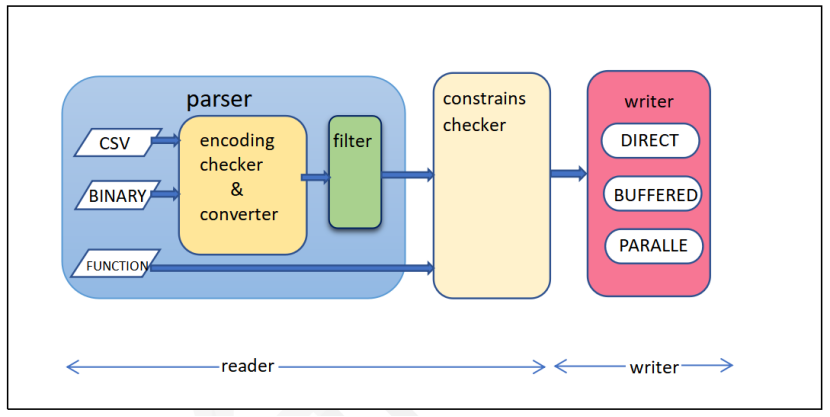
3 瀚高db_bulkload产品优势
l 快速加载巨量数据;
l 灵活的输入输出设置;
l 支持constrains与filter。
4 瀚高db_bulkload产品的功能
4.1批量加载数据

如果db_bulkload成功完成数据加载,结果如下:

4.2数据恢复
4.3数据过滤筛选
|
CREATE FUNCTION sample_filter(integer, text, text, real DEFAULT 0.05) RETURNS record AS $$ SELECT $1 * $4, upper($3) $$ LANGUAGE SQL; |
4.4数据约束检查
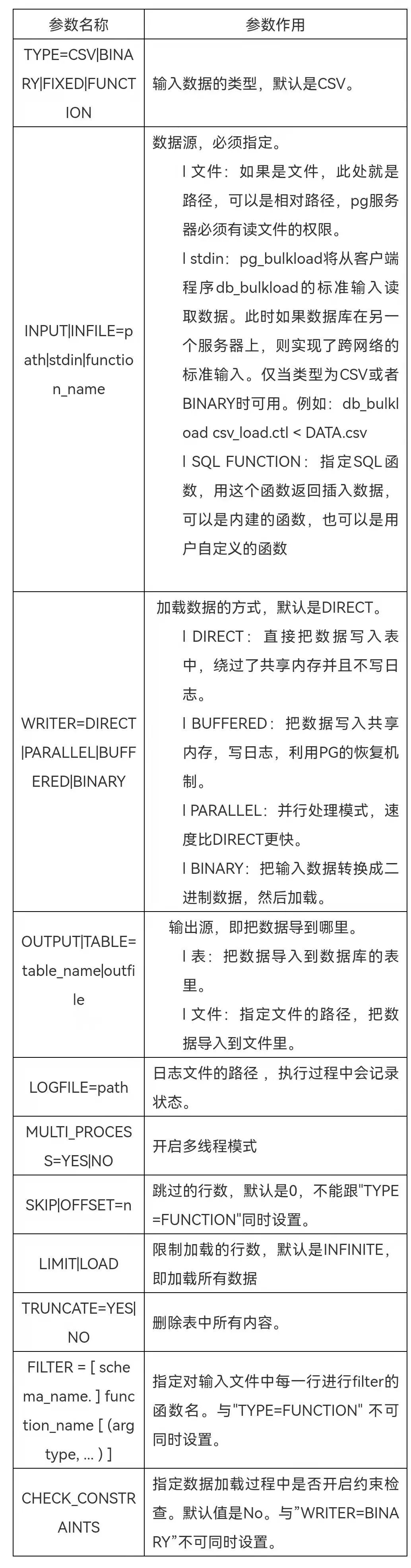
4.5参数设置
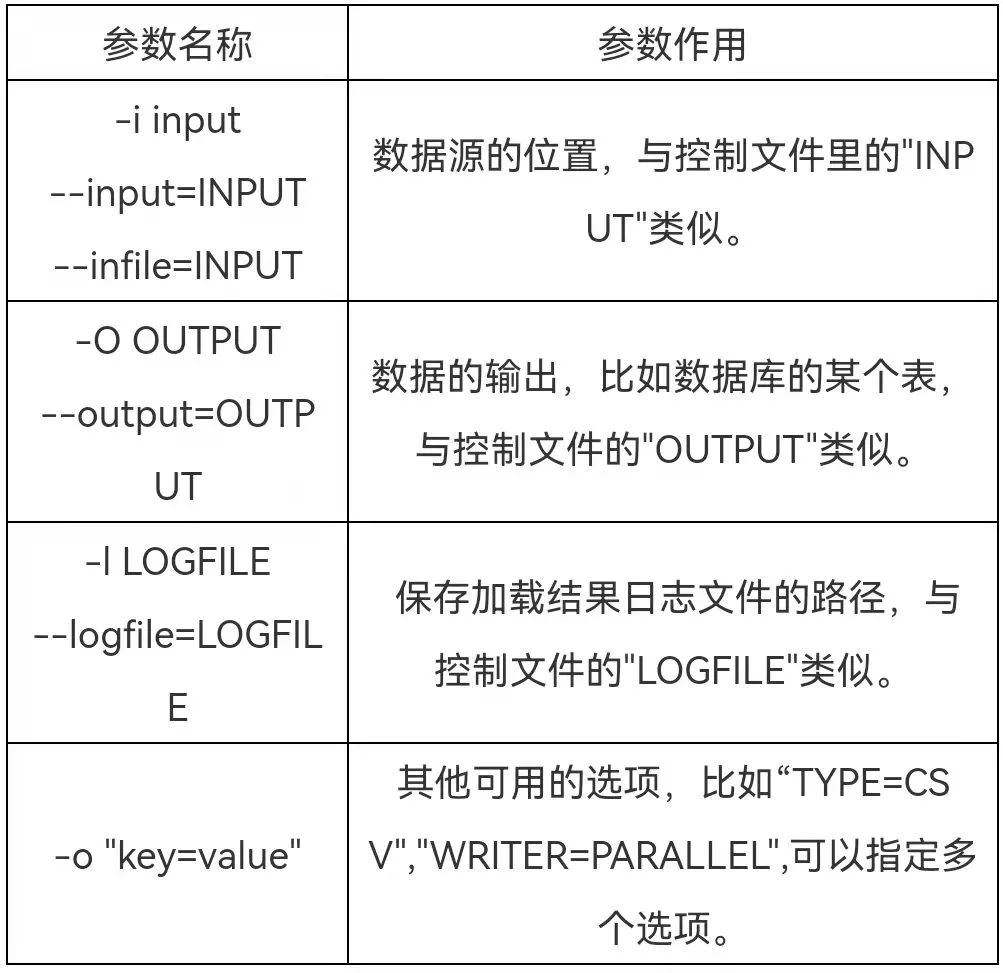
连接选项表(可以环境变量代替)
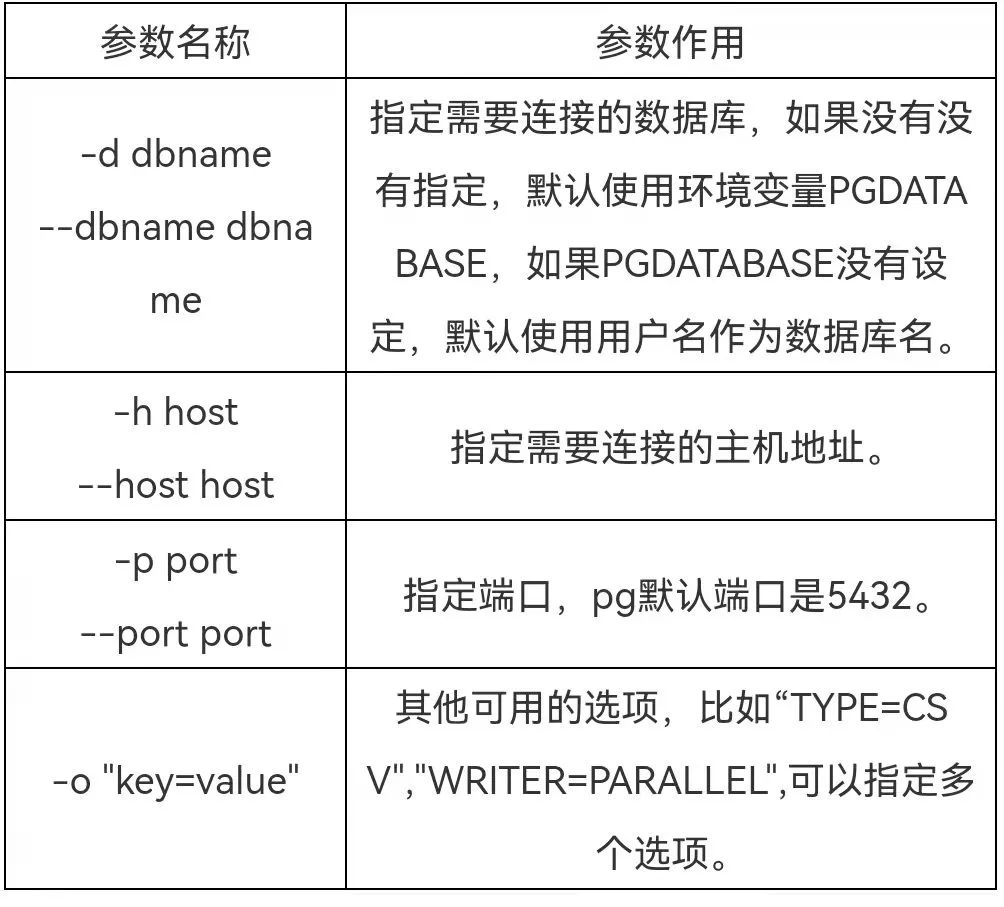
2. 控制文件参数
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 国产操作系统环境搭建(内含镜像资源链接和提取码) 97
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 93
- 分享几个在日常办公中可以用到的shell脚本 88
- bat脚本生成查看电脑配置\硬件信息 83
- 以openkylin为例编译安装内核 81
- 常见系统问题及其解决方法 81
- 分享解决宏碁电脑关机时自动重启的方法 78
- loadrunner常见问题整理 75
- 统信uosboot区分未挂载导致更新备份失败 73
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 71
- 最近下载排行榜
- 国产操作系统环境搭建(内含镜像资源链接和提取码) 0
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 0
- 分享几个在日常办公中可以用到的shell脚本 0
- bat脚本生成查看电脑配置\硬件信息 0
- 以openkylin为例编译安装内核 0
- 常见系统问题及其解决方法 0
- 分享解决宏碁电脑关机时自动重启的方法 0
- loadrunner常见问题整理 0
- 统信uosboot区分未挂载导致更新备份失败 0
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 0

prtyaa 收益401.13元

哆啦漫漫喵 收益253.43元

zlj141319 收益238.36元

IT-feng 收益219.97元

1843880570 收益214.2元

风晓 收益208.24元

777 收益173.2元

Fhawking 收益106.6元

信创来了 收益106.03元

克里斯蒂亚诺诺 收益91.08元
