随着瀚高数据库参与信创项目的不断深入,瀚高数据库产品与isv厂家做适配迁移的内容日益剧增,瀚高迁移工具产品团队结合瀚高应用迁移工程师在日常迁移工作中遇到的情况,对目前已有的瀚高数据库的迁移工具进行了功能升级推出升级版本,此次用于演示的迁移工具版本为hgdb-migration-v4.1.4。
瀚高数据库迁移工具支持源端为Oracle、MySQL、SQL Server、DB2、KingbaseV7、KingbaseV8、DM7、DM8、HIGHGO数据库,目标端为HIGHGO、PostgreSQL数据库的自动化迁移,针对用户的应用系统数据库迁移需求,瀚高会指派专职适配迁移工程师来配合应用开发商的开发人员、DBA进行适配与迁移的工作。基于应用迁移工作的安全性和实际迁移中对工具部署的灵活性考虑,瀚高迁移工具被设计为在单机运行的软件。与之前的版本相比,为了能更好地实现数据迁移工程管理,新增了工程组模块,迁移实施人员可以在工程组模块中实现各个功能在对应迁移工作中的分组管理,从而更好地管控对应迁移项目;在大量实际迁移工作中,根据用户的实际需求,新增了在源端生成迁移数据落地文件,可以安全拷贝至目标环境然后导入目标端指定数据库内库实现数据在目标端落盘,接下来会做部分功能的演示。
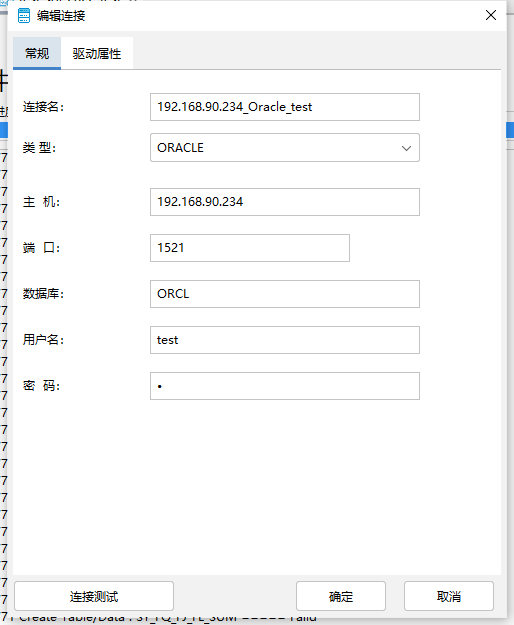
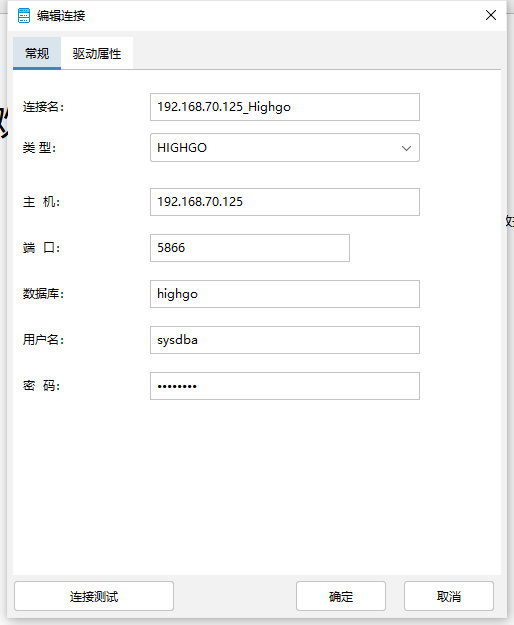
点击新建连接按钮,打开编辑连接界面,以下为编辑连接界面中填写项目的说明:
"连接名"是新建连接的名字,为必填项;如果连接名与已有连接相同则会提示;
"主机"是连接的 IP 地址,为必填项,默认为"localhost"此为必填项;
"端口”是连接的端口号为必填项,默认为"5866”;
"数据库”是要连接的数据库,为必填项,默认为"highgo”;
"用户名”是连接的用户名,为必填项,默认为"highgo”;
在"驱动属性”选项卡中,可以配置连接的驱动属性,如果配置了驱动属性,连接时将会使用设置的驱动属性点击左下方的"新增一行"图标,将新增一行空白行。点击左下方的"删除一行”图标,将删除选中的当前行。
新建源端库连接,在工作组中新建源端Oracle数据库连接,根据源库实际信息进行填写,进行连接测试,连接测试成功后保存。
新建目标端库连接,在工作组中新建目标端HighGo数据库连接,根据目标端数据库信息进行填写,进行连接测试,连接测试成功后保存。
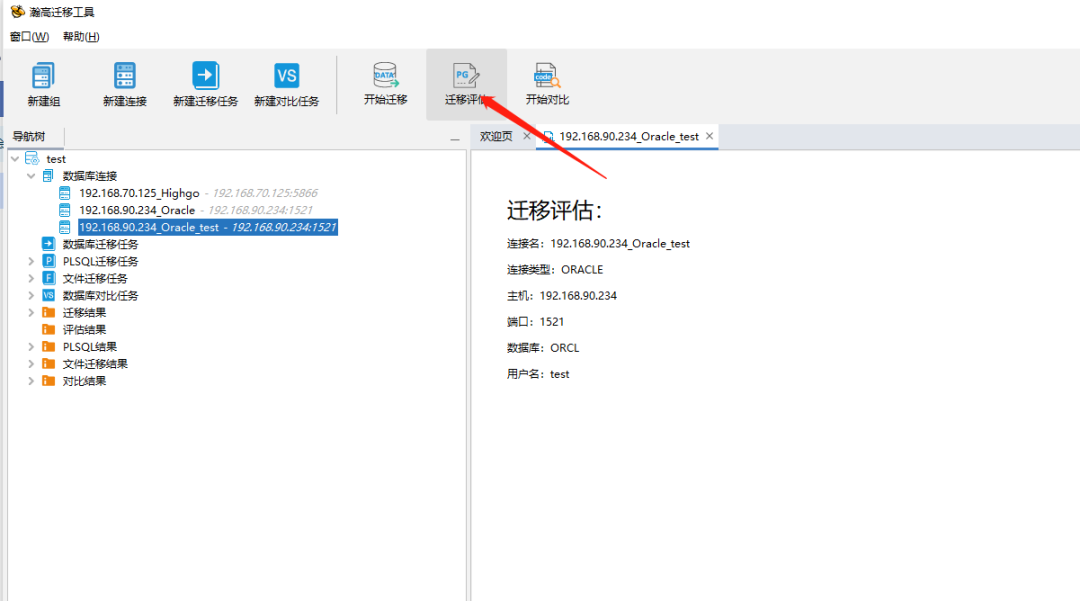
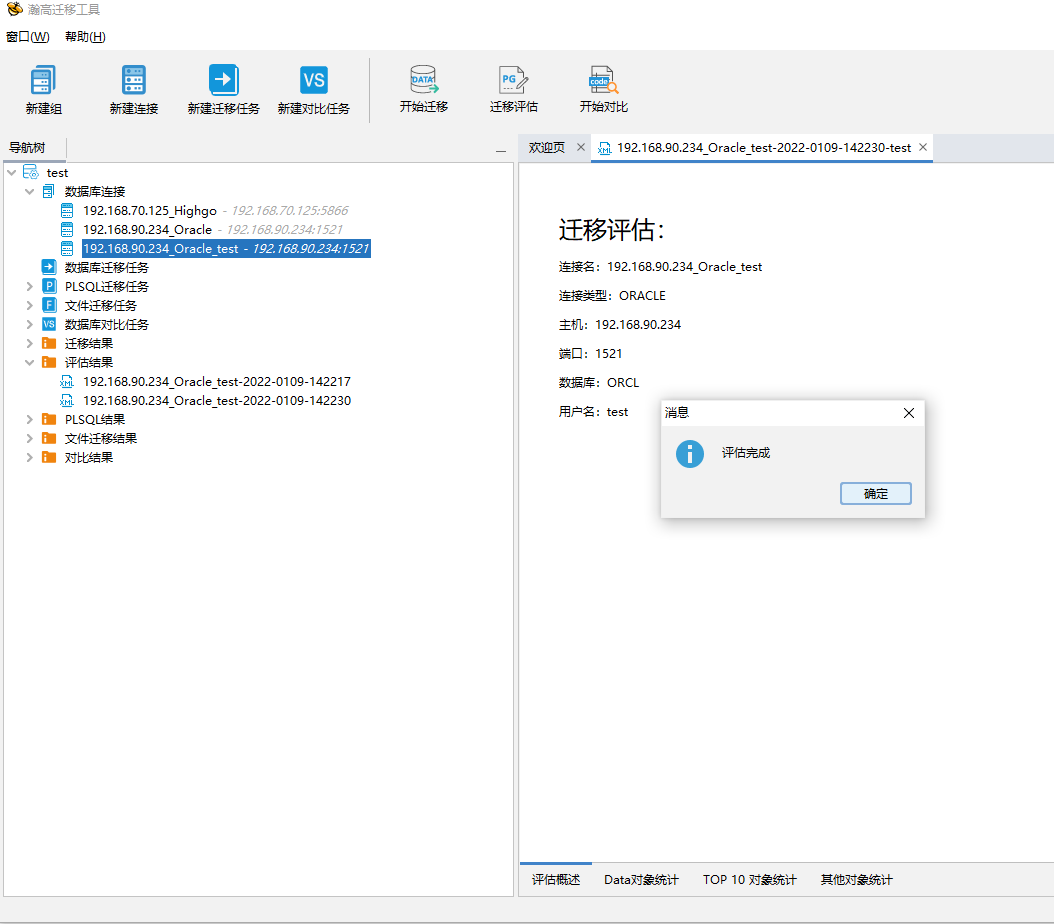
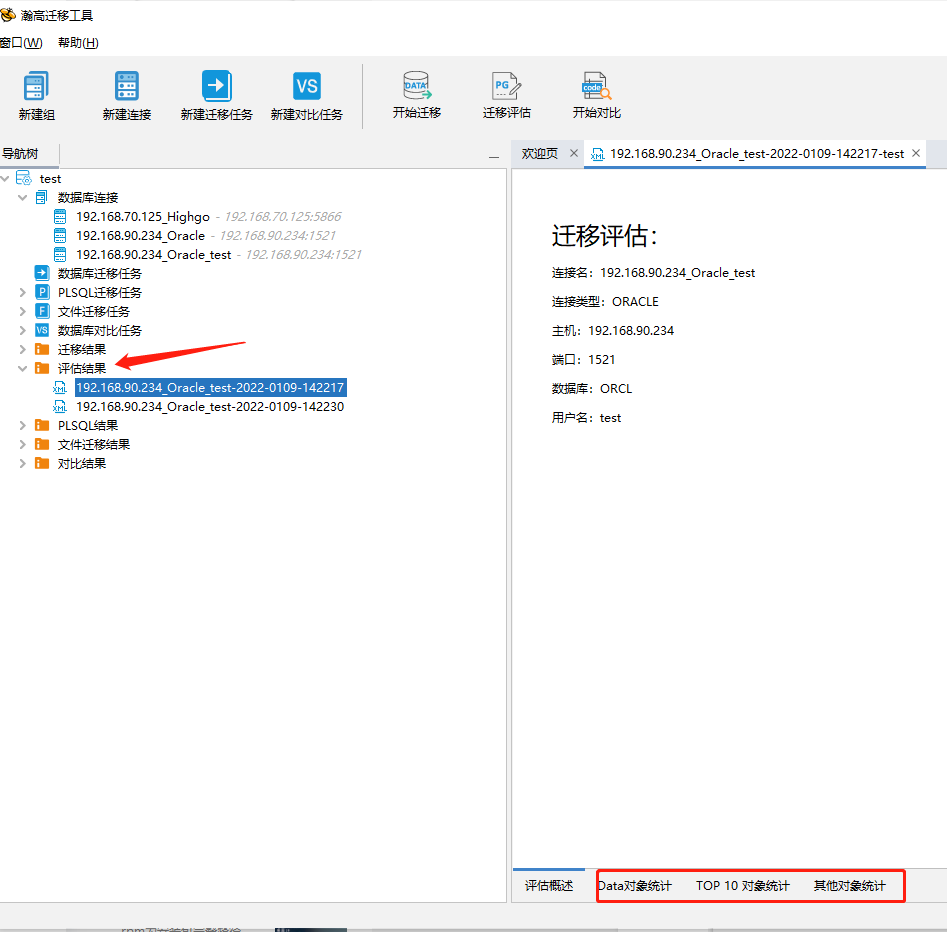
在工作组中进行源端数据库迁移评估,迁移评估完成后会获得相应的迁移评估报告,可根据评估报告进行数据迁移的工作量评估,并辅助制定迁移方案和计划。
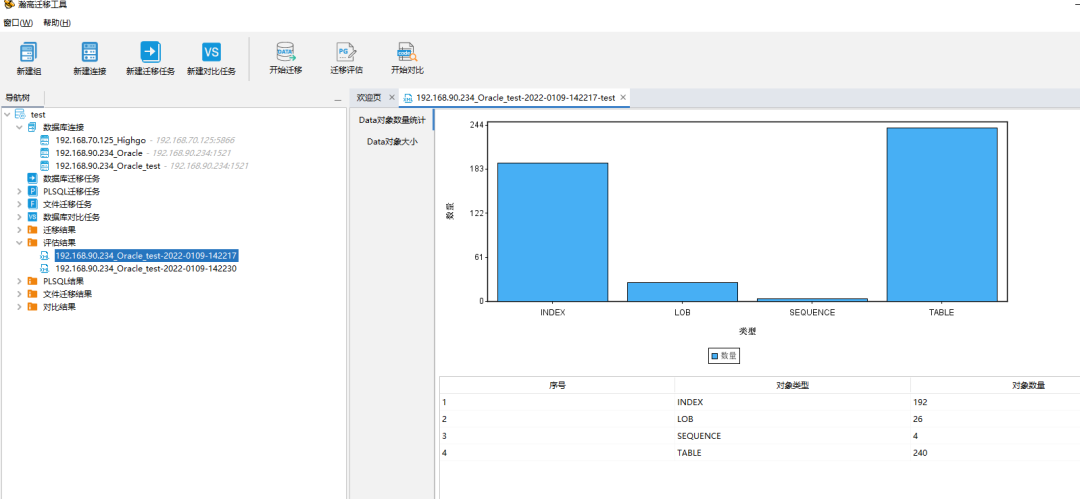
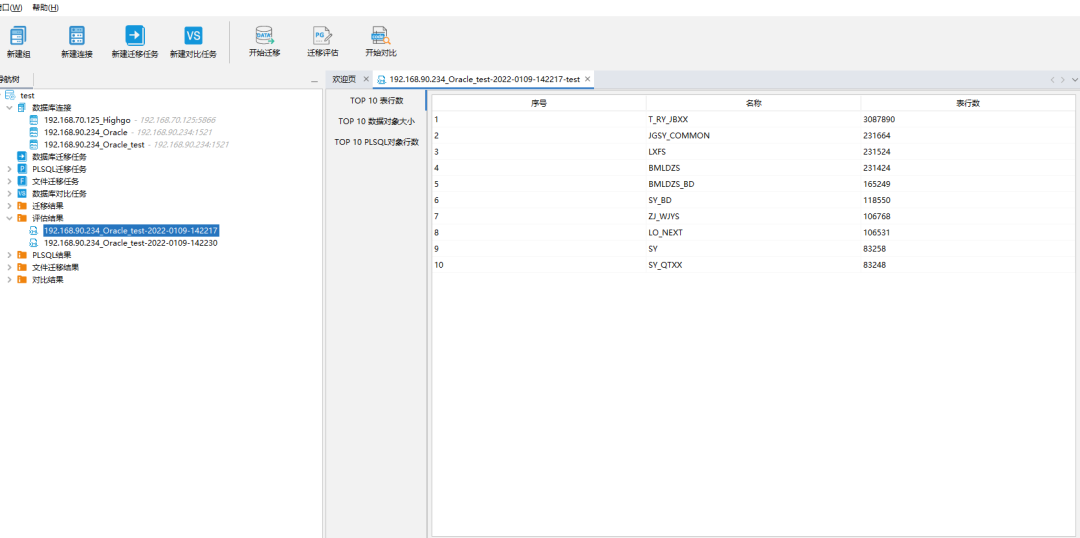
可以通过下图中标注红框的内容查看,数据评估结果包含以下信息:Data 对象数量统计(对象类型包括:TABLE、INDEX、SEQUENCE、LOB和 SYNONYM)、 Data 对象大小(对象类型包括:TABLE、INDEX、LOBINDEX 和 LOBSEGMENT)、Top10 表行数、Top10 数据对象大小、分区表统计、触发器统计、PLSQL 对象数量统计(对象类型包括:PACKAGE、VIEW、PACKAGE BODY、FUNCTION、PROCEDURE、MATERIALIZED VIEW、TYPE 和 TRIGGER)、TOP 10 PLSQL 对象行数、其他对象统计(其他对象为除 Data对象数量统计包括的对象和 PLSQL 对象统计包括的对象)。
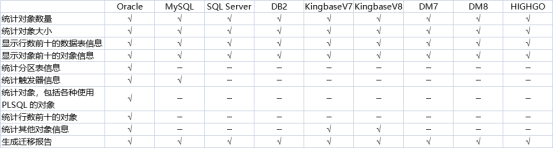
当前版本提供Oracle、MySQL、SQL Server、DB2、KingbaseV7、KingbaseV8、DM7、DM8、HIGHGO源端数据库到HIGHGO、PostgreSQL目标端数据库的迁移评估,支持数据库的功能如下列表:
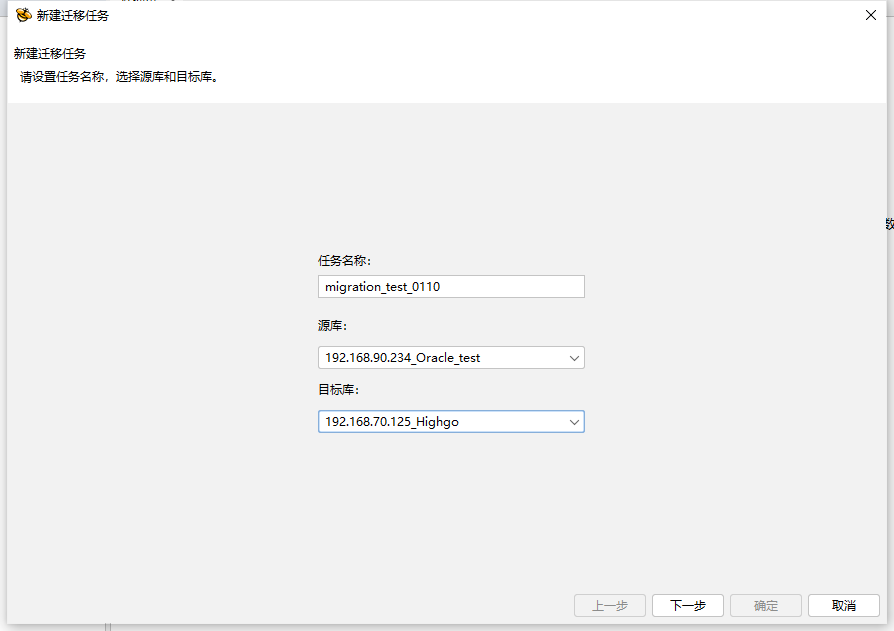
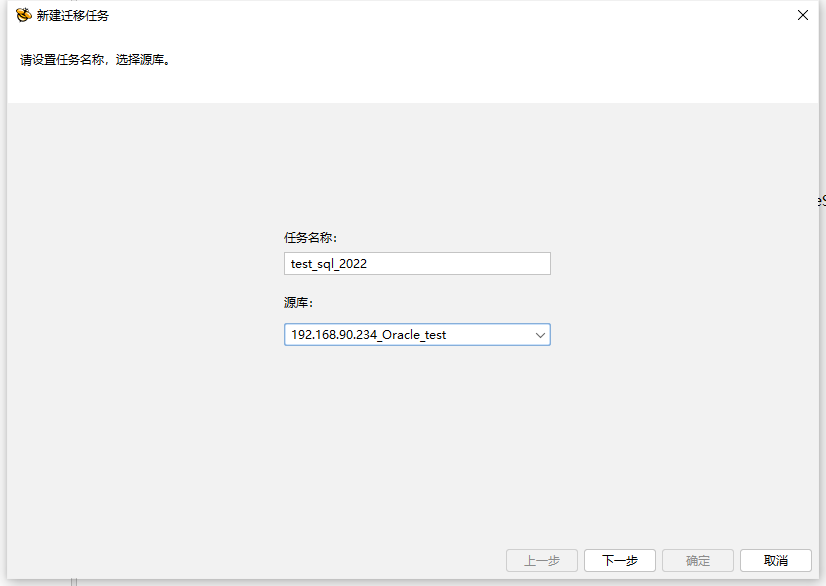
在工作中配置迁移工作计划,命名迁移工作名称,在源库和目标库的下拉菜单中选择相应的数据库,点击下一步进入第二页。
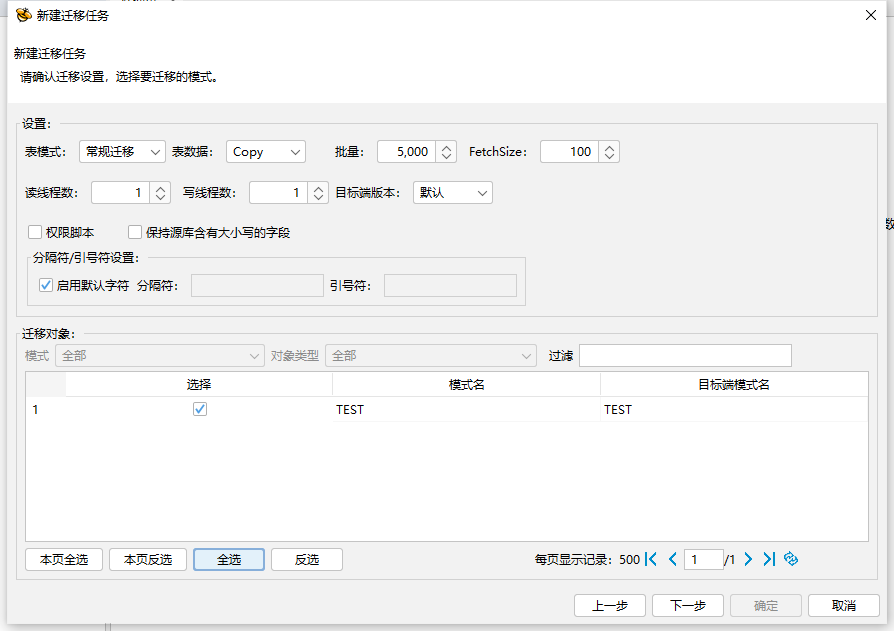
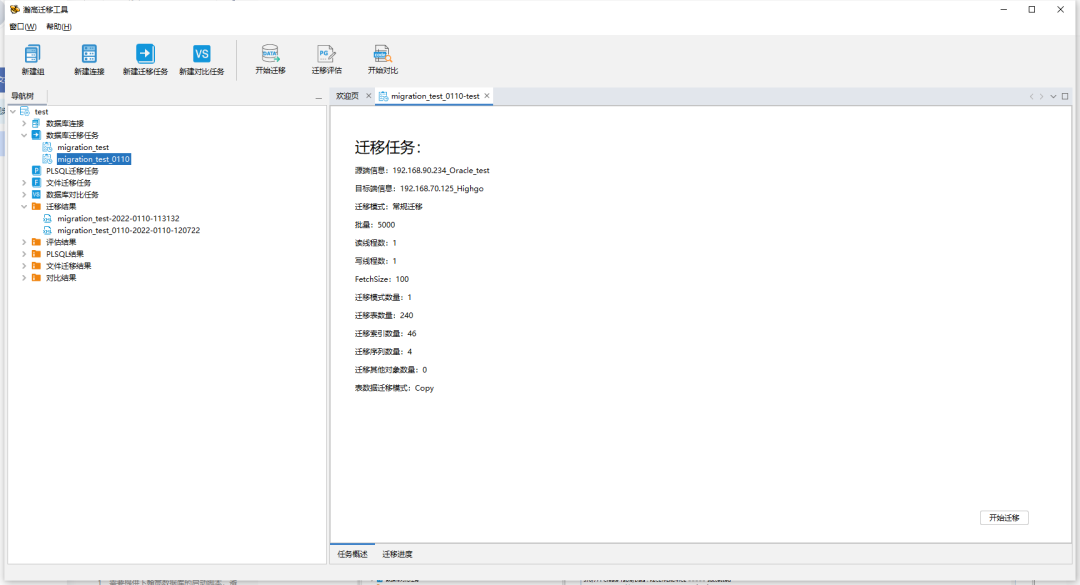
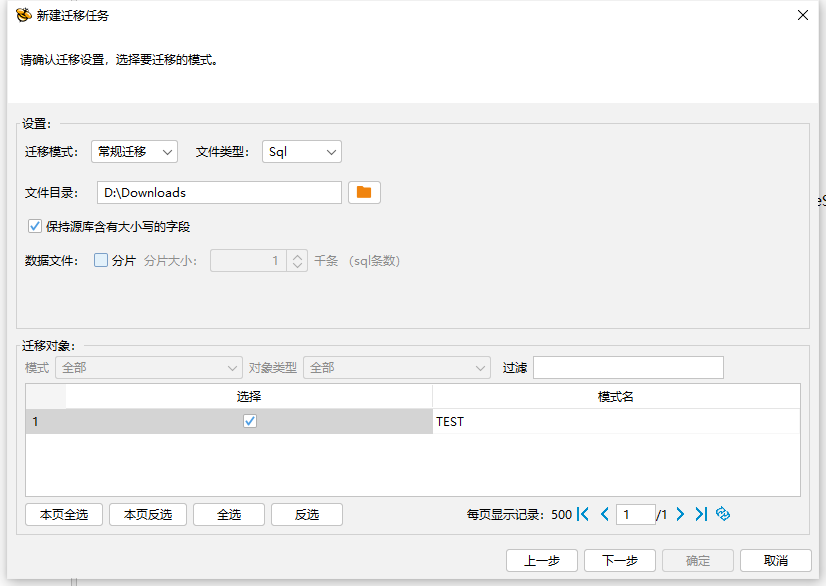
新建迁移任务中设置迁移模式,上半部分为迁移设置,下半部分为迁移对象模式选择。
"表模式"是迁移时表模式的设置,分为常规迁移,只迁移表结构,只迁移表数据,只迁移表约束。
"表数据"是迁移时表数据的设置,分为 Copy 模式、Bulkload模式、Sqlldr模式、Insert模式。(Bulkload模式需要数据库安装并启用相应插件,Sqlldr模式为HIGHGO数据库特有)
"批量"是迁移数据时一次执行的最大行数;
"FetchSize"是迁移数据时读取数据的FetchSize设置;
"读线程数"是迁移数据时读取数据同时运行的最大线程数 ;
"写线程数"是迁移数据时单个读线程对应的写入数据同时运行的最大线程数;
"权限脚本"为是否生成权限脚本;
"保持源库含有大小写的字段"为在迁移过程中是否保持源库含有大小写的字段;
保持源库含有大小写的字段选项,默认为不勾选,源库含有的大小写字段迁移到目标 库默认都转换为小写字段,勾选后源库含有的带有大小写的字段迁移到目标库后源库 的大小写字段会保留(例如,在源库中表名为 Aa,如果不勾选此选项迁移后就会变为 aa,勾选此选项之后迁移到目标库会保持与源库一致为 Aa;);
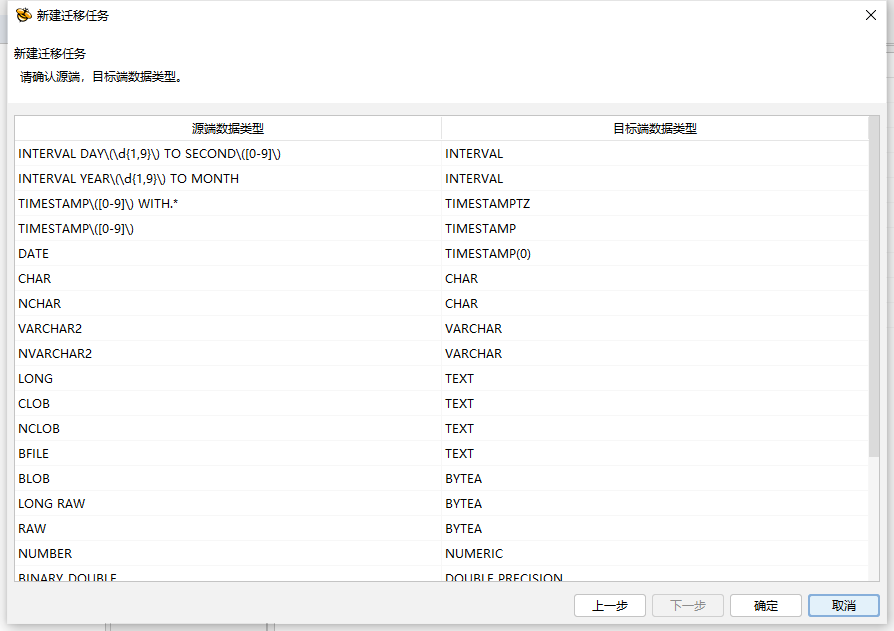
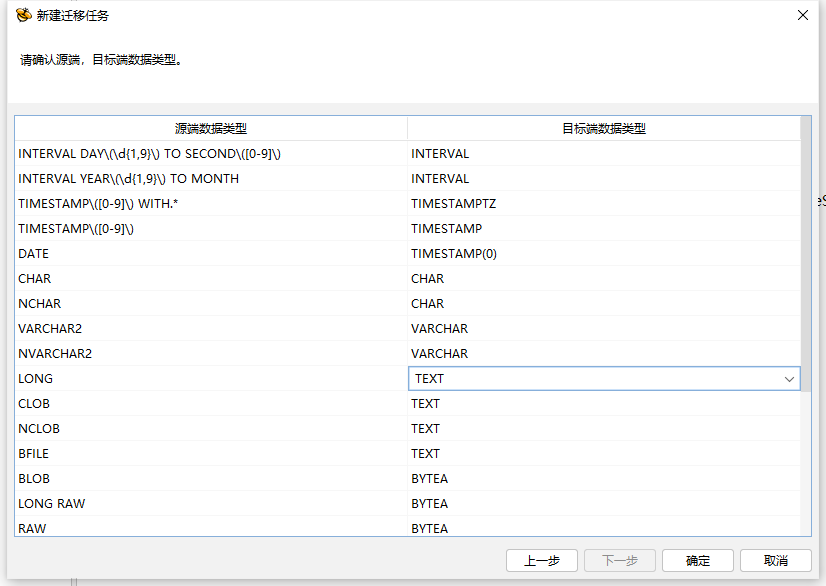
"目标端"目标端版本默认设置为"默认"选项,当源端为 Oracle,目标端为 HIGHGO 安全版 4.5 时会显示目标端的版本 ,并将目标端 HIGHGO 数据类型与已兼容的 Oracle 的数据类型进行匹配,将匹配最合适的数据类型在数据类型转换中进行展示,也可以手动将目标端版本设置为默认,这样不会将已兼容的 Oracle 的数据类型进行匹配。“
启用默认字符"如果不启用默认字符,则使用手动填写的分隔符和引号符,可使用十六进制填写;默认分隔符为“\u001e”,默认引号符为“\u001f;
"迁移对象"可选择要迁移的模式。
设置完成后点击下一步就会跳转到第三页;如果此时为编辑状态,此时可点击确定保存编辑后的迁移任务。
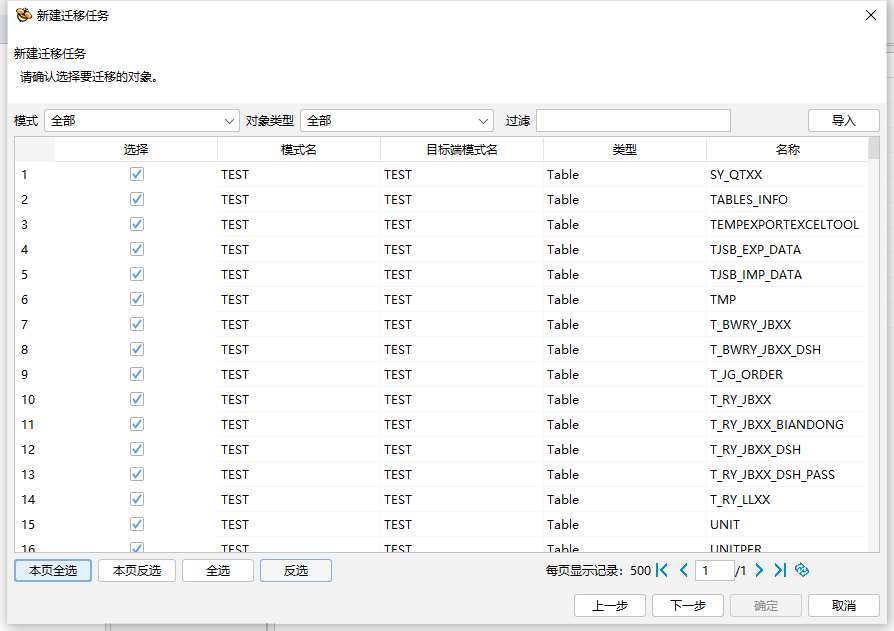
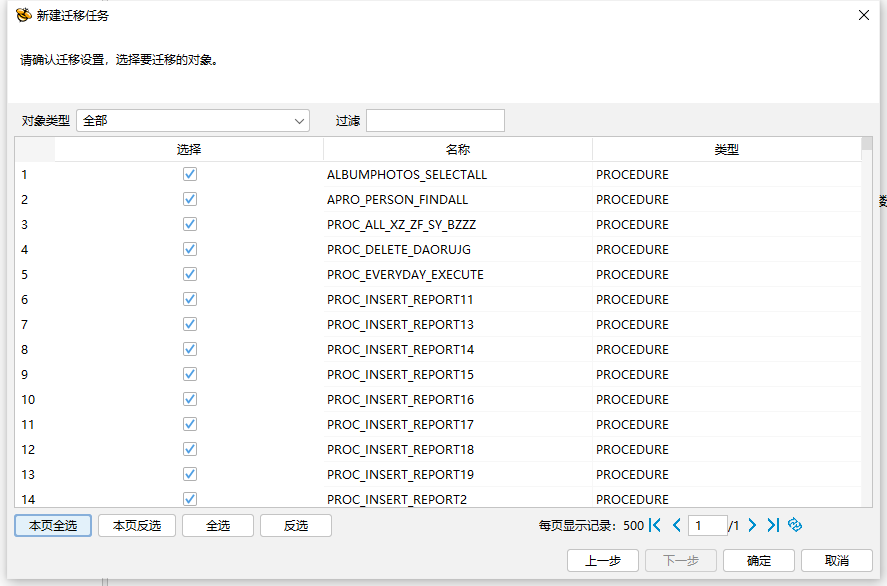
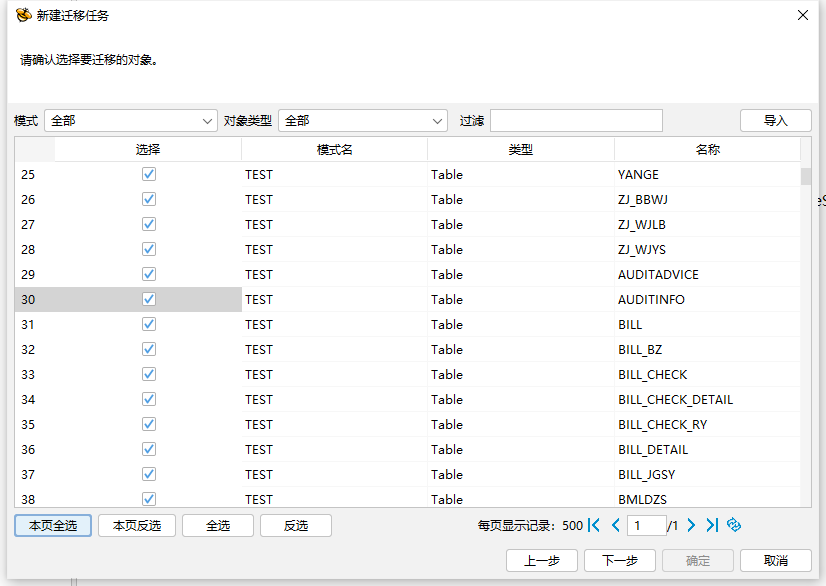
新建迁移任务选择要迁移的对象,可以根据实际需要迁移的对象情况进行选择
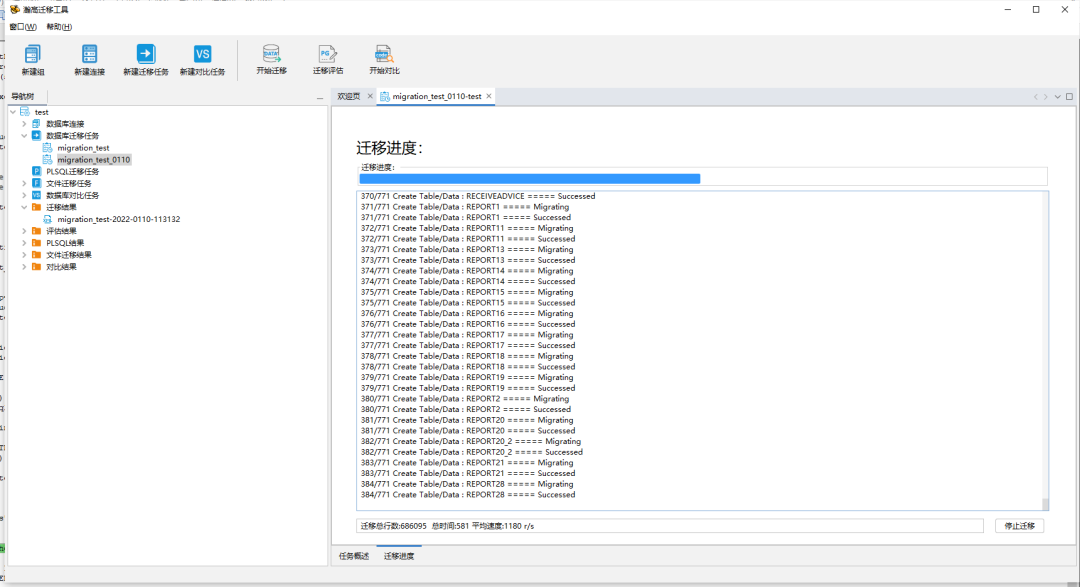
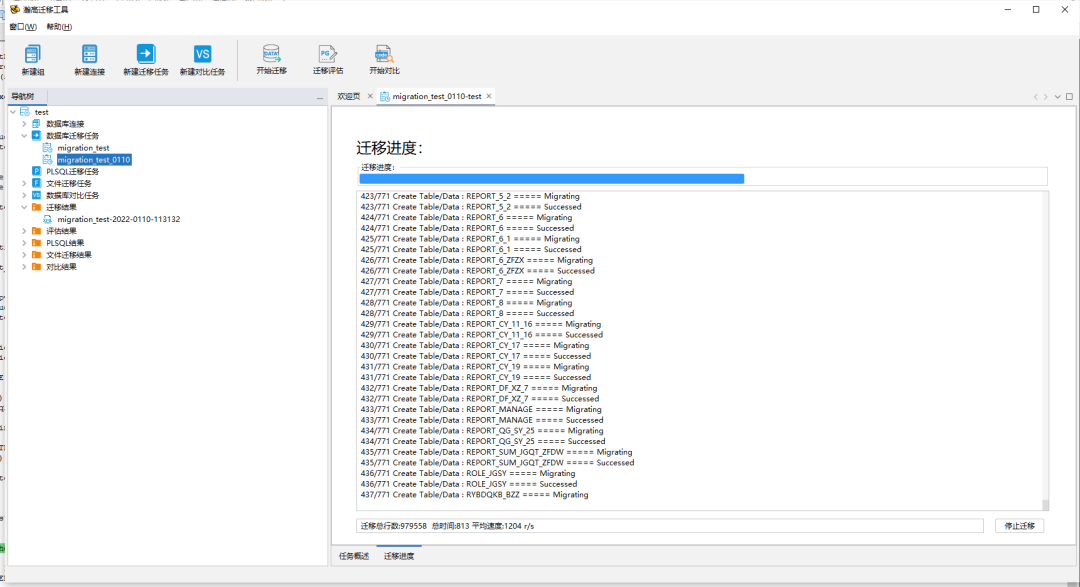
点选数据库迁移任务中的相应迁移任务,点击“开始迁移”。
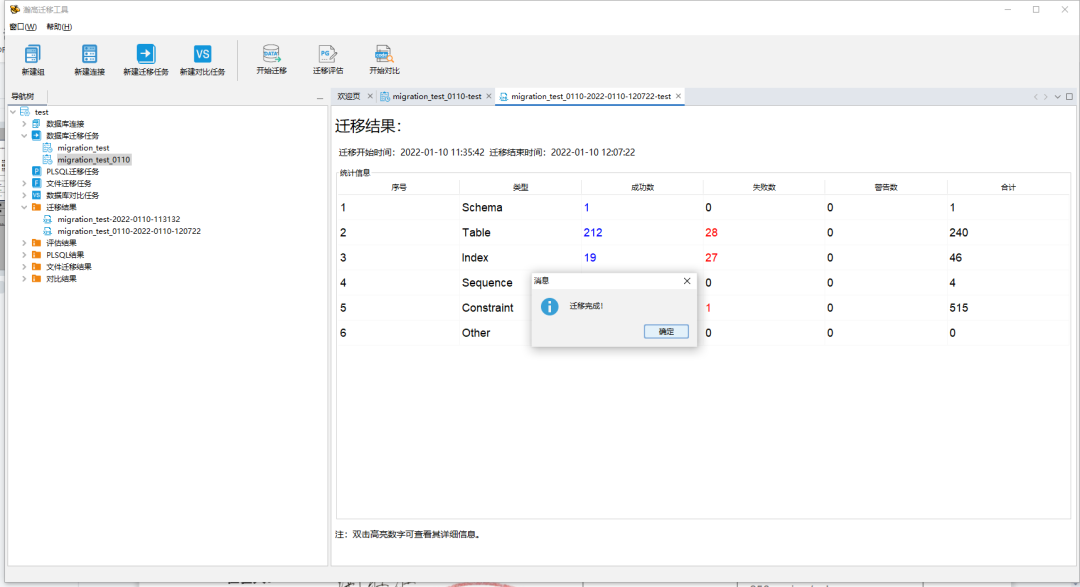
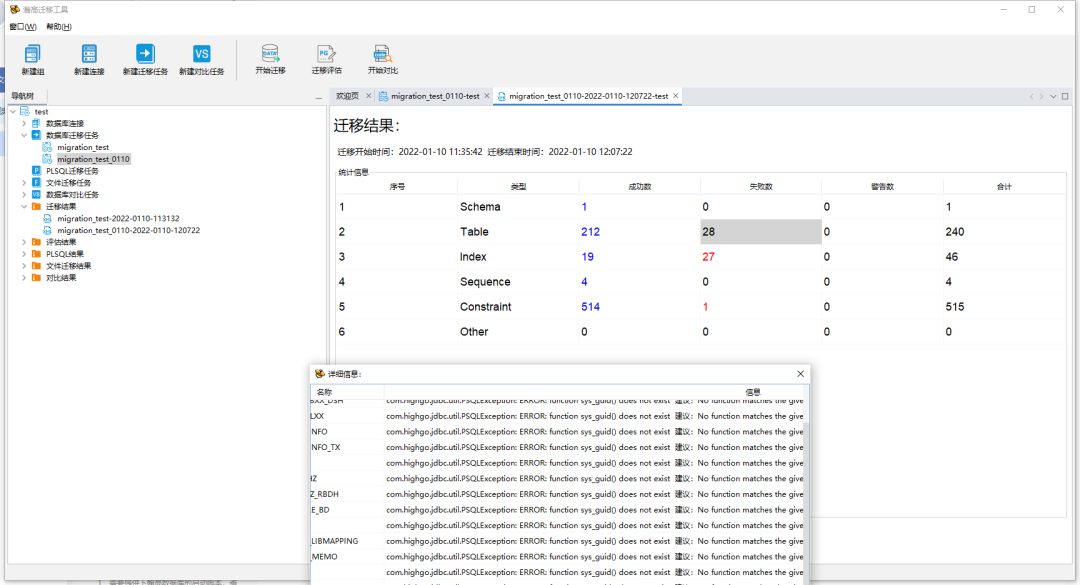
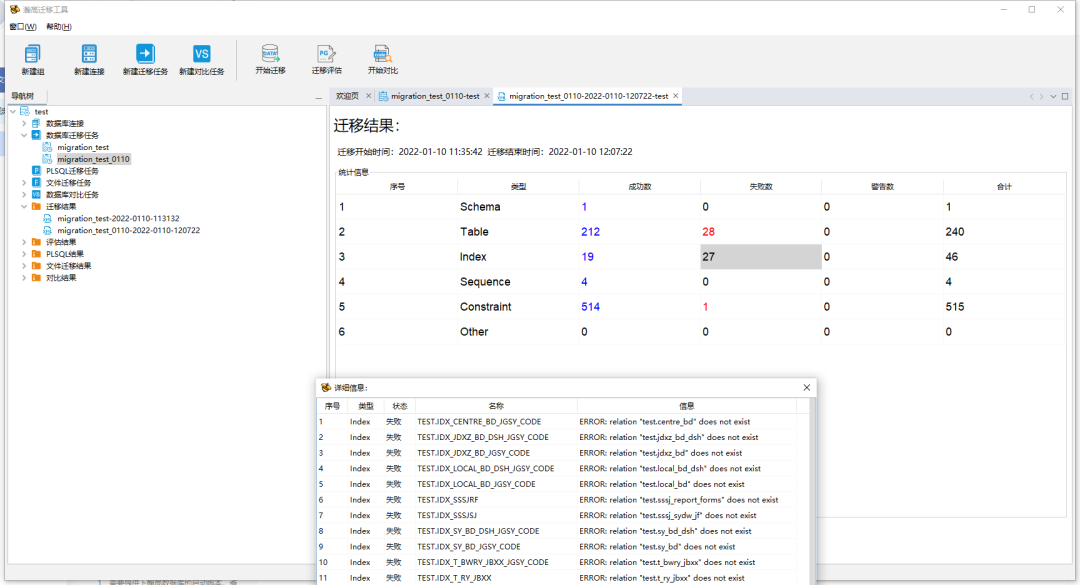
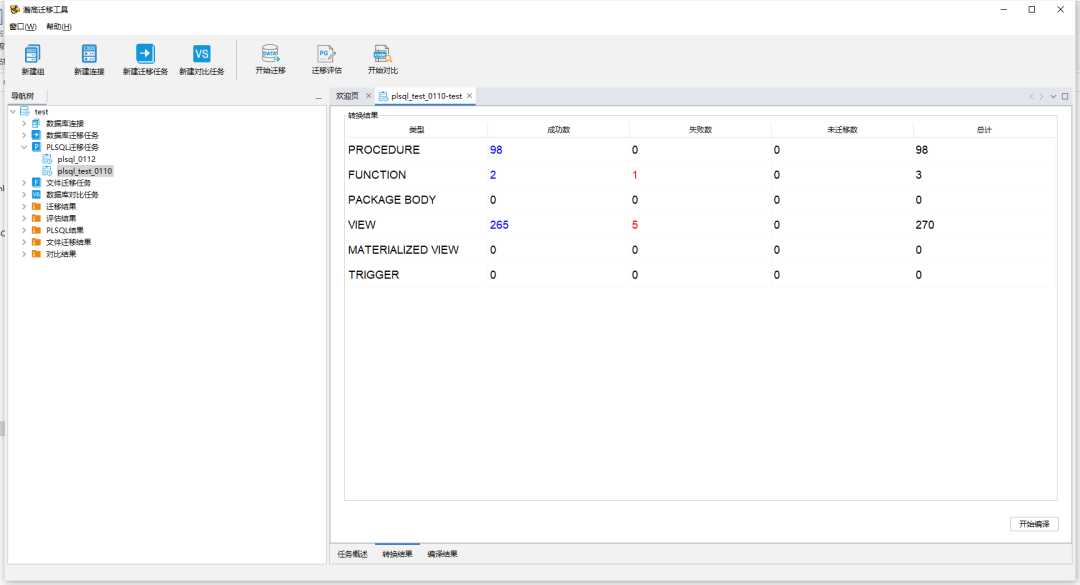
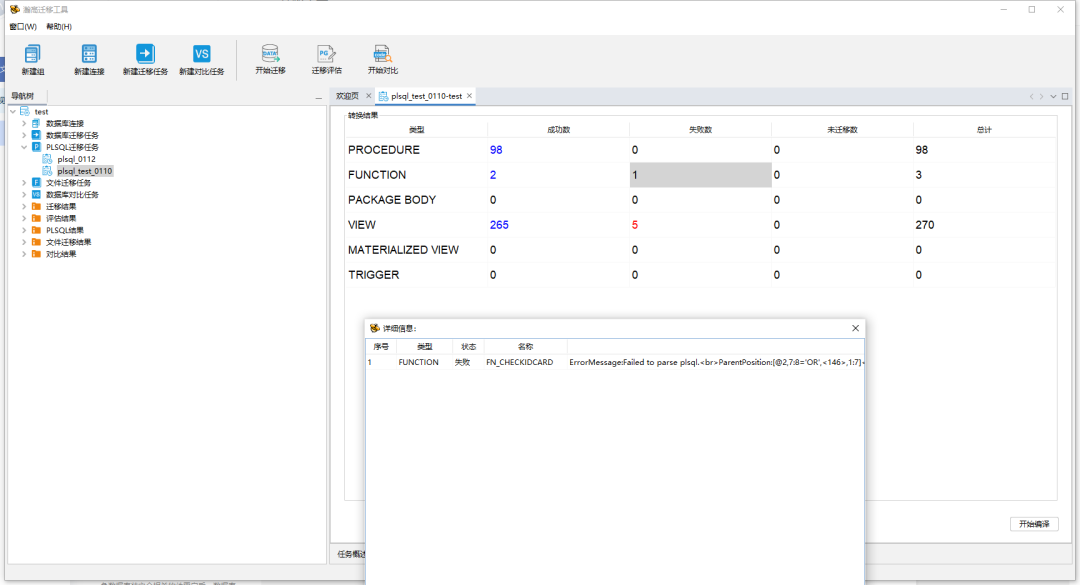
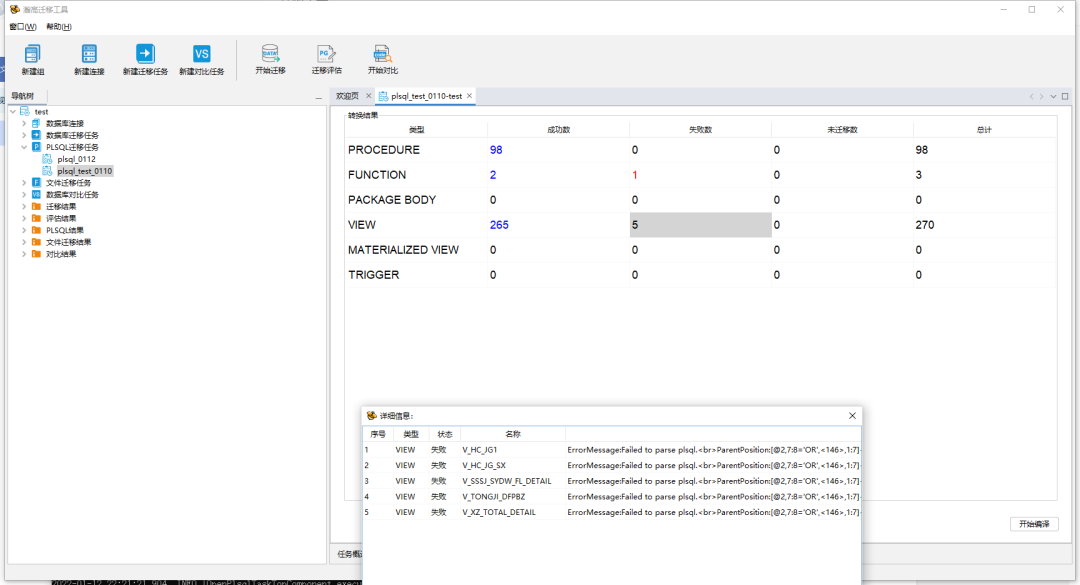
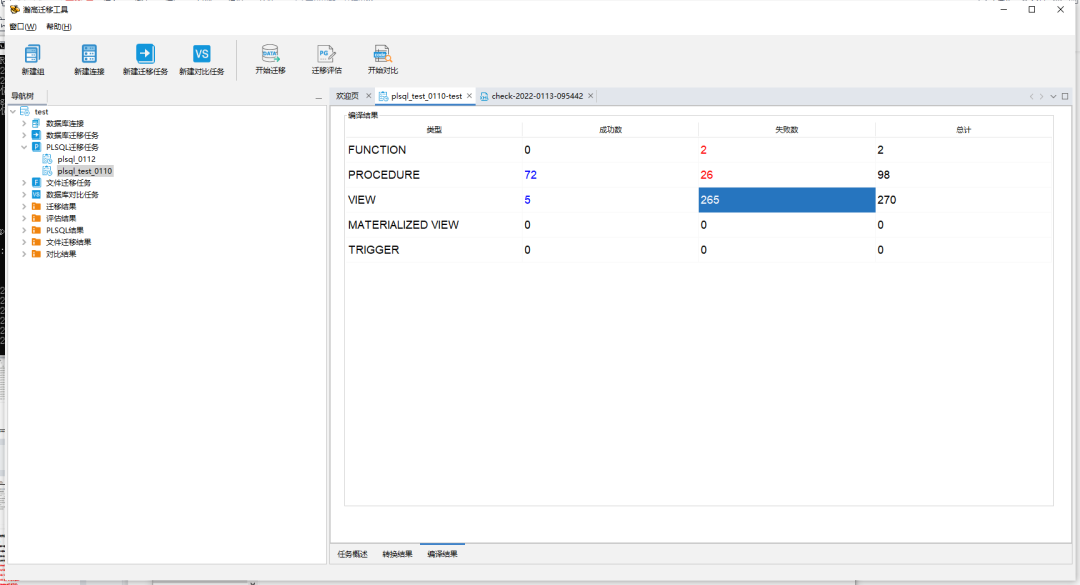
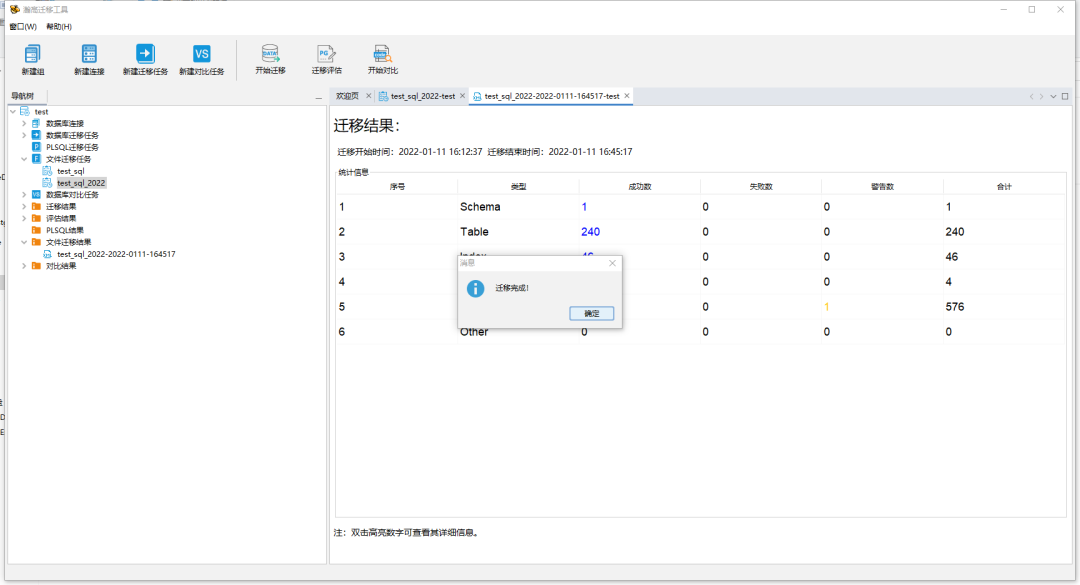
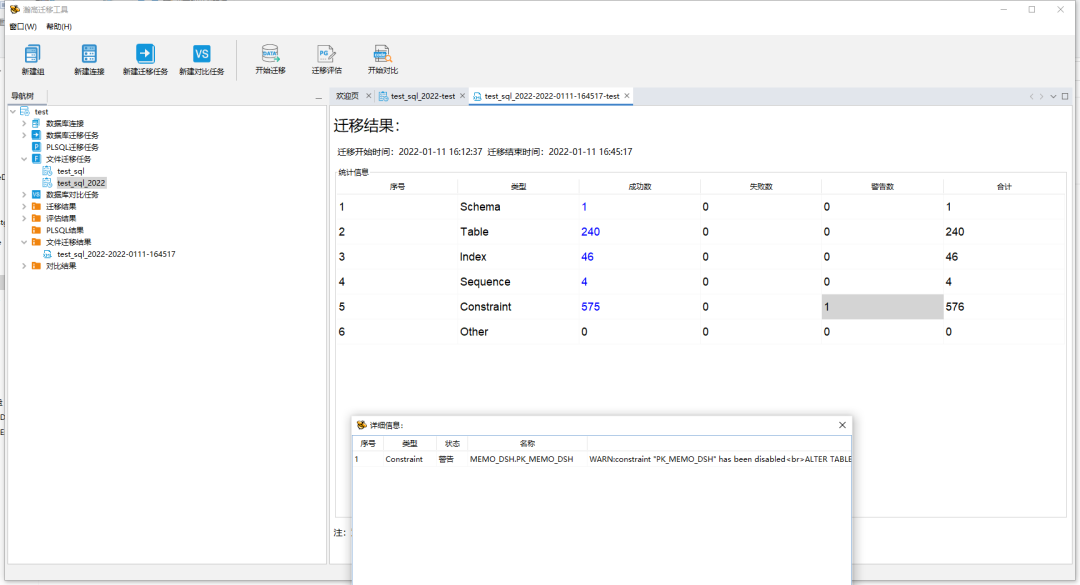
迁移完成后可以通过迁移结果中的展示内容查看具体成功、失败的数据并点击查看细节。
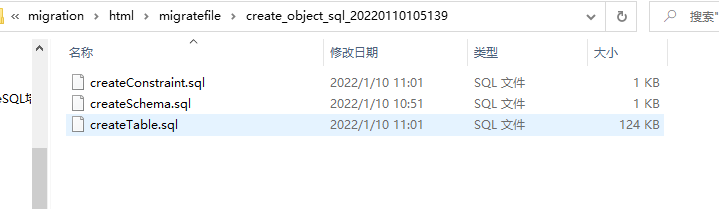
所有对象迁移时,目标库中执行的创建SQL语句都会输出到当前..\html\migratefile\create_object_sql_yyyymmddhhmmss文件夹中对应对象的文件中,用户的创建的sql语句的文件名为createSchema.sql、表的创建的sql语句的文件名为createTable.sql、约束的创建的 sql 语句的文件名为 createConstraint.sql、索引的创建的sql语句的文件名为createIndex.sql、序列的创建的sql语句的文件名为createSequence.sql、其他对象的创建的 sql 语句的文件名为 createOther.sql。如下图:
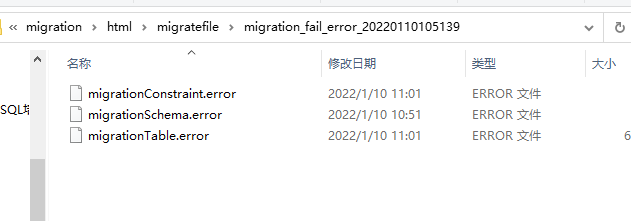
所有对象迁移时,失败的对象的完整的错误信息都会输出到..\ html\migratefile\migration_fail_error_yyyymmddhhmmss文件夹中对应对象的文件中,用户的失败错误信息的文件名为migrationSchema.error、表的失败错误信息的文件名为migrationTable.error、约束的失败错误信息的文件名为migrationConstraint.error、索引的失败错误信息的文件名为migrationIndex.error、序列的失败错误信息的文件名为 migrationSequence.error、其他对象的失败错误信息的文件名为 migrationOther.error。如下图:
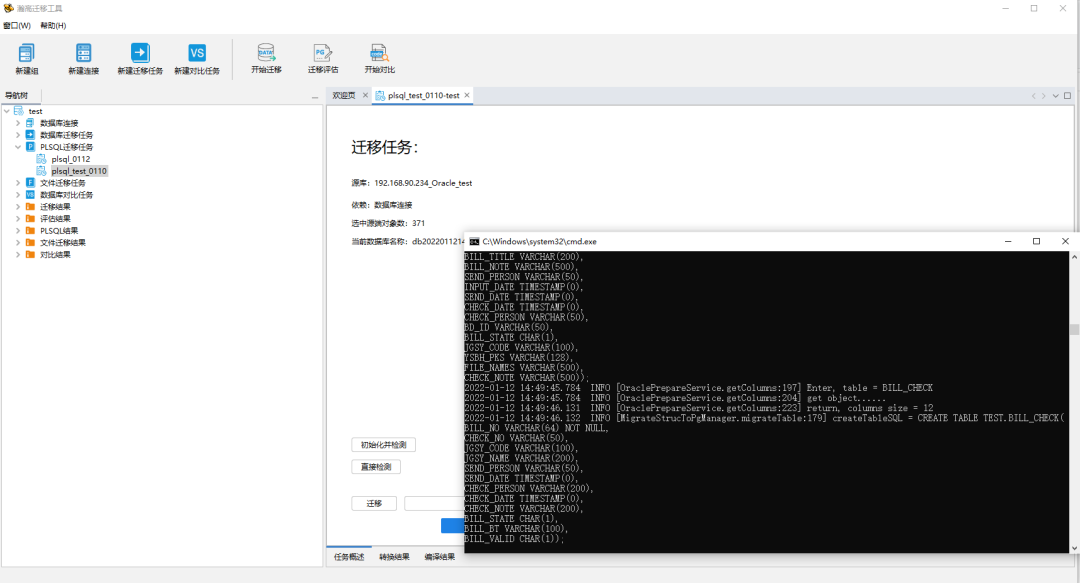
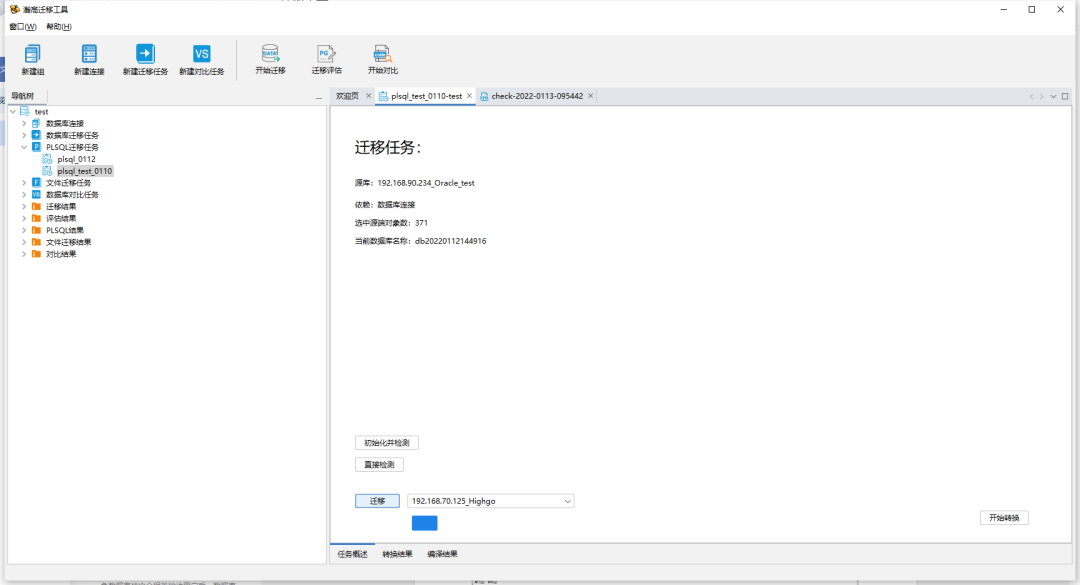
新建PLSQL迁移任务,填写任务名称,选择关联的源库或者选择关联的迁移任务,点击下一步。
当前数据库名称为当前迁移任务所使用的数据库名称,通过操作不同的数据库,来保证 Plsql 执行互不干扰。
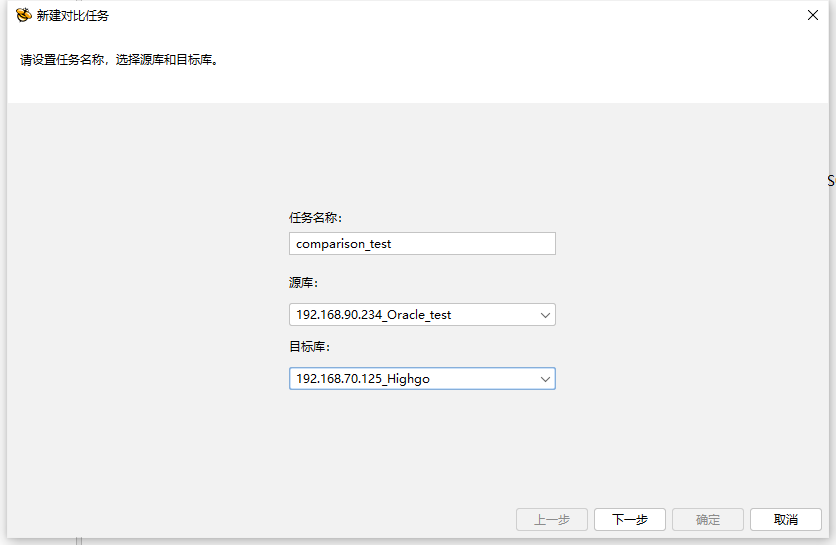
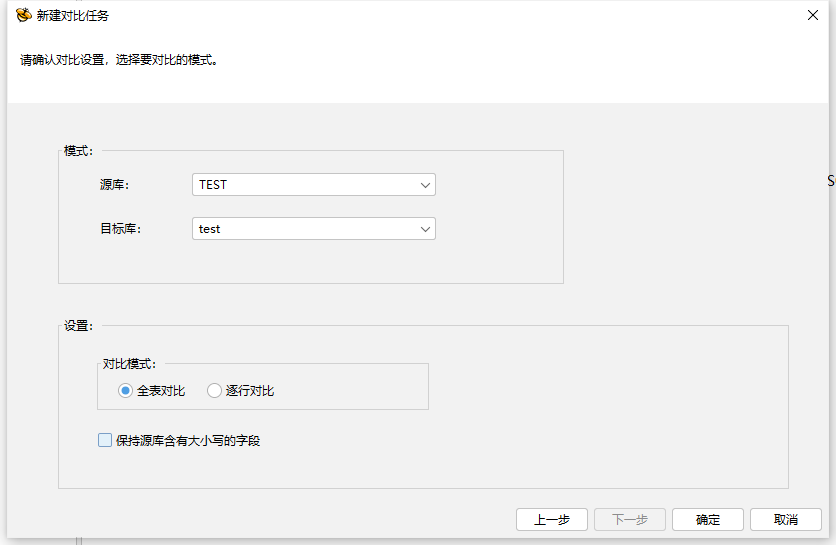
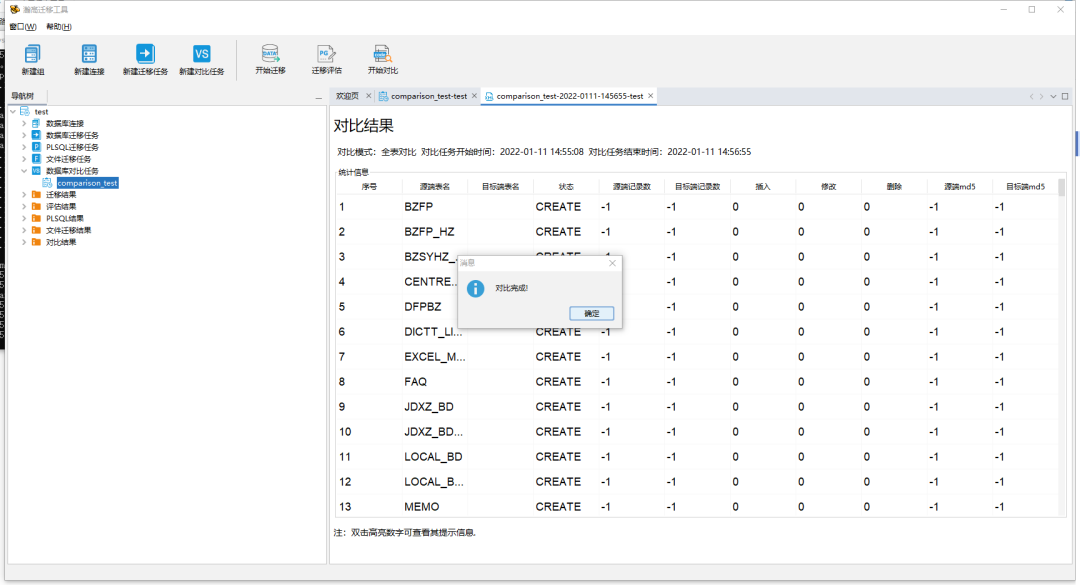
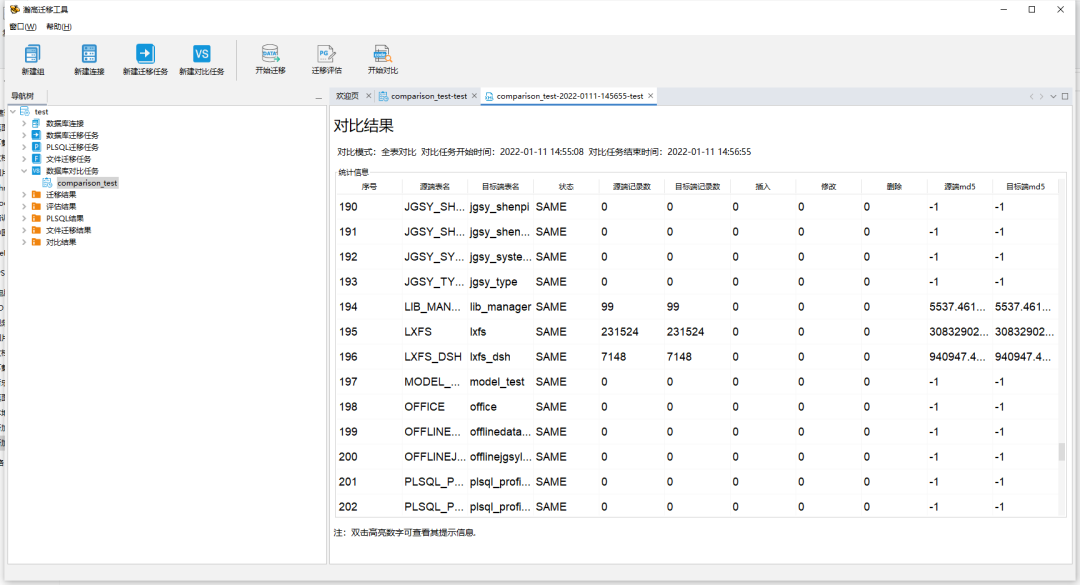
在工作组中新建数据对比任务,命名对比工作名称,在源库和目标库的下拉菜单中选择相应的源端与目标端数据库。
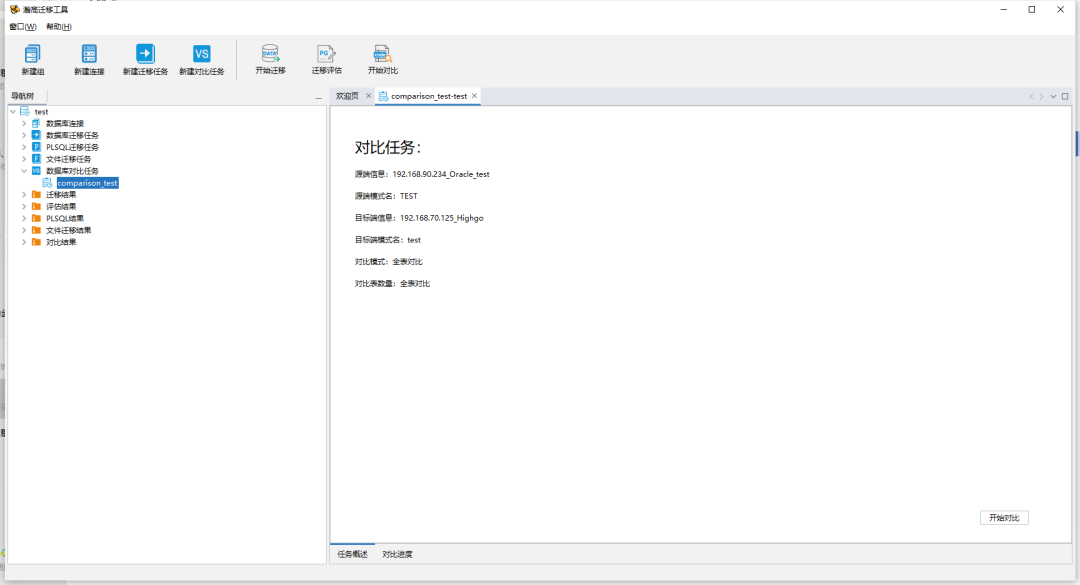
设置对比任务内容,完成设置源端与目标端的模式并设置,对比模式可以选择全表对比或者逐行对比,点击确定后生成对比任务
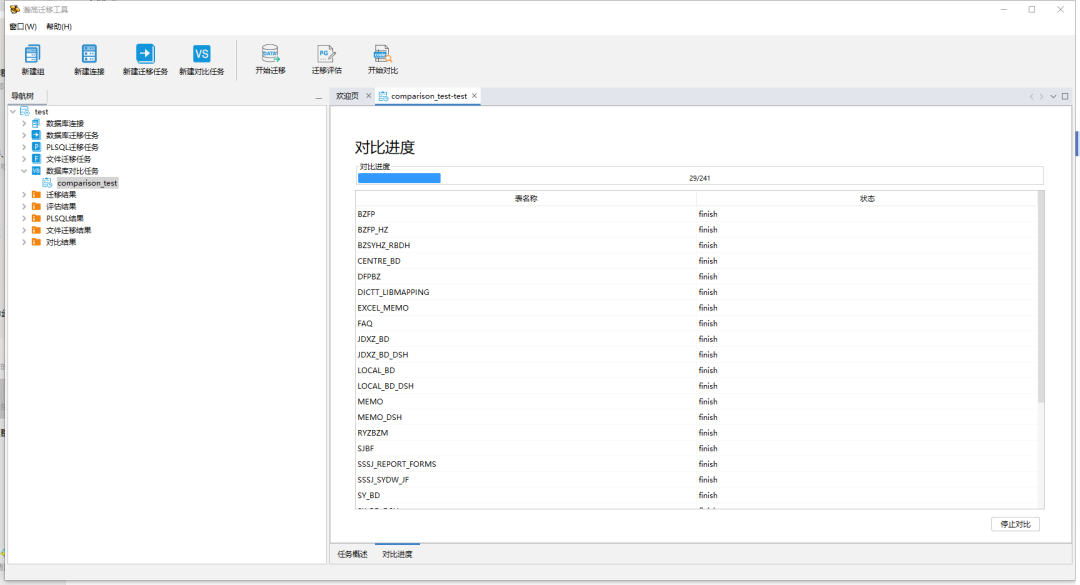
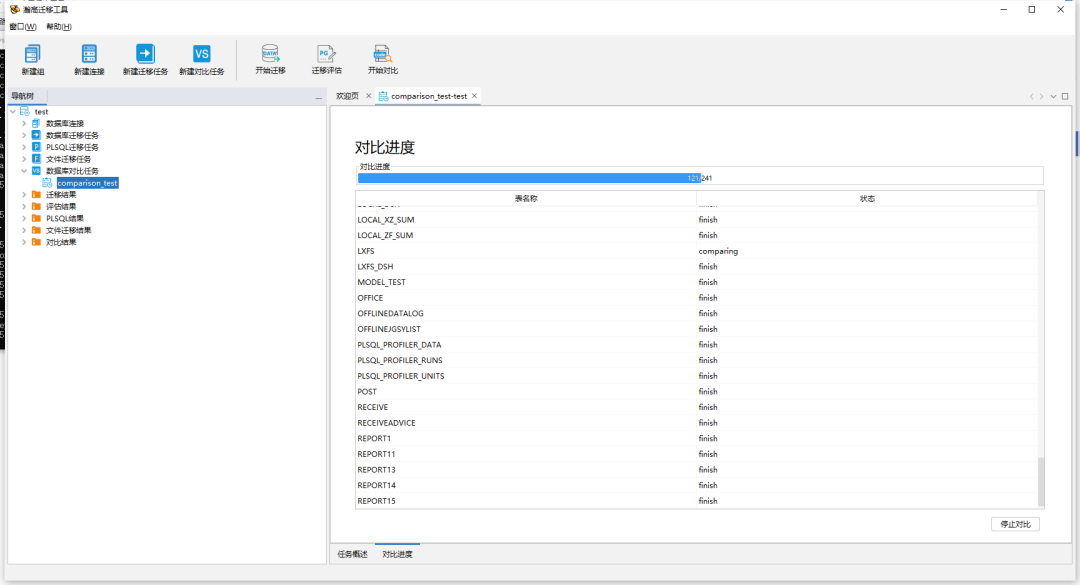
在数据对比任务中选择相应的数据对比任务,开始进行数据对比
使用此功能可实现Oracle、MySQL、SQL Server、DB2、KingbaseV7、KingbaseV8、DM7、DM8、HIGHGO的源端数据库到HIGHGO、PostgreSQL的目标端数据库的数据迁移,支持静态(离线)数据迁移,支持自主选择是否 保留源库中含有的大小写字段,并做到对用户、表、索引、序列、约束的支持,迁移结果支持SQL脚本(支持的数据库及版本:ORACLE支持11g;MySQL支持v5.5及以上;SQL Server支持2012、2008、2005;DB2 支持v11、v9.7、v9.5;KingbaseV7支持V7;KingbaseV8支持V8;DM7支持7;DM8支持8;HIGHGO支持v4.5.6)。
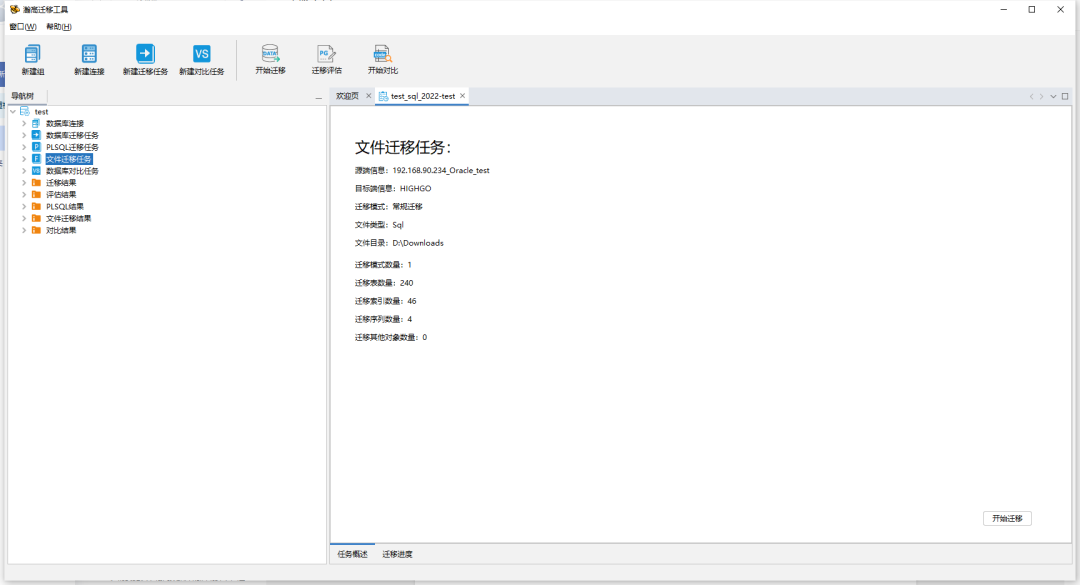
新建文件迁移任务,命名任务名称,在源库下拉菜单中选择相应的源库,设置完成后点击下一步。
进行文件迁移任务设置,对迁移模式、迁移类型与落地文件存放目录地址、是否保持源库含有大小写的字段、对数据文件是否进行分片保存及分片大小设置,并对迁移对象模式进行选择。
选择迁移对象,可以根据需求针对列表内容选择需要进行文件迁移的对象。
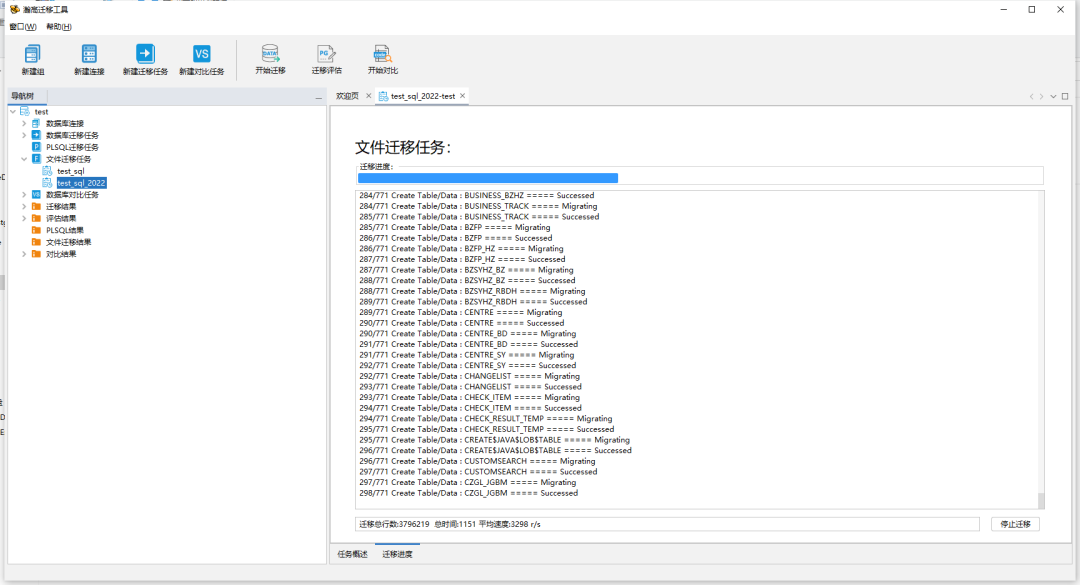
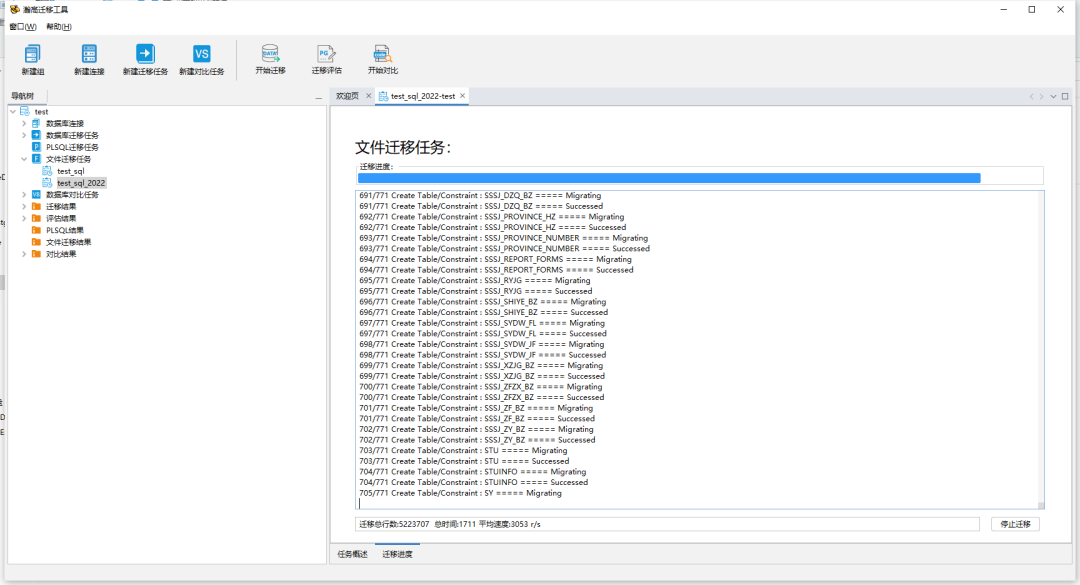
在文件迁移任务中选择相应的任务,点击“开始迁移”按钮开始文件迁移。
文件迁移结束,与直接迁移类似,可以通过迁移结果中的展示内容查看具体成功、失败的数据并点击查看细节。
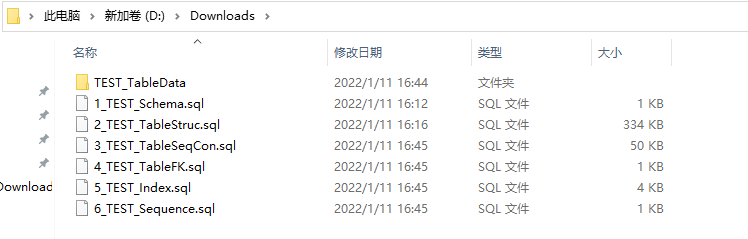
迁移完成时会根据任务配置时文件目录的地址生成具体的落地文件,此次设置的落地文件目录路径为D:\Downloads,表数据将会单独生成到该路径的 TableData 目录下,如下图中的TEST_TableData文件夹目录,默认情况下每张表会生成一个文件,选择分区时,将按分区大小生成多个文件,文件后缀序号自动增加可以根据实际需求导入目标数据库。
以上是瀚高迁移工具的一些功能使用介绍,在迁移适配的实操作过程中除了可以根据迁移工具的指引文档来完成,也可以向瀚高数据库申请专职适配迁移工程师来配合完成迁移适配,这样就可以更快速的完成相应的适配迁移工作。