UTF8编码(Unicode Transformation Format)

UTF8编码(Unicode Transformation Format)
99%的前端写网页时都会加上<meta charset="utf-8">,99%的后端工程师新建数据库表时都会加上DEFAULT CHARSET=utf8(剩下的1%应该是忘了写)。
之所以我们想让UTF8一统天下,就是因为UTF8可以表示出世界上所有的文字!UTF8与前面说的GB系列编码不兼容,所以如果一个文件中即有UTF8编码的文字,又有GB18030编码的文字,那绝对会有乱码。
Unicode赋予了全世界所有文字和符号一个独一无二的数字编号,UTF8所做的事情就是把这个数字编号表示出来(即解决前文提到的第2件事情)。UTF8解决字符间分隔的方式是数二进制中最高位连续1的个数来决定这个字是几字节编码。0开头的属于单字节,和ASCII码重合,做到了兼容。
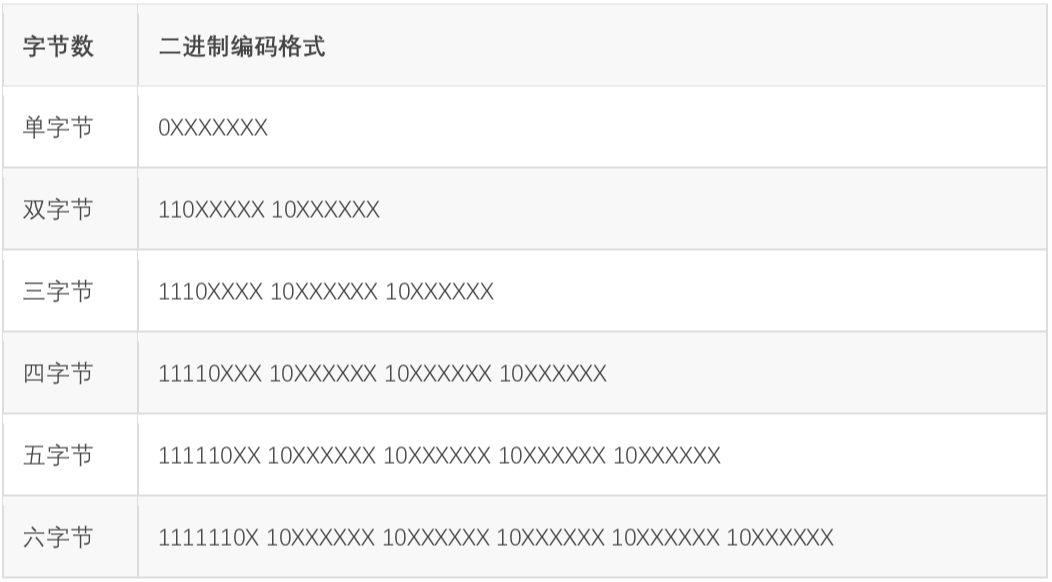
以三字节为例,开头第一个字节的”1110”,有连续三个1,说明包括本字节在内,接下来三个字节一起构成了一个文字。凡是不属于文字首字节的byte都以“10”开头,上表中标注X的位置才是真正用来表示Unicode数值的。
这种巧妙设计,把Unicode的数值和每个字的字节数融合在一起,最坏情况是6个字节表示一个字,已经足够表示世界上所有语言的所有文字了。不过从这种表示方式也可以很显然地看出来,UTF8和GBK没有任何关系,除了都兼容ASCII以外。

举例说明,中文“鹅”字,Unicode十进制值为40517(16进制为9E45,2进制为1001 1110 0100 0101)。这个2进制值长度为12位,查询上面表格发现,二字节不够表示,四字节太长,三字节刚好,因此可以表示为 11101001 10111001 10000101,换算为16进制即E9B985,这就是“鹅”字的UTF8编码,占3字节。另外,经查询,“鹅”的GBK编码为B6EC,和UTF8的值完全不相干。
对于中文汉字来说,所有常用汉字的Unicode值都可以用3字节的UTF8表示出来,而GBK编码的汉字基本是2字节(GB18030虽4字节但是日常没人会写那些字)。这也就导致了,如果把GBK编码的中文文本另存为UTF8编码,体积会大50%左右。这也是UTF8的一点小瑕疵,存储同样的汉字,体积比GBK要大50%。
不过在“可表示世界上所有文字”这一巨大优势面前,UTF8的这点小瑕疵可以忽略了,所以日常开发中最常使用UTF8。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1448
- 银河麒麟打印带有图像的文档时出错 1365
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1151
- 统信桌面专业版【如何查询系统安装时间】 1073
- 统信操作系统各版本介绍 1070
- 统信桌面专业版【全盘安装UOS系统】介绍 1028
- 麒麟系统也能完整体验微信啦! 984
- 统信【启动盘制作工具】使用介绍 627
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 575
- 信刻全自动档案蓝光光盘检测一体机 483
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
