三分钟学习 | 熵编码

1. 概念
What?不知道什么是熵?那我们还是先看看熵的概念吧。
首先,熵的概念很早就有,在物理学,热力学中早有应用。
后来信息论中,Shannon他老人家发明了信息熵。
公式如下,它代表了信源S的熵:
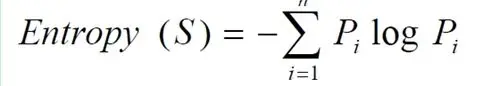
单位:Bit/字符
那信息熵到底是什么呢?它是信息量的度量单位。不要再去想什么不确定性了,抽象的让人想去抽它,就认为它是信息的多样性吧,它的实际意义有两个:
1. 信源S的平均信息量
2. 编码所有符号S平均所需要的位数
好了,无论你有没有看懂,我都要开始讲熵编码了。
为什么要编码? 编码的一个重要目的是压缩 (当然还有其他目的,比如加密)。举个例子就是把100MB的原始数据,压缩成10MB的数据,这个过程就需要编码。
那么怎么编码才能不失真呢?就是说解码后可以完全恢复原始数据。用信息熵来计算数据压缩的理论极限呀!
那什么是熵编码?在信息熵的极限范围内进行编码就是熵编码。例如信息熵算出来是3bit/字符,你用4bit/字符来编码,就是熵编码,你用2bit/字符来编码,就不叫熵编码,因为这种情况下,就失真了嘛。
从这里也看以看出,信源熵是编码这个信源平均所需要的最小位数。
所以,熵编码是无损压缩。
熵编码有很多种:
霍夫曼编码 (Huffman)
算术编码
行程编码 (RLE)
基于上下文的自适应变长编码(CAVLC)
基于上下文的自适应二进制算术编码(CABAC)
2. 应用举例
熵编码一个很重要的应用领域就是图像压缩。
下面是JPEG的编码流程。蓝色框中的编码就是用了熵编码。
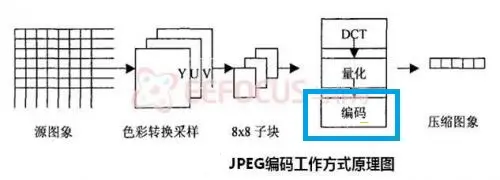
至于其他的视频标准,如MPEG2,H264, H265,编码流程都是大同小异,过程无非都是采样-DCT-量化-编码。
它们都会用到熵编码,例如JPEG用的是Huffman编码和算术编码,H264用的是CAVLC和CABAC。
3. 红猴子呓语
为什么要有这么多的编码标准呢?又是Huffman,又是CABAC,又是有损,又是无损,无非是斤斤计较的人类在寻求一种最优化的权衡罢了,既想拥有令人惊叹的压缩比,又不想失真,同时也想降低算法复杂度,让电脑在编码的时候可以快点再快点,编码后数据量小点再小点,最好还能再清楚点。
我也是晕了,这么多算法搞得眼花缭乱,不过别担心,小伙伴们,因为在工作中,你不用去自己写算法,它们多半是靠硬件来实现滴,比如有硬件熵编码器模块,你直接拿来就可以用了。 假如很不幸的,你要用软件来实现编码,也没关系,现成的代码模块,网上一堆一堆的。
所以,同学们,不用发愁你学不会这个复杂的算法,现实生活中,也很少会让你去计算什么信息熵,因为前辈们早已铺好道路了,你只需站在他们的肩膀上前行就好了。
但是!!做理论研究的同学,还是得好好学习,天天向上,因为你们需要为人类无止尽的优化事业添砖加瓦。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2959
- 【软件正版化】软件正版化工作要点 2878
- 统信UOS试玩黑神话:悟空 2843
- 信刻光盘安全隔离与信息交换系统 2737
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1271
- grub引导程序无法找到指定设备和分区 1235
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 165
- 点击报名 | 京东2025校招进校行程预告 164
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 163
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 159
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
