超图地理编码引擎:集地名地址资产管理和数据空间化于一体的强大引擎

但实际应用中,各类共性问题阻碍了地名地址服务的发展,包括:
地名地址数据多源异构,融合过程繁琐
POI变化复杂
用户检索条件各异,匹配困难
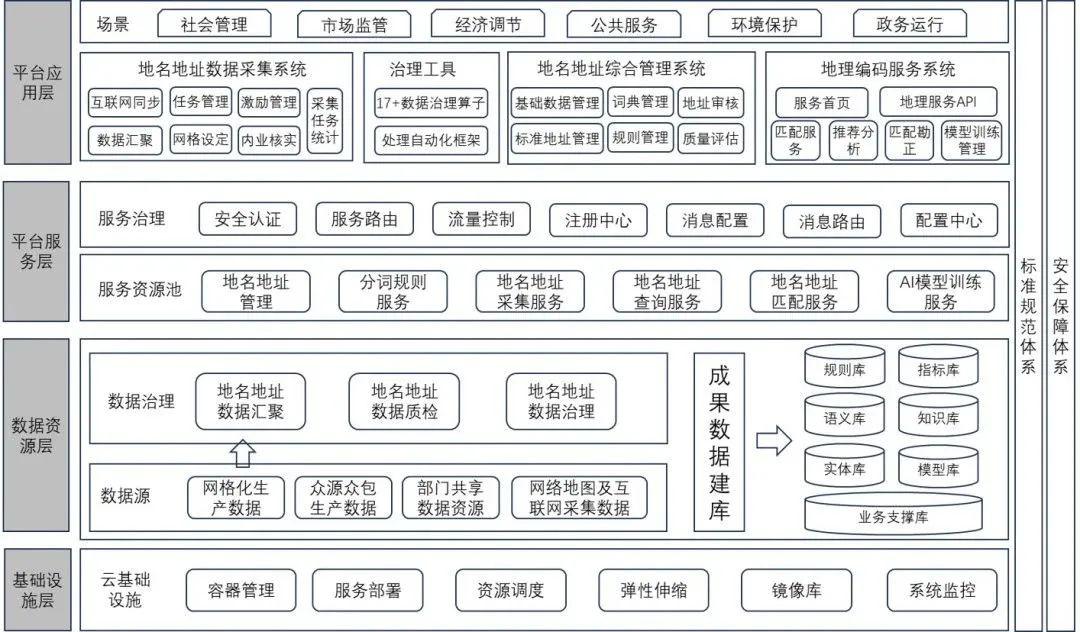
总体架构图

超图自定义数据标准
2.2地名地址的快速治理与融合
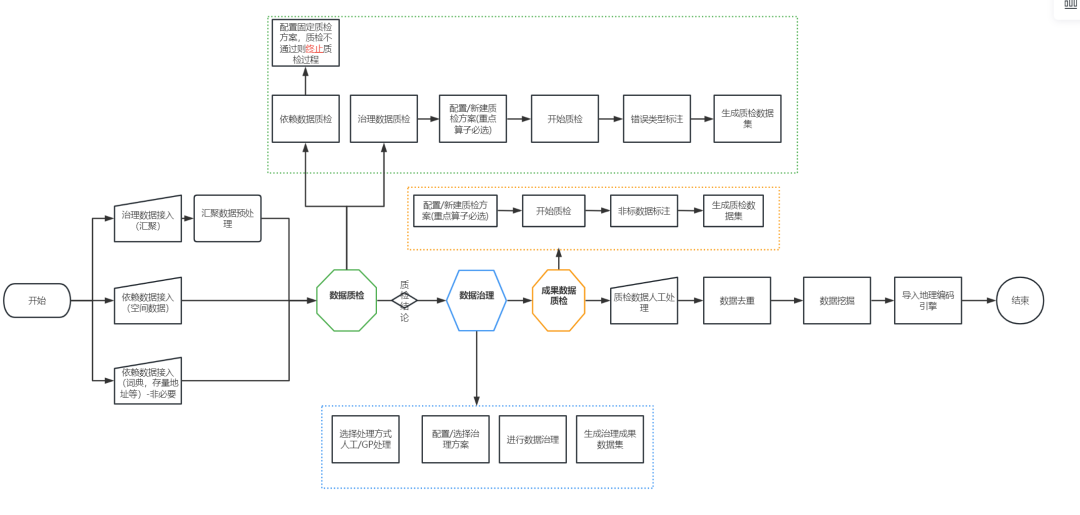
数据治理流程
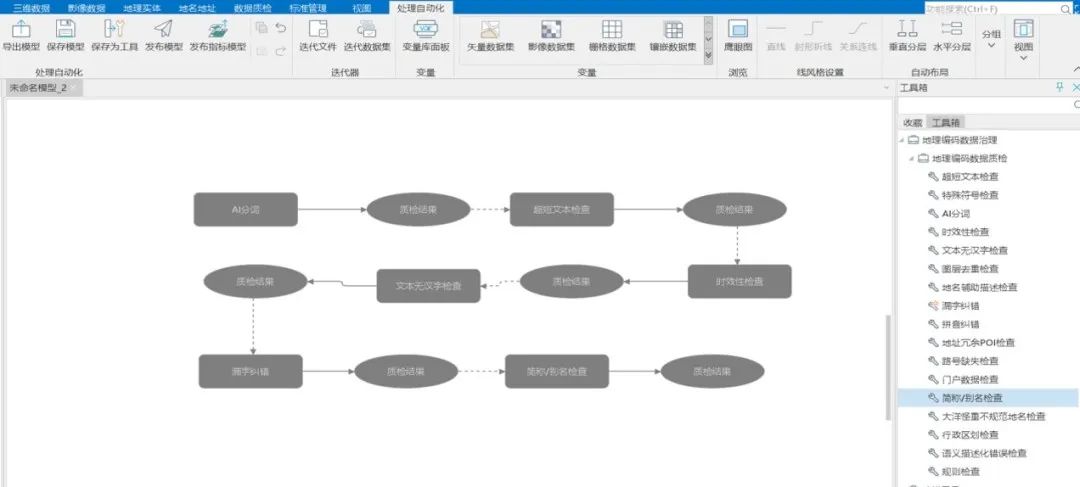
数据治理GPA算子自动化流程
-
AI分词算子: 使用AI分词算子对地址进行分词,为后续的质检/治理/去重过程提供基础输入 数据。
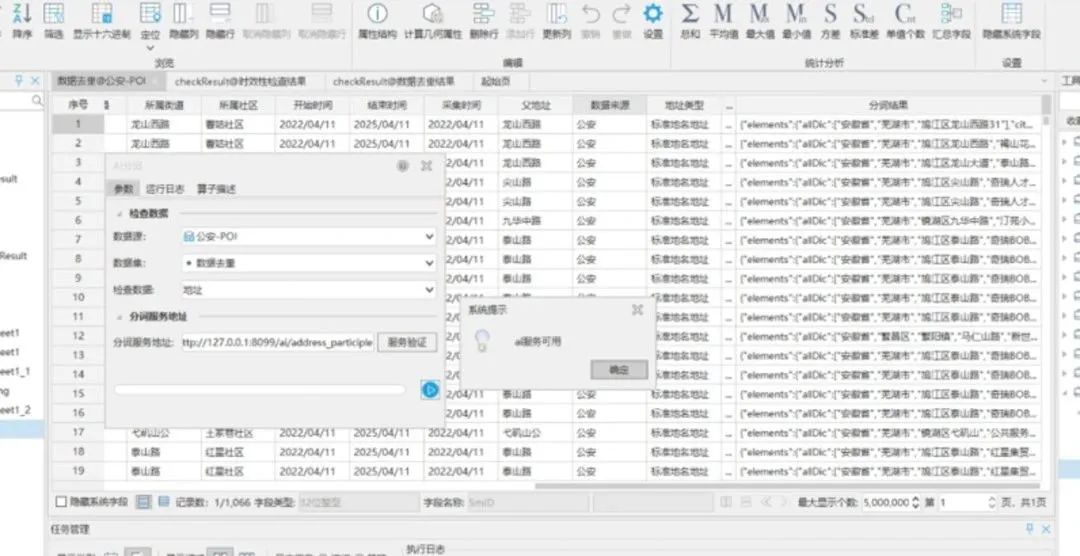
AI分词算子样例
-
数据去重算子: 使用数据去重算子可以很好的纠出多源异构数据在汇聚过程中产生的重复、相似的数据。
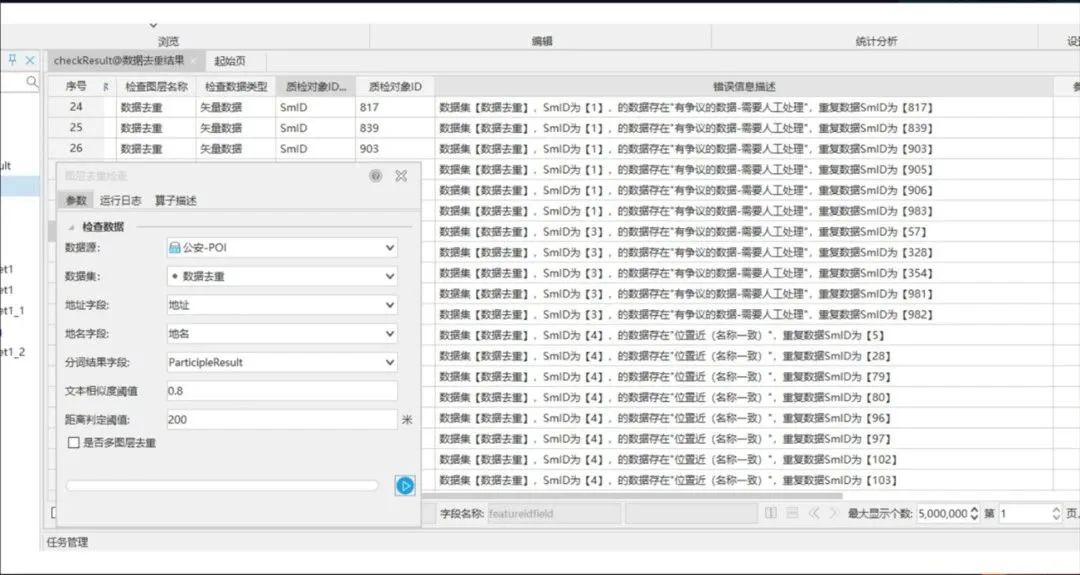
数据去重算子样例
-
时效检性检查算子: 支持筛选出时间属性错误的地址,实现历史地名地址数据的关联处理。
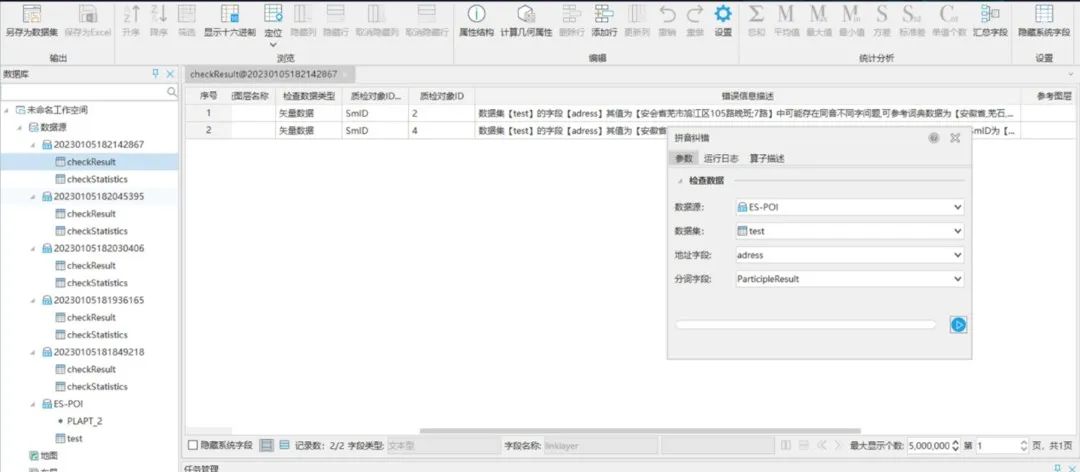
拼音纠错算子
-
拼音纠错检查算子:
该算子为数据纠错的算子的一种,主要可以通过拼音纠错算法找出同音不同字的错误地名地址。
2.3高效智能地名地址匹配
超图地理编码引擎的技术演进经历了文本处理、规则匹配、机器学习及深度学习等阶段,不断提升地名地址匹配的精度,优化匹配流程并丰富质检规则。
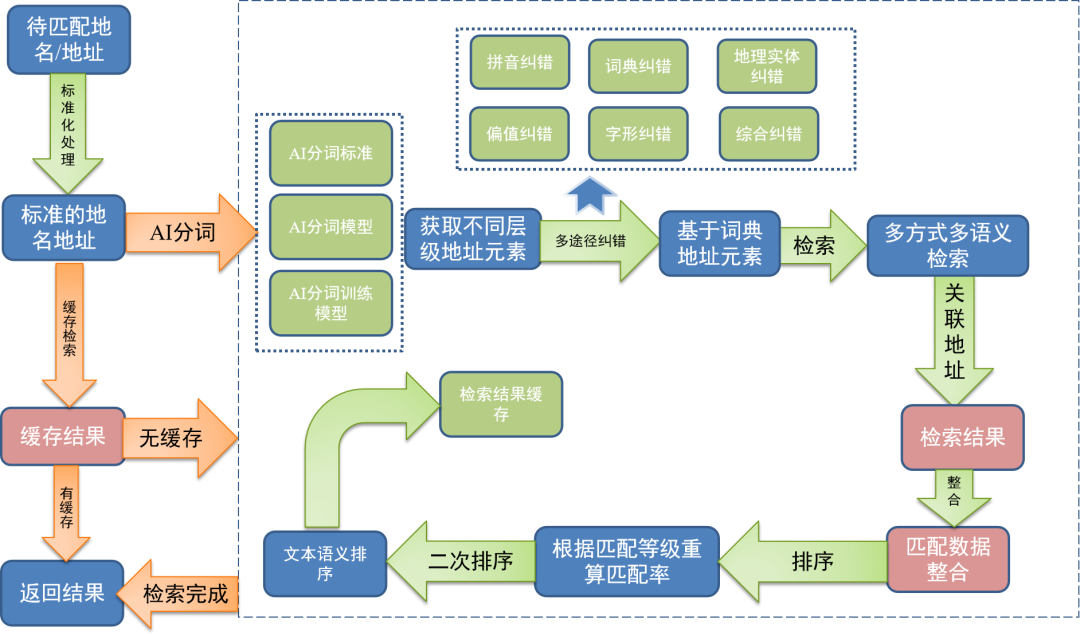
地名地址匹配流程

多维度纠错样例
在排序方面,超图地理编码引擎采用了文本相似度+地名地址相似度算法,能够完美地对检索结果进行排序,给出最优的检索解。并且支持区划检索和缓存检索等特性,可以在百万级大数据量实现多样、高效的检索。
2.4基础数据的语义化管理
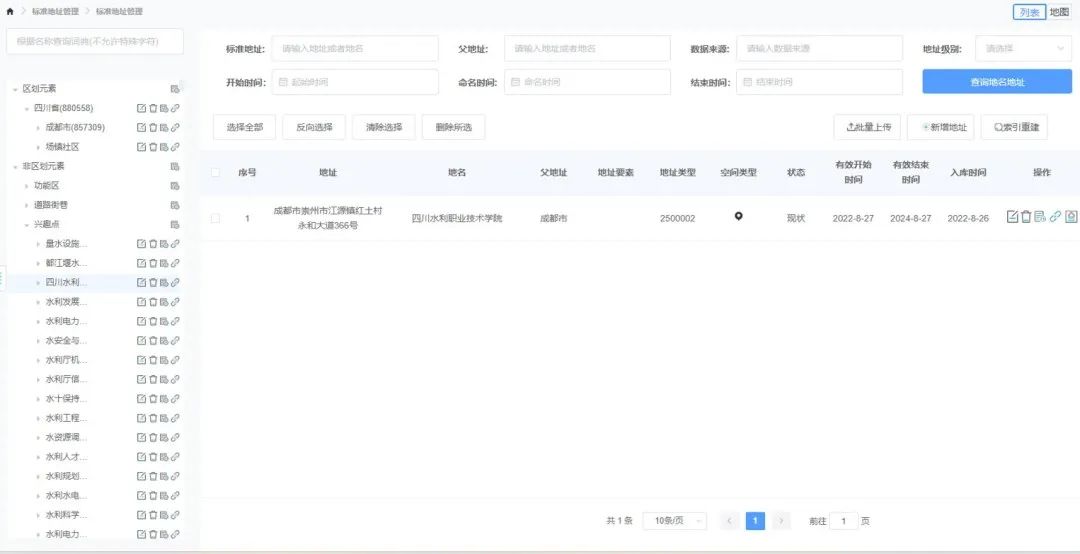
数据管理-列表
数据管理-地图
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2935
- 【软件正版化】软件正版化工作要点 2854
- 统信UOS试玩黑神话:悟空 2811
- 信刻光盘安全隔离与信息交换系统 2702
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1235
- grub引导程序无法找到指定设备和分区 1205
- 点击报名 | 京东2025校招进校行程预告 162
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 160
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 157
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 154
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
