openGauss数据导入导出
1、数据导入导出 - INSERT
⚫ 用户可以通过以下方式执行INSERT语句直接向openGauss数据库写入数据:
使用openGauss数据库提供的客户端工具向openGauss数据库写入数据。
通过JDBC/ODBC驱动连接数据库执行INSERT语句向openGauss数据库写入数据。
⚫ openGauss数据库支持完整的数据库事务级别的增删改操作。INSERT是最简单的一种数 据写入方式,这种方式适合数据写入量不大,并发度不高的场景。
2、数据导入导出 – COPY FROM STDIN
⚫ 用户可以使用以下方式通过COPY FROM STDIN语句直接向openGauss写入数据。
通过键盘输入向openGauss写入数据。通过COPY命令实现在表和文件之间拷贝数据。COPY FROM表示从一个文件拷贝数据到一个表,COPY TO表示把一个表的数据拷贝到一个文件。
◼ COPY FROM/TO适合低并发,本地小数据量导入导出。
通过JDBC驱动的CopyManager接口从文件或者数据库向openGauss写入数据。此方法支持 COPY语法中copy option的所有参数。
◼ CopyManager是 openGauss JDBC驱动中提供的一个API接口类,用于批量向openGauss中导入数据。
◼ CopyManager类位于org.postgresql.copy Package中,继承自java.lang.Object类。
⚫ COPY适用场景:
小数据量表以文本数据作为来源导入;
小数量表的导出;
查询结果集导出。
⚫ COPY使用方法:
文本数据导入;
copy t1 from '/data/input/t1.txt' delimiter '^';
表数据导出;
copy t1 to '/data/input/t1_output.txt' delimiter '^';
查询结果集导出;
copy (select * from t1 where a2=1) to '/data/input/t1_output.txt' delimiter '^';
3、数据导入导出 – gsql
⚫ openGauss的gsql工具提供了元命令\copy进行数据导入导出。
⚫ \copy元命令语法
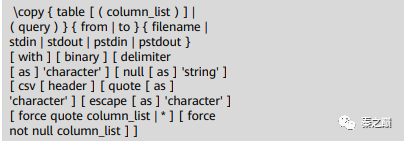
⚫ 说明:
在任何gsql客户端登录数据库成功后,可以使用该命令进行数据的导入/导出。但是与SQL的 COPY命令不同,该命令读取/写入的文件是本地文件,而非数据库服务器端文件;因此要操作 的文件的可访问性、权限等,都是受限于本地用户的权限。
4、数据导入导出 – gs_dump
⚫ openGauss提供的gs_dump和gs_dumpall工具,能够帮助用户导出需要的数据库对象或 其相关信息。通过导入工具将导出的数据信息导入至需要的数据库,可以完成数据库信 息的迁移。
gs_dump支持导出单个数据库或其内的对象,而gs_dumpall支持导出openGauss中所有 数据库或各库的公共全局对象。
gs_dump 参数说明:
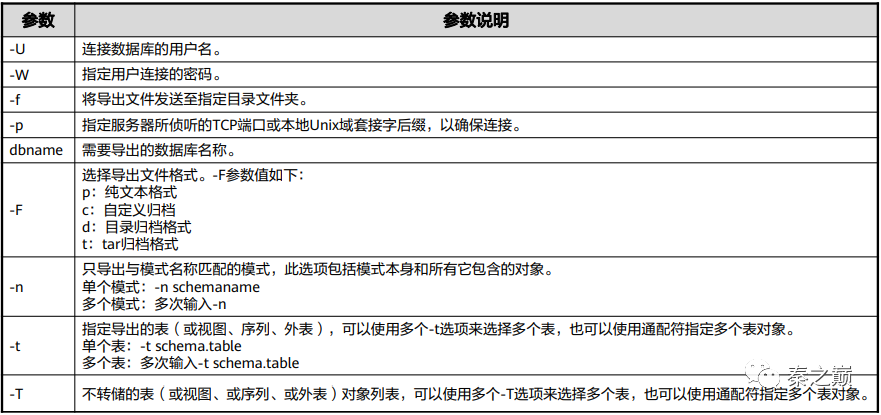
5、导出数据库
⚫ openGauss支持使用gs_dump工具导出某个数据库级的内容,包含数据库的数据和所有 对象定义。可根据需要自定义导出如下信息:
导出数据库全量信息,包含数据和所有对象定义。使用导出的全量信息可以创建一个与当前库 相同的数据库,且库中数据也与当前库相同。
仅导出所有对象定义,包括:库定义、函数定义、模式定义、表定义、索引定义和存储过程定 义等。使用导出的对象定义,可以快速创建一个相同的数据库,但是库中并无原数据库的数据。
仅导出数据,不包含所有对象定义。
⚫ 示例:使用gs_dump导出postgres数据库。
gs_dump -U jack -f /home/omm/backup/postgres_backup.tar -p 8000 postgres -F t
6、导出模式
⚫ openGauss目前支持使用gs_dump工具导出模式级的内容,包含模式的数据和定义。
⚫ 用户可通过灵活的自定义方式导出模式内容,不仅支持选定一个模式或多个模式的导出, 还支持排除一个模式或者多个模式的导出。可根据需要自定义导出如下信息:
导出模式全量信息,包含数据和对象定义。
仅导出数据,即模式包含表中的数据,不包含对象定义。
仅导出模式对象定义,包括:表定义、存储过程定义和索引定义等。
⚫ 示例:使用gs_dump同时导出hr和public模式。
gs_dump -U jack -f /home/omm/backup/MPPDB_schema_backup -p 8000 human_resource -n hr -n public -F d
7、导出表
⚫ openGauss支持使用gs_dump工具导出表级的内容,包含表定义和表数据。视图、序列 和外表属于特殊的表。
⚫ 用户可通过灵活的自定义方式导出表内容,不仅支持选定一个表或多个表的导出,还支 持排除一个表或者多个表的导出。可根据需要自定义导出如下信息:
导出表全量信息,包含表数据和表定义。
仅导出数据,不包含表定义。
仅导出表定义。
⚫ 示例:使用gs_dump同时导出指定表hr.staffs和hr.employments。
gs_dump -U jack -f /home/omm/backup/MPPDB_table_backup -p 8000 human_resource -t hr.staffs -t hr.employments -F d
8、导出所有数据库
⚫ openGauss支持使用gs_dumpall工具导出所有数据库的全量信息,包含openGauss中每个数据库 信息和公共的全局对象信息。可根据需要自定义导出如下信息:
导出所有数据库全量信息,包含openGauss中每个数据库信息和公共的全局对象信息(包含角色和表空 间信息)。使用导出的全量信息可以创建与当前主机相同的一个主机环境,拥有相同数据库和公共全局 对象,且库中数据也与当前各库相同。
仅导出数据,即导出每个数据库中的数据,且不包含所有对象定义和公共的全局对象信息。
仅导出所有对象定义,包括:表空间、库定义、函数定义、模式定义、表定义、索引定义和存储过程定 义等。使用导出的对象定义,可以快速创建与当前主机相同的一个主机环境,拥有相同的数据库和表空 间,但是库中并无原数据库的数据。
⚫ 示例:使用gs_dumpall一次导出所有数据库信息。
gs_dumpall -U omm -f /home/omm/backup/MPPDB_backup.sql -p 8000
9、无权限角色导出数据
⚫ gs_dump和gs_dumpall通过-U指定执行导出的用户帐户。如果当前使用的帐户不具备导 出所要求的权限时,会无法导出数据。此时,可在导出命令中设置--role参数来指定具备 权限的角色。在执行命令后,gs_dump和gs_dumpall会使用--role参数指定的角色,完 成导出动作。
⚫ 示例:使用gs_dump导出human_resource数据库数据。
假设用户jack不具备导出数据库human_resource的权限,而角色role1具备该权限,要实现导 出数据库human_resource,可以在导出命令中设置--role角色为role1,使用role1的权限,完 成导出目的。
gs_dump -U jack -f /home/omm/backup/MPPDB_backup.tar -p 8000 human_resource --role role1 -- rolepassword abc@1234 -F t
数据导入导出 – gs_restore
⚫ gs_restore是openGauss数据库提供的与gs_dump配套的导入工具。通过该工具,可将gs_dump 导出的文件导入至数据库。gs_restore支持导入的文件格式包含自定义归档格式、目录归档格式和 tar归档格式。
⚫ gs_restore具备如下两种功能。
导入至数据库
◼ 如果指定了数据库,则数据将被导入到指定的数据库中。其中,并行导入必须指定连接数据库的密码。
导入至脚本文件
◼ 如果未指定导入数据库,则创建包含重建数据库所需的SQL语句脚本,并将其写入至文件或者标准输出。该脚本文 件等效于gs_dump导出的纯文本格式文件。
⚫ gs_restore工具在导入时,允许用户选择需要导入的内容,并支持在数据导入前对等待导入的内容 进行排序。
gs_restore 参数说明
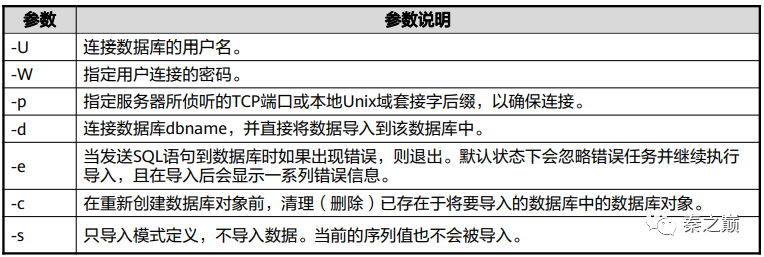
gs_restore 示例
⚫ 使用gs_restore命令,从postgres整个数据库内容的导出文件中,将数据库的所有对象的 定义导入到backupdb。
gs_restore -U jack /home/omm/backup/MPPDB_backup.tar -p 8000 -d backupdb -s -e -c
⚫ 使 用 gs_restore 命 令 , 导 入 指 定 MPPDB_backup.dmp 文 件 ( 自 定 义 归 档 格 式 ) 中 postgres数据库的数据和对象定义。
gs_restore backup/MPPDB_backup.dmp -p 8000 -d backupdb
⚫ 使用gs_restore命令,将postgres数据库的所有对象的定义导入至backupdb数据库。导 入前,postgres存在完整的定义和数据,导入后,backupdb数据库只存在所有对象定义, 表没有数据。
gs_restore /home/omm/backup/MPPDB_backup.tar -p 8000 -d backupdb -s -e -c
10、ANALYZE
⚫ 执行计划生成器需要使用表的统计信息,以生成最有效的查询执行计划,提高查询性能。因此数据导入完成后,建议执行ANALYZE语句生成最新的表统计信息。统计结果存储在 系统表PG_STATISTIC中。
⚫ ANALYZE支持的表类型有行/列存表。ANALYZE同时也支持对本地表的指定列进行信息 统计。
⚫ ANALYZE语法(以product_info表为例)。
postgres=# ANALYZE product_info;
ANALYZE
VACUUM
⚫ 如果导入过程中,进行了大量的更新或删除行时,应运行VACUUM FULL命令,然后运 行ANALYZE命令。大量的更新和删除操作,会产生大量的磁盘页面碎片,从而逐渐降低 查询的效率。VACUUM FULL可以将磁盘页面碎片恢复并交还操作系统。
⚫ VACUUM FULL语法(以product_info表为例)。
postgres=# VACUUM FULL product_info;
VACUUM
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 麒麟系统版本介绍白皮书 509
- MiSans 阿拉伯语字体文件 450
- 解决新版本麒麟系统中微信打开白屏显示 393
- 麒麟系统进行系统监控,查看进程的运行时间来优化性能 326
- 临时关闭swap分区与永久关闭swap分区(注意必须确保系统有足够内存运行!) 217
- 统信桌面专业版添加字体 210
- 统信uos单一程序黑屏,任务栏正常显示解决办法 209
- 统信uos快捷键文档 181
- 统信系统双无线网卡设置关闭开启单一网卡 144
- 分享一个磁盘恢复工具,适用于多平台(包括统信) 119
- 最近下载排行榜
- 麒麟系统版本介绍白皮书 0
- MiSans 阿拉伯语字体文件 0
- 解决新版本麒麟系统中微信打开白屏显示 0
- 麒麟系统进行系统监控,查看进程的运行时间来优化性能 0
- 临时关闭swap分区与永久关闭swap分区(注意必须确保系统有足够内存运行!) 0
- 统信桌面专业版添加字体 0
- 统信uos单一程序黑屏,任务栏正常显示解决办法 0
- 统信uos快捷键文档 0
- 统信系统双无线网卡设置关闭开启单一网卡 0
- 分享一个磁盘恢复工具,适用于多平台(包括统信) 0

prtyaa 收益399.62元

zlj141319 收益236.11元

IT-feng 收益219.61元

1843880570 收益214.2元

风晓 收益208.24元

哆啦漫漫喵 收益204.5元

777 收益173.07元

Fhawking 收益106.6元

信创来了 收益106.03元

克里斯蒂亚诺诺 收益91.08元
