GaussDB整体性能慢分析
GaussDB整体性能慢分析
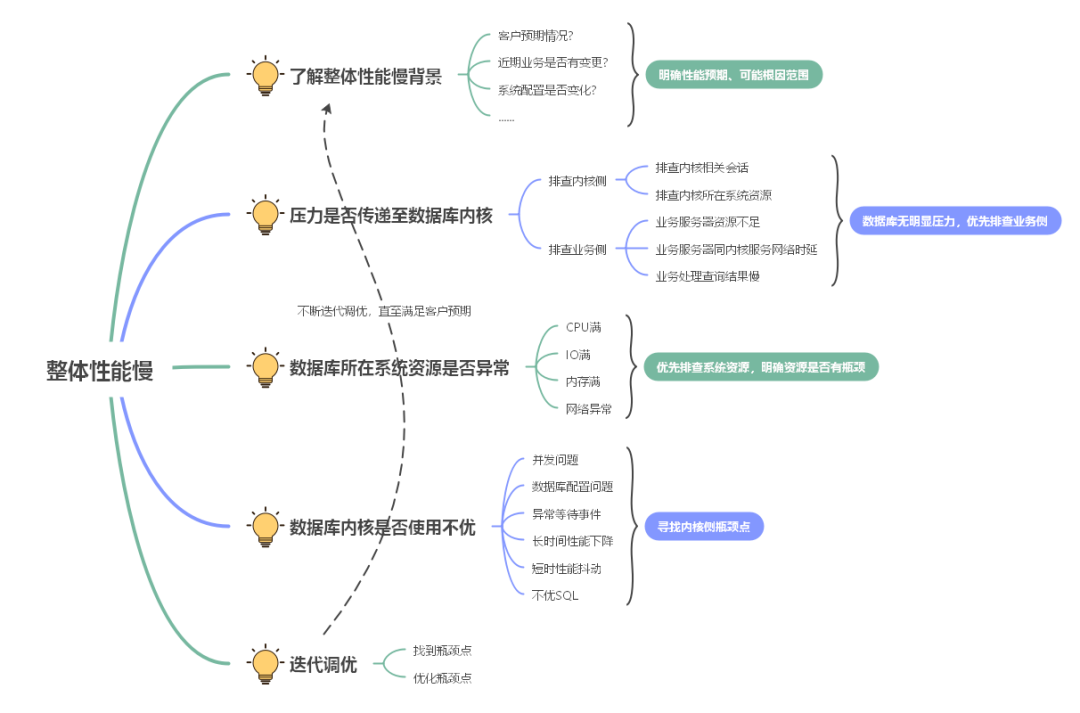
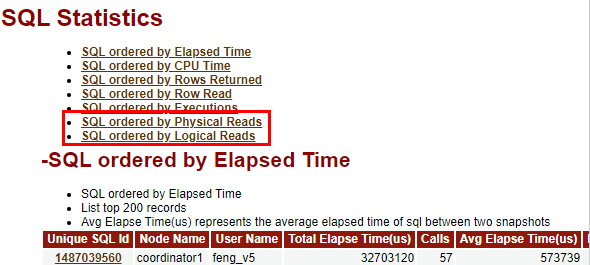
$ cd /var/log/sa $ sar -f sa 12:00:01 AM CPU %user %nice %system %iowait %steal %idle 12:10:01 AM all 41.40 0.00 10.14 0.05 0.00 48.42 12:20:01 AM all 41.37 0.00 10.15 0.05 0.00 48.42 12:30:01 AM all 41.40 0.00 10.18 0.06 0.00 48.36 12:40:01 AM all 41.40 0.00 10.16 0.05 0.00 48.40 12:50:01 AM all 41.31 0.00 10.11 0.03 0.00 48.55 01:00:01 AM all 41.40 0.00 10.13 0.02 0.00 48.44 top top - xxxxxx up 44 days, 1:06, 0 users, load average: 34.91, 35.33, 35.14 Tasks: 641 total, 10 running, 631sleeping, 0 stopped, 0 zombie %Cpu(s): 41.3 us, 10.1 sy, 0.0 ni, 48.6id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st KiB Mem : 19748899+total, 14801132 free, 8637000 used, 17405084+buff/cache KiB Swap: 4194300 total, 0 free, 4194300 used. 10027731+avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 10678 Ruby 20 0 54.8g 38.2g 34.6g S 1398 20.3 126085:50 gaussdb 58736 Ruby 20 0 4901420 53220 6520 S 22.8 0.0 2624:15 cm_agent 57648 Ruby 20 0 12.9g 90624 10168 S 10.6 0.0 1208:55 etcd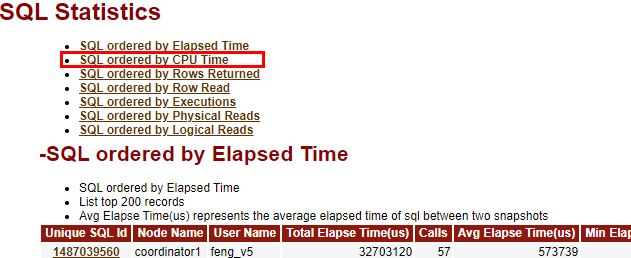
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
评价 0 条
- 最近热门资源
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 2057
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 1994
- 银河麒麟桌面操作系统【保留数据盘重装系统】 1804
- 麒麟系统各种原因开不了机解决(合集) 1587
- 桌面通用(全架构)【rpm包转成deb包】操作方法 931
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 915
- 统信系统安装(合集) 853
- 统信桌面专业版【手动分区安装UOS系统】介绍 845
- 统启动异常几种类型(initramfs 模式) 688
- 最近下载排行榜
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 0
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 0
- 银河麒麟桌面操作系统【保留数据盘重装系统】 0
- 麒麟系统各种原因开不了机解决(合集) 0
- 桌面通用(全架构)【rpm包转成deb包】操作方法 0
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 0
- 统信系统安装(合集) 0
- 统信桌面专业版【手动分区安装UOS系统】介绍 0
- 统启动异常几种类型(initramfs 模式) 0

prtyaa 收益393.72元

zlj141319 收益220.97元

1843880570 收益214.2元

IT-feng 收益213.03元

风晓 收益208.24元

777 收益172.82元

Fhawking 收益106.6元

信创来了 收益105.89元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
