程序员笔记 (四十)Kafka Connect 与 Kafka Streams
(一)
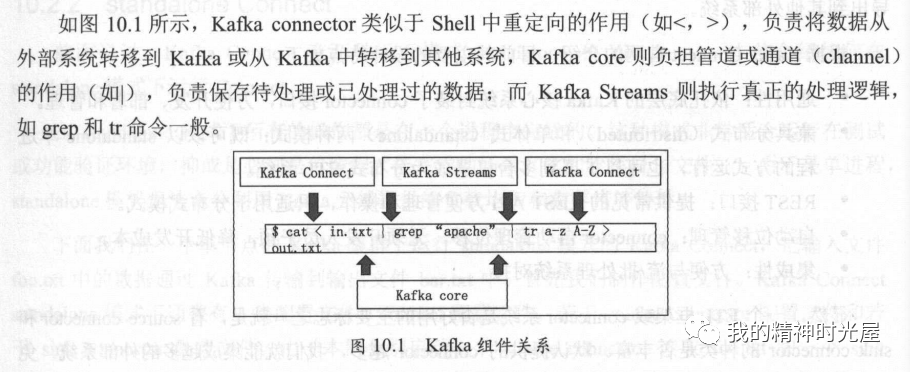
(二)
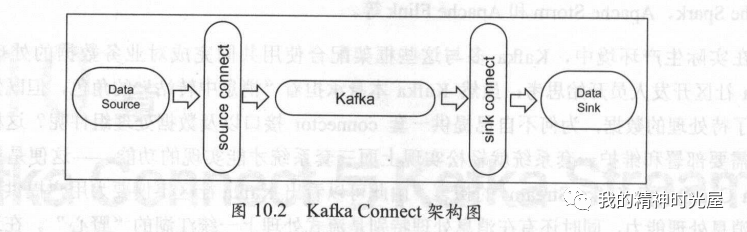
如图所示,Kafka Connect主要由source connector和sink connector组成。事实上,几乎大部分的ETL框架都是由这两大类逻辑组件组成的,如Apache Flume、Kettle等。sourceconnector 负责把输入数据从外部系统中导入到 Kaka 中,而 sik connector 则负责把输出数据导出到其他外部系统。
根据KafkaConnect官网的介绍,目前其主要的设计特点如下。
通用性:依托底层的Kafka核心系统封装了connector接口,方便开发、部署和管理
兼具分布式(distributed)和单体式(standalone)两种模式:既可以以 standalone 单进程的方式运行,也可以扩展到多台机器成为分布式ETL系统。
REST接口:提供常见的RESTAPI方便管理和操作,只适用于分布式模式自动位移管理:connector
自动管理位移,无须开发人员干预,降低开发成本
集成性:方便与流/批处理系统对接。
(三)什么是流处理
从本质上说,流处理是一种处理模式或一类数据处理引擎,旨在处理无限多的数据集合从广义上说,它既包括完全的流处理,也包括模拟流处理的微批次实现 (micro-batch)Spark Streaming 的设计理念就是这种 micro-batch 化。值得注意的是,流处理经常与以下的词混淆。


(四)

(五)
KafkaStreams是一个轻量级的客户端处理API库。它非常适用于输入/输出数据均来自Kafka集群的流处理场景。如果配合用户自定义的connector它也支持连接上下游外部系统的流处理应用或微服务的实现。
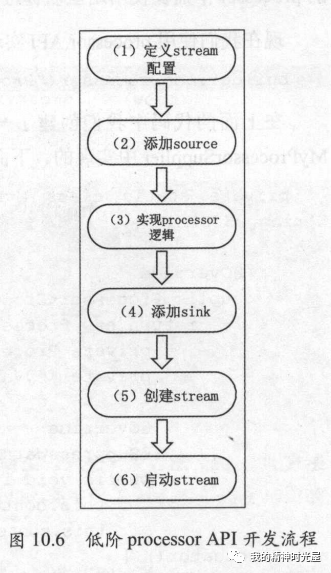
(六)

(七)

如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 40
- 统信uos安装mysql的实例参考 31
- 分享解决宏碁电脑关机时自动重启的方法 30
- 在银河麒麟高级服务器操作系统V10SP3中,需要将默认shell类型修改为csh。 29
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 28
- 统信uosboot区分未挂载导致更新备份失败 27
- 格之格打印机dp3300系列国产系统uos打印机驱动选择 25
- 以openkylin为例编译安装内核 23
- 最近下载排行榜
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 0
- 统信uos安装mysql的实例参考 0
- 分享解决宏碁电脑关机时自动重启的方法 0
- 在银河麒麟高级服务器操作系统V10SP3中,需要将默认shell类型修改为csh。 0
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 0
- 统信uosboot区分未挂载导致更新备份失败 0
- 格之格打印机dp3300系列国产系统uos打印机驱动选择 0
- 以openkylin为例编译安装内核 0

prtyaa 收益400.53元

zlj141319 收益237.46元

哆啦漫漫喵 收益231.42元

IT-feng 收益219.71元

1843880570 收益214.2元

风晓 收益208.24元

777 收益173.07元

Fhawking 收益106.6元

信创来了 收益106.03元

克里斯蒂亚诺诺 收益91.08元
