程序员笔记 (三十四)Kafka
(一)创建 topic 时,Kafka为该 topic 的每个分区在文件系统中创建了一个对应的子目录,名字就是<topic><分区号>。所以,倘若有一个 topic 名为 test,有两个分区,那么在文件系统中Kafka会创建两个子目录:test-0和 test-1。每个日志子目录的文件构成都是若干组日志段+索引文件。
(二)事实上,Kafka每个日志段文件是有上限大小的,由 broker 端参数logsegment.bytes控制,默认就是1GB 大小。因此,当日志段文件填满记录后,Kafka 会自动创建一组新的日志段文件和索引文件--这个过程被称为日志切分 (log rolling)。日志切分后,新的日志文件被创建并开始承担保存记录的角色。
(三)

(四)

(五)
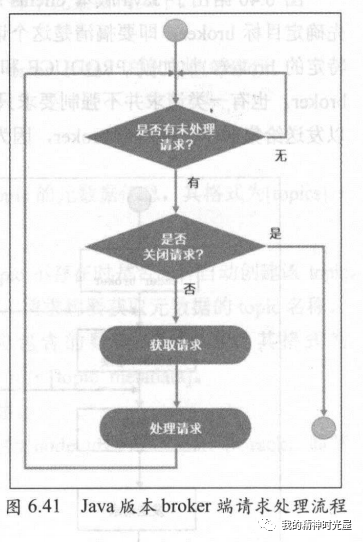
(六)
controller 概览
在一个 Kafka 集群中,某个 broker 会被选举出来承担特殊的角色,即控制器(下称controller)。顾名思义,引入 controller 就是用来管理和协调 Kafka 集群的。具体来说,就是管理集群中所有分区的状态并执行相应的管理操作。
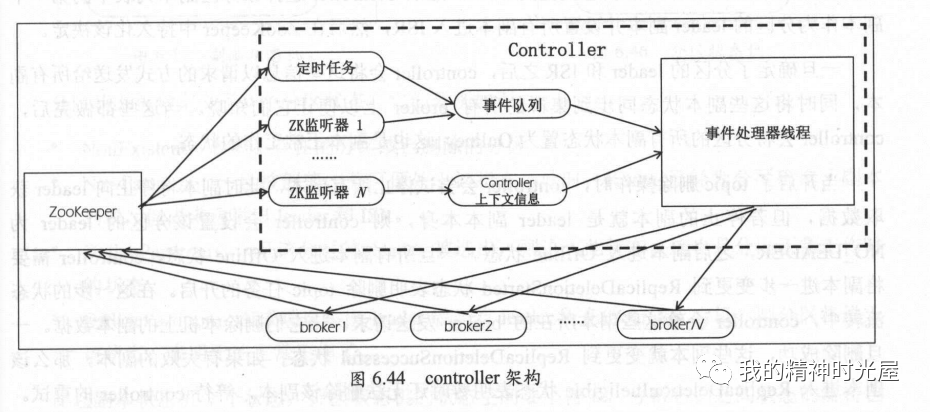
每个Kafka集群任意时刻都只能有一个controller。当集群启动时,所有broker都会参与controller的竞选,但最终只能由一个 broker 胜出。一旦controller 在某个时刻崩溃,集群中剩余的 broker 会立刻得到通知,然后开启新一轮的 controller 选举。新选举出来的controller 将承担起之前controller 的所有工作。图6.44 展示了cntroller 的架构,后续我们会为读者一一详解其中的组件。
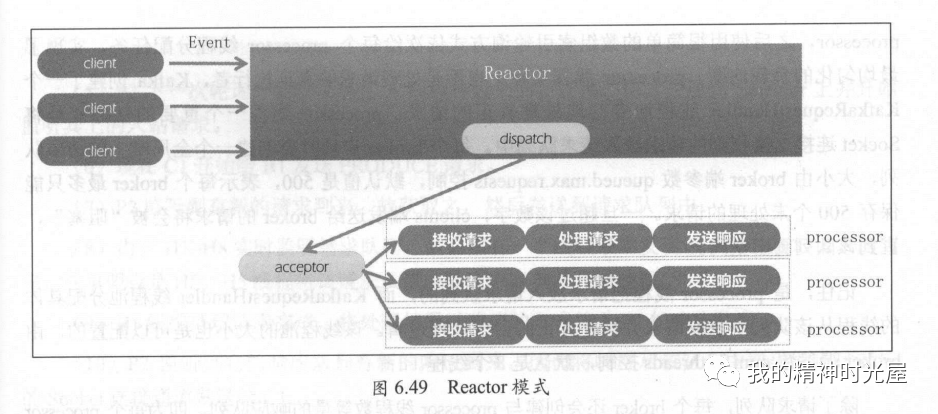
(七)
Reactor 模式中有很两个很重要的组件 acceptor 线程和 processor 线程。acceptor 线程实时地监听外部数据源发送过来的事件,并执行分发任务;processor 线程执行事件处理逻辑并将处理结果发送给 client。
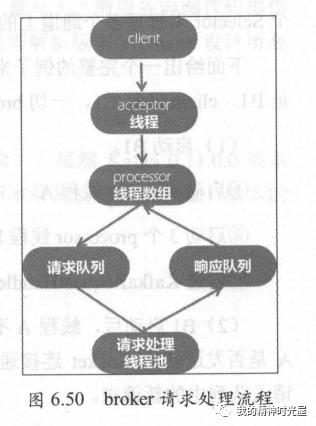
(八)
(九)


如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 81
- 以openkylin为例编译安装内核 76
- 分享解决宏碁电脑关机时自动重启的方法 73
- 统信uosboot区分未挂载导致更新备份失败 63
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 63
- 统信uos安装mysql的实例参考 60
- 格之格打印机dp3300系列国产系统uos打印机驱动选择 57
- 在银河麒麟高级服务器操作系统V10SP3中,需要将默认shell类型修改为csh。 51
- MySQL国产平替最佳选择---万里数据库(GreatDB) 45
- 最近下载排行榜
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 0
- 以openkylin为例编译安装内核 0
- 分享解决宏碁电脑关机时自动重启的方法 0
- 统信uosboot区分未挂载导致更新备份失败 0
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 0
- 统信uos安装mysql的实例参考 0
- 格之格打印机dp3300系列国产系统uos打印机驱动选择 0
- 在银河麒麟高级服务器操作系统V10SP3中,需要将默认shell类型修改为csh。 0
- MySQL国产平替最佳选择---万里数据库(GreatDB) 0

prtyaa 收益400.83元

zlj141319 收益237.91元

哆啦漫漫喵 收益231.52元

IT-feng 收益219.92元

1843880570 收益214.2元

风晓 收益208.24元

777 收益173.17元

Fhawking 收益106.6元

信创来了 收益106.03元

克里斯蒂亚诺诺 收益91.08元
