从零开始学正则(四),什么是正则回溯?
壹 ❀ 引
我在 从零开始学正则(三)这篇博客中介绍了分组引用与反向引用的概念,灵活利用分组能让我们的正则表达式更为简洁。在文章结尾我们留下了两个问题,一问使用正则模拟实现 trim方法;二问将my name is echo每个单词首字母转为大写。
我们先来分析第一个问题,trim属于String方法,能去除字符串头尾空格,所以我们只需要写一个正则匹配头尾空格将其替换成空即可。空格属于空白符,所以这里需要使用字符组 \s ,空格可能有多个,所以要使用量词 + ;其次我们需要匹配紧接开头后与结尾前的空格,所以需要使用^与$;最后将空格替换成空字符串,所以需要使用replace方法,综合起来,就应该是这样:
var str = ' 听风 是风 '; var regex = /^\s+|\s+$/g; var result = str.replace(regex, ''); //听风 是风
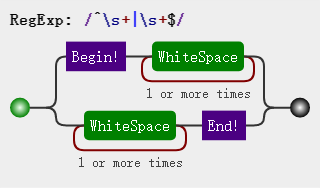
有人肯定就纳闷了,“听风”与“是风”中间的空格怎么没被去除呢?常理上来说,听风后的空格也算开头位置^之后,结束位置之前啊;其实通过图解已经很清楚,能被匹配的空格一定是紧接开头位置之后,再到“听风”时,之后的空格像是被“听风”打断了一样,已经不具备被匹配的资格了。关于^若有疑问,可以阅读博主 JS 正则表达式^详解,脱字符与美元符同时写表示什么意思?这篇博客。
我们再来看第二个问题,将my name is echo首字符转为大写,纵观首字符出现的位置要么在^之后,要么在空格之后,所以只要匹配这两个位置之后的字符,再利用String方法toUpperCase方法转为大写即可,所以可以这么写:
var result = 'my name is echo'.replace(/(^|\s)\w/g, function (word) {
return word.toUpperCase();
});
console.log(result); //My Name Is Echo
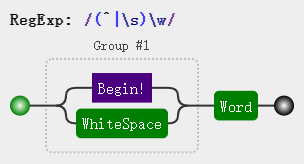
注意,(^|\s) 由于是一个分组,所以正则还是会存储此分组所匹配的信息,但我们只是需要使用此分组来确定字符的位置,所以此分组匹配结果保存起来也是无意义的,浪费内存,所以更优的写法是这样:
var result = 'my name is echo'.replace(/(?:^|\s)\w/g, function (word) {
return word.toUpperCase();
});
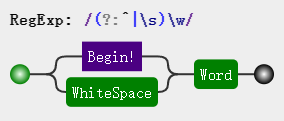
仔细对比两张图解可以发现,在添加非捕获括号后,(?:^|\s) 只是单纯起到匹配作用,去除了正则默认存储分组匹配结果的行为。
那么关于题目解析就说到这里,让我们开始本篇学习。说在前面,正则学习系列文章均为我阅读 老姚《JavaScript正则迷你书》的读书笔记,文中所有正则图解均使用regulex制作。那么本文开始!
贰 ❀ 理解正则的回溯
回溯属于正则匹配原理上的东西,但理解并不难,我们通过一个简单的例子先来了解什么是回溯。
比如,我们现在有这样一个正则 /ab{1,3}c/ ,它表示匹配 a加上1-3个b再加上c这样的字符串。
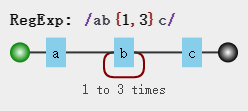
我们假设现在使用此正则匹配字符串 abbbc ,它的匹配过程是这样,这里直接引用原书的图:
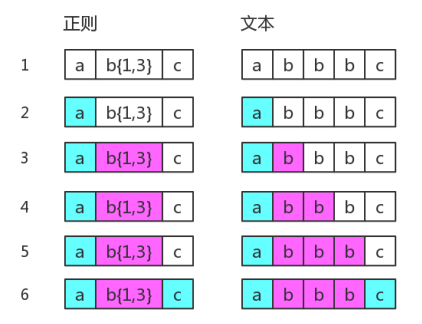
而当我们使用此正则匹配字符串 abbc 时,它的匹配过程却是这样:
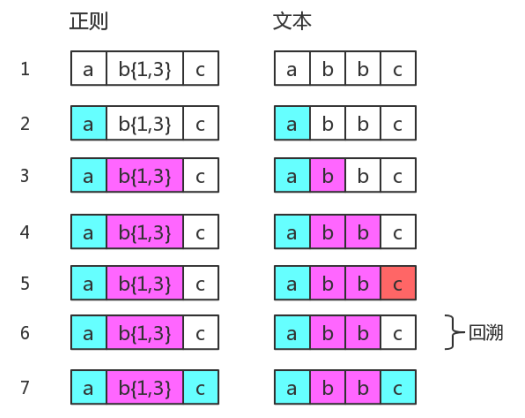
仔细对比两次匹配图解可以发现,尽管字符串 abbc 只有两个字母b,但由于量词范围是 {1,3} ,所以匹配过程中还是做了第三次匹配的尝试,只是匹配失败了。于是匹配状态回到了第二次字母b匹配成功时的样子,然后开始接下来的匹配。可以看到第6步与第4步是完全相同的,我们将第6步称为回溯。
我们再来看个例子加深回溯的印象,假设现在有这段正则 /ab{1,3}bbc/ ,我们用于匹配字符串 abbbc ,它的匹配过程是这样:
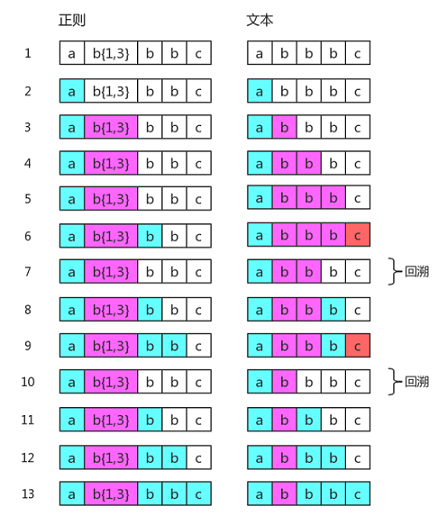
请留意图解中第7步与第10步的回溯,因为正则默认就是贪婪匹配,对于量词 {1,3} 而言,它一开始就把三个字母 b 给匹配完了,但正则匹配要顾全大局,后面 bb 还需要匹配,没办法只能回溯,将量词 {1,3} 匹配的b先吐一个出来让给第一个字母b;紧接着又匹配,发现又不够,于是再次回溯,量词 {1,3} 又得吐一个出来,这次回溯的起点要更早,直接回到量词 {1,3} 只匹配了一个字母b的步骤,然后重新匹配直至结束。
我们总结起来说就是量词 {1,3} 就是先下手为强,强占三个b,但正则为顾全大局,批评了量词的贪婪行为让其为后面的字段让位(回溯),所以最后量词 {1,3} 只对应了一个字母b。
最后看个因为不良写法导致大量回溯的例子,现在使用正则 /".*"/ 匹配字符 "abc"de,图解过程是这样:
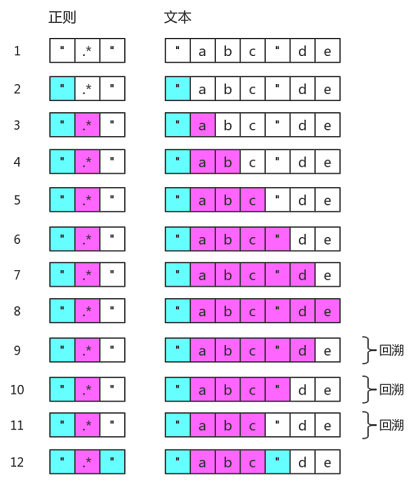
我们是希望匹配出 "abc",但由于使用了通配符 . 加上量词 * ,由于贪婪的本性,直接将整个字符匹配了一遍,直接匹配完成后,正则发现我还有个双引号要匹配,于是一次次回退,直到回到被 .* 匹配过的双引号,重新再匹配。
记住 .* 非常影响性能,既然我们希望匹配一对双引号加上中间若干不是引好的字符,将正则改为 /"[^"]*"/ 会好很多。
叁 ❀ 常见的回溯形式
正则匹配字符的整个流程有个专业的名词叫回溯法。我们可以看看百度百科的官方解释:
回溯法(探索与回溯法)是一种选优搜索法,又称为试探法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
这非常类似深度优先算法,先从一条线走到底,发现行不通了再回溯到分支点,尝试其它路线。
1.贪婪量词
在上文中我们已经展示了几个因为量词贪婪导致回溯的例子。比如量词 {1,3} 一开始就霸占了三个字母b,但由于正则得顾全大局,后面还有两个b需要匹配,导致量词需要吐出两个字母b,从而造成两次回溯。
那现在有个问题,如果量词紧跟量词贪婪性会怎么样呢?我们来看个简单的例子:
var string = "1234";
var regex = /(\d{1,3})(\d{1,3})/;
console.log( regex.exec(string) );// ["1234", "123", "4", index: 0, input: "1234", groups: undefined]
通过结果123与4可以看出如果存在多个量词,前面的量词总是先下手为强,虽然大家都很贪婪,但因为近水楼台先得月,在前面的总是拿自己能拿的极限。
2.惰性量词
我们知道可以通过添加?将匹配模式改变成惰性匹配,我们来看个简单的例子:
var string = "1234";
var regex = /(\d{1,3}?)(\d{1,3})/;
console.log(regex.exec(string)); // ["1234", "1", "234", index: 0, input: "1234", groups: undefined
可以看到通过添加了?,分组1果然只匹配了一个数字1,变得不再贪婪。
不过即使是惰性匹配,它也有身不由己的情况,我们来个有趣的例子:
var string = "12345";
var regex = /^(\d{1,3}?)(\d{1,3})$/;
console.log(regex.test(string)); //true
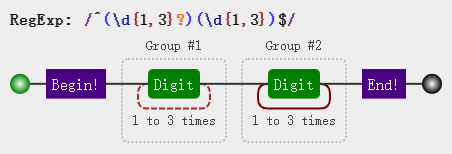
可以看到我们使用 test方法 检验结果还是true,哎?exec方法匹配的结果是1和234,加起来才四个数字,怎么在test 12345时还为true呢,因为此时的匹配过程是这样的:
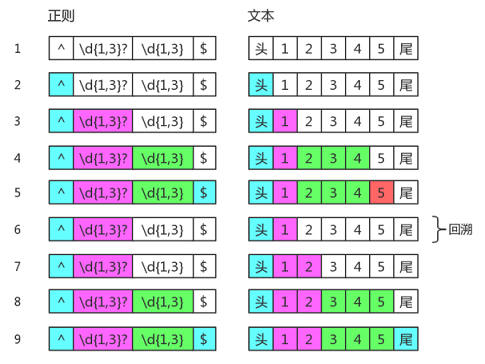
分组 (\d{1,3}?) 确实不贪婪,一开始也只匹配了一个数字,但匹配到5时,发现还差一个数字我们才能成功匹配到尾部,为了顾全大局,那就只能麻烦不贪婪的分组1再多匹配一个数字,顾全大局嘛,不寒碜。
3.分支结构
我们在第一篇文章中也有提到分支结构也是惰性匹配,看个例子:
var regex = /hello|helloEcho/g; var result = 'helloEcho'.match(regex); console.log(result);//["hello"]
对于分支而言,因为hello这条分支能走通,那么后面的分支就不再尝试了。当然也存在前面的分支走不通,于是回溯走另一条分支的情况。比如这个例子:
var regex = /^(?:can|candy)$/g;
var result = regex.test('candy');
console.log(result);//true
它的匹配过程是这样:
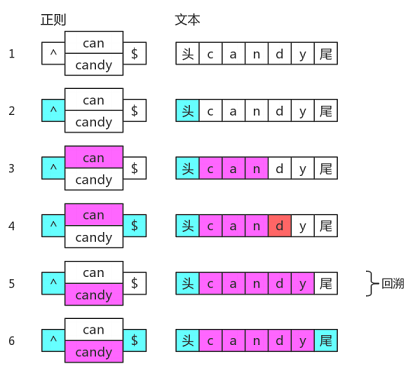
当can分支走不通了,回溯并切换到candy分支尝试。
肆 ❀ 总
那么到这里,关于回溯相关的知识就介绍完了,好消息是没有思考题,毕竟这个点太晚了,我也有点困了....那么我们回顾一下知识点。
贪婪总是尽自己所能拿最多,但正则顾全大局,有时候它得把已经吞下去的再给吐出来。
惰性总是能少拿就少拿点,但正则顾全大局,有时惰性还是得多拿一点。
分支总是先将前面的分支走到底,走不通了再回到分支的岔口,再尝试其它分支的可能性。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 40
- 统信uos安装mysql的实例参考 31
- 分享解决宏碁电脑关机时自动重启的方法 30
- 在银河麒麟高级服务器操作系统V10SP3中,需要将默认shell类型修改为csh。 29
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 28
- 统信uosboot区分未挂载导致更新备份失败 27
- 格之格打印机dp3300系列国产系统uos打印机驱动选择 25
- 以openkylin为例编译安装内核 23
- 最近下载排行榜
- 银河麒麟桌面操作系统V10SP1-2403-update1版本中,通过“麒麟管家-设备管理-硬件信息-硬盘”查看硬盘类型时,显示的是HDD(机械硬盘),而实际上该笔记本的硬盘类型为SSD 0
- 统信uos安装mysql的实例参考 0
- 分享解决宏碁电脑关机时自动重启的方法 0
- 在银河麒麟高级服务器操作系统V10SP3中,需要将默认shell类型修改为csh。 0
- 分享如何解决报错:归档 xxx.deb 对成员 control.tar.zst 使用了未知的压缩,放弃操作 0
- 统信uosboot区分未挂载导致更新备份失败 0
- 格之格打印机dp3300系列国产系统uos打印机驱动选择 0
- 以openkylin为例编译安装内核 0

prtyaa 收益400.53元

zlj141319 收益237.46元

哆啦漫漫喵 收益231.42元

IT-feng 收益219.81元

1843880570 收益214.2元

风晓 收益208.24元

777 收益173.07元

Fhawking 收益106.6元

信创来了 收益106.03元

克里斯蒂亚诺诺 收益91.08元
