从零开始学正则(上)三
六 、 正则中的位置
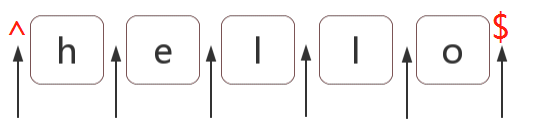
注意,这里所说的位置并不是我们遍历数组时所使用的索引概念,正则匹配的位置又称为锚,是指相邻字符之间的位置,比如下图一个字符 hello 中,每个箭头就是一个位置:
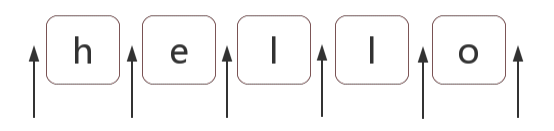
正则表达式中,匹配位置的字符又称为锚,在文章开头我们已经见过了 ^$ 两个锚,其实你已经能猜到这两个代表了开头和结尾的两个箭头的位置,我们来验证下位置的概念,看个简单的例子:
const str = '听风是风';
const regex = /^|$/g;
const result = str.replace(regex, '❀'); //❀听风是风❀
可以看到两个位置被替换成了花朵,此时字符串的开头位置与结尾位置发生了变化,开头变成了花朵左边,结尾位置变为第二朵花的右边。
七、理解正则的锚
除了常用的 ^$ ,还有其它正则提前定义的锚,我们一一细说。
7.1 ^ 脱字符
**^** 脱字符:匹配开头,在多行中匹配行开头,比如:
const str = '听风\n是风';
// 这里的修饰符m表示匹配多行
const regex = /^/mg;
const result = str.replace(regex, '❀');
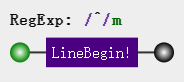

注意,正则结尾添加了一个 mg ,g(global)前面有解释表示全局匹配,表示一行从左到右完整匹配一遍;而m(more)表示多行匹配,mg就是多行全局匹配,每行不管文本多长,都完全匹配一遍。
7.2 $ 美元符号
**$**美元符号:匹配结尾,在多行中匹配行尾。
7.3 \b 单词边界
**\b**单词边界:表示\w(单词字符)与\W(非单词字符)之间,\w(单词字符)与 ^ (脱字符)之间,以及\w (单词字符)与 $ 之间的位置,有点难理解,先看个例子:
const str = '[echo].123';
const regex = /\b/g;
const result = str.replace(regex, '❀'); //[❀echo❀].❀123❀
上面解析有点长,我们缩短点,\b表示\w与\W、^、$之间的位置,而\w范围是[0-9a-zA-Z_],那么我们再看上面的例子,为了方便理解,我们拆分细说:
从左往右看,首先 ^ 与 [ 之间不满足,再到 [ 与 e 之间,[ 是非单词符而 e 是单词符,满足条件。
echo 由于四个字母都是单词符,直接跳过,o 与 ] 又满足了条件。
] 与 . 之间很明显不符合,再看 . 与 1 又满足了条件。
123都是单词符,跳过,直接到了尾部 3 与 $ ,满足条件。
7.4 \B 非单词边界
**\B**非单词边界,意思与 \b 相反,匹配 \w 与 \w、\W 与 \W、^ 与 \W,\W 与 $ 之间的位置,还是上面的例子,我们改改匹配条件:
const str = '[echo].123';
const regex = /\B/g;
const result = str.replace(regex, '❀'); //❀[e❀c❀h❀o]❀.1❀2❀3
可以看到 ^ 与 [ 之间,以及单词符与单词符之间都满足了条件。
7.5 正向先行断言 (?=p)
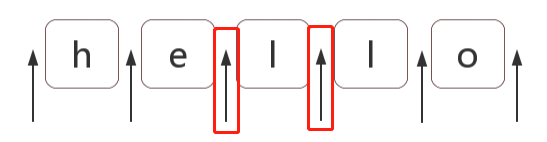
**(?=p)**正向先行断言:p表示一个匹配模式,即匹配所有满足条件p的字段的前面位置,有点绕口,看个简单的例子:
const str = 'hello';
const regex = /(?=l)/g;
const result = "hello".replace(regex, '❀'); //he❀l❀lo
这里就是先在字符串中找到字母 l,然后再找到 l 前面的位置就是目标位置。为了方便,直接利用前面位置理解的图,也就是这两个红框了:
7.6 负向先行断言 (?!p)
那么(?!p)与(?=p)就是反过来的表示负(反)向先行断言,还是上面的例子,我们改改条件,也就是下图中绿框中的位置:
const str = 'hello';
const regex = /(?!l)/g;
const result = "hello".replace(regex, '❀'); //❀h❀ell❀o❀
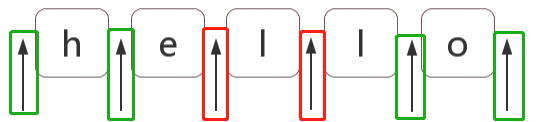
如果不看这个图,我不知道大家有没有这样的疑惑,不对啊,前面解释 \b单词边界时,是从 ^脱字符 开始判断的,脱字符也不满足条件前面也应该加朵❀,最终输出难道不应该是 ❀❀h❀ell❀o❀ 这样吗?o后面有❀ 是因为o后面还有个 不满足条件所以才这样啊。
记住,^和主动理解成两个隐藏字符,我们现在是在匹配位置。
所以 /(?=l)/g 就是在找 l 前面的位置,而 /(?!l)/g 本质上来说就是找不是字母 l 前面的其它所有位置。
那为什么 \b单词边界还能从 ^ 开始判断呢,因为概念就包含了判断\w 与^ 之间的位置,在判断单词边界时,这两个特殊位置就像两个隐藏字符一样,也成了判断位置的条件。而在判断(?!p)与(?=p)时,主要p不是^,那么此时的 ^$单纯作为两个位置,不会主动作为判断条件参与判断,这一点千万不要弄混了!!!
7.7 正向后发断言 (?<=p)
正向后发断言**(?<=p)**:与正向先行断言类似都是匹配位置,区别在于正向先行断言是匹配符合条件前的位置,而正向后发断言是匹配符合条件后面的位置:
const str = 'hello';
const regex = /(?<=l)/g;
const result = "hello".replace(regex, '❀'); //'hel❀l❀o'
总结来说,先行就是位置在匹配结果的前面,后发就是位置在匹配结果的后面。
7.8 负向后发断言 (?<!p)
这里大家应该能秒懂呢,反正就是匹配与正向后发断言完全相反的位置就对了(除了两个l之后的所有位置),不好理解的概念,就基于好理解的概念进行取反。
const str = 'hello';
const regex = /(?<!l)/g;
const result = "hello".replace(regex, '❀'); //'❀h❀e❀llo❀'
八、位置的特性
到这里你也许有点迷糊,本来就是找位置,结果 ^$ 作为位置应该是被找的对象,怎么还反客为主成了找位置的条件了,位置和位置之间难道还有位置?正则里还真是这样。
我们可以将位置理解成一个空字符" ",就像上图的箭头,一个hello可以写成这样:
"hello" = "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + "";
它甚至还能写成这样,站在位置的角度,位置能是无限个:
"hello" = "" + "" + "hello"
以正则的角度,我们测试一个单词是否为hello甚至可以写成这样:
const str = 'hello';
const regex = /^^^^^hello$$$$$$$$$$$$/g;
const result = regex.test(str); //true
当然这是我们站在匹配正则位置的角度抽象理解成这样的,毕竟真的给字符串加空格,字符串就真的变样了,\b单词边界会拿^$这两个特殊位置作为判断其它位置的条件,记住这一点就好了。
到这里我们整理下位置(锚)的知识点:

九、分组和分支结构
9.1.分组基础
在正则中,圆括号 () 表示一个分组,即括号内的正则是一个整体,表示一个子表达式。
我们知道 /ab+/ 表示匹配a加上一个或多个b的组合,那如果我们想匹配ab的多次组合呢?这里就可以使用()包裹ab:
const str = 'abab ababab aabbaa';
const regex = /(ab)+/g;
const result = str.match(regex); //["abab", "ababab", "ab"]
在分支中使用括号也是非常常见的,比如这个例子:
const str1 = 'helloEcho';
const str2 = 'helloKetty';
const regex = /^hello(Echo|Ketty)$/;
const result1 = regex.test(str1); //true
const result2 = regex.test(str2); //true
若我们不给分组加括号,此时的分支就变成了helloEcho和Ketty,很明显这就是不是我们想要的。(TODO 注意正则尾部未加全局匹配 g,如果加了第二个验证为false,原因参考)。
9.2.分组引用
不知道大家在以往看正则表达式时有没有留意到$1,$2类似的字符,这类字符表示正则分组引用,对于正则使用是非常重要的概念。我们来看一个简单的例子:
写一个匹配 yyyy-mm-dd 的正则:
const regex = /(\d{4})-(\d{2})-(\d{2})/;
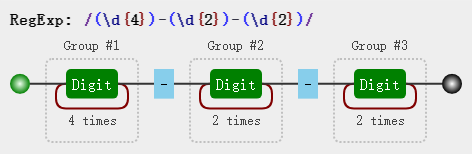
通过图解我们能发现每个分组上面多了类似Group #1的分组编号,是不是已经联想到1相关的字符了呢?没错,这里1,$2正是对应的分组编号。
这里我们提前科普两个方法,一个是字符串的match方法,一个是正则的exec方法,它们都用于匹配正则相符字段,看个例子:
const result1 = '2019-12-19'.match(regex);
const result2 = regex.exec('2019-12-19');
console.log(result1);
console.log(result2);

可以看到虽然方法写法不同,但结果一模一样,我们来解释下匹配的结果。
2019-12-19为正则最终匹配到的结果,"2019", "12", "19"这三个分别为group1,group2,group3三个分组匹配的结果,index: 0 为匹配结果的开始位置,input: "2019-12-19"为被匹配的输入字段,groups表示捕获组的匹配结果,如果该字段的值为undefined,则说明当前正则表达式没有定义任何捕获组。
我们可以通过1,2直接访问上面例子中各分组匹配到的结果。这里我们展示一个完整的例子,在使用过一次正则后输出RegExp对象,可以看到此对象上有众多属性,再通过 RegExp.$1 我们能直接拿到分组1的匹配结果:
const regex = /(\d{4})-(\d{2})-(\d{2})/;
const string = "2019-12-19";
//注意,这里你得先使用一次正则,match test,replace等方法都行
regex.exec(string);
console.dir(RegExp);
console.log(RegExp.$1); // "2019"
console.log(RegExp.$2); // "02"
console.log(RegExp.$3); // "119"
现在我们要明白一个概念,$1 表示的就是Group #1的匹配结果,它就像一个变量,保存了匹配到的实际值。那么知道了这一点我们能做什么呢?比如我们将 yyyy-mm-dd 修改为 dd/mm/yyy 格式。
const result = string.replace(regex, '$3/$2/$1'); // 19/12/2019
console.log(result);
这段代码等价于:
const result = string.replace(regex, function () {
return RegExp.$3 + "/" + RegExp.$2 + "/" + RegExp.$1; // 19/12/2019
});
同时也等价于:
const result = string.replace(regex, function (match, year, month, day) {
console.log(match, year, month, day);//2019-12-19 2019 12 19
return day + "/" + month + "/" + year;//19/12/2019
});
所以看到这,大家也不要纠结第一个修改中'$3/$2/$1'字段如何关联上的分组匹配结果,知道是正则底层实现这么去用就对了。
9.3 groups的bug
上文提到如果你的正则有定义分组,那么匹配结果中的groups字段将展示你分组以及对应的结果,但这其实会有bug:
const regex = /(\d{4})-(\d{2})-(\d{2})/;
const match = regex.exec('2022-03-11');
console.log(match.groups);// undefined
这段代码我们其实定义了3个分组,我们预期的groups字段输出应该是如下:
{
"1": "2022",
"2": "03",
"3": "11"
}
这是因为,在ES6之前,JavaScript并没有原生支持groups字段,只有通过第三方库或者自己手动解析正则表达式的分组才能得到捕获组的匹配结果。
从ECMAScript 2018(ES9)开始,JavaScript引入了具名捕获组和 groups 属性,可以通过实现具名捕获组来访问匹配的结果:
const regex = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
const match = regex.exec('2022-03-11');
console.log(match.groups);
// 输出结果
{
year: '2022',
month: '03',
day: '11'
}
十、反向引用
10.1 基本概念
除了像在上文API中那样使用分组一样,还有一个比较常见的就是在正则自身中使用分组,即代指之前已经出现过的分组,又称为反向引用。我们通过一个例子来了解反向引用。
现在我们需要一个正则能同时匹配 2019-12-19 2016/12/19 2016.12.19 这三种字段,正则我们可以这么写:
const regex = /\d{4}[-\/\.]\d{2}[-\/\.]\d{2}/;
regex.test('2019-12-19'); //true
regex.test('2019/12/19'); //true
regex.test('2019.12.19'); //true
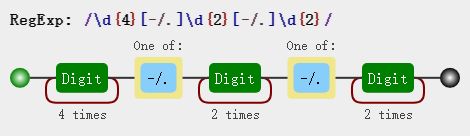
通过图解我们也知道这个正则其实有个问题,它甚至能匹配 2019-12.19 格式的字段
regex.test('2019-12.19'); //true
那现在我们要求前后两个分隔符一定相同时才能匹配成功怎么做呢,这里就需要使用反向引用,像这样:
const regex = /\d{4}([-\/\.])\d{2}\1\d{2}/;
regex.test('2019-12-19'); //true
regex.test('2019/12/19'); //true
regex.test('2019.12.19'); //true
regex.test('2019-12.19'); //false
regex.test('2019/12-19'); //false
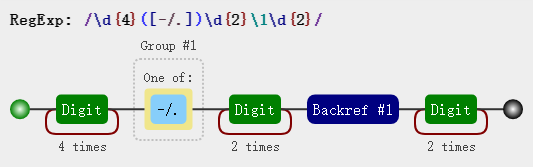
这里的 \1就是反向引用,除了代指前面出现过的分组([-/.])以外,在匹配时它的分支选择也会与前者分组同步,说直白点,当前面分组选择的是 - 时,后者也会选择 - 然后才去匹配字段。
10.2 引用嵌套
有个问题,括号也会存在嵌套的情况,如果多层嵌套反向引用会有什么规则呢?我们来看个例子:
const regex = /^((\d)(\d(\d)))\1\2\3\4$/;
'1231231233'.match(regex); // true
console.log( RegExp.$1 ); // 123
console.log( RegExp.$2 ); // 1
console.log( RegExp.$3 ); // 23
console.log( RegExp.$4 ); // 3
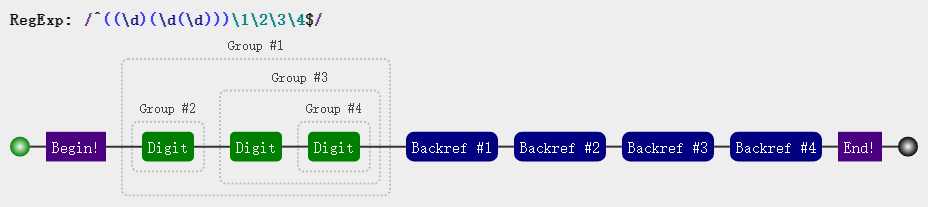
通过例子与图解应该不难理解,当存在多个括号嵌套时,从1−9的顺序对应括号嵌套就是从外到内,从左到右的顺序。
$1 对应的是((\d)(\d(\d))),$2 对应的是第一个 (\d),$3 对应的是 (\d(\d)),$4 对应的是 $3 中的 (\d)。
虽然我们在前面说的是$1-$9,准确来说,只要你的分组够多,我们甚至能使用$1000都行,比如:
const regex = /(a)(b)(c)(d)(e)(f)(g)(h)(i)(j)(k)(l)\12+/;
const string = "abcdefghijkllll";
regex.test(string);//true
console.log(RegExp.$12);//undefined

可以看到 \12 确实指向了前面的(l)分组,但由于RegExp对象只提供了 $1-$9 的属性,所以这里我们输出RegExp.$12是undefined。
还有一个问题,如果我们反向引用了不存在的分组会怎么样呢?很好理解,直接看个例子:
const regex = /\1\2\3/;
const string = "\1\2\3";
regex.test(string);//true
console.log(RegExp.$1);//为空
由于在\1前面不存在任何分组,所以这里的\1\2\3就单纯变成转义符\和三个数字 123 了,不会代指任何分组。
最后一点,分组后面如果有量词,分组会记录匹配的最后一次的数据,看个例子:
const regex = /(\w)+/;
const string = "abcde";
console.log(regex.exec(string));// ["abcde", "e", index: 0, input: "abcde", groups: undefined]
可以看到分组匹配的结果为e,也就是最后捕获的数据,但index还是为 0,表示捕获结果的开始位置。
所以在分组有量词的情况下使用反向引用,它也会指向捕获最大次数最后一次的结果。
const regex = /(\w)+\1/;
regex.test('abcdea');//false
regex.test('abcdee');//true
const regex1 = /(\w)+\1/;
regex1.test('abcdee');
console.log(RegExp.$1);//e十一、非捕获括号
在前面讲述分组匹配以及反向引用时,我们都知道正则其实将分组匹配的结果都储存起来了,不然也不会有反向引用这个功能,那么如果我们不需要使用反向引用,说直白点就是不希望分组去记录那些数据,怎么办呢?这里就可以使用非捕获括号了。
写法很简单,就是在正则条件加上 ?: 即可,例如(?:p) 和 (?:p1|p2|p3),我们来做个试验,看看最终match 输出结果:
const regex = /(ab)+/;
const string = "ababa aab ababab";
string.match(regex);
console.log(RegExp.$1);//ab
javascript
const regex = /(?:ab)+/;
const string = "ababa aab ababab";
string.match(regex);
console.log(RegExp.$1);//空
我们分别在正则分组 ab前面加或不加 ?:,再分别输出 RegExp.$1 ,可以看到普通分组记录了最后一次的匹配结果,而非捕获括号单纯起到了匹配作用,并没有去记录匹配结果。

那么到这里,第三章知识全部解释完毕,我们来做一个技术总结,大家可以参照下方思维导图回顾知识点,看看是否还熟记于心头。

最后留两个思考题,请模拟实现 trim方法,即使用正则去除字符串开头与结尾的空白符。第二个,请将my name is echo每个单词首字母转为大写。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 123
- 统信桌面专业版【全盘安装UOS系统】介绍 117
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 109
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 102
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
