Llama2-Chinese项目:2.1-Atom-7B预训练(二)
3.raw_datasets = load_dataset(...)
解析:加载原始数据集,如下所示: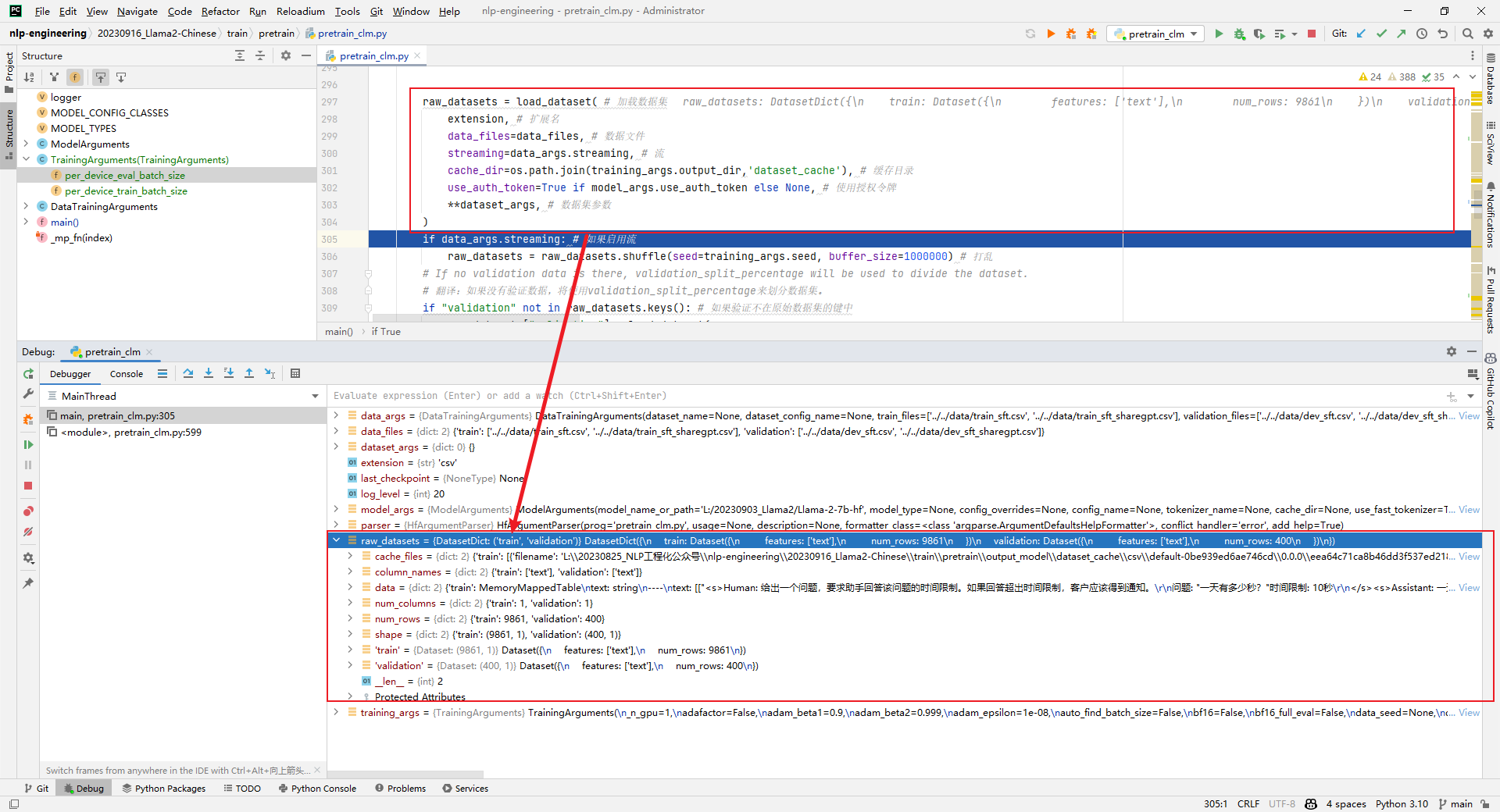
4.config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
解析:加载config,如下所示: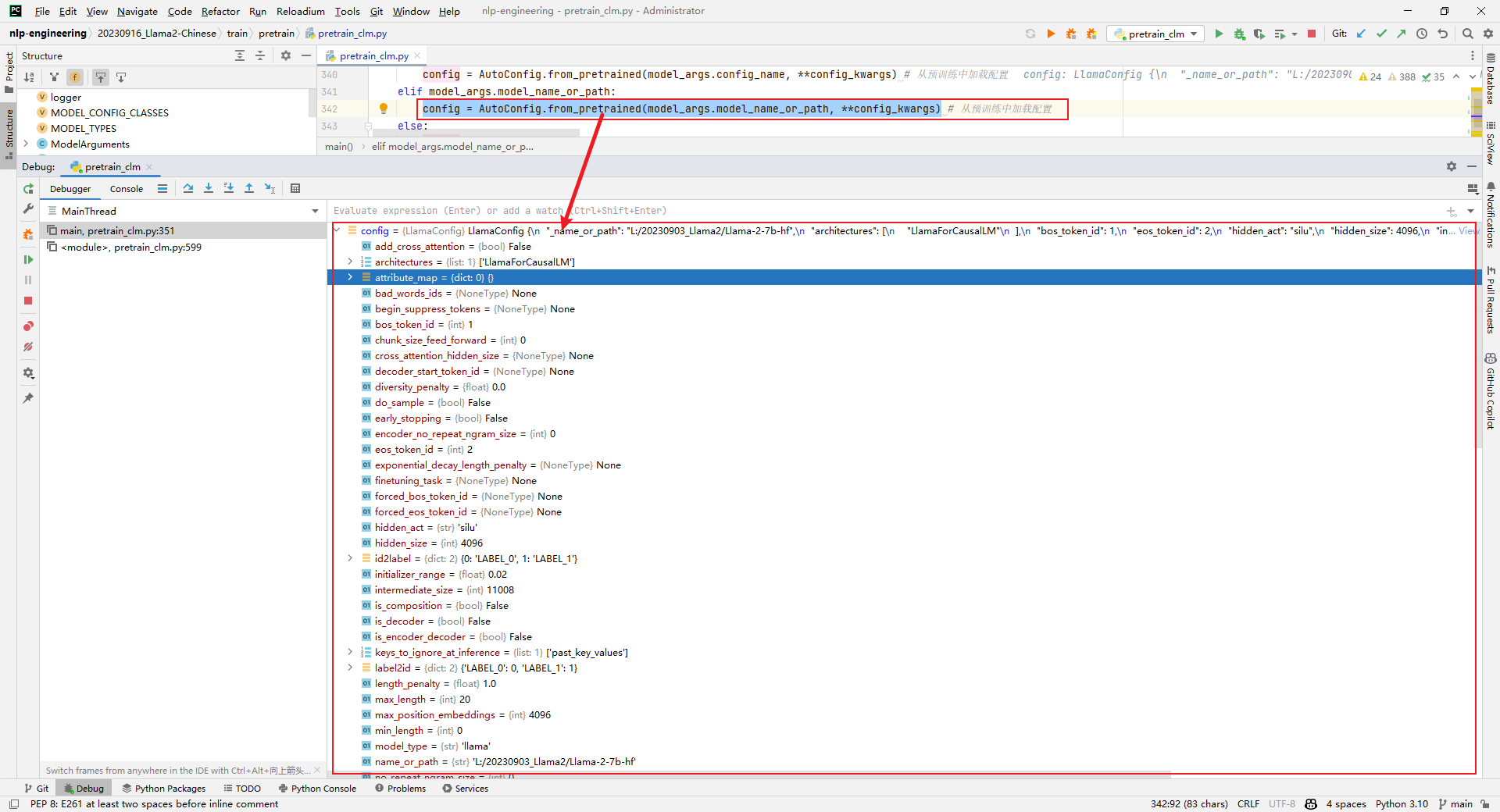
5.tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
解析:加载tokenizer,如下所示: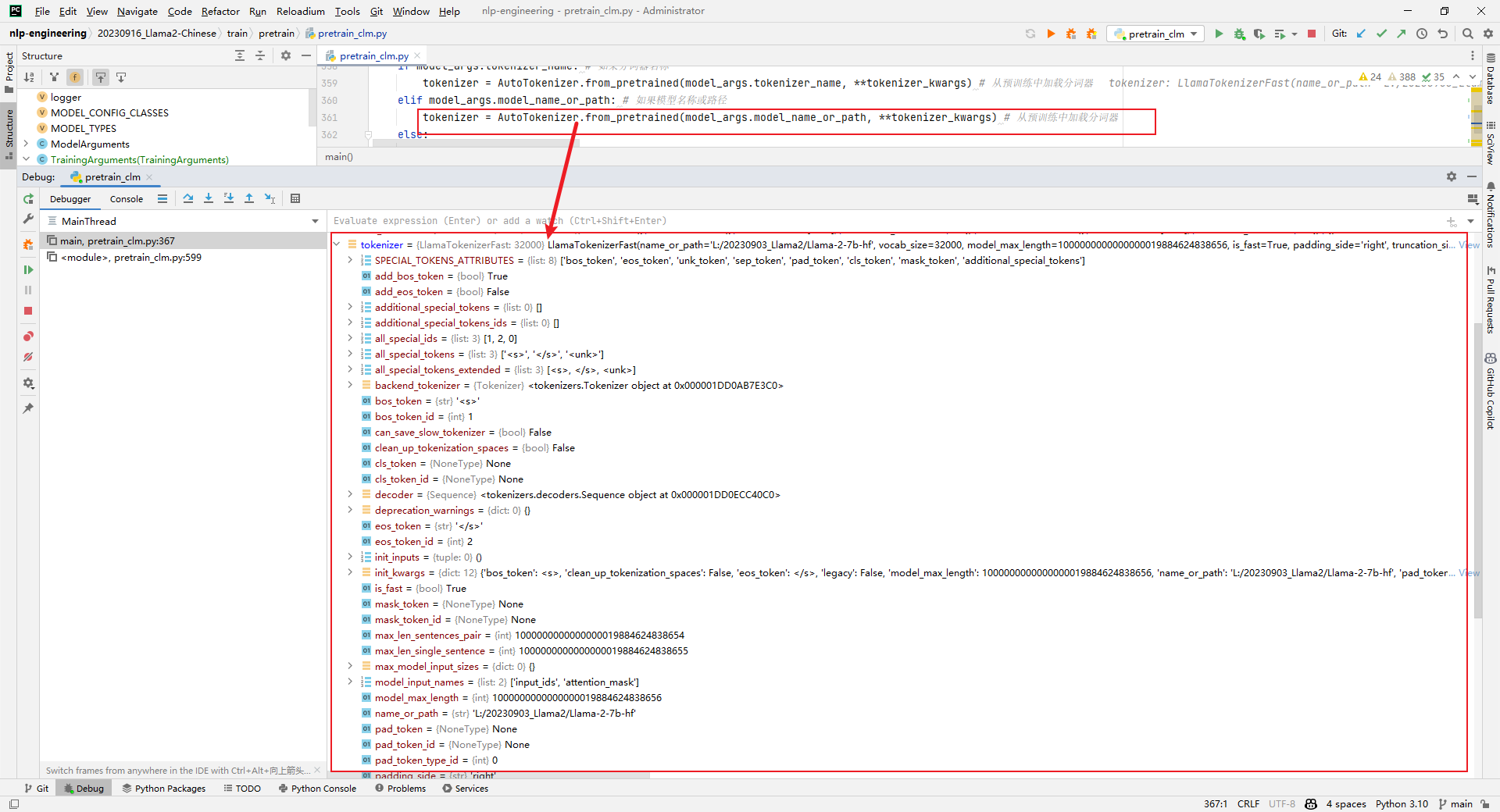
6.model = AutoModelForCausalLM.from_pretrained()
解析:加载model,这一步非常耗时,如下所示: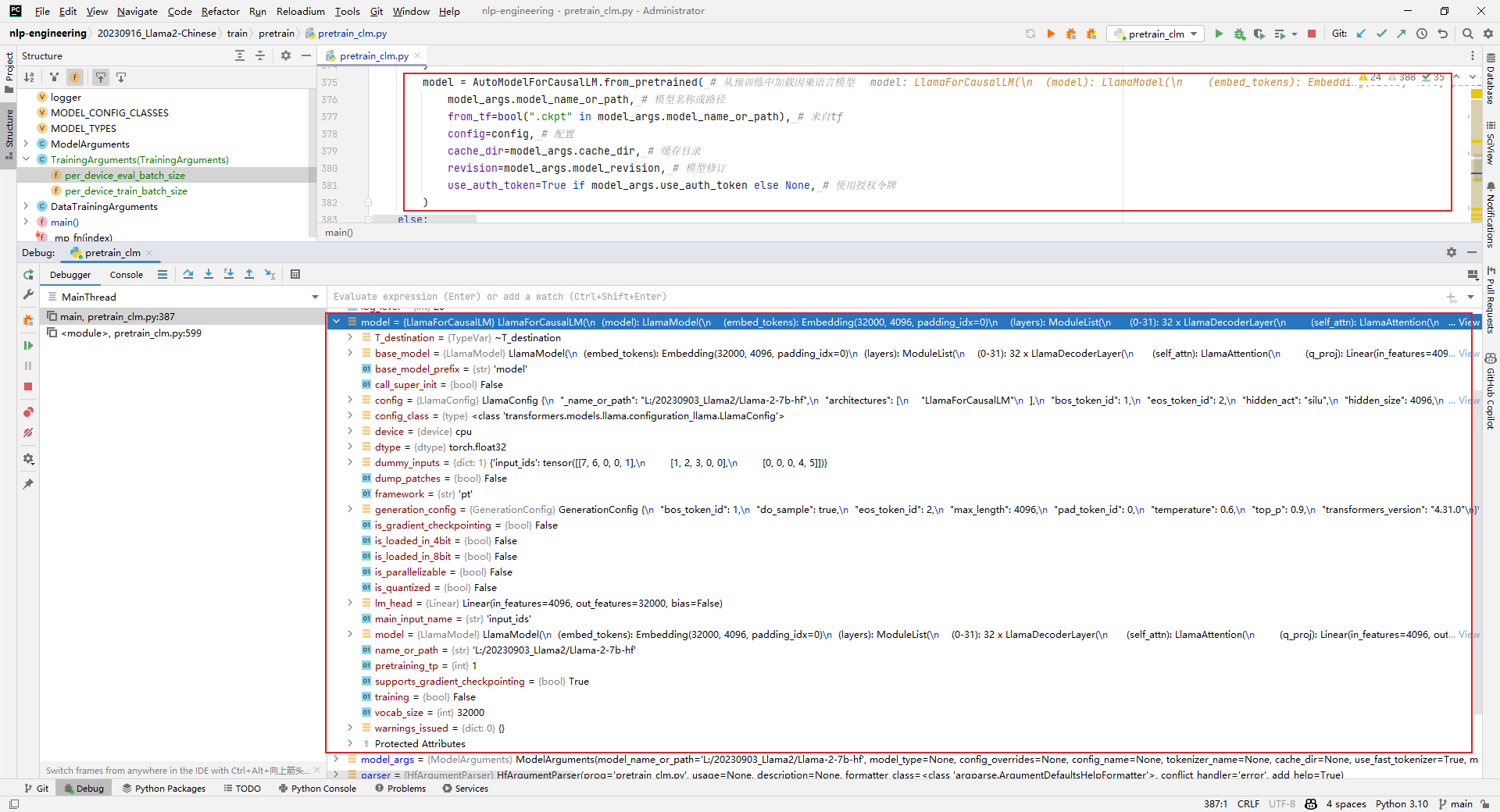
7.tokenized_datasets = raw_datasets.map()
解析:原始数据集处理,比如编码等,如下所示: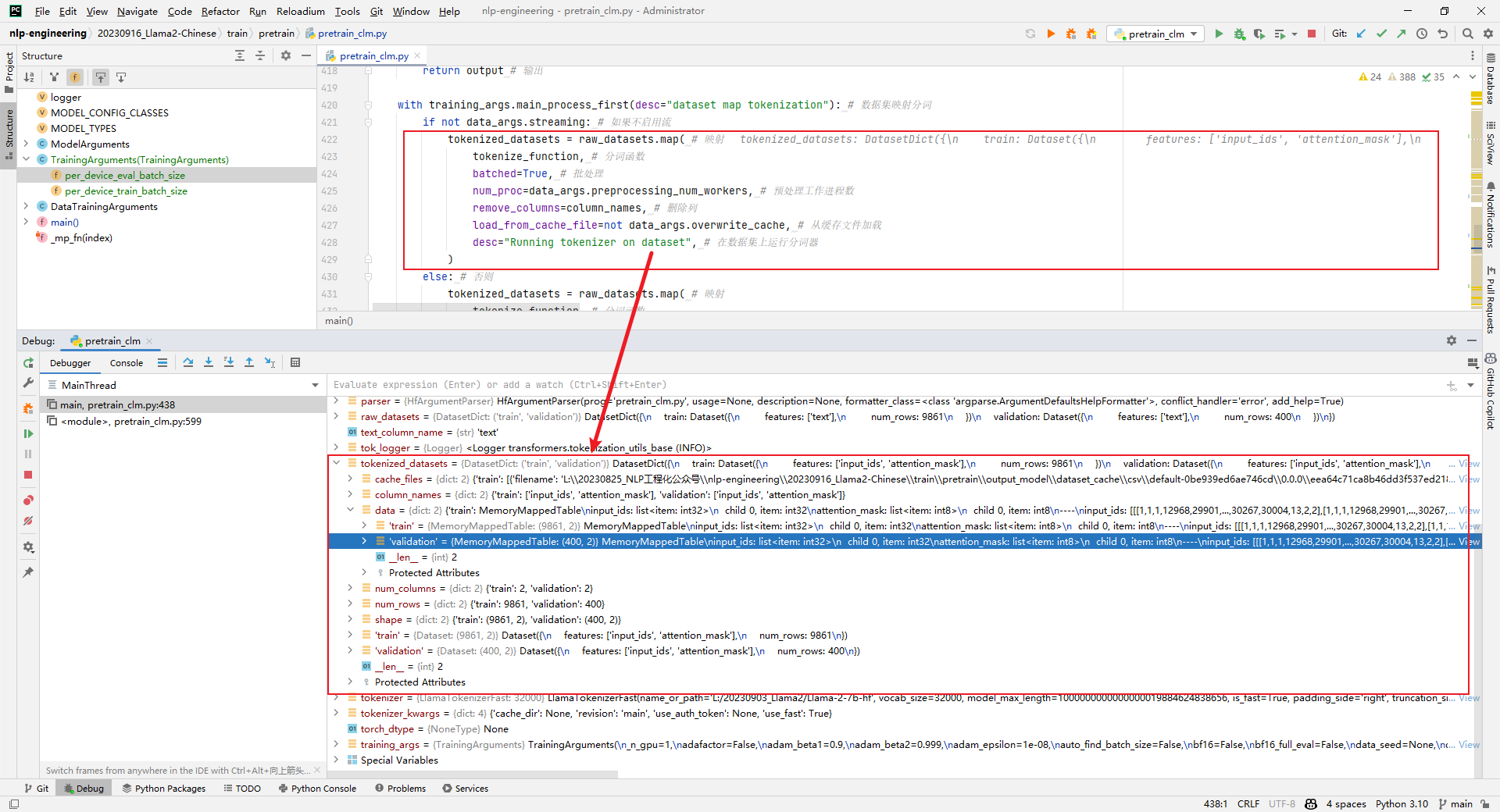
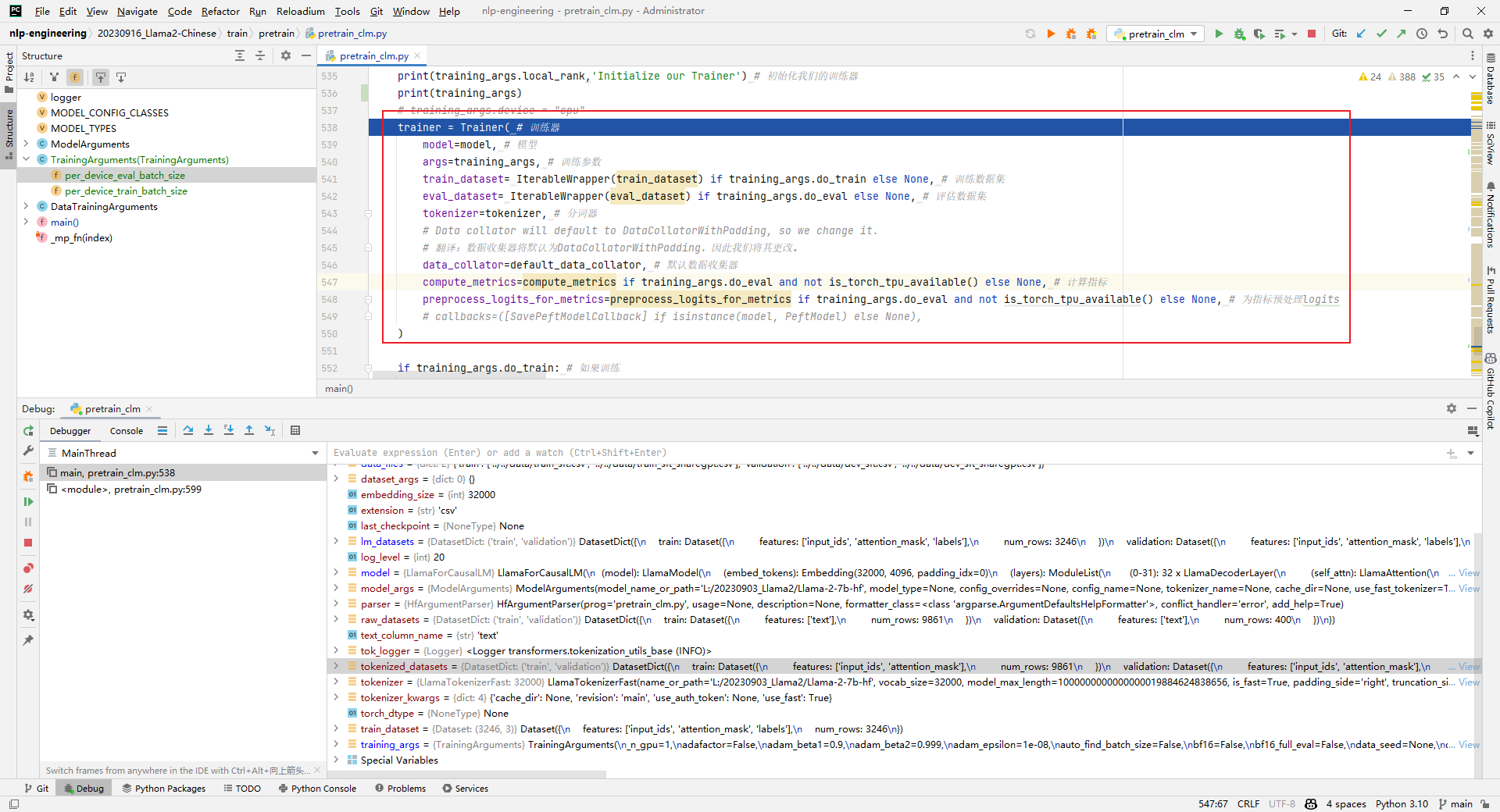
8.trainer = Trainer()
解析:实例化一个trainer,用于后续的训练或评估。跑到这一步的时候就报OOM了。如下所示:
trainer = Trainer( # 训练器
model=model, # 模型
args=training_args, # 训练参数
train_dataset= IterableWrapper(train_dataset) if training_args.do_train else None, # 训练数据集
eval_dataset= IterableWrapper(eval_dataset) if training_args.do_eval else None, # 评估数据集
tokenizer=tokenizer, # 分词器
# Data collator will default to DataCollatorWithPadding, so we change it.
# 翻译:数据收集器将默认为DataCollatorWithPadding,因此我们将其更改。
data_collator=default_data_collator, # 默认数据收集器
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None, # 计算指标
preprocess_logits_for_metrics=preprocess_logits_for_metrics if training_args.do_eval and not is_torch_tpu_available() else None, # 为指标预处理logits
# callbacks=([SavePeftModelCallback] if isinstance(model, PeftModel) else None),
)
说过:阅读pretrain_clm.py代码有几个疑问:中文词表是什么扩展的?上下文长度如何扩增?如何预训练text数据?后续再写文章分享。
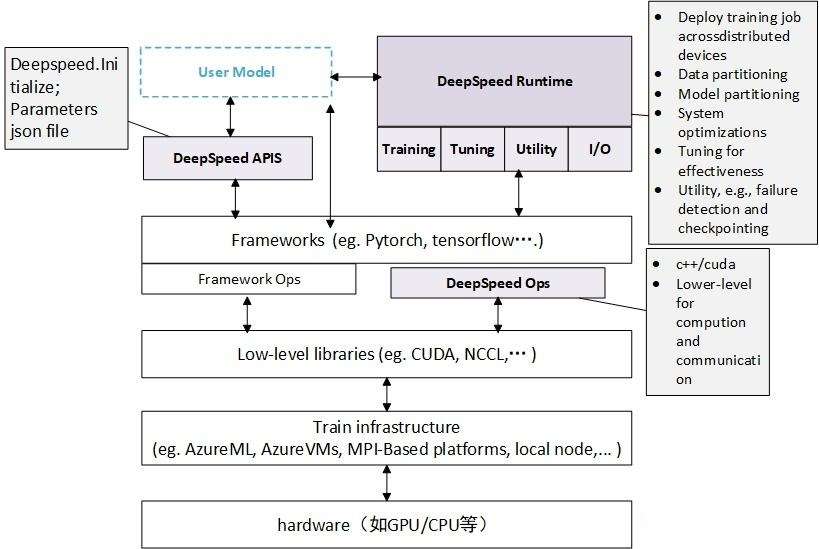
三.DeepSpeed加速
DeepSpeed是一个由微软开发的开源深度学习优化库,旨在提高大规模模型训练的效率和可扩展性。它通过多种技术手段来加速训练,包括模型并行化、梯度累积、动态精度缩放、本地模式混合精度等。DeepSpeed还提供了一些辅助工具,如分布式训练管理、内存优化和模型压缩等,以帮助开发者更好地管理和优化大规模深度学习训练任务。此外,deepspeed基于pytorch构建,只需要简单修改即可迁移。DeepSpeed已经在许多大规模深度学习项目中得到了应用,包括语言模型、图像分类、目标检测等等。
DeepSpeed主要包含三部分:
- Apis:提供易用的api接口,训练模型、推理模型只需要简单调用几个接口即可。其中最重要的是initialize接口,用来初始化引擎,参数中配置训练参数及优化技术等。配置参数一般保存在config.json文件中。
- Runtime:运行时组件,是DeepSpeed管理、执行和性能优化的核心组件。比如部署训练任务到分布式设备、数据分区、模型分区、系统优化、微调、故障检测、checkpoints保存和加载等。该组件使用Python语言实现。
- Ops:用C++和CUDA实现底层内核,优化计算和通信,比如ultrafast transformer kernels、fuse LAN kernels、cusomary deals等。
1.Windows10安装DeepSpeed
解析:管理员启动cmd:
build_win.bat
python setup.py bdist_wheel
2.安装编译工具
在Visual Studio Installer中勾选"使用C++的桌面开发",如下所示: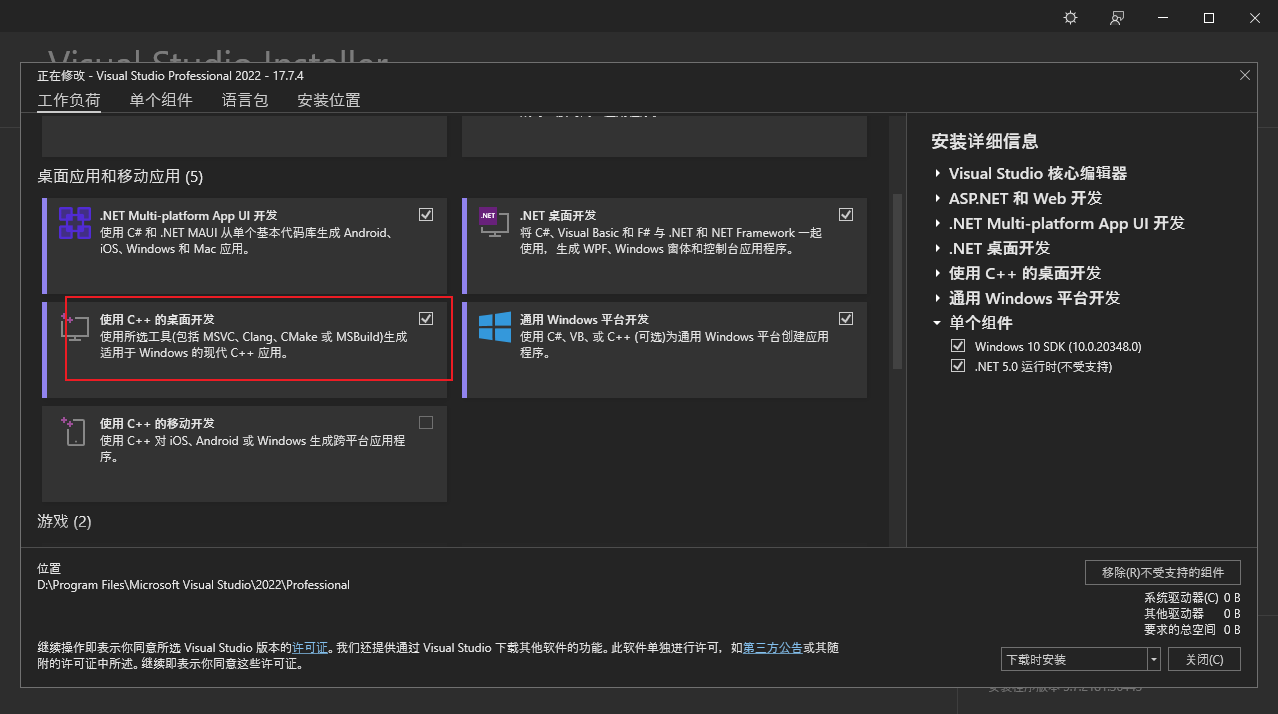
3.error C2665: torch::empty: 没有重载函数可以转换所有参数类型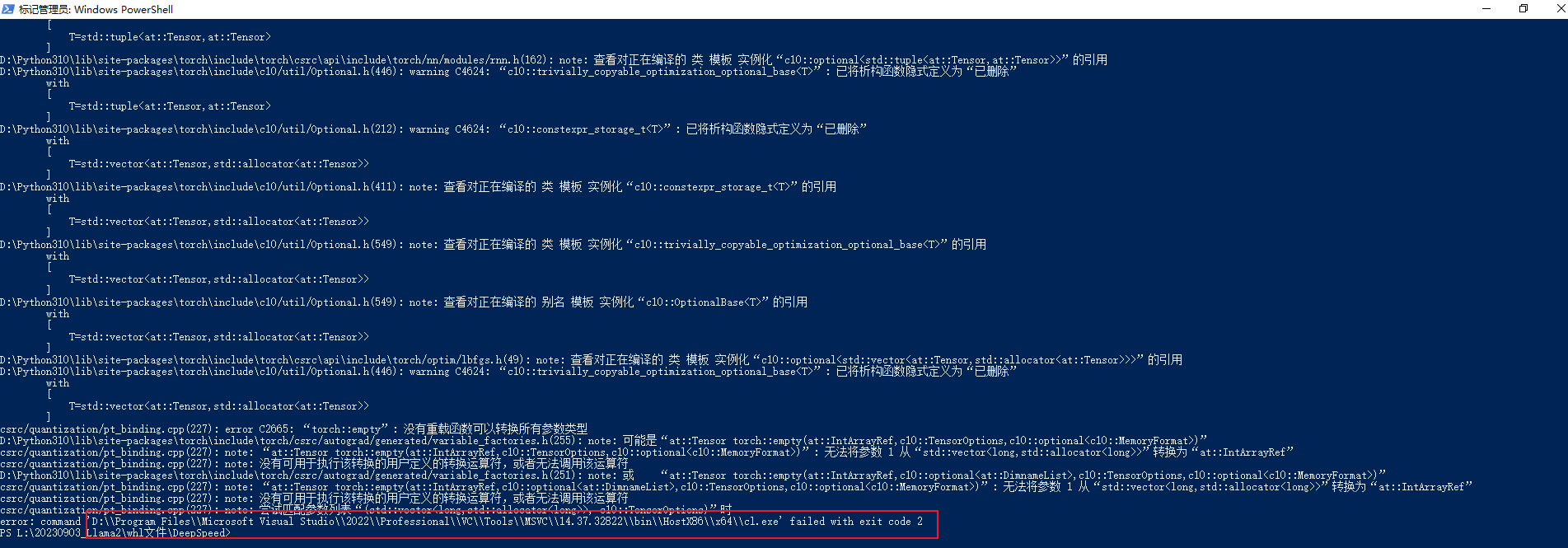
解决办法如下所示: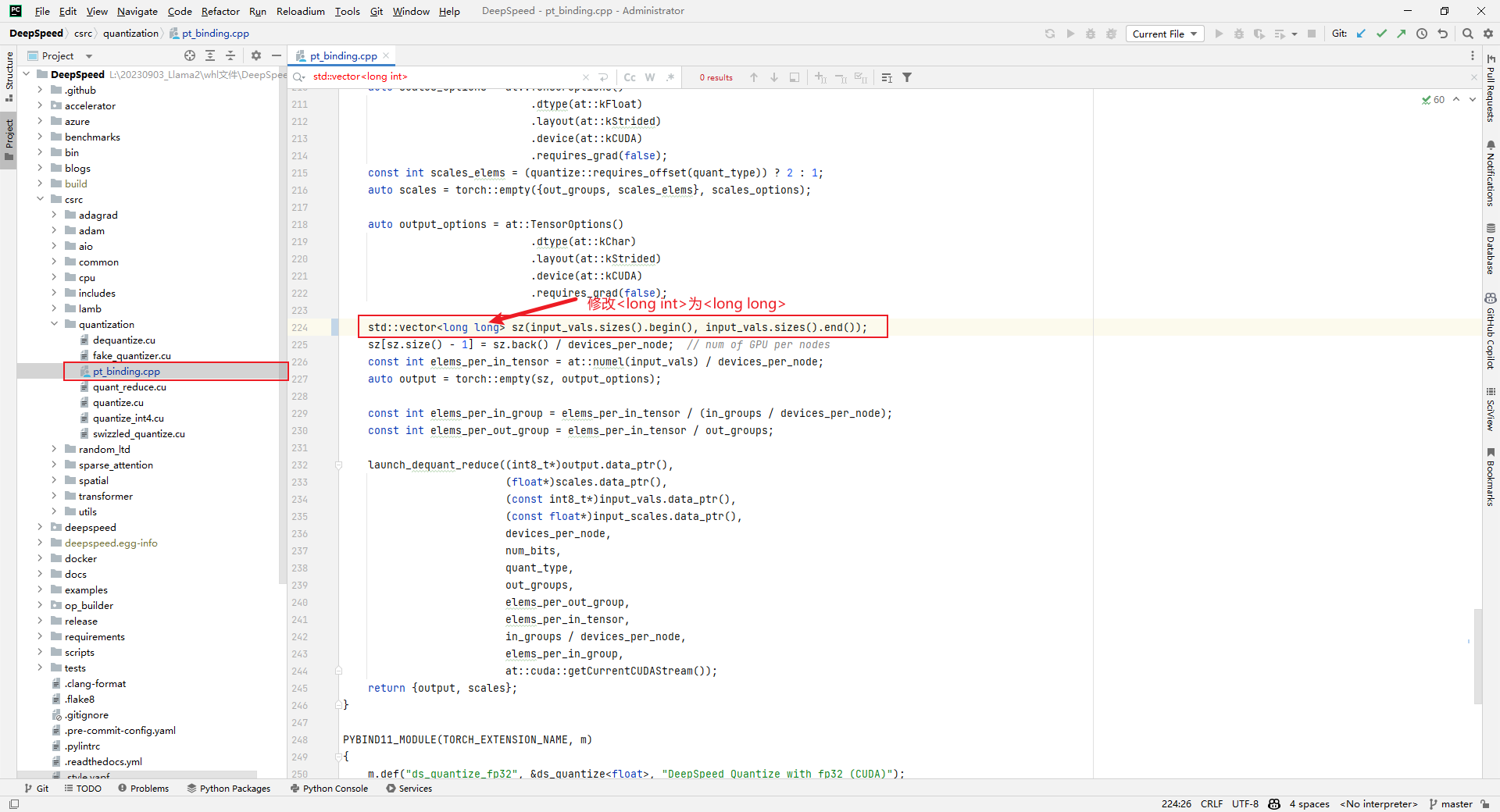
4.元素"1": 从"size_t"转换为"_Ty"需要收缩转换
解析:具体错误如下所示:
csrc/transformer/inference/csrc/pt_binding.cpp(536): error C2398: 元素"1": 从"size_t"转换为"_Ty"需要收缩转换
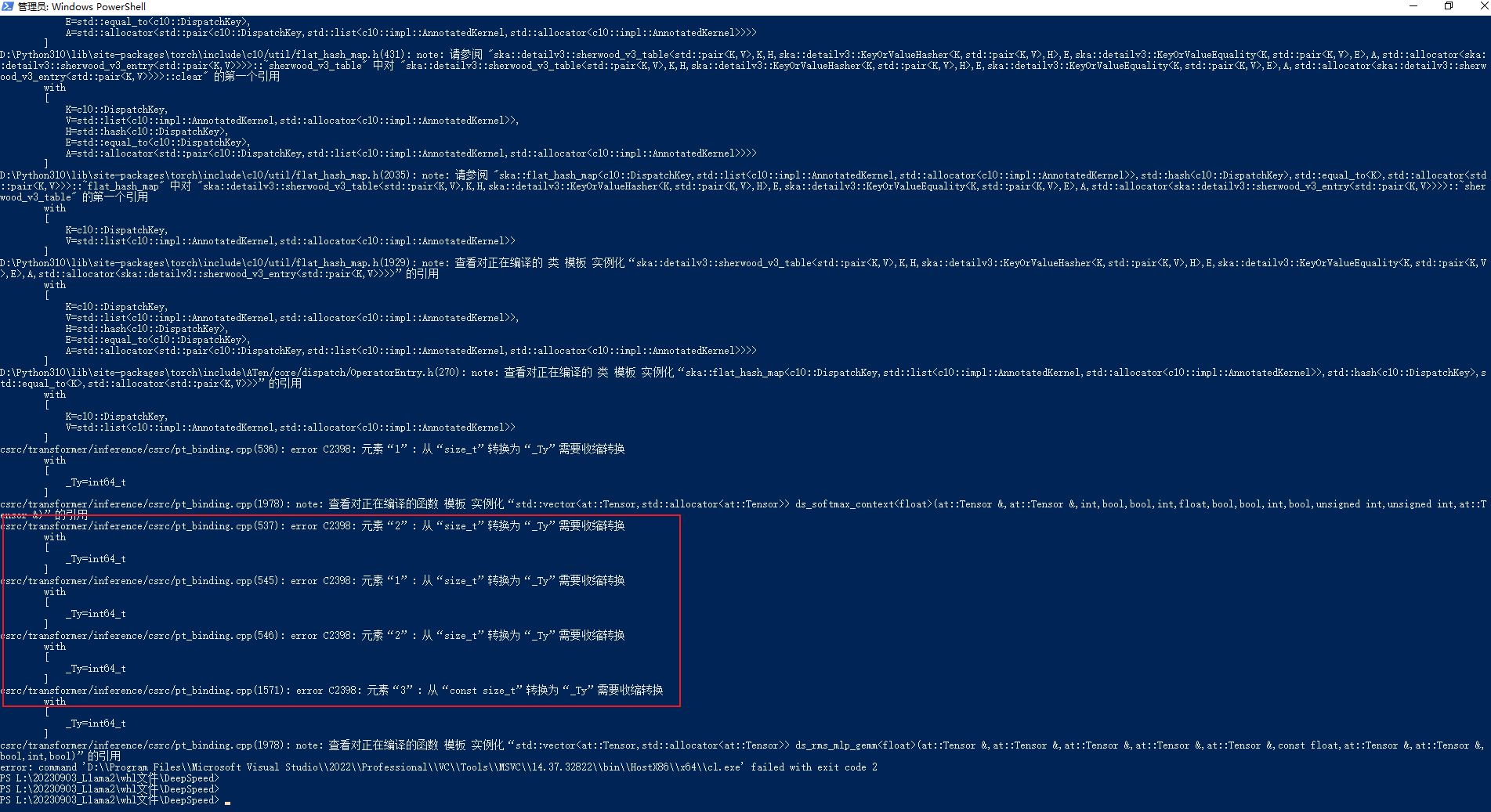
解析方案如下所示:
536:hidden_dim * (unsigned)InferenceContext
537:k * (int)InferenceContext
545:hidden_dim * (unsigned)InferenceContext
546:k * (int)InferenceContext
1570: input.size(1), (int)mlp_1_out_neurons
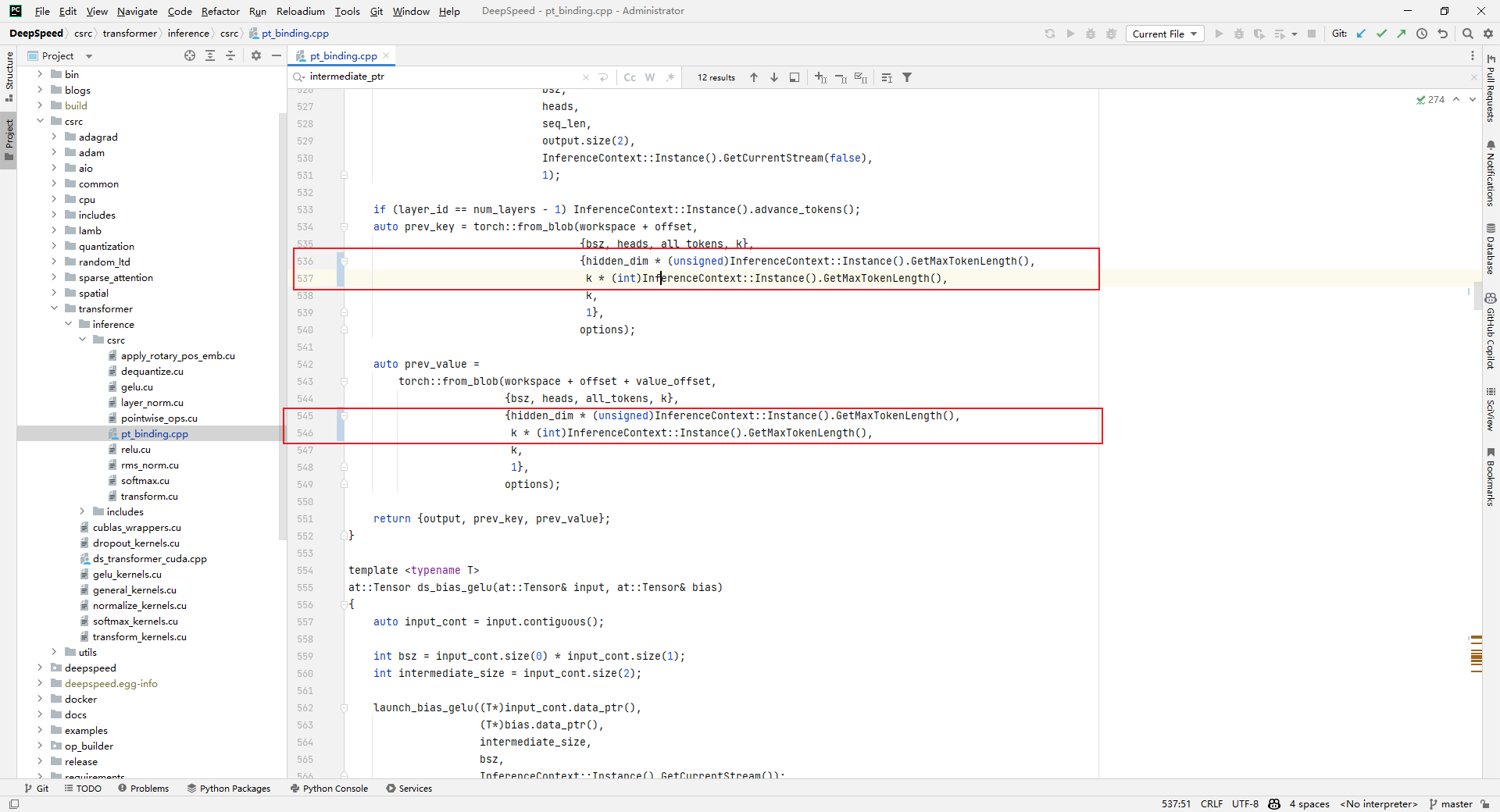
编译成功如下所示:
5.安装类库
PS L:\20230903_Llama2\whl文件\DeepSpeed\dist> pip3 install .\deepspeed-0.10.4+180dd397-cp310-cp310-win_amd64.whl
说明:由于DeepSpeed在Windows操作不友好,这部分只做学习使用。
6.单卡训练和多卡训练
(1)对于单卡训练,可以采用ZeRO-2的方式,参数配置见train/pretrain/ds_config_zero2.json
{
"fp16": { // 混合精度训练
"enabled": "auto", // 是否开启混合精度训练
"loss_scale": 0, // 损失缩放
"loss_scale_window": 1000, // 损失缩放窗口
"initial_scale_power": 16, // 初始损失缩放幂
"hysteresis": 2, // 滞后
"min_loss_scale": 1 // 最小损失缩放
},
"optimizer": { // 优化器
"type": "AdamW", // 优化器类型
"params": { // 优化器参数
"lr": "auto", // 学习率
"betas": "auto", // 衰减因子
"eps": "auto", // 除零保护
"weight_decay": "auto" // 权重衰减
}
},
"scheduler": { // 学习率调度器
"type": "WarmupDecayLR", // 调度器类型
"params": { // 调度器参数
"last_batch_iteration": -1, // 最后批次迭代
"total_num_steps": "auto", // 总步数
"warmup_min_lr": "auto", // 最小学习率
"warmup_max_lr": "auto", // 最大学习率
"warmup_num_steps": "auto" // 热身步数
}
},
"zero_optimization": { // 零优化
"stage": 2, // 零优化阶段
"offload_optimizer": { // 优化器卸载
"device": "cpu", // 设备
"pin_memory": true // 锁页内存
},
"offload_param": { // 参数卸载
"device": "cpu", // 设备
"pin_memory": true // 锁页内存
},
"allgather_partitions": true, // 全收集分区
"allgather_bucket_size": 5e8, // 全收集桶大小
"overlap_comm": true, // 重叠通信
"reduce_scatter": true, // 减少散射
"reduce_bucket_size": 5e8, // 减少桶大小
"contiguous_gradients": true // 连续梯度
},
"activation_checkpointing": { // 激活检查点
"partition_activations": false, // 分区激活
"cpu_checkpointing": false, // CPU检查点
"contiguous_memory_optimization": false, // 连续内存优化
"number_checkpoints": null, // 检查点数量
"synchronize_checkpoint_boundary": false, // 同步检查点边界
"profile": false // 档案
},
"gradient_accumulation_steps": "auto", // 梯度累积步骤
"gradient_clipping": "auto", // 梯度裁剪
"steps_per_print": 2000, // 每次打印步骤
"train_batch_size": "auto", // 训练批次大小
"min_lr": 5e-7, // 最小学习率
"train_micro_batch_size_per_gpu": "auto", // 每个GPU的训练微批次大小
"wall_clock_breakdown": false // 墙上时钟分解
}
(2)对于多卡训练,可以采用ZeRO-3的方式,参数配置见train/pretrain/ds_config_zero3.json
{
"fp16": { // 混合精度训练
"enabled": "auto", // 是否开启混合精度训练
"loss_scale": 0, // 损失缩放
"loss_scale_window": 1000, // 损失缩放窗口
"initial_scale_power": 16, // 初始缩放幂
"hysteresis": 2, // 滞后
"min_loss_scale": 1, // 最小损失缩放
"fp16_opt_level": "O2" // 混合精度优化级别
},
"bf16": { // 混合精度训练
"enabled": "auto" // 是否开启混合精度训练
},
"optimizer": { // 优化器
"type": "AdamW", // 优化器类型
"params": { // 优化器参数
"lr": "auto", // 学习率
"betas": "auto", // 衰减因子
"eps": "auto", // 除零保护
"weight_decay": "auto" // 权重衰减
}
},
"scheduler": { // 学习率调度器
"type": "WarmupDecayLR", // 学习率调度器类型
"params": { // 学习率调度器参数
"last_batch_iteration": -1, // 最后批次迭代
"total_num_steps": "auto", // 总步数
"warmup_min_lr": "auto", // 最小学习率
"warmup_max_lr": "auto", // 最大学习率
"warmup_num_steps": "auto" // 热身步数
}
},
"zero_optimization": { // 零优化
"stage": 3, // 零优化阶段
"overlap_comm": true, // 重叠通信
"contiguous_gradients": true, // 连续梯度
"sub_group_size": 1e9, // 子组大小
"reduce_bucket_size": "auto", // 减少桶大小
"stage3_prefetch_bucket_size": "auto", // 阶段3预取桶大小
"stage3_param_persistence_threshold": "auto", // 阶段3参数持久性阈值
"stage3_max_live_parameters": 1e9, // 阶段3最大活动参数
"stage3_max_reuse_distance": 1e9, // 阶段3最大重用距离
"gather_16bit_weights_on_model_save": true // 在模型保存时收集16位权重
},
"gradient_accumulation_steps": "auto", // 梯度累积步数
"gradient_clipping": "auto", // 梯度裁剪
"steps_per_print": 2000, // 每次打印步数
"train_batch_size": "auto", // 训练批次大小
"train_micro_batch_size_per_gpu": "auto", // 训练每个GPU的微批次大小
"wall_clock_breakdown": false // 墙上时钟分解
}
ZeRO-2和ZeRO-3间的比较如下所示(ChatGPT):
| 特征 | Zero2(0.2版本) | Zero3(0.3版本) |
|---|---|---|
| 内存占用优化 | 是 | 是 |
| 动态计算图支持 | 不支持 | 支持 |
| 性能优化 | 一般 | 更好 |
| 模型配置选项 | 有限 | 更多 |
| 分布式训练支持 | 是 | 是 |
| 具体应用 | 非动态计算图模型 | 动态计算图模型 |
四.训练效果度量指标accuracy.py代码的中文注释参考[1],主要在预训练评估的时候用到了该文件,如下所示:
train/pretrain/accuracy.py
metric = evaluate.load("accuracy.py") # 加载指标
五.中文测试语料
中文测试语料数据格式如下所示:
<s>Human: 问题</s><s>Assistant: 答案</s>
多轮语料将单轮的拼接在一起即可,如下所示:
<s>Human: 内容1\n</s><s>Assistant: 内容2\n</s><s>Human: 内容3\n</s><s>Assistant: 内容4\n</s>
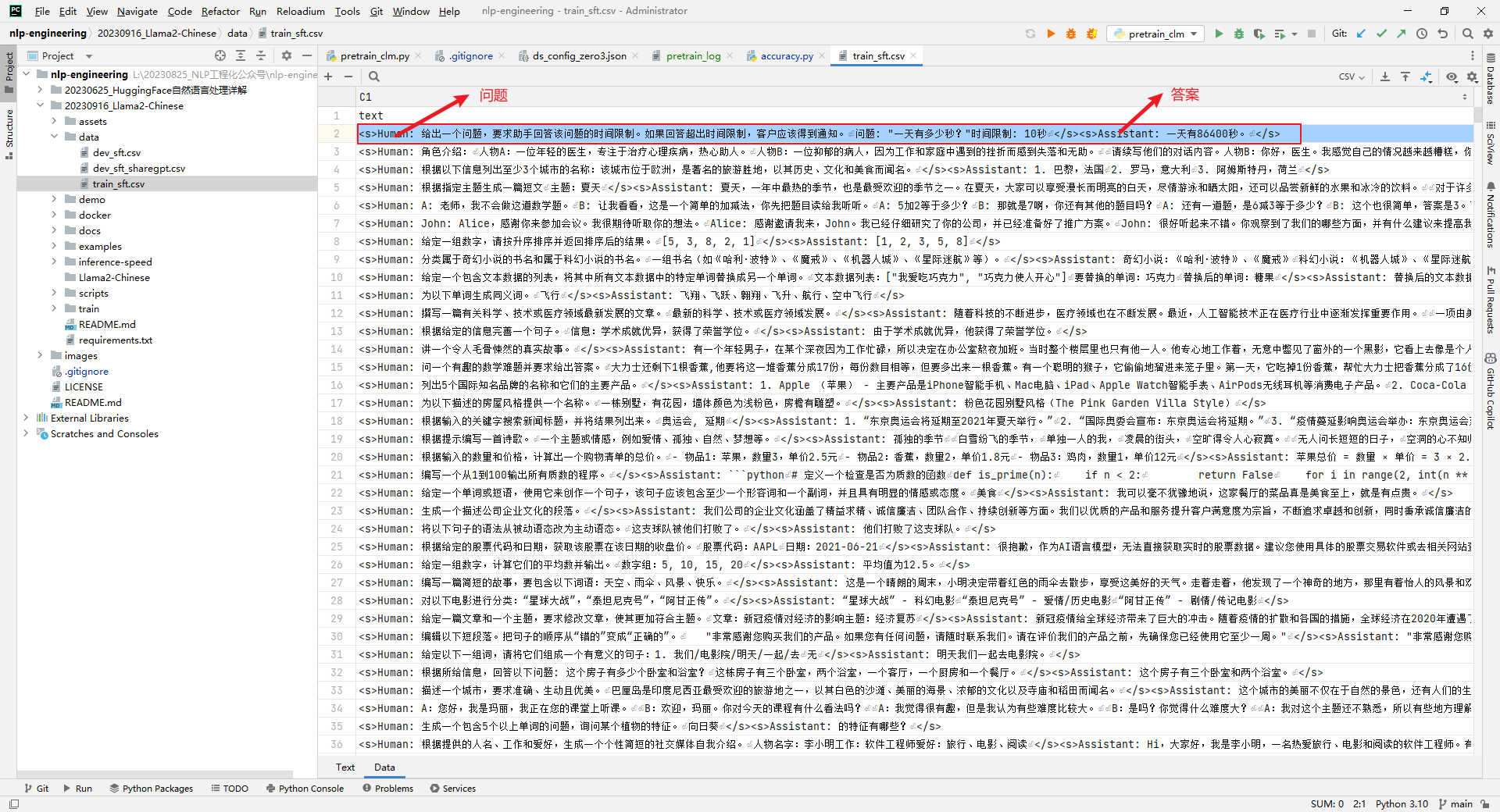
Llama2-Chinese项目中提供的train和dev文件共有3个,如下所示:
data\dev_sft.csv
data\dev_sft_sharegpt.csv
data\train_sft.csv
更多的语料可从Llama中文社区(https://llama.family/)链接下载: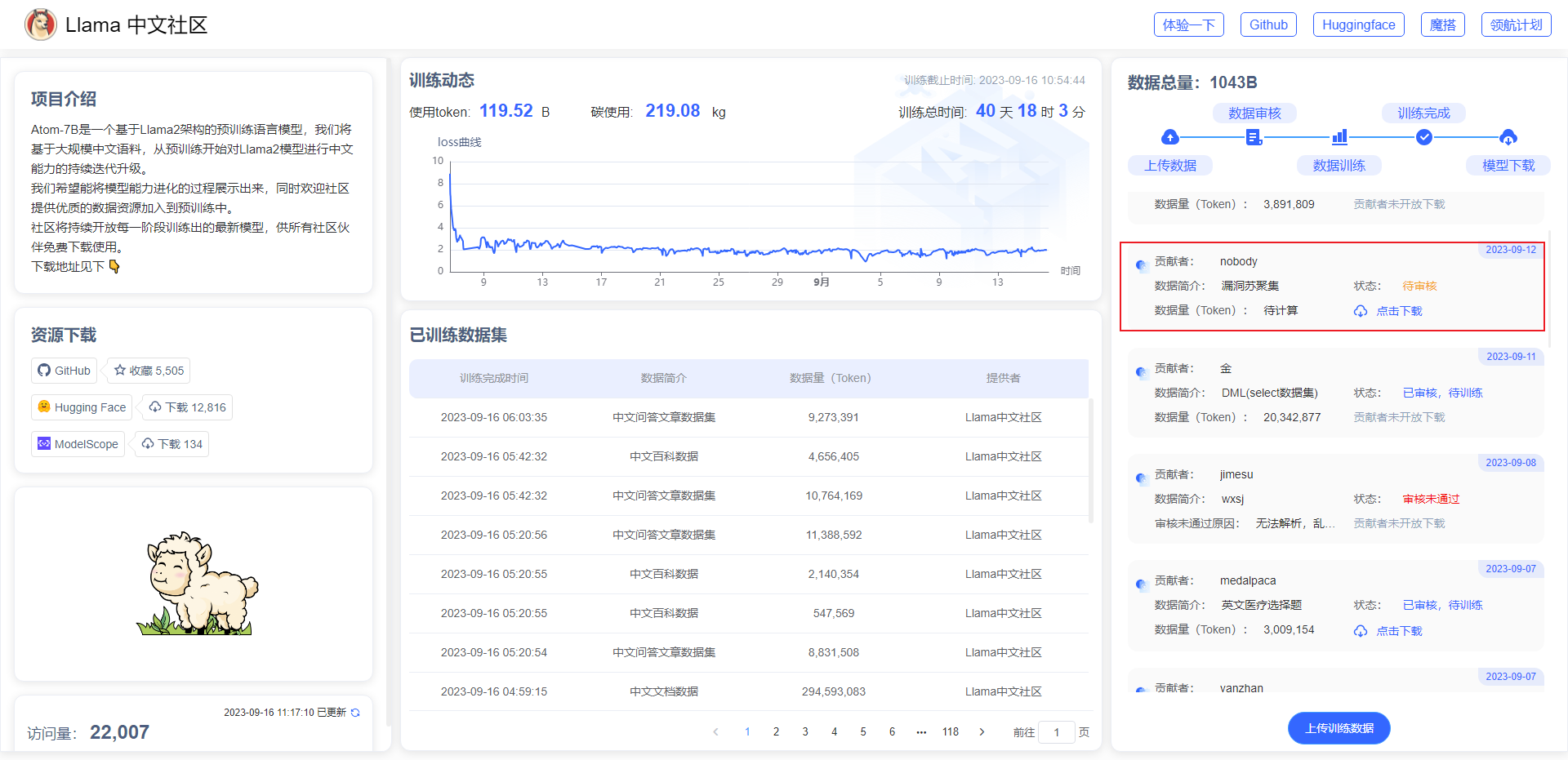
六.中文语料
Atom-7B是一个基于Llama2架构的预训练语言模型,Llama中文社区将基于大规模中文语料,从预训练开始对Llama2模型进行中文能力的持续迭代升级。通过以下数据来优化Llama2的中文能力:
| 类型 | 描述 |
|---|---|
| 网络数据 | 互联网上公开的网络数据,挑选出去重后的高质量中文数据,涉及到百科、书籍、博客、新闻、公告、小说等高质量长文本数据。 |
| Wikipedia | 中文Wikipedia的数据 |
| 悟道 | 中文悟道开源的200G数据 |
| Clue | Clue开放的中文预训练数据,进行清洗后的高质量中文长文本数据 |
| 竞赛数据集 | 近年来中文自然语言处理多任务竞赛数据集,约150个 |
| MNBVC | MNBVC 中清洗出来的部分数据集 |
说明:除了网络数据和竞赛数据集这2个没有提供链接,其它的4个都提供了数据集的链接。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 1554
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 1533
- 银河麒麟桌面操作系统【保留数据盘重装系统】 1487
- 麒麟系统各种原因开不了机解决(合集) 1212
- 统信桌面专业版【手动分区安装UOS系统】介绍 634
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 596
- 统信系统安装(合集) 563
- 桌面通用(全架构)【rpm包转成deb包】操作方法 488
- 统启动异常几种类型(initramfs 模式) 466
- 最近下载排行榜
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 0
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 0
- 银河麒麟桌面操作系统【保留数据盘重装系统】 0
- 麒麟系统各种原因开不了机解决(合集) 0
- 统信桌面专业版【手动分区安装UOS系统】介绍 0
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 0
- 统信系统安装(合集) 0
- 桌面通用(全架构)【rpm包转成deb包】操作方法 0
- 统启动异常几种类型(initramfs 模式) 0

prtyaa 收益393.72元

zlj141319 收益220.97元

1843880570 收益214.2元

IT-feng 收益213.03元

风晓 收益208.24元

777 收益172.82元

Fhawking 收益106.6元

信创来了 收益105.89元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
