- 微调需要的算力资源少,能够快速实现一个中文Llama的雏形。但缺点也显而易见,只能激发基座模型已有的中文能力,由于Llama2的中文训练数据本身较少,所以能够激发的能力也有限,治标不治本。
- 基于大规模中文语料进行预训练,成本高,不仅需要大规模高质量的中文数据,也需要大规模的算力资源。但是优点也显而易见,就是能从模型底层优化中文能力,真正达到治本的效果,从内核为大模型注入强大的中文能力。
下面从主要目标、训练数据、权重更新、数据转换和预处理、任务类型、示例应用和典型场景7个方面进行比较,如下所示(ChatGPT):
| 特征 | Pretraining(预训练) | Continuous Pretraining(继续预训练) | Fine-tuning(微调) | Post-Pretrain(预训练之后) |
|---|---|---|---|---|
| 主要目标 | 学习通用的表示 | 在通用表示上继续学习 | 在特定任务上调整模型 | 在预训练之后的额外学习和任务 |
| 训练数据 | 大规模文本数据集 | 额外的文本数据集 | 特定任务的数据集 | 额外的优化、领域适应或任务迁移 |
| 权重更新 | 权重更新 | 继续更新模型参数 | 在任务数据上进行权重更新 | 针对特定需求进行权重更新 |
| 数据转换和预处理 | 通常包括数据标准化、掩码预测等 | 与预训练相似的预处理 | 根据任务需求进行调整 | 针对特定需求进行数据处理和优化 |
| 任务类型 | 无监督学习、自监督学习 | 通常是自监督学习 | 监督学习 | 可以包括优化、领域适应、任务迁移等多种任务 |
| 示例应用 | BERT、GPT等 | 额外的预训练 | 文本分类、命名实体识别等 | 模型优化、领域适应、多任务学习等 |
| 典型场景 | 语言理解和生成 | 继续模型学习 | 特定文本任务 | 后续步骤和任务,用于定制和优化模型 |
说明:本文环境为Windows10,Python3.10,CUDA 11.8,GTX 3090(24G),内存24G。
一.模型预训练脚本
模型预训练脚本中的参数较多,只能在实践中来消化了。因为用的Windows10系统,所以运行shell脚本较麻烦,这部分不做过多介绍。如下所示:
train/pretrain/pretrain.sh
output_model=/mnt/data1/atomgpt # output_model:输出模型路径
if [ ! -d ${output_model} ];then # -d:判断是否为目录,如果不是目录则创建
mkdir ${output_model} # mkdir:创建目录
fi
cp ./pretrain.sh ${output_model} # cp:复制文件pretrain.sh到output_model目录下
cp ./ds_config_zero*.json ${output_model} # cp:复制文件ds_config_zero*.json到output_model目录下
deepspeed --num_gpus 1 pretrain_clm.py \ # deepspeed:分布式训练,num_gpus:使用的gpu数量,pretrain_clm.py:训练脚本
--model_name_or_path L:/20230903_Llama2/Llama-2-7b-hf \ # model_name_or_path:模型名称或路径
--train_files ../../data/train_sft.csv \ # train_files:训练数据集路径
../../data/train_sft_sharegpt.csv \
--validation_files ../../data/dev_sft.csv \ # validation_files:验证数据集路径
../../data/dev_sft_sharegpt.csv \
--per_device_train_batch_size 10 \ # per_device_train_batch_size:每个设备的训练批次大小
--per_device_eval_batch_size 10 \ # per_device_eval_batch_size:每个设备的验证批次大小
--do_train \ # do_train:是否进行训练
--output_dir ${output_model} \ # output_dir:输出路径
--evaluation_strategy steps \ # evaluation_strategy:评估策略,steps:每隔多少步评估一次
--use_fast_tokenizer false \ # use_fast_tokenizer:是否使用快速分词器
--max_eval_samples 500 \ # max_eval_samples:最大评估样本数,500:每次评估500个样本
--learning_rate 3e-5 \ # learning_rate:学习率
--gradient_accumulation_steps 4 \ # gradient_accumulation_steps:梯度累积步数
--num_train_epochs 3 \ # num_train_epochs:训练轮数
--warmup_steps 10000 \ # warmup_steps:预热步数
--logging_dir ${output_model}/logs \ # logging_dir:日志路径
--logging_strategy steps \ # logging_strategy:日志策略,steps:每隔多少步记录一次日志
--logging_steps 2 \ # logging_steps:日志步数,2:每隔2步记录一次日志
--save_strategy steps \ # save_strategy:保存策略,steps:每隔多少步保存一次
--preprocessing_num_workers 10 \ # preprocessing_num_workers:预处理工作数
--save_steps 500 \ # save_steps:保存步数,500:每隔500步保存一次
--eval_steps 500 \ # eval_steps:评估步数,500:每隔500步评估一次
--save_total_limit 2000 \ # save_total_limit:保存总数,2000:最多保存2000个
--seed 42 \ # seed:随机种子
--disable_tqdm false \ # disable_tqdm:是否禁用tqdm
--ddp_find_unused_parameters false \ # ddp_find_unused_parameters:是否找到未使用的参数
--block_size 4096 \ # block_size:块大小
--overwrite_output_dir \ # overwrite_output_dir:是否覆盖输出目录
--report_to tensorboard \ # report_to:报告给tensorboard
--run_name ${output_model} \ # run_name:运行名称
--bf16 \ # bf16:是否使用bf16
--bf16_full_eval \ # bf16_full_eval:是否使用bf16进行完整评估
--gradient_checkpointing \ # gradient_checkpointing:是否使用梯度检查点
--deepspeed ./ds_config_zero3.json \ # deepspeed:分布式训练配置文件
--ignore_data_skip true \ # ignore_data_skip:是否忽略数据跳过
--ddp_timeout 18000000 \ # ddp_timeout:ddp超时时间,18000000:18000000毫秒
| tee -a ${output_model}/train.log # tee:将标准输出重定向到文件,-a:追加到文件末尾
# --resume_from_checkpoint ${output_model}/checkpoint-20400 \# resume_from_checkpoint:从检查点恢复训练
二.预训练实现代码
Llama中文社区供了Llama模型的预训练代码,以及中文语料(参考第六部分)。本文在meta发布的Llama-2-7b基础上进行预训练,pretrain_clm.py代码的中文注释参考[0],执行脚本如下所示:
python pretrain_clm.py --output_dir ./output_model --model_name_or_path L:/20230903_Llama2/Llama-2-7b-hf --train_files ../../data/train_sft.csv ../../data/train_sft_sharegpt.csv --validation_files ../../data/dev_sft.csv ../../data/dev_sft_sharegpt.csv --do_train --overwrite_output_dir
说明:使用GTX 3090 24G显卡,还是报了OOM错误,但是并不影响调试学习,输出日志参考[2]。
1.代码结构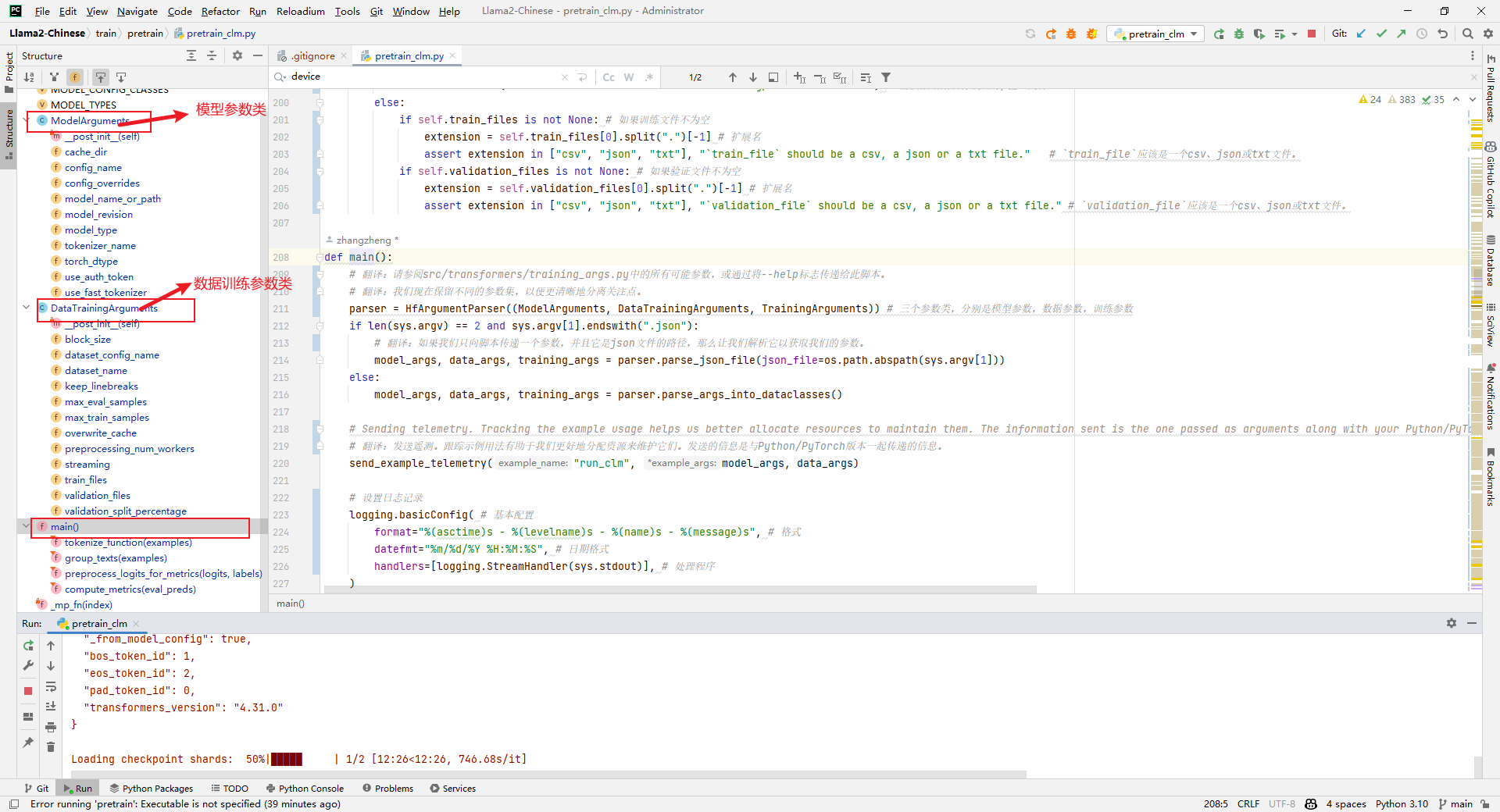
(1)ModelArguments:模型参数类
(2)DataTrainingArguments:数据训练参数类
(3)TrainingArguments:训练参数类
2.model_args, data_args, training_args = parser.parse_args_into_dataclasses()
解析:加载模型参数、数据训练参数和训练参数,如下所示: