丝析发解丨一个TCP性能优化点

最近读了一篇关于TCP性能优化的论文【1】,里面讲到一个普遍性的问题:一个TCP链接的收包和发包流程,经常在不同CPU核上运行,性能开销很大。对很多系统来说,解决掉这个问题,性能可以提升20%以上。

1
问题描述
随着网络速度提高,网卡接收报文的速度超过了单个CPU核的处理能力,为了解决这个问题,现在的很多网卡芯片都支持RSS(Receive Side Scaling)特性,也就是把接收到的TCP报文送给多个CPU核处理。
为了保证同一条TCP链接的报文被送到相同的CPU核上,网卡会用五元组(local_addr、remote_addr、local_port、remote_port、proto)来计算一个hash值,然后根据这个hash值,把报文送入不同的接收队列,不同队列由不同CPU核负责处理。具体实现方法是:不同的接收队列对应不同的中断号码,这些中断号码会被路由到不同的CPU核上去;网络报文到达后,通过中断通知CPU核,然后Linux内核会唤醒这个核上的软中断处理流程,在软中断中运行TCP接收报文的代码路径;然后唤醒上层应用线程,调用recvmsg()把报文从内核拷贝出去。也就是说,内核TCP的接收处理路径,是由网卡的RSS的Hash算法,以及网卡的接收队列中断和CPU核之间绑定关系决定的。
Linux内核的TCP发送处理路径,是与应用线程在同一个CPU核上。如果不做特殊处理,同一条TCP链接的接收流程和发送流程大概率是在不同CPU核上处理的。
由于接收流程和发送流程都需要访问TCP链接的数据结构,它们在不同CPU核上运行,就需要锁来保证互斥访问,会产生锁竞争。这些TCP数据结构频繁在不同CPU核的L1/L2 Cache之间迁移。锁竞争和Cache中数据的频繁迁移会产生很大性能开销。设法让同一条TCP的接收和发送流程在同一个CPU核上运行,成为优化TCP性能的一个重要方向。
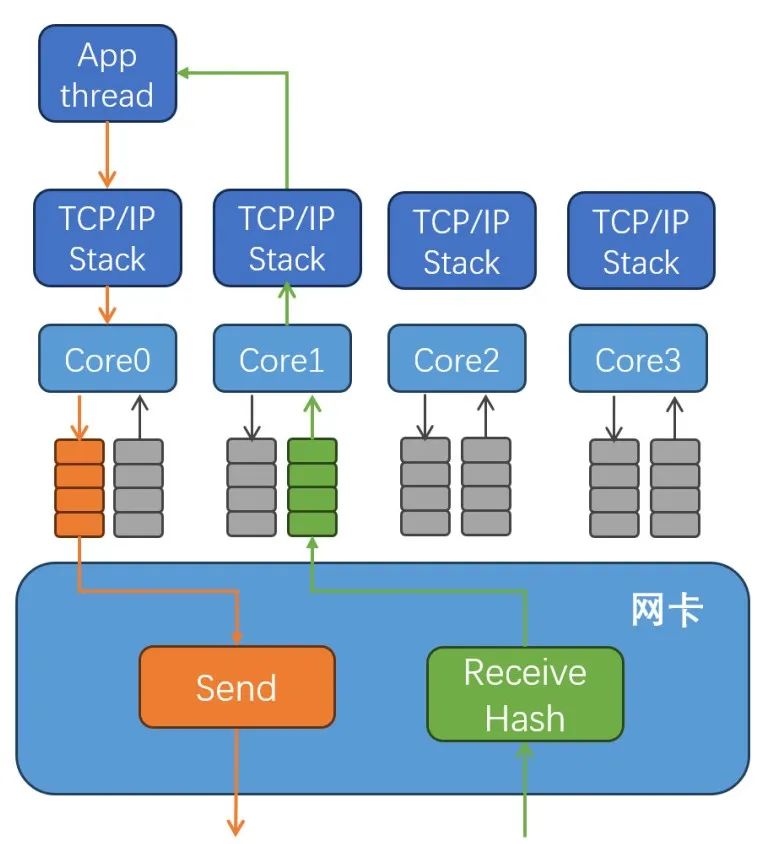
图2 多核CPU的TCP接收和发送
2
现有方案
流定向,即Flow Direct,简写为FD或FDir。有些网卡内部集成了一个路由表,软件可以配置这个路由表来决定某个特定TCP链接的报文被送到哪个接收队列中。一般来说,这个路由表中可配置的表项数量有限,也不是所有高速网卡都支持。
Intel某些型号网卡支持Application Targeting Routing(ATR),网卡自动配置FDir路由表,把TCP接收队列调整到发送流程所在的CPU核上,也不是所有网卡都支持这个特性。
除了上面这些网卡硬件实现的特性之外,Linux内核软件也实现了一些类似的特性。RPS是软件实现的RSS,由一个CPU核来处理网卡接收报文,然后把报文分发到多个CPU核上去,RFS可以把报文分发到上层应用所在的核。
本文开头提到的《Improving Network Connection Locality on Multicore System》论文【1】,提出了一个新方法。应用可以在多个线程中同时调用accept(),Linux内核选择这个新TCP链接的接收流程所在的CPU核返回accept()。这样处理这个TCP链接的应用线程所在的CPU核跟TCP链接的报文接收流程处理CPU核很大概率是相同的。但这个方案只对服务端起作用,对客户端不起作用,似乎最新的Linux内核代码也没包括这部分代码。
3
我的方法
我曾经发明过一种土方法,通过主动选择local_port,让网卡把收到的TCP消息送到应用线程所在的CPU核,从而避免TCP接收和发送在不同核上处理。
在TCP客户端调用connect()发起链接之前,先为这条链接选定一个本地端口号(local_port),并调用bind让这条TCP链接使用这个选定的本地端口号,避免让Linux内核在connect的自动选择一个随机的端口号;应用通过选定本地端口号,可以控制这个TCP链接的接收流程在特定的CPU核上运行,这样就可以控制TCP的接收和发送流程在相同的CPU核上运行;参与RSS的Hash值计算的五元组(local_addr, remote_addr, local_port, remote_port, proto)中的有四个都是固定的,只有local_port是一个可变的,控制local_port的值,可以让Hash函数算出期望的结果。如果这条TCP链接是一个集群内部的链接,使用该方法可以同时选择本地CPU核和远端的CPU核。
在 zStorage 里面,解决过很多类似的小问题,zStorage 的高性能就是靠很多个类似微创新积累起来才达到的。
关于 zStorage
zStorage 是云和恩墨针对数据库应用开发的高性能全闪分布式块存储。三节点 zStorage 集群可以达到200万IOPS随机读写性能,同时平均时延<300μs、P99时延小于800μs。
zStorage 支持多存储池、精简配置、快照/一致性组快照、链接克隆/完整克隆、NVMeoF/NVMeoTCP、iSCSI、CLI和API管理、快照差异位图(DCL)、慢盘检测、亚健康管理、16KB原子写、2副本、强一致3副本、Raft 3副本、IB和RoCE、TCP/IP、后台巡检、基于Merkle树的一致性校验、全流程TRIM、QoS、SCSI PR、SCSI CAW。
zStorage 是一个存储平台,可作为数据库产品和存储产品的底座,欢迎发邮件至 marketing@enmotech.com 咨询。
作者简介
黄岩,云和恩墨分布式存储软件总架构师,十余年存储研发经验,在NAS和备份领域有深入钻研,曾担任某NAS产品性能SE,负责产品性能调优工作,该产品在2011年打破了SPECsfs性能测试世界纪录。
「墨读时


数据驱动,成就未来,云和恩墨,不负所托!
云和恩墨创立于2011年,以“数据驱动,成就未来”为使命,是智能的数据技术提供商。我们致力于将数据技术带给每个行业、每个组织、每个人,构建数据驱动的智能未来。
云和恩墨在数据承载(分布式存储、数据持续保护)、管理(数据库基础软件、数据库云管平台、数据技术服务)、加工(应用开发质量管控、数据模型管控、数字化转型咨询)和应用(数据服务化管理平台、数据智能分析处理、隐私计算)等领域为各个组织提供可信赖的产品、服务和解决方案,围绕用户需求,持续为客户创造价值,激发数据潜能,为成就未来敏捷高效的数字世界而不懈努力。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1487
- 银河麒麟打印带有图像的文档时出错 1405
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1194
- 统信操作系统各版本介绍 1116
- 统信桌面专业版【如何查询系统安装时间】 1114
- 统信桌面专业版【全盘安装UOS系统】介绍 1069
- 麒麟系统也能完整体验微信啦! 1026
- 统信【启动盘制作工具】使用介绍 672
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 616
- 信刻全自动档案蓝光光盘检测一体机 526
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
