Dataset之MNIST:MNIST(手写数字图片识别及其ubyte.gz文件)数据集简介、下载、使用方法(包括数据增强)之详细攻略

Dataset之MNIST:MNIST(手写数字图片识别及其ubyte.gz文件)数据集简介、下载、使用方法(包括数据增强,将已有MNIST数据集通过移动像素上下左右的方法来扩大数据集为初始数据集的5倍))之详细攻略
目录
1、基于python语言根据爬虫技术自动下载MNIST数据集
MNIST数据集的简介
四个gz文件,一共大约11M左右。


MNIST是一个非常有名的手写体数字识别数据集(手写数字灰度图像数据集),在很多资料中,这个数据集都会被用作深度学习的入门样例。
MNIST数据集是由0 到9 的数字图像构成的。训练图像有6 万张,测试图像有1 万张。MNIST数据集是NIST数据集的一个子集,它包含了60000张图片作为训练数据,10000张图片作为测试数据。每一张图片都有对应的标签数字,训练图像一共高60000 张,供研究人员训练出合适的模型。测试图像一共高10000 张,供研究人员测试训练的模型的性能。

单张图片样本的矩阵表示

在上图中右侧显示了一张数字1的图片,而右侧显示了这个图片所对应的像素矩阵。
MNIST 数据集主要由一些手写数字的图片和相应的标签组成,图片一共高10 类, 分别对应从0~9 ,共10 个阿拉伯数字。在MNIST数据集中的每一张图片都代表了0~9中的一个数字。
MNIST的图像,每张图片是包含28 像素× 28 像素的灰度图像(1 通道),各个像素的取值在0 到255 之间。每个图像数据都相应地标有数字标签。每张图片都由一个28 ×28 的矩阵表示,每张图片都由一个784 维的向量表示(28*28=784),如图所示。图片的大小都为28*28,且数字都会出现在图片的正中间。 处理后的每一张图片是一个长度为784的一维数组,这个数组中的元素对应了图片像素矩阵中的每一个数字。

1、mnist 对象中各个属性的含义和大小


文件名 大小 特点
train-images-idx3-ubyte.gz ≈9.45 MB 训练图像数据
train-labels-idx 1-ubyte.gz ≈0.03MB 训练图像的标
ti Ok-images-idx3-ubyte.gz ≈ t.57MB 测试图像数据
t l Ok-labels-idxl-ubyte.gz ≈4.4KB 测试图像的标
原始的MNIST 数据集中包含60000 张训练图片和10000 张测试图片。
而在TensorFlow 中,又将原先的60000 张训练图片重新划分成了新的55000张训练图片和5000张验证图片。所以在mnist 对象中,数据一共分为三部分: mnist.train 是训练图片数据, mnist. validation 是验证图片数据,mnist.test是测试图片数据,这正好对应了机器学习中的训练集、验证集和测试集。一般来说,会在训练集上训练模型,通过模型在验证集上的表现调整参数,最后通过测试集确定模型的性能。
2、数据集的应用—训练和预测
这些图像可以用于学习和推理。MNIST数据集的一般使用方法是,先用训练图像进行学习,再用学习到的模型度量能在多大程度上对测试图像进行正确的分类。
在原始的MNIST 数据集中(官网MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges),可以找到多达68 种模型在该数据集上的准确率数据,包括相应的论文出处。这些模型包括线性分类器、K 近邻方法、普通的神经网络、卷积神经网络等。
3、基于MNIST数据集最新算法预测准确率对比
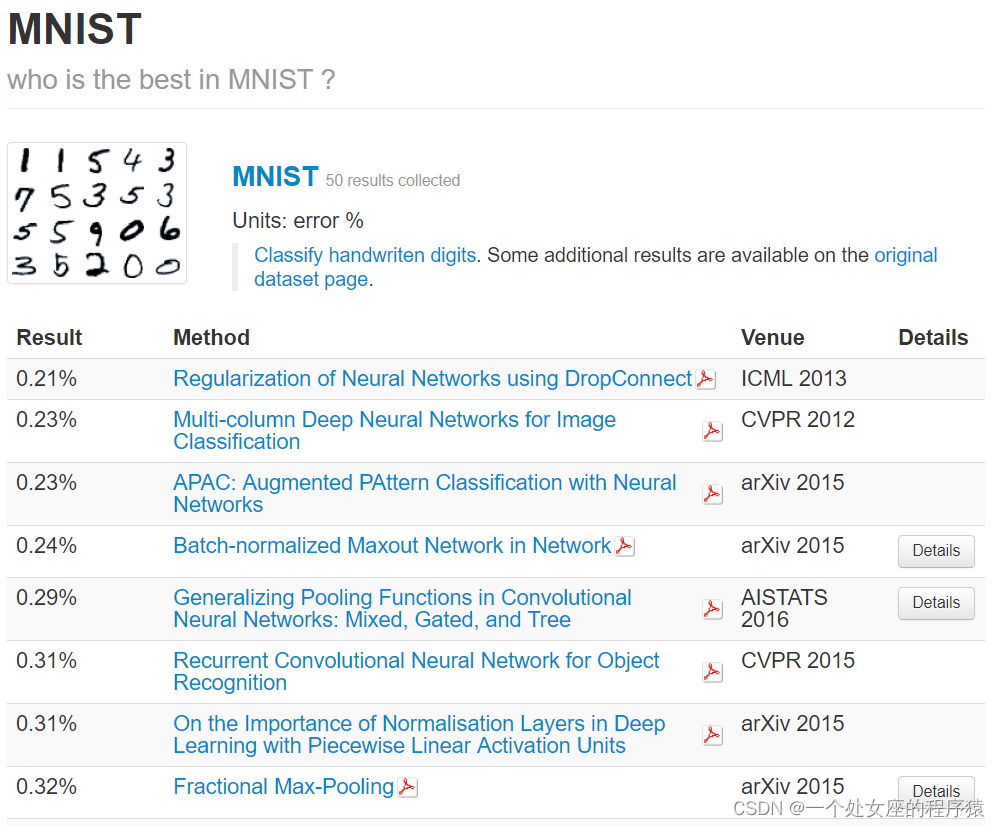
相关链接: Classification datasets results
MNIST数据集的下载
1、基于python语言根据爬虫技术自动下载MNIST数据集
Dataset之MNIST:自定义函数mnist.load_mnist根据网址下载mnist数据集(四个ubyte.gz格式数据集文件)
Dataset之MNIST:MNIST(手写数字图片识别+ubyte.gz文件)数据集的下载(基于python语言根据爬虫技术自动下载MNIST数据集)
2、TensorFlow的封装下使用MNIST数据集
TensorFlow的封装让使用MNIST数据集变得更加方便。
MNIST数据集提供了4个下载文件,在tensorflow中可将这四个文件直接下载放于一个目录中并加载,如下代码所示,如果指定目录中没有数据,那么tensorflow会自动去网络上进行下载。通过input_data.read_data_sets函数生成的类会自动将MNIST数据集划分为train, validation和test三个数据集。
其中train这个集合内含有55000张图片,validation集合内含有5000张图片,这两个集合组成了MNIST本身提供的训练数据集。test集合内有10000张图片,这些图片都来自与MNIST提供的测试数据集。
(1)、MNIST数据集下载及输出基本信息
- import tensorflow as tf
- from tensorflow.examples.tutorials.mnist import input_data 这是TensorFlow 为了教学Mnist而提前设计好的程序
- number 1 to 10 data
- mnist = input_data.read_data_sets('MNIST_data', one_hot=True) TensorFlow 会检测数据是否存在。当数据不存在时,系统会自动,在当前代码py文件位置,自动创建MNIST_data文件夹,并将数据下载到该件夹内。当执行完语句后,读者可以自行前往MNIST_data/文件夹下查看上述4 个文件是否已经被正确地下载
- 若因网络问题无法正常下载,可以前往MNIST官网http://yann.lecun.com/exdb/mnist/使用下载工具下载上述4 个文件, 并将它们复制到MNIST_data/文件夹中。
-
-
- 查看训练数据的大小
- print(mnist.train.images.shape) (55000, 784)
- print(mnist.train.labels.shape) (55000, 10)
-
- 查看验证数据的大小
- print(mnist.validation.images.shape) (5000, 784)
- print(mnist.validation.labels.shape) (5000, 10)
-
- 查看测试数据的大小
- print(mnist.test.images.shape) (10000, 784)
- print(mnist.test.labels.shape) (10000, 10)
-
- print(mnist.train.images[0,:]) 打印出第0张训练图片对应的向量表示
-
(2)、利用TF查看MNIST数据集中训练集的前20张图片
- 利用TF查看MNIST数据集中训练集的前20张图片
- from tensorflow.examples.tutorials.mnist import input_data
- import scipy.misc
- import os
-
- 读取MNIST数据集。如果不存在会事先下载。
- mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
-
- 我们把原始图片保存在MNIST_data/raw/文件夹下
- 如果没有这个文件夹会自动创建
- save_dir = 'MNIST_data/raw/'
- if os.path.exists(save_dir) is False:
- os.makedirs(save_dir)
-
- 保存前20张图片
- for i in range(20):
- 请注意,mnist.train.images[i, :]就表示第i张图片(序号从0开始)
- image_array = mnist.train.images[i, :]
- TensorFlow中的MNIST图片是一个784维的向量,我们重新把它还原为28x28维的图像。
- image_array = image_array.reshape(28, 28)
- 保存文件的格式为 mnist_train_0.jpg, mnist_train_1.jpg, ... ,mnist_train_19.jpg
- filename = save_dir + 'mnist_train_%d.jpg' % i
- 将image_array保存为图片
- 先用scipy.misc.toimage转换为图像,再调用save直接保存。
- scipy.misc.toimage(image_array, cmin=0.0, cmax=1.0).save(filename)
-
- print('Please check: %s ' % save_dir)

(3)、查看mnist_train数据集
打印出前20张图片的One-hot编码+前20张图片所对应的标签
- mnist_train数据集:打印出前20张图片的One-hot编码+前20张图片所对应的标签
- from tensorflow.examples.tutorials.mnist import input_data
- import numpy as np
- 读取mnist数据集。如果不存在会事先下载。
- mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
-
- 看前20张训练图片的label
- for i in range(20):
- 得到one-hot表示,形如(0, 1, 0, 0, 0, 0, 0, 0, 0, 0)
- one_hot_label = mnist.train.labels[i, :]
- 通过np.argmax我们可以直接获得原始的label
- 因为只有1位为1,其他都是0
- label = np.argmax(one_hot_label)
- print('mnist_train中,第 %d 张图片One-hot编码'% i,mnist.train.labels[i,:])
- print('mnist_train中,第 %d 张图片对应的 label: %d' % (i, label))

MNIST数据集的使用方法
1、数据集增强代码演示
Dataset之MNIST:MNIST(手写数字图片识别)数据集简介、下载、使用方法(包括数据集增强)之详细攻略
1.1、思路

1.2、代码实现
数据集增强(将已有MNIST数据集通过移动像素上下左右的方法来扩大数据集为初始数据集的5倍)
- from __future__ import print_function
-
- import cPickle
- import gzip
- import os.path
- import random
-
- import numpy as np
-
- print("Expanding the MNIST training set")
-
- if os.path.exists("../data/mnist_expanded.pkl.gz"):
- print("The expanded training set already exists. Exiting.")
- else:
- f = gzip.open("../data/mnist.pkl.gz", 'rb')
- training_data, validation_data, test_data = cPickle.load(f)
- f.close()
- expanded_training_pairs = []
- j = 0
- for x, y in zip(training_data[0], training_data[1]):
- expanded_training_pairs.append((x, y))
- image = np.reshape(x, (-1, 28))
- j += 1
- if j % 1000 == 0: print("Expanding image number", j)
-
- for d, axis, index_position, index in [
- (1, 0, "first", 0),
- (-1, 0, "first", 27),
- (1, 1, "last", 0),
- (-1, 1, "last", 27)]:
- new_img = np.roll(image, d, axis)
- if index_position == "first":
- new_img[index, :] = np.zeros(28)
- else:
- new_img[:, index] = np.zeros(28)
- expanded_training_pairs.append((np.reshape(new_img, 784), y))
- random.shuffle(expanded_training_pairs)
- expanded_training_data = [list(d) for d in zip(*expanded_training_pairs)]
- print("Saving expanded data. This may take a few minutes.")
- f = gzip.open("../data/mnist_expanded.pkl.gz", "w")
- cPickle.dump((expanded_training_data, validation_data, test_data), f)
- f.close()

网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2691
- 【软件正版化】软件正版化工作要点 2655
- 统信UOS试玩黑神话:悟空 2559
- 信刻光盘安全隔离与信息交换系统 2247
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1117
- grub引导程序无法找到指定设备和分区 769
- 江波龙2025届校园招聘宣讲会行程大放送 28
- 点击报名 | 京东2025校招进校行程预告 25
- 海康威视2025校招|海康机器人,邀你共创工业智能化未来! 24
- 金山办公2024算法挑战赛 | 报名截止日期更新 22
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
