Py之Beautiful Soup 4.2.0:Beautiful Soup 4.2.0的简介、安装、使用方法详细攻略

Py之Beautiful Soup 4.2.0:Beautiful Soup 4.2.0的简介、安装、使用方法详细攻略
目录
Beautiful Soup 4.2.0的简介
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。
Beautiful Soup 4.2.0的安装
如果你用的是新版的Debain或ubuntu,那么可以通过系统的软件包管理来安装:
$ apt-get install Python-bs4
Beautiful Soup 4 通过PyPi发布,所以如果你无法使用系统包管理安装,那么也可以通过 easy_install 或 pip 来安装.包的名字是 beautifulsoup4 ,这个包兼容Python2和Python3.
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
Beautiful Soup 4.2.0的使用方法
1、将一段文档传入BeautifulSoup 的构造方法,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄.
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"))
soup = BeautifulSoup("<html>data</html>")
首先,文档被转换成Unicode,并且HTML的实例都被转换成Unicode编码
BeautifulSoup("Sacré bleu!")
<html><head></head><body>Sacré bleu!</body></html>
然后,Beautiful Soup选择最合适的解析器来解析这段文档,如果手动指定解析器那么Beautiful Soup会选择指定的解析器来解析文档.(参考 解析成XML ).
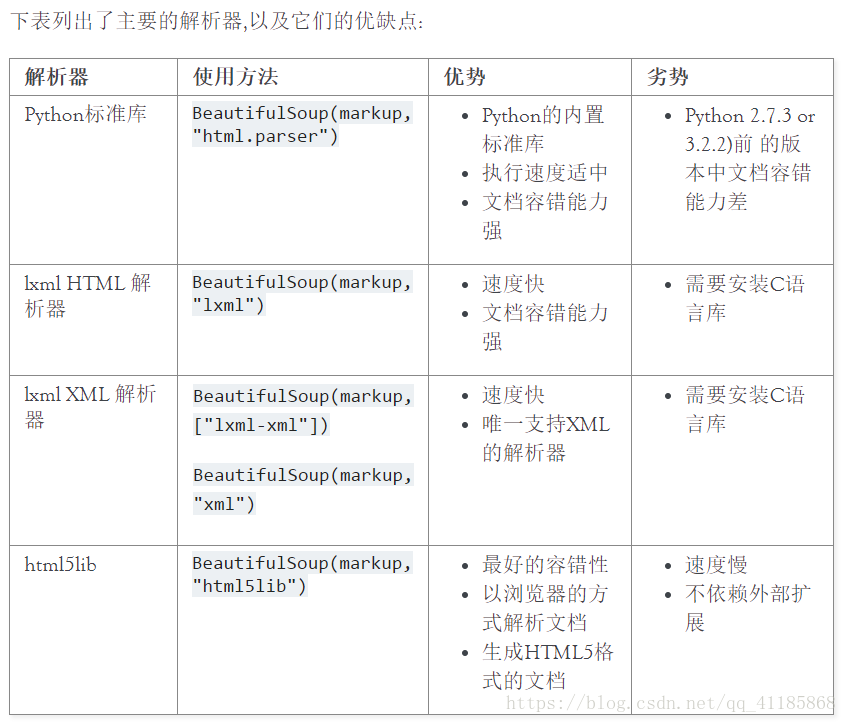
2、BeautifulSoup包 功能比正则表达式很多,且要简洁明白一些。
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可 以归纳为4种: Tag、NavigableString、BeautifulSoup、Comment 。
Tag: 即我们在写网页时所使用的标签(如<a>超链接标签)
NavigableString:简单的说就是一种可以遍历的字符串
Beautiful Soup库对比lxml库
这两个库主要是解析html/xml文档,BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、 Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Sou和Lxml是两个非常流行的python模块,他们常被用来对抓取到的网页进行解析,以便进一步抓取的进行。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1323
- 银河麒麟打印带有图像的文档时出错 1236
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1023
- 统信桌面专业版【如何查询系统安装时间】 951
- 统信操作系统各版本介绍 944
- 统信桌面专业版【全盘安装UOS系统】介绍 903
- 麒麟系统也能完整体验微信啦! 889
- 统信【启动盘制作工具】使用介绍 499
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 440
- 信刻全自动档案蓝光光盘检测一体机 386
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
