ML之RS:基于用户的CF+LFM实现的推荐系统(基于相关度较高的用户实现电影推荐)

ML之RS:基于用户的CF+LFM实现的推荐系统(基于相关度较高的用户实现电影推荐)
目录
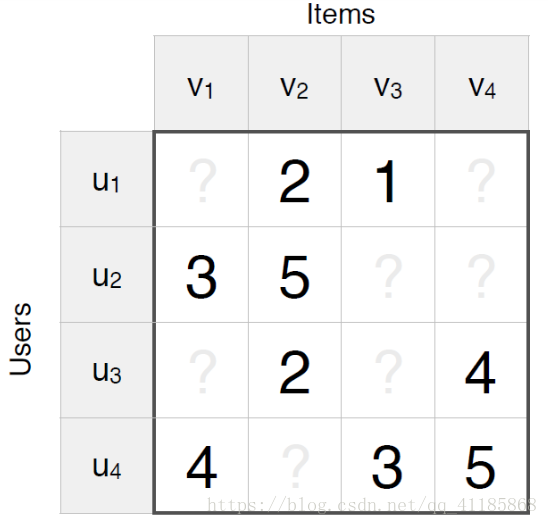
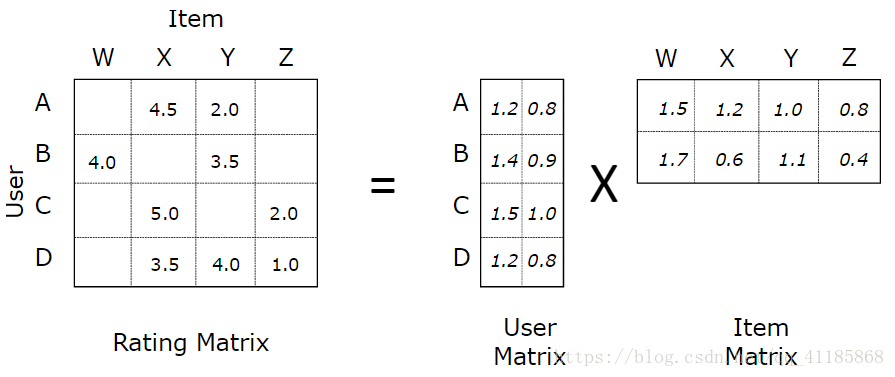
输出结果

实现代码
- ML之RS:基于CF和LFM实现的推荐系统
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import time
- import warnings
- warnings.filterwarnings('ignore')
- np.random.seed(1)
-
- plt.style.use('ggplot')
- data = pd.read_csv('ml-20m/ratings_smaller.csv', index_col=0)
- movies = pd.read_csv('ml-20m/movies_smaller.csv')
-
- 1、导入数据集
- data = pd.read_csv('ml-latest-small/ratings.csv')
- movies = pd.read_csv('ml-latest-small/movies.csv')
- movies = movies.set_index('movieId')[['title', 'genres']]
-
- 2、观察数据集
- How many users?
- print (data.userId.nunique(), 'users')
-
- How many movies?
- print (data.movieId.nunique(), 'movies')
-
- How possible ratings?
- print (data.userId.nunique() * data.movieId.nunique(), 'possible ratings')
-
- How many do we have?
- print (len(data), 'ratings')
- print (100 * (float(len(data)) / (data.userId.nunique() * data.movieId.nunique())), '% of possible ratings')
-
-
-
- Number of ratings per users
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.groupby('userId').apply(lambda x: len(x)).values, bins=50)
- plt.xlabel("ratings")
- plt.ylabel("users")
- plt.title("Number of ratings per user")
- plt.show()
-
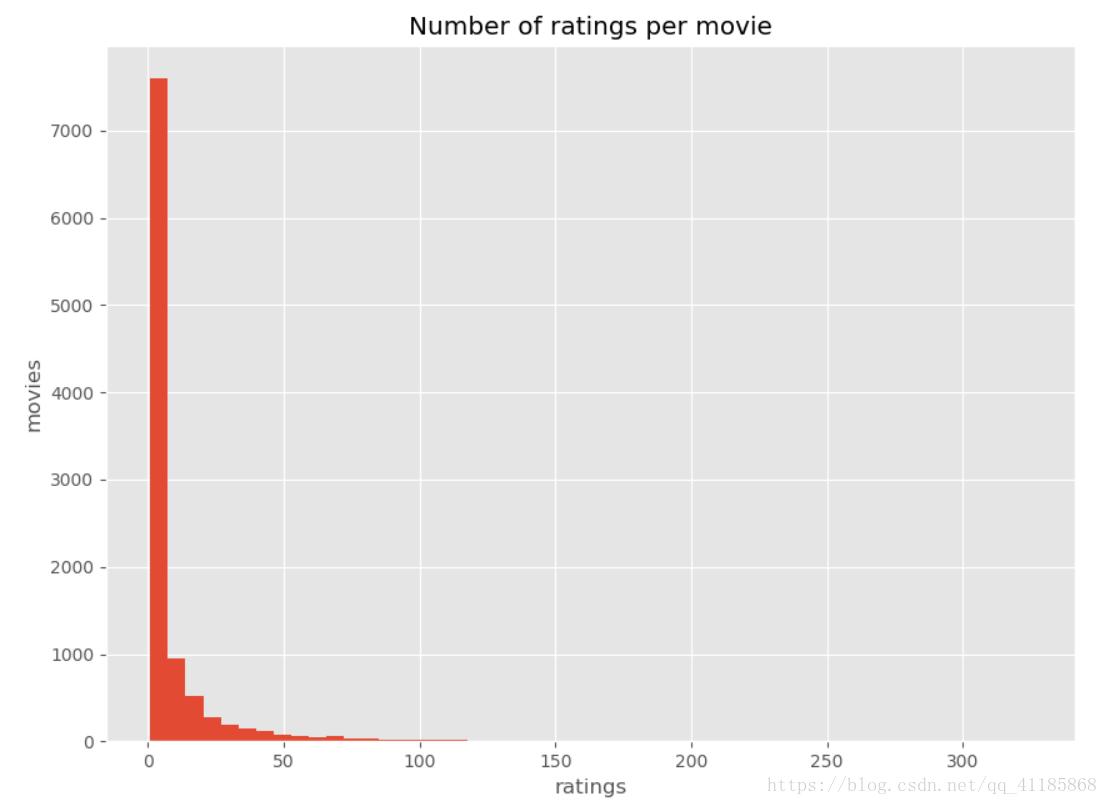
- Number of ratings per movie
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.groupby('movieId').apply(lambda x: len(x)).values, bins=50)
- plt.xlabel("ratings")
- plt.ylabel("movies")
- plt.title('Number of ratings per movie')
- plt.show()
-
- Ratings distribution评分分布
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.rating.values, bins=5)
- plt.xlabel("ratings")
- plt.ylabel("numbers")
- plt.title("Distribution of ratings")
- plt.show()
-
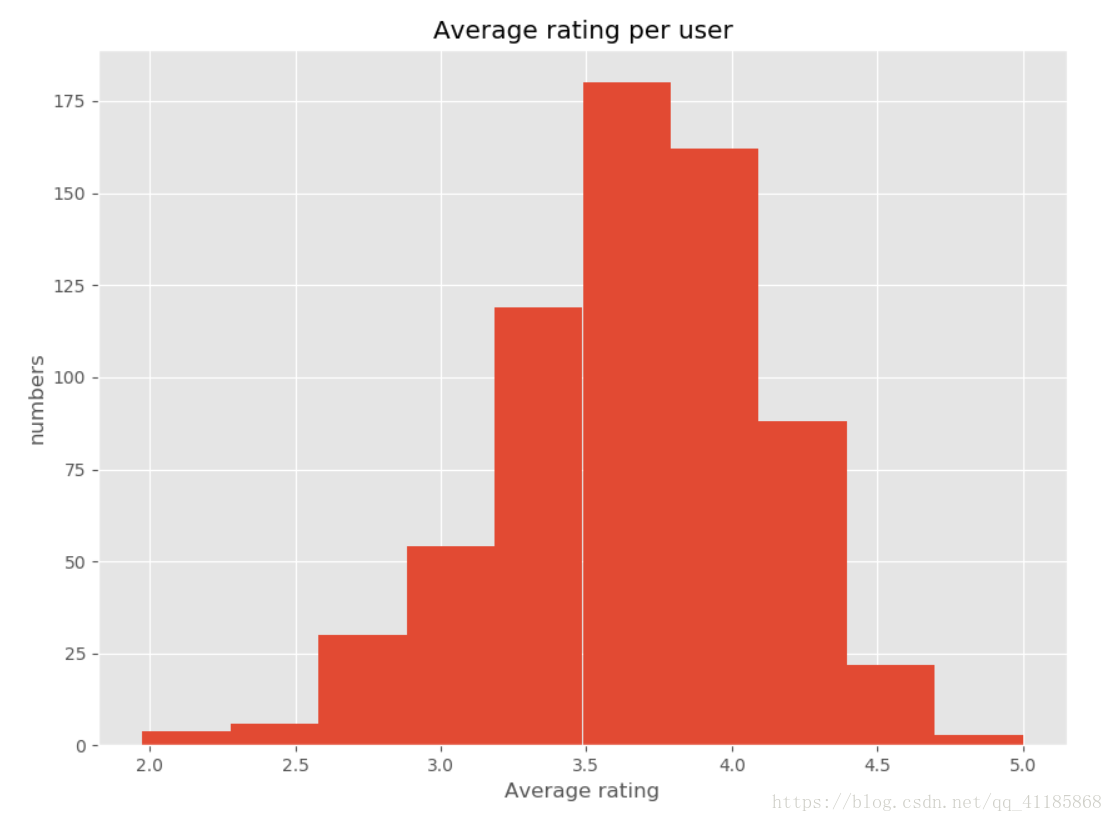
- Average rating per user
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.groupby('userId').rating.mean().values, bins=10)
- plt.xlabel("Average rating")
- plt.ylabel("numbers")
- plt.title("Average rating per user")
- plt.show()
-
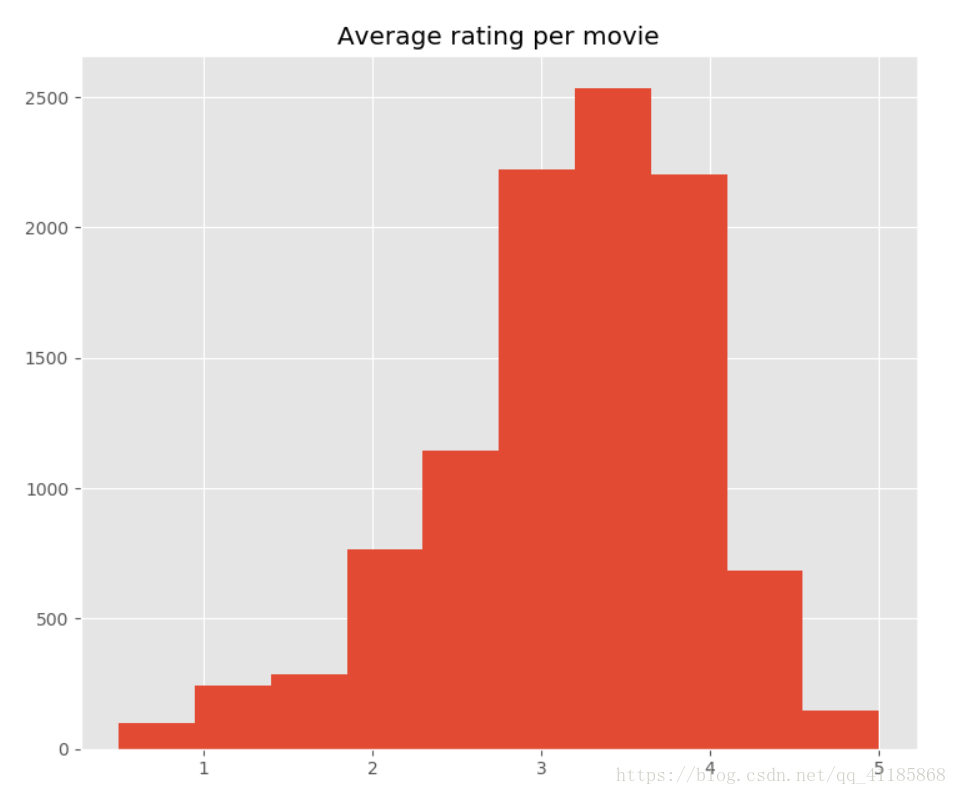
- Average rating per movie
- fig = plt.figure(figsize=(10, 10))
- ax = plt.hist(data.groupby('movieId').rating.mean().values, bins=10)
- plt.title('Average rating per movie')
- plt.show()
-
- Top Movies,genres电影类型
- average_movie_rating = data.groupby('movieId').mean()
- top_movies = average_movie_rating.sort_values('rating', ascending=False).head(10)
- pd.concat([movies.loc[top_movies.index.values],
- average_movie_rating.loc[top_movies.index.values].rating], axis=1)
-
- Robust Top Movies - Lets weight the average rating by the square root of number of ratings让平均评分进行加权数的平方根
- top_movies = data.groupby('movieId').apply(lambda x:len(x)**0.5 * x.mean()).sort_values('rating', ascending=False).head(10)
- pd.concat([movies.loc[top_movies.index.values],
- average_movie_rating.loc[top_movies.index.values].rating], axis=1)
-
- controversial_movies = data.groupby('movieId').apply(lambda x:len(x)**0.25 * x.std()).sort_values('rating', ascending=False).head(10)
- pd.concat([movies.loc[controversial_movies.index.values],
- average_movie_rating.loc[controversial_movies.index.values].rating], axis=1)
相关文章推荐
GitHub
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- Kingbase用户权限管理 1999
- 信刻全自动光盘摆渡系统 1727
- 信刻国产化智能光盘柜管理系统 1399
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 987
- 银河麒麟打印带有图像的文档时出错 888
- 银河麒麟添加打印机时,出现“server-error-internal-error” 682
- 麒麟系统也能完整体验微信啦! 637
- 统信桌面专业版【如何查询系统安装时间】 600
- 统信操作系统各版本介绍 595
- 统信桌面专业版【全盘安装UOS系统】介绍 570
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
