基于统计与评分

过去的两周里,我一直忙于为 『玩点什么』 设计一个推荐系统(即,recommend system)。在这个过程中,参考了之前的 几本书籍,查找了一系列的资料。想着这些资料上,大部分都是大同小民的,实现了几个简单的推荐功能,改进了标签推荐算法,便想着写篇文章记录一下。
『玩点什么』,是一个基于 Django、Python 的 CMS 系统(Mezzanine)。是的,和我的博客使用的是同一个 CMS 系统。由于使用的是 Python 语言,因此对于机器学习具有天生的优势。
推荐系统
推荐系统是一种信息过滤系统,用于预测用户对物品的“评分”或“偏好”。
对于推荐系统系统来说,目前采用的主要方式是:
- 基于内容推荐:内容之间的相似度,如文章的标签、电影的属性、书籍的分类。
- 协同过滤(待实现):用户之间的相似度,如喜欢看科幻片的 A、B 用户、并且都看过 a 电影,A 喜欢看的 c 电影,B 也可能喜欢 c 电影。
要实现这两种方式有一个前提是,用户数据。特别是协同过滤,需要有大量的用户行为数据。对于一些大的社交应用、有大量的用户,如微信来说,还会有:
- 基于社区推荐,如,你的好友喜欢什么,就会为你推荐王者荣耀。
- 基于人口统计学,即我们网上看到的各种区域性人的偏好,各种地域黑~。
上面主要是依赖于大量的用户数量,当我们没有大量的用户数据时。我们可以先采用其它的方式:
- 基于统计学推荐,诸如文章的阅读量、分享量,又或者文章的评分数。
- 基于标签推荐,对于专业领域的文章来说,作者提交的标签往往比机器生成更加可靠。
除此,按我的理解,对于专业领域来说,还会有一种方式是:
- 基于知识图谱推荐,如我之前做的技能树和 Growth,便是其中的一种方式。
这种成知识体系的文章,往往对于用户来说,更具备价值。
收集用户数据(一):统计
那么,现在先让我们从收集用户数据谈起。
因为不论是哪一种推荐方式,其都依赖于应用服务提供者所拥有的数据、数据、数据。没有数据,你所谈的算法都是在耍流氓,你所学的机器学习、深度学习算法也是在而流氓,只谈算法不谈收集数据都是在耍流氓。他们的学习成本都很低,几星期几个月,差不多能学好七八十。可是要是没有 ImageNet 的图片数据、CNN 的上亿条新闻数据,这一些算法都没有价值。
而如我在《全栈应用开发:精益实践》所写,数据分析应该在我们上线了第一个 DEMO 之后,或第一个正式版就必须上线的功能,以实现产品的精益化。
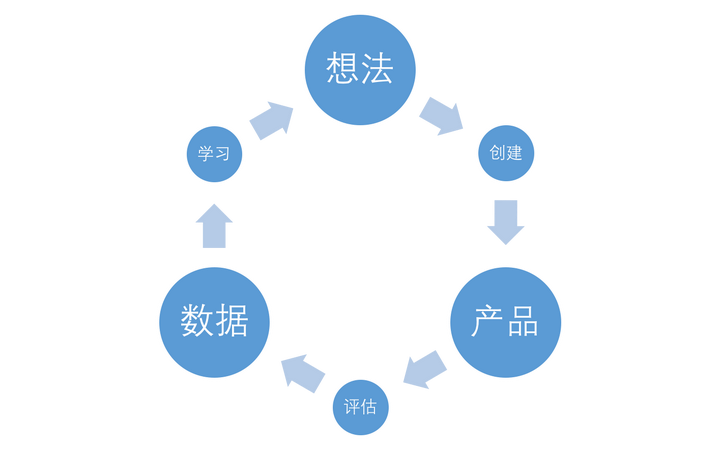
它只是数据分析的第一步,引入一些数据分析的工具——只需要引入 Google Analytics、又或者 Piwik 这样的工具,就可以轻松地帮我们做数据统计。这些功夫,基本上只需要半天就做完了。这时,当我们谈及收集用户数据的时候:
- 对于技术人员来说,无非就是用户的地域、浏览器、操作系统等等,这些相关的信息会影响到用户的体验、技术决策等等。
- 对于业务人员来说,他们可以了解某个产品的浏览量、受欢迎程度、爱欢迎的区域等等。
只是这些数据,并不能帮我们做出一个优秀的推荐系统。这时,我们是基于统计学,只能统计出哪些产品受用户欢迎:
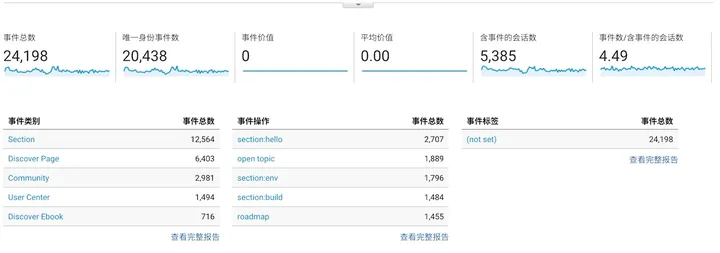
但是,这已经可以实现我们的第一个推荐系统。
(PS:另外一部分用户数据收集,敬请期待下一篇)
基于统计学:访问量及评论数推荐
我过去一直觉得,依据统计博客、文章的访问量来推荐是不可靠的。
- 一篇文章可能因为观点受争议,如 『PHP 不再是最好的语言』,而着有极高的访问量。可这个时候,用户往往是通过标题和摘要来理解作者的观点,往往就会轻易地下定论。又有一些用户,比如我则喜欢看热闹,去下面回复一个『JavaScript 是最流行的语言』。
- 一篇文章可能因为大 V 的流量效应,而导致 他/她/也 的每一篇文章都有极高的访问量
- 。。。
并且使用流量统计也容易被攻击,只需要一些诸如『流量精灵』这样的软件,就可以提高文章的访问——虚假的繁荣。
一般来说,大部分的社区都会将流量大的内容、话题等,放在首页显眼的位置。从这个推荐的位置,我们就可以知道这个社区的『水平』。衡量一个社区的『水平』,无非就是最受欢迎文章的类型,如简书的鸡汤,知乎的故事。但是,这些并不代表着这些社区的真实水平,却反应了这些社区的主要受众。
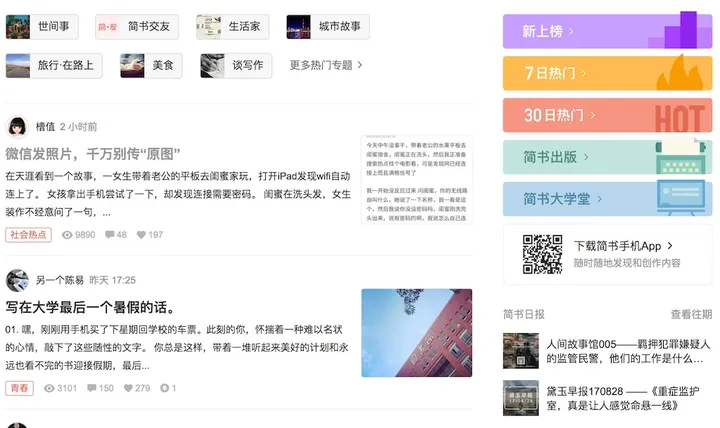
好在简书是编辑推荐制,但章的质量还是『有一定』保证的,但是文章的性质改不了鸡汤。
考虑到我过去曾经刷过访问量,以及流量统计对于数据库性能的影响,我决定改进一下统计代码,即将统计代码放在 JavaScript 中,通过 Ajax 请求实现。而我在这个过程中,犯了一个严重的错误就是,忘了在前端屏蔽中的爬虫。我虽然在 Nginx 里,直接过滤了一部分的爬虫,但是诸如 Google、百度、Bing 都是允许的,而 Google bot 则会在页面上执行 JavaScript,因此每篇博客都被刷了好多阅读量。
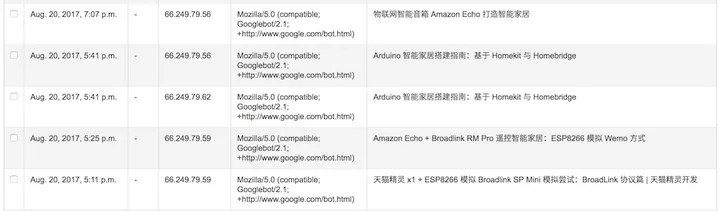
于是,只好在前端做一些相关的处理。
var botPattern = "(googlebot\/|Googlebot-Mobile|Googlebot-Image|Google favicon|Mediapartners-Google|bingbot...";
var botRe = new RegExp(botPattern, 'i');
var userAgent = navigator.userAgent;
if (!botRe.test(userAgent)) {
}而除了,上面说到的鸡汤问题。它也有一些额外的好处,如:
- 长尾效应。这种高流量的文章、商品,往往能带来长尾效应,就像亚马逊上的畅销书,畅销书本身是不赚钱的。但是网站可以通过相关的文章、产品,来获得更多的阅读及利润。而这取决于,我们为用户推荐的相关产品,是不是真正是用户需要的。
考虑到上面的鸡汤流量问题,它可以吸引大量的人气,但是会导致劣币驱除良币的产生——大量产生优秀内容的作者,写不出受大众欢迎的文章。举个例子,技术写作来说,面向新手的文章,往往会有比较高的阅读量;而面向中高端用户的文章,则阅读量低。可要是首页都是新手文章,流量和受众就会越来越多,但是高端用户就会离开这个社区。
因此,我们还可以采用用户评分,来增加一个新的榜单,如 Medium 和 『玩点什么』的第二种推荐方式。
它可以在保证流量的同时,也不降低网站的质量。
基于统计学:评分及 IMDB 加权算法推荐
软件开发,本身是以演进的形式进行的。不论,我们是开发基于内容的推荐系统,还是协同过滤的系统,它都依赖于我们拥有一个评分系统。与此同时,如果我们没有足够的用户,我们也进行不了内容推荐和协同过滤,因此设计一个稍微完善一点的评价排名,便显得很有必要。
下图是『玩点什么』的评分,用户不需要登录就可以评分:
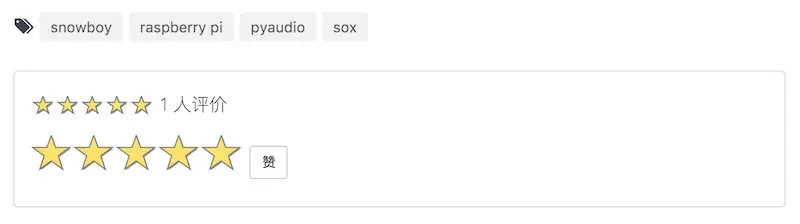
尽管没有登录是一个风险问题,然而对于一个内容网站来说,刷评价的意义并不大。
在真实应用的过程中,遇到了一个问题:
- A 文章只有 5 个评分,且都是 5 分;
- B 文章则有 100 个评分,平均值则是 4.8 分;
如下表示:
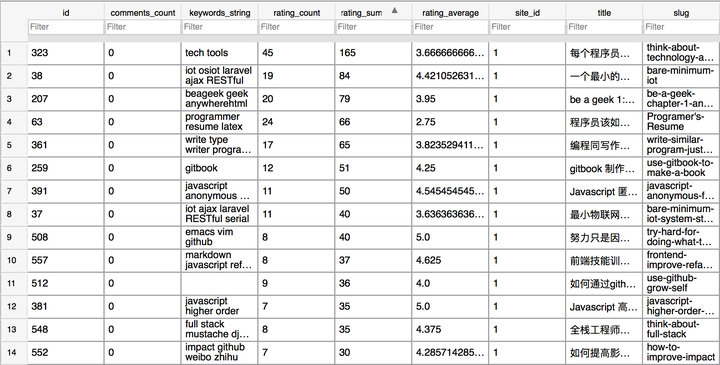
这个时候,我们很难判定 A 就比 B 好,于是在知乎上看到了一个相关的评分算法,即(更多信息可以阅读:IMDB 给出的电影评分的计算方法是怎样的?),又可以称为 IMDB TOP 250 评分算法。
它是由贝叶斯统计的算法得出的加权分(Weighted Rank-WR),其公式如下:
(WR) = (v ÷ (v+m)) × R + (m ÷ (v+m)) × C
- WR, 加权得分(weighted rating)。
- R, 该电影的用户投票的平均得分(Rating)。
- v, 该电影的投票人数(votes)。
- m, 排名前 250 名的电影的最低投票数(现在为 3000)。
- C, 所有电影的平均得分(现在为6.9)。
于是,我的算法代码就变成了这样:
def imdb_rank(average_rating, votes_number):
minimum_votes = settings.MINIMUM_VOTES
correctly_votes_rate = settings.CORRECTLY_VOTES_RATE
return (votes_number / (votes_number + minimum_votes)) * average_rating + (minimum_votes / (
votes_number + minimum_votes)) * correctly_votes_rate
然而,在计算排序的时候,我不是拿所有的文章排序,而是:
- 从所有文章中过滤出能达到最小评分数的文章
- 按评分值,对这些文章进行排序,取前 10
- 对前 10 中的这些文章,进行 imdb_rank 计算,取前 3
这样做的主要原因是,出于服务器性能考虑。
待改进
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1319
- 银河麒麟打印带有图像的文档时出错 1232
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1018
- 统信桌面专业版【如何查询系统安装时间】 948
- 统信操作系统各版本介绍 941
- 统信桌面专业版【全盘安装UOS系统】介绍 899
- 麒麟系统也能完整体验微信啦! 886
- 统信【启动盘制作工具】使用介绍 496
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 437
- 信刻全自动档案蓝光光盘检测一体机 383
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
