ML之LiR:使用线性回归LiR回归模型在披萨数据集上拟合(train)、价格回归预测(test)

ML之LiR:使用线性回归LiR回归模型在披萨数据集上拟合(train)、价格回归预测(test)
目录
输出结果
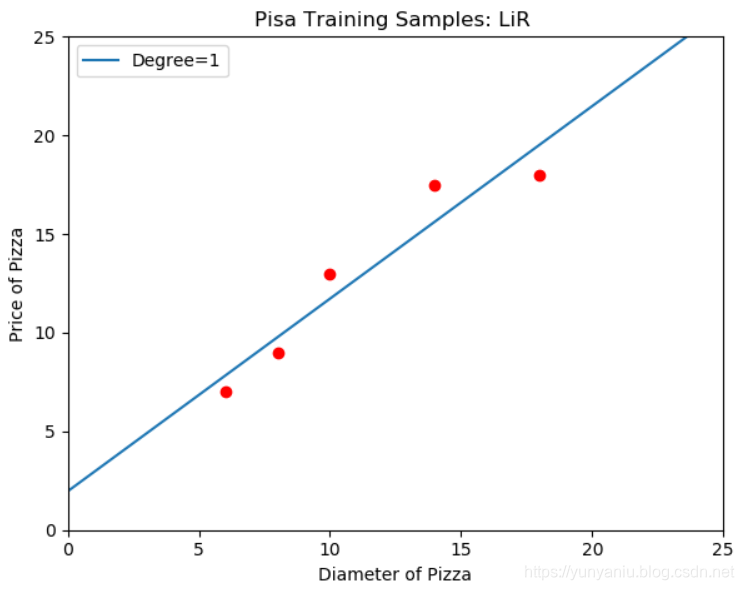
![]()
![]()
设计思路
核心代码
- r= LinearRegression()
- r.fit(X_train, y_train)
-
- x = np.linspace(0, 26, 100)
- x = x.reshape(xx.shape[0], 1)
- y = r.predict(x)
- class LinearRegression(LinearModel, RegressorMixin):
- """
- Ordinary least squares Linear Regression.
-
- Parameters
- ----------
- fit_intercept : boolean, optional, default True
- whether to calculate the intercept for this model. If set
- to False, no intercept will be used in calculations
- (e.g. data is expected to be already centered).
-
- normalize : boolean, optional, default False
- This parameter is ignored when ``fit_intercept`` is set to
- False.
- If True, the regressors X will be normalized before
- regression by
- subtracting the mean and dividing by the l2-norm.
- If you wish to standardize, please use
- :class:`sklearn.preprocessing.StandardScaler` before
- calling ``fit`` on
- an estimator with ``normalize=False``.
-
- copy_X : boolean, optional, default True
- If True, X will be copied; else, it may be overwritten.
-
- n_jobs : int, optional, default 1
- The number of jobs to use for the computation.
- If -1 all CPUs are used. This will only provide speedup for
- n_targets > 1 and sufficient large problems.
-
- Attributes
- ----------
- coef_ : array, shape (n_features, ) or (n_targets, n_features)
- Estimated coefficients for the linear regression problem.
- If multiple targets are passed during the fit (y 2D), this
- is a 2D array of shape (n_targets, n_features), while if only
- one target is passed, this is a 1D array of length
- n_features.
-
- intercept_ : array
- Independent term in the linear model.
-
- Notes
- -----
- From the implementation point of view, this is just plain
- Ordinary
- Least Squares (scipy.linalg.lstsq) wrapped as a predictor
- object.
-
- """
- def __init__(self, fit_intercept=True, normalize=False,
- copy_X=True,
- n_jobs=1):
- self.fit_intercept = fit_intercept
- self.normalize = normalize
- self.copy_X = copy_X
- self.n_jobs = n_jobs
-
- def fit(self, X, y, sample_weight=None):
- """
- Fit linear model.
- Parameters
- ----------
- X : numpy array or sparse matrix of shape [n_samples,
- n_features]
- Training data
- y : numpy array of shape [n_samples, n_targets]
- Target values. Will be cast to X's dtype if necessary
- sample_weight : numpy array of shape [n_samples]
- Individual weights for each sample
- .. versionadded:: 0.17
- parameter *sample_weight* support to
- LinearRegression.
- Returns
- -------
- self : returns an instance of self.
- """
- n_jobs_ = self.n_jobs
- X, y = check_X_y(X, y, accept_sparse=['csr', 'csc', 'coo'],
- y_numeric=True, multi_output=True)
- if sample_weight is not None and np.atleast_1d
- (sample_weight).ndim > 1:
- raise ValueError("Sample weights must be 1D array
- or scalar")
- X, y, X_offset, y_offset, X_scale = self._preprocess_data(
- X, y, fit_intercept=self.fit_intercept, normalize=self.
- normalize,
- copy=self.copy_X, sample_weight=sample_weight)
- if sample_weight is not None:
- Sample weight can be implemented via a simple
- rescaling.
- X, y = _rescale_data(X, y, sample_weight)
- if sp.issparse(X):
- if y.ndim < 2:
- out = sparse_lsqr(X, y)
- self.coef_ = out[0]
- self._residues = out[3]
- else:
- sparse_lstsq cannot handle y with shape (M, K)
- outs = Parallel(n_jobs=n_jobs_)(
- delayed(sparse_lsqr)(X, :j]ravel()) for y[.
- j in range(y.shape[1]))
- self.coef_ = np.vstack(out[0] for out in outs)
- self._residues = np.vstack(out[3] for out in outs)
- else:
- self.coef_, self._residues, self.rank_, self.singular_ =
- linalg.lstsq(X, y)
- self.coef_ = self.coef_.T
- if y.ndim == 1:
- self.coef_ = np.ravel(self.coef_)
- self._set_intercept(X_offset, y_offset, X_scale)
- return self
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2951
- 【软件正版化】软件正版化工作要点 2872
- 统信UOS试玩黑神话:悟空 2833
- 信刻光盘安全隔离与信息交换系统 2728
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1261
- grub引导程序无法找到指定设备和分区 1226
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 165
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 163
- 点击报名 | 京东2025校招进校行程预告 163
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 159
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 如何玩转信创开放社区—从小白进阶到专家 15
- 信创开放社区邀请他人注册的具体步骤如下 15
- 方德桌面操作系统 14
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 我有15积分有什么用? 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
