JVM(三):垃圾回收机制(二):分代收集

先说方法区(Hotspot虚拟机中的永久代)的回收条件:
假如有一个类叫 Person
1、加载这个类的ClassLoader要被回收
2、该类的实例对象要被回收
3、其他地方不能持有类对象的引用 Person.class但是方法区的回收条件以及苛刻,一般来说回收效率极低。
而且方法区的回收分为两部分:上面算一部分,还有一部分是常量池的回收
常量池回收废弃常量的时候和回收类是一样的:假如一个字符串没有被引用,遇见GC的话那就被回收了。
永久代 是 jdk1.7 对方法区的 实现,到了1.8是元数据区。
永久代是实现 实现 实现 对方法区的实现,永久代不是方法区!!!
分代收集:
根据对象的存活周期的不同,将Java堆内存划分为几个区域(新生代,老年代),这样可以根据各个年代的特点采用最适当的收集算法。
新生代:新的对象会分配到新生代,在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活(也是新生代的特点:朝生幕死),那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
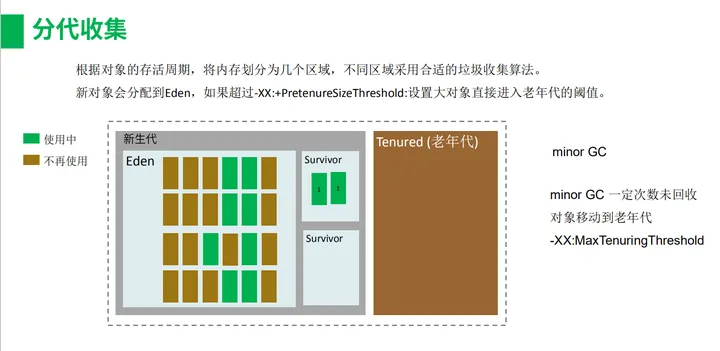
老年代比新生代要大很多。如果新生代的对象回收了很多次还是没有被回收,那么该对象可能会进入到老年代。
新生代采用复制算法,复制算法的特点上篇文章也说到了:不适用于回收率比较低(存活率较高)的对象,因为回收的时候,一旦对象的回收率较低,那么将要复制大量的对象到另一边。消耗性能。因为回收率较低。可回收的很少。而新生代的对象基本都是朝生幕死的,存活率很低,所以复制算法适用于新生代
新new的对象放入Eden区,当Eden区满了需要回收的时候把不能回收的对象复制到Survivor1里,然后把Eden区清空。然后过一段时间创建的对象又在Eden区了,Eden区满了又进行垃圾回收,这时候把Eden区不能回收的对象和之前的Survivor1里的对象一块复制到Survivor2里,之后将之前的Survivor1和Eden区清空。然后Eden区中的对象占用内存再次满了的话,就把Eden区不能回收的对象和Survivor2的对象复制到Survivor1里,就这样只留一个空的Survivor区来不停的倒数据。
新生代的对象什么时候进入老年代?
第一种情况:理想情况下:Java对象是有对象头的,对象头的Mark word里有age,当进入Eden区的时,age=0,然后每进入一次Survivor区的时候 ,age都自增1,当 age = 15 的时候,该对象就进入老年代。
第二种情况叫做老年代担保:意思是当Eden区的不可回收的对象占用的容量大于一个Survivor区的容量的的时候,那么一部分对象会进入Survivor区,而剩下的对象会进入老年代
第三种情况:大对象会进入老年代,大的String,或者大的数组等等。当进入Eden区的时候,可能Eden区可用的内存不多了,进来的话,直接会造成Eden区的垃圾回收,每次都有大对象进入Eden区的话会造成新生代频繁的垃圾回收(也叫做minor GC),这样不好,所以大对象就进入到老年代。
第四种情况:在Survivor区的对象,举个例子:当对象头中 age = 6 的所有的对象的容量大于Survivor区的容量的一半的时候,这是就会将所有age >=6 的对象将会进入老年代。
Minor GC:发生在新生代,比如执行很多的方法,这些方法里会创建对象,
当方法结束后,虚拟机栈的栈帧里的局部变量表就会清空,那么那些方法里的局部变量就会被清空,
所以堆内存中对象就没有引用了,这时候就会采用复制算法,回收那些没有引用的对象。
Minor GC是频繁发生的
Full GC:发生在老年代,可能会伴有 Minor GC,耗时比较长 是Minor GC的10倍以上,
通常伴有卡顿等情况,Minor GC 和 Full GC 都会有stop the world。
Minor GC 时间非常短,发生stop the world 的时候基本上不会出现程序的响应。
而Full GC时间很长,发生stop the world的话,就会出现程序的卡顿。什么时候发生 Full GC ?
1、System.gc(): 一个使用场景是我在做机器学习的时候,比如 train.csv 要分割,python里有直接拿到索引的enumerate函数,拿到索引后用pandas根据索引可以划分为训练集和验证集,划分完成后,就直接带入lgb或者xgb进行训练,那么训练之前就可以 gc.collect( )了,回收一下原来的老的数据,占用的内存,因为csv文件太大了,直接导入内存就爆了,如果再不回收,那么就没法训练了,而且老的数据集也不需要了,或者在spark,flink 也经常gc
2、老年代担保失败:当老年代的内存不多的时候,如果担保的新生代的内存比自己本身剩余的内存还要大的时候,那么就不能强行担保,硬塞进来,而是对老年代先进行一个Full GC,然后才能担保新生代的对象。
3、Concurrent Failure : CMS收集器 可能会出现的错误。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 如何使用 StarRocks 管理和优化数据湖中的数据? 2959
- 【软件正版化】软件正版化工作要点 2878
- 统信UOS试玩黑神话:悟空 2843
- 信刻光盘安全隔离与信息交换系统 2737
- 镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态 1270
- grub引导程序无法找到指定设备和分区 1235
- 华为全联接大会2024丨软通动力分论坛精彩议程抢先看! 165
- 点击报名 | 京东2025校招进校行程预告 164
- 2024海洋能源产业融合发展论坛暨博览会同期活动-海洋能源与数字化智能化论坛成功举办 163
- 华为纯血鸿蒙正式版9月底见!但Mate 70的内情还得接着挖... 159
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
