MySQL性能调优(二)


当使用索引列查询的时候,尽量不要使用表达式,应该把计算放到业务层而不是数据库层。
例如下面这两个sql语句,显然应该避免的是第二种 where字句后面 写计算的
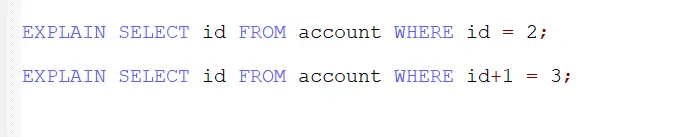
通过执行计划可以看出这个sql的type是const
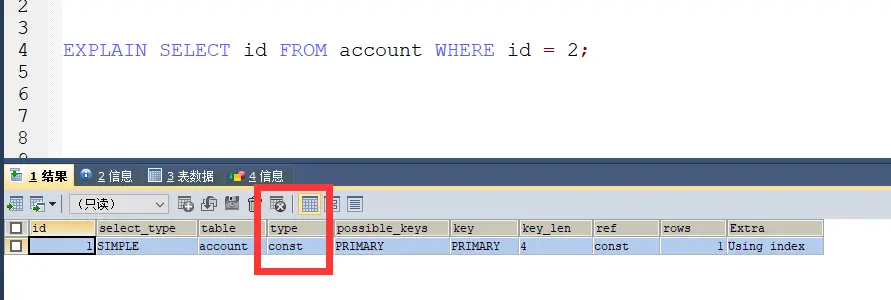
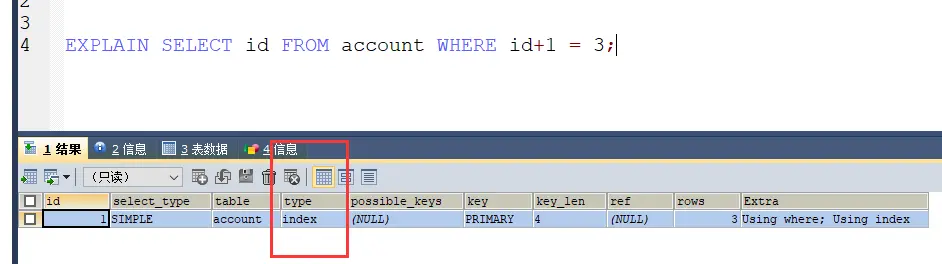
而这个写表达式的是 index,const比index执行效率高
尽量使用主键查询,而不是其他索引,因为主键查询不会触发回表。
使用索引扫描来做排序:
mysql有两种方式可以生成有序的结果:通过排序操作或者按索引顺序扫描,如果explain出来的type列的值为index,则说明mysql使用了索引扫描来做排序
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录。但如果索引不能覆盖查询所需的全部列,那么就不得不每扫描一条索引记录就得回表查询一次对应的行,这基本都是随机IO,因此按索引顺序读取数据的速度通常要比顺序地全表扫描慢
mysql可以使用同一个索引即满足排序,又用于查找行,如果可能的话,设计索引时应该尽可能地同时满足这两种任务。
只有当索引的列顺序和order by子句的顺序完全一致,并且所有列的排序方式都一样时(都是desc或都是asc),mysql才能够使用索引来对结果进行排序,如果查询需要关联多张表,则只有当orderby子句引用的字段全部为第一张表时,才能使用索引做排序。order by子句和查找型查询的限制是一样的,需要满足索引的最左前缀的要求,否则,mysql都需要执行顺序操作,而无法利用索引排序。
union all , in , or 都能使用索引的情况下,推荐使用 in
更新十分频繁,数据区分度不高的字段不宜建立索引:
更新会变更B+树,更新频繁的字段建立索引会大大降低数据库性能,更新的话会造成页分裂和页合并。
类似于性别这类区分度不大的属性,建立索引是没有意义的,不能有效过滤数据,想一下,性别就男和女,本身就能区分数据了,建立索引没什么意义,索引在id这种字段上建立的话,sql上where id = ? 这种的话,是直接可以检索的,而在性别上,就一个分支,男和女,没有太多的树。一般区分度在80%以上的时候就可以建立索引,区分度可以使用count(distinct(列名))/count(*)来计算。
创建索引的列,不允许为null。如果为null则会出现不符合预期的结果。
如果明确知道只有一条结果返回,limit 1 能够提高效率。因为用了limit 1之后 索引指针不会往下进行判断,如果下面还有数据,如果没有用limit 1 的话,还是会继续往下判断的。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1489
- 银河麒麟打印带有图像的文档时出错 1407
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1196
- 统信操作系统各版本介绍 1118
- 统信桌面专业版【如何查询系统安装时间】 1116
- 统信桌面专业版【全盘安装UOS系统】介绍 1071
- 麒麟系统也能完整体验微信啦! 1029
- 统信【启动盘制作工具】使用介绍 674
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 618
- 信刻全自动档案蓝光光盘检测一体机 529
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
