MySQL:缓冲池CheckPoint技术

在innodb体系结构中说到了缓冲池里使用了checkpoint技术。
缓冲池的设计就是为了协调cpu的速度和磁盘的速度,所以页的操作首先都是在缓冲池中完成的,例如读取数据,先是从磁盘读取到缓冲池里。那么当修改和删除语句改变了缓冲池里的页中的记录的时候,这个页就是脏页,(缓冲池里的页里的数据比磁盘里的数据新),那么此时数据库需要将新版本的页从缓冲池刷新到磁盘。
假如每次一个页的变化就将新的页的版本刷新到磁盘,多个页里的数据都发生了变化,如果都去刷盘的话,开销是非常大的,db的性能也变的非常差。而且,如果刷盘的时候宕机了,数据就不能恢复了。
为了避免数据刷盘时宕机带来的数据丢失问题,当前事务数据库系统普遍采用了一种策略,名叫 Write Ahead log策略,即当事务提交时,先写重做日志,再修改页。当由于发生宕机而导致数据丢失时,通过重做日志 redo log来完成数据的恢复,这也是事务ACID中的D持久性的要求。
假如redo log和 缓冲池足够大,能够缓冲所有数据,那么是不需要将缓冲池里页的新数据刷新到磁盘中的,因为宕机后,可以通过redo log恢复到宕机发生的时刻。很显然缓冲池不可能装的下数据库的所有数据,而redo log也不可能无限大,如果无限大,那么宕机后恢复的时候,运行了几个月几年的数据库,恢复会非常久,代价非常大。
所以CheckPoint技术的目的是解决以下问题:
- 1、缩短DB的恢复时间
- 2、缓冲池不够用时,将脏页刷新到磁盘
- 3、redo log不可用时,刷新脏页
当数据库发生宕机是,数据库不需要重做所有的日志,因为CheckPoint之前的页已经刷新回磁盘了,所以数据库只需要对CheckPoint后的redo log进行恢复,这样就缩短了恢复时间。

在innodb中,CheckPoint发生的时间,条件,脏页的选择都非常复杂。其实CheckPoint无非就是刷新缓冲区中页里的新数据到磁盘里,关键就是每次刷新多少页到磁盘,每次从哪里取脏页,以及什么时间触发CheckPoint,在innodb中有两种CheckPoint,分别为:
Sharp CheckPoint 一般不用
Fuzzy CheckPoint 默认使用
在innodb中可能发生如下几种情况的Fuzzy CheckPoint
1、对于Master Thread中发生的CheckPoint,差不多是以每秒或者每10s的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,不阻塞其他线程
2、flush lru list CheckPoint,innodb存储引擎需要保证LRU列表中有差不多100个空闲页可以使用,在innodb1.1.x版本之前,需要检查LRU列表中是否有足够的可用空间操作发生在用户查询线程中,显然这会阻塞用户的查询操作。倘若没有100个可用空闲页,那么innodb存储引擎会将LRU列表尾端的页移除。如果这些页有脏页,则需要CheckPoint,而这些页是来自LRU列表的,所以称为FLUSH_LRU_LIST CheckPoint。
3、redolog不可用的时候需要将一些页刷新回磁盘,而此时脏页是从脏页列表中选取的,


4、脏页太多的时候触发CheckPoint
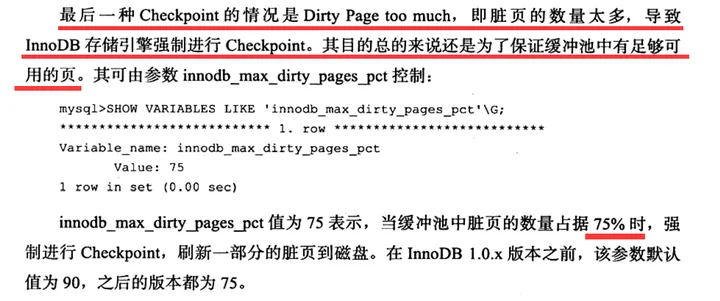
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1486
- 银河麒麟打印带有图像的文档时出错 1404
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1193
- 统信操作系统各版本介绍 1115
- 统信桌面专业版【如何查询系统安装时间】 1113
- 统信桌面专业版【全盘安装UOS系统】介绍 1067
- 麒麟系统也能完整体验微信啦! 1026
- 统信【启动盘制作工具】使用介绍 671
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 615
- 信刻全自动档案蓝光光盘检测一体机 526
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
