MySQL数据库——MySQL表的增删改查(进阶)

MySQL表的增删改查(进阶)
1. 数据库约束
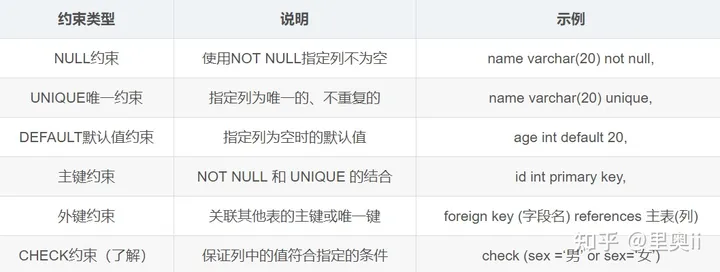
1.1 约束类型
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- DEFAULT - 规定没有给列赋值时的默认值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
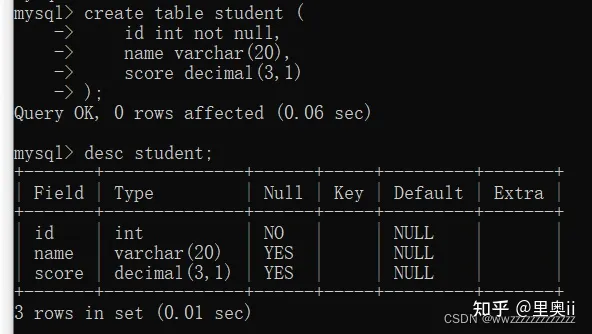
1.2 NULL约束
创建表时,可以指定某列不为空:
create table student (
id int not null,
name varchar(20),
score decimal(3,1)
);

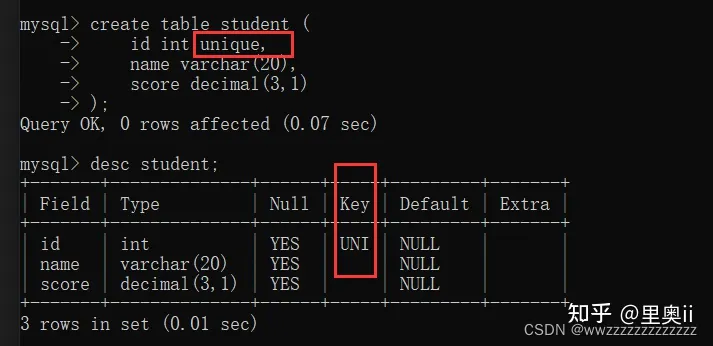
1.3 UNIQUE:唯一约束
create table student (
id int unique,
name varchar(20),
score decimal(3,1)
);

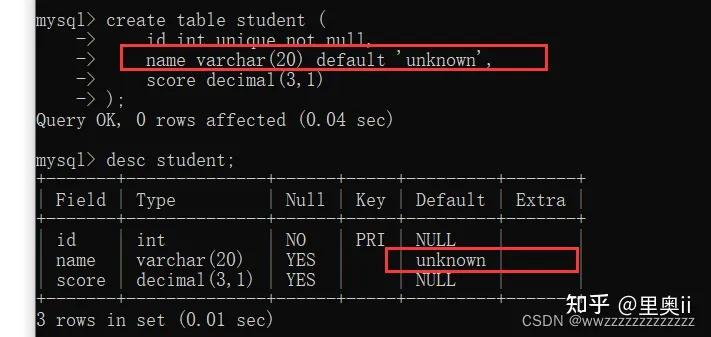
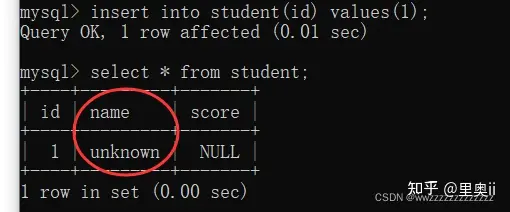
1.4 DEFAULT:默认值约束
create table student (
id int unique not null,
name varchar(20) default 'unknown',
score decimal(3,1)
);
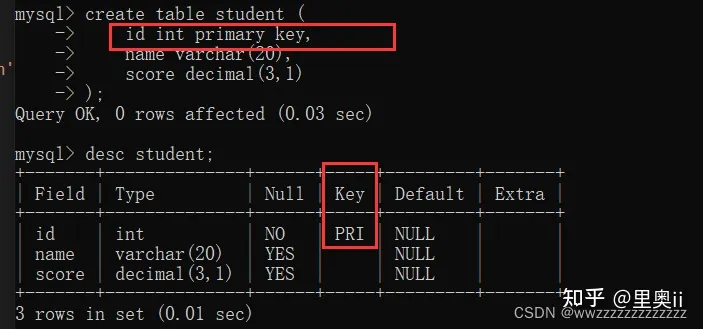
1.5 PRIMARY KEY:主键约束
等价于 not null + unique
create table student (
id int primary key,
name varchar(20),
score decimal(3,1)
);
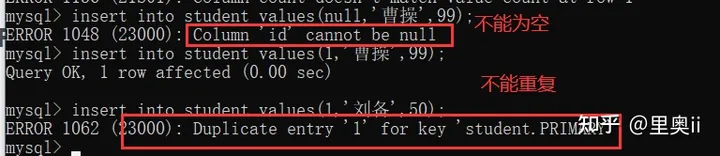
如何保证主键不重复?人工保证不太靠谱.
可以借助数据库自动来生成.----auto_increment
create table student (
id int primary key auto_increment,
name varchar(20),
score decimal(3,1)
);
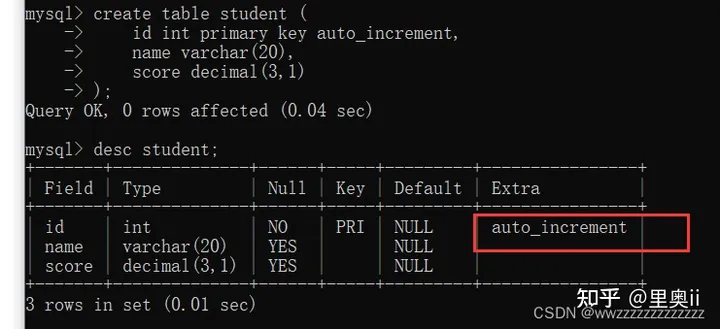
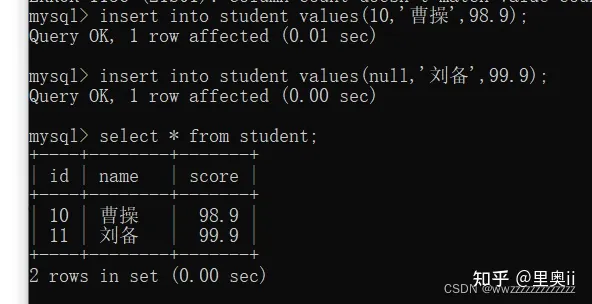
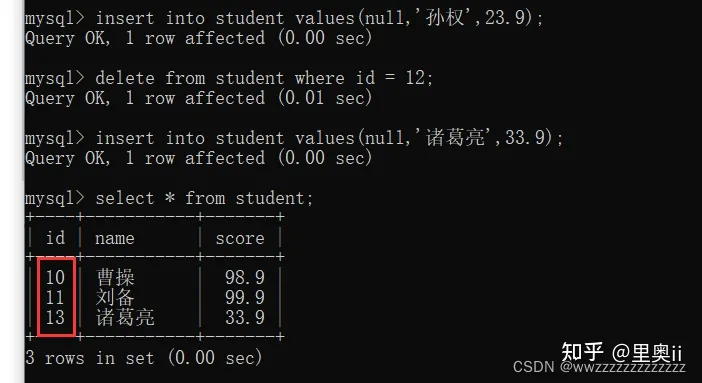
自增的特点是:
如果表中没有任何的记录,自增从1开始.
如果表中已经有记录了,自增从上一条记录往下自增.
如果中间某个数据删了,再次插入数据,刚才删掉的自增主键的值不好被重复利用
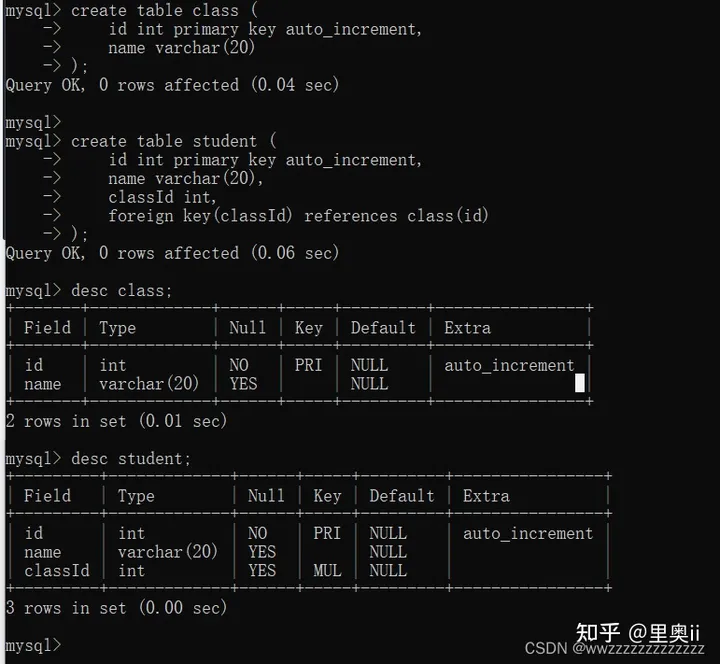
1.6 FOREIGN KEY:外键约束
描述两张表的之间的关联关系
外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列)例:
create table class (
id int primary key auto_increment,
name varchar(20)
);
create table student (
id int primary key auto_increment,
name varchar(20),
classId int,
foreign key(classId) references class(id)
);

1.7 CHECK约束(了解)
MySQL使用时不报错,但忽略该约束:
create table user_test (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);
2. 表的设计
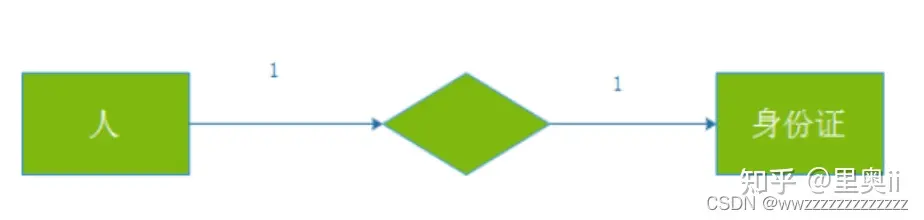
2.1 一对一
2.2 一对多
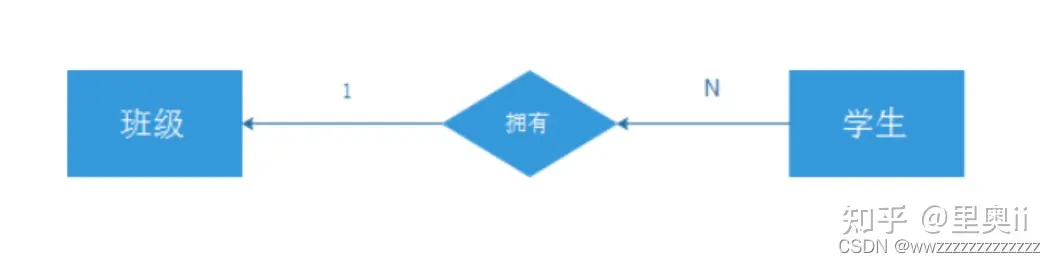
2.3 多对多
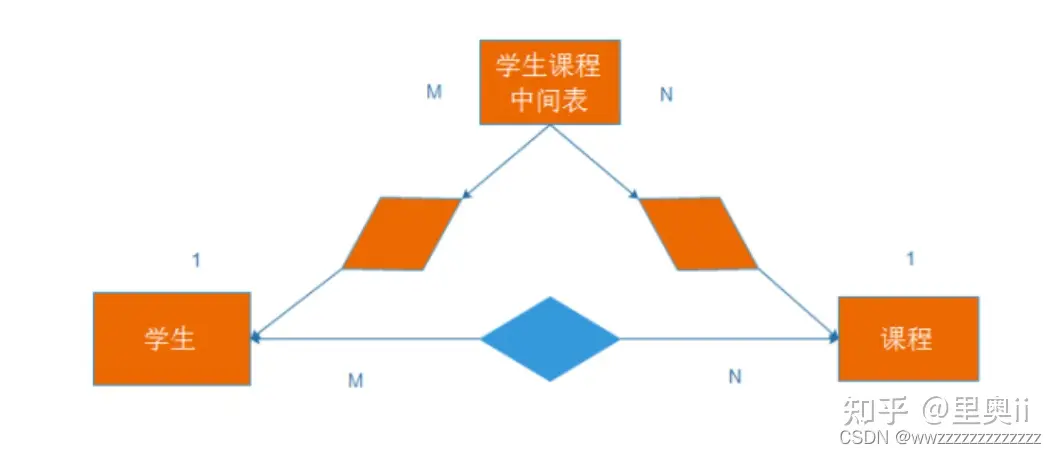
多对多的关系两者之间的对应关系是非常复杂的.
多对多这个关系复杂需要引入中间表来解决这个问题.
例如,描述每个同学的每个科目的考试成绩.
先创建表来描述同学的信息,然后创建表描述科目信息.
create table student(
id int primary key auto_increment,
name varchar(20)
);
create table course(
id int primary key auto_increment,
name varchar(20)
);
insert into student values
(null,'甲'),
(null,'乙'),
(null,'丙'),
(null,'丁');
insert into course values
(null,'语文'),
(null,'数学'),
(null,'英语'),
(null,'物理'),
(null,'化学');
为了描述每个同学每一科考了多少分,就需要搞一个中间表来描述.
create table score(
courseId int,
studentId int,
score decimal(3,1)
);
insert into score values
(1,1,90);
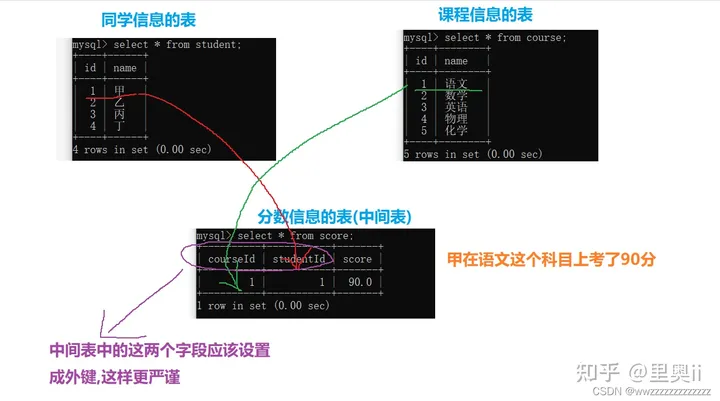
如果想查找"甲"这个同学的"语文"成绩如何?
此时的查找过程就会更复杂.
- 先找到甲的studentld
- 在找到语文的courseld
- 结合这两个id再在score表中查找
3. 新增
插入查询结果
语法:
insert into [表名] select [列名],[列名]... from [表名];案例:
create table user(
id int primary key auto_increment,
name varchar(20),
description varchar(1000)
);
insert into user values
(null,'曹操','乱世枭雄'),
(null,'刘备','仁德之主'),
(null,'孙权','年轻有为');
create table user2(
name varchar(20),
description varchar(1000)
);
insert into user2 select name,description from user;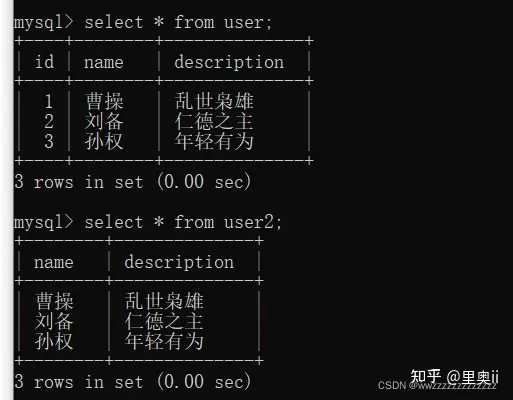
4. 查询
4.1 聚合查询
4.1.1 聚合函数
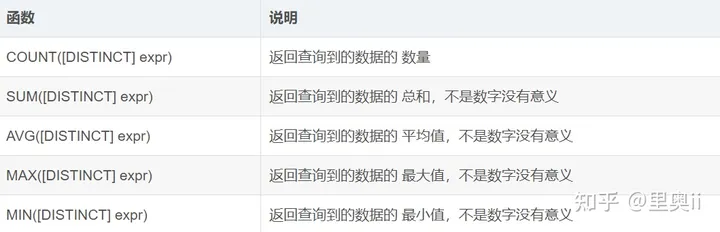
4.1.1.1 COUNT
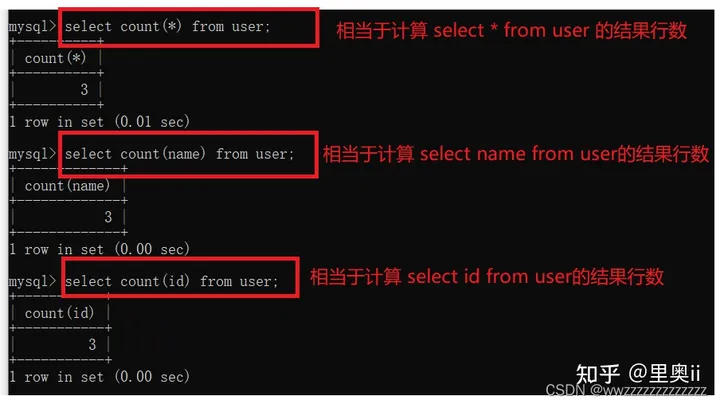

4.1.1.2 SUM
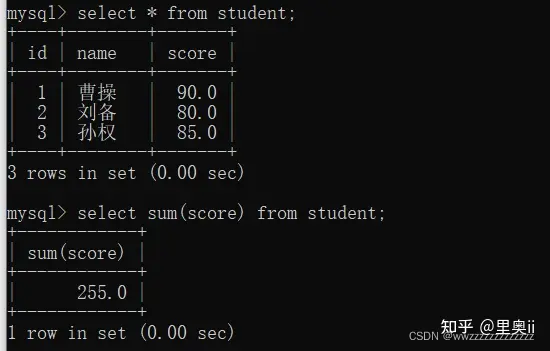
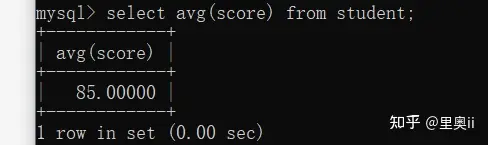
4.1.1.3 AVG
4.1.1.4 MAX
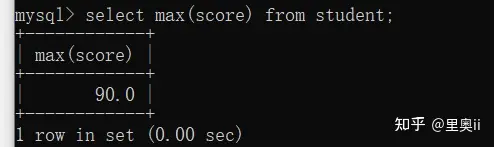
4.1.1.5 MIN
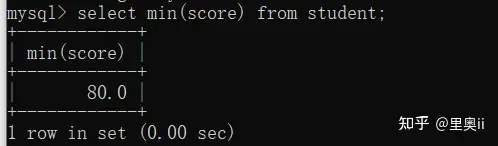
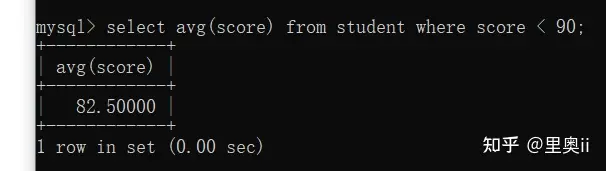
案例求所有分数小于90的同学的平均分
4.1.2 GROUP BY子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时, SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
select column1, sum(column2), .. from table group by column1,column3;案例:
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
insert into emp(name, role, salary) values
('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66);查询每个角色的最高工资、最低工资和平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role;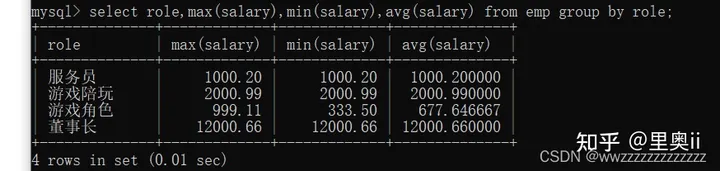
4.1.3 HAVING
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
显示平均工资低于1500的角色和它的平均工资
select role,avg(salary) from emp group by role having avg(salary) <1500;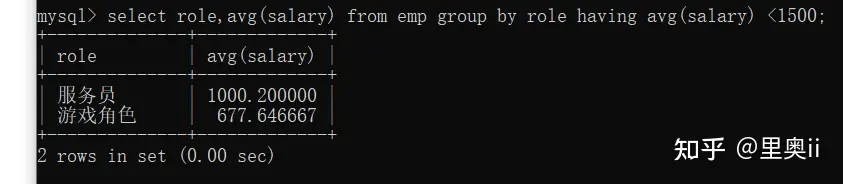
4.2 联合查询
实现联合查询的基本机制 : 笛卡尔积

测试数据:
create table classes (id int primary key auto_increment,name varchar(20),`desc` varchar(100));
create table student (id int primary key auto_increment,sn varchar(20),name varchar(20),qq_mail varchar(20),classes_id int);
create table course (id int primary key auto_increment,name varchar(20));
create table score (score decimal(3,1),student_id int,course_id int);
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68,3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23,4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);4.2.1 内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;注:多表查询时,写列的时候要写成[表名].[列名]
示例1: 查找名字为"许仙"的同学的所有成绩
思路 : 许仙在 student 表中 ,成绩是score表, 对两个表进行笛卡尔积,如何按照条件筛选,名字为许仙,id相同.
select score.score from student,score where student.id = score.student_id and student.name = '许仙';
select score.score from student inner join score on student.id = score.student_id and student.name = '许仙';

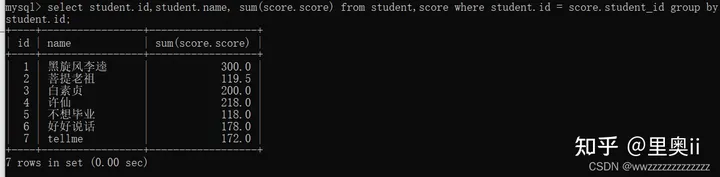
示例2: 查找所有同学的总成绩,以及该同学的基本信息
思路 : 同学信息在student表中,成绩是score表,对两个表进行笛卡尔积.然后按照筛选条件筛选.
select student.id,student.name, sum(score.score) from student,score where student.id = score.student_id group by student.id;注: 如果某一列若干行的值已经相同的了,group by 没影响
如果某一个列若干行不相同,group by 最终就只剩下一条记录.
示例3: 查找所有同学的每一科的成绩,和同学的相关信息
思路 : 需要3张表 studednt表 score表 course表
先对3张表进行笛卡尔积. 然后根据id进行筛选
select student.id,student.name,course.name,score.score from student,score,course where student.id = score.student_id and course.id = score.course_id;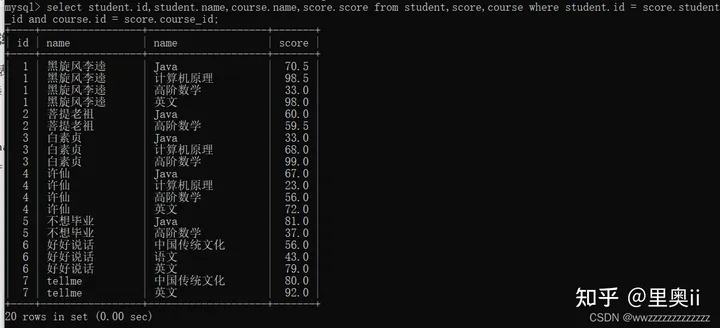
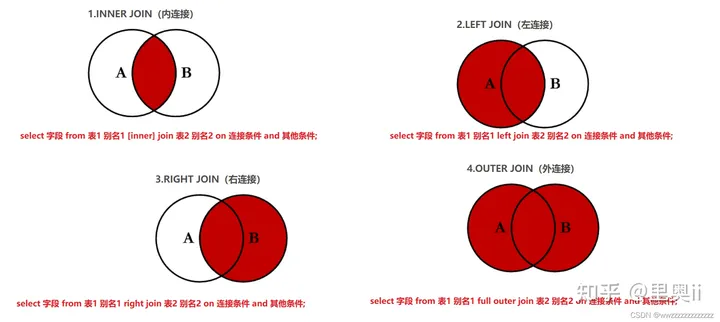
4.2.2 外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;示例1: 查询所有同学的成绩,及同学的个人信息,如果该同学没有成绩,也需要显示
select student.id,student.name,course.name,score.score from student left join score on student.id = score.student_id left join course on score.course_id = course.id;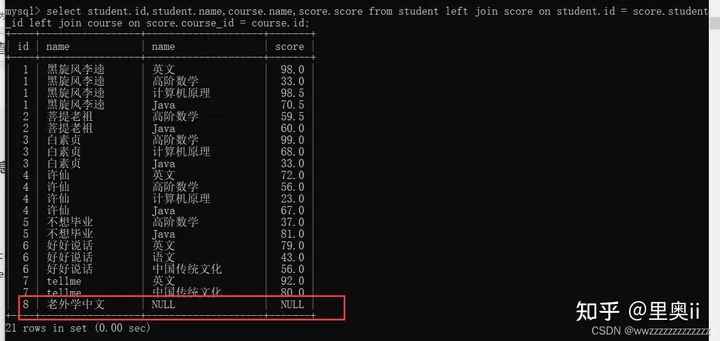
4.2.3 自连接
自连接是指在同一张表连接自身进行查询
示例1: 所有计算机原理的成绩 比 Java 成绩高的同学
- 先找到Java和计算机原理课程id — 计算机组成原理id=3 javaid = 1
- 对score表 进行 笛卡尔积 (score表 和 score表 分为命名为 s1 和 s2)
- 筛选条件1 s1.student_id = s2.student.id
- 筛选条件2 s1.course_id = 3 s2.course_id =1
- 筛选条件3 s1.score > s2.score
select s1.student_id from score s1,score s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;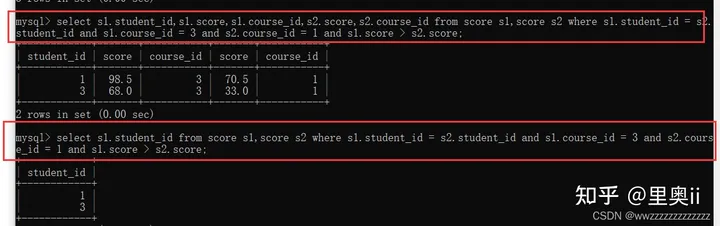
4.2.4 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:子查询只有一行
示例1: 查询与“不想毕业” 同学的同班同学:
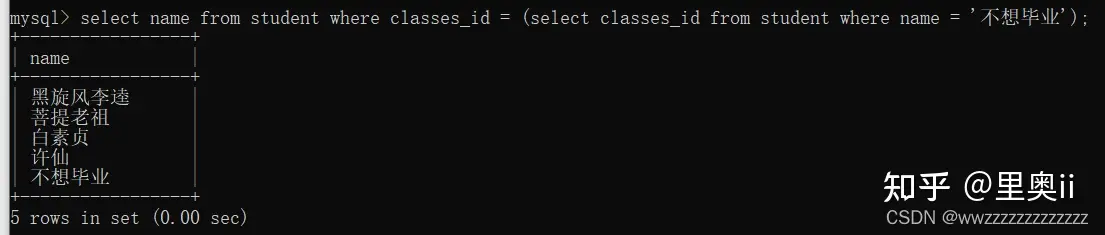
select name from student where classes_id = (select classes_id from student where name = '不想毕业');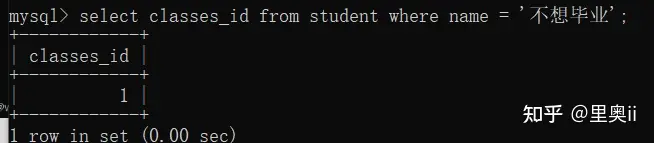
多行子查询:返回多行记录的子查询
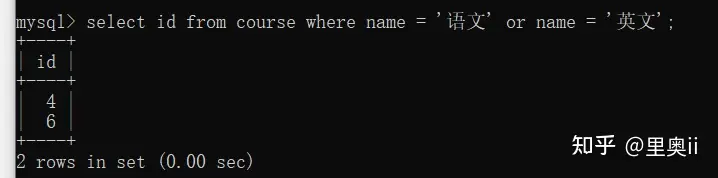
查询"语文"或者"英文"课程的成绩信息
- [NOT] IN关键字:
-- 使用in
select * from score where course_id in (select id from course where name = '语文' or name = '英文');
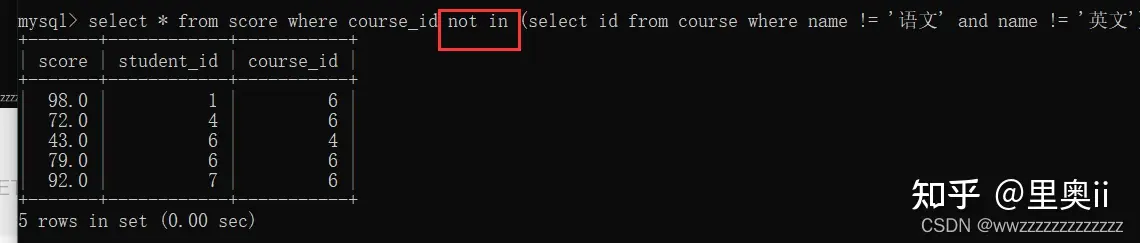
-- 使用 not in
select * from score where course_id not in (select id from course where name != '语文' and name != '英文');

2. [NOT] EXISTS关键字:
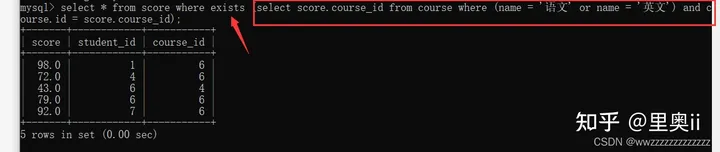
-- 使用exists
select * from score where exists (select score.course_id from course where (name = '语文' or name = '英文') and course.id = score.course_id);
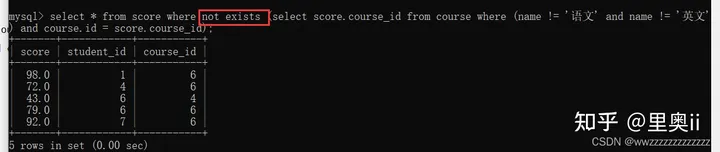
-- 使用not exists
select * from score where not exists (select score.course_id from course where (name != '语文' and name != '英文') and course.id = score.course_id);
如果子表查询的结果集合比较小,就使用in
如果子表查询的结果集合比较大,而主表的集合小,就使用exists
4.2.5 合并查询
相当于把多个查询的结果集合合并成一个集合
可以使用集合操作符union,union all
示例1: 查询 id < 3 或者 名字为 "英语"的课程
select * from course where id < 3 union select * from course where name = '英文';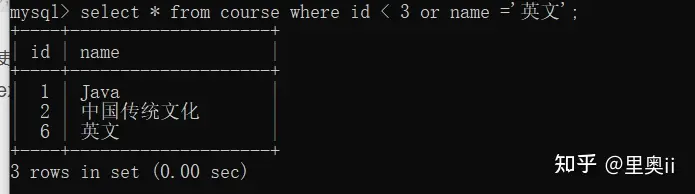

如果两个查询结果中存在相同的记录,就会只保留一个
如果不想去重,可以使用 union all即可.
示例2: 查询id小于3,或者名字为“Java”的课程
select * from course where id<3 union all select * from course where name='Java';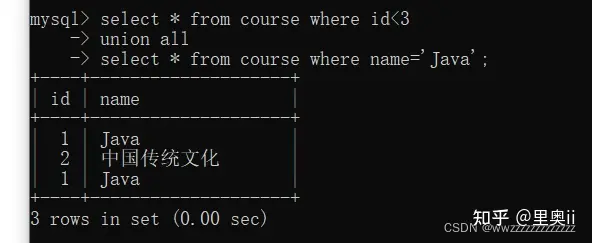
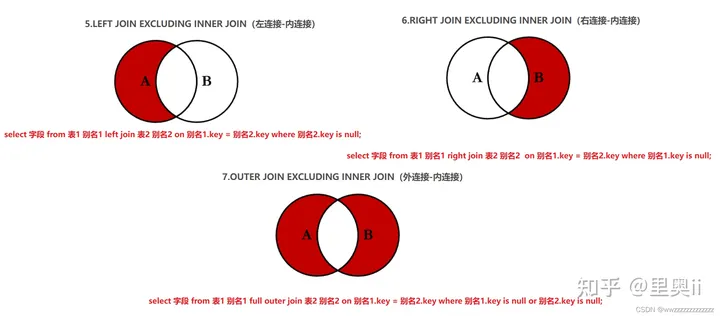
4.2.6 内连 外连 集合图
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1323
- 银河麒麟打印带有图像的文档时出错 1236
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1023
- 统信桌面专业版【如何查询系统安装时间】 951
- 统信操作系统各版本介绍 944
- 统信桌面专业版【全盘安装UOS系统】介绍 903
- 麒麟系统也能完整体验微信啦! 889
- 统信【启动盘制作工具】使用介绍 499
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 441
- 信刻全自动档案蓝光光盘检测一体机 386
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
