架构即代码:构建下一代企业(应用)架构体系

架构即代码,是一种架构设计和治理的思想,它围绕于架构的一系列模式,将架构元素、特征进行组合与呈现,并将架构决策与设计原则等紧密的与系统相结合。
如我的上一篇文章《为“架构”再建个模:如何用代码描述软件架构?》中所说,要准确描述软件的架构是一件颇具难度的事情。仅就实现的层面来说,也已经很难通过一个标准模型来让所有人达成一致,“哦,这就是架构”。也因此,在无法定义架构的情况下,也很难无法给出一个让所有人信服的架构治理模型。毕竟:模型只有合适的,永远没有对的。
但是呢,我们(ArchGuard Team)依旧会在 ArchGuard 构建出一个架构模型,以及架构治理模型,作为推荐的 “最佳实践”。除此,我们还应该提供一种自定义企业应用架构的可能性,这就是架构即代码。面向初级架构师来说,他们只需要按照 ArchGuard 的最佳实践来实施即可;面向中高级架师,他们可以基于 ArchGuard 提供的插件化能力 + DSL 构建自己的架构体系。
所以,如你在其它系统中所看到的那样,要提供这样的能力,需要一定的编码、配置等。所以,我们就需要构建一个架构即代码的系统。那么,问题来了,即代码又是什么鬼。
架构即代码是什么?
在先前的一系列的代码化(https://ascode.ink/)文章中,描述了如何将软件开发完全代码化,包含了将文档、需求、设计、代码、构建、部署、运营等变成代码化。设计和实现一个领域特定语言并不难,如《领域特定语言设计技巧》一文中所描述的过程,在这个上下文之下就是:
- 定义呈现模式。寻找适合于呈现架构的方式,如 UML 图、依赖图、时序图等。
- 提炼领域特定名词。一系列的架构相关元素,如架构风格:微内核等、架构分层:MVC 等。
- 设计关联关系与语法。如何以自然的方式来关联这些架构元素,如关键词、解析占位符等。
- 实现语法解析。除了实现之后,另外一种还要考虑的是:如何提供更灵活的扩展能力?
- 演进语言的设计。版本迭代
也因此,我们将架构即代码定义为:
架构即代码,是一种架构设计和治理的思想,它围绕于架构的一系列模式,将架构元素、特征进行组合与呈现,并将架构决策与设计原则等紧密的与系统相结合。
接下来的问题就是,如何将这个理念有机的与系统结合在一起?并友好地提供这样的 API 接口(DSL)?
于是放到当前 ArchGuard 的 PoC,架构即代码的呈现方式是 “ArchDoc”,一种基于 Markdown 的交互式代码分析和治理方式。即所有的 “代码” 都通过 markdown 来管理,优点有一大堆:
- 使用内嵌 DSL (用语法块管理)表述架构
- 可以记录系统的架构文档,如架构决策、业务架构等
- 拥有广泛的解析库,能提供更灵活的定制灵感(Ctrl + C, Ctrl + V)。
- 自定义 Render
- 广泛的编辑工具支持
唯一的缺点就是实现这样一个工具并不简单。
架构即代码的特点
不过,我们已经实现了一个简单的 PoC(概念证明)版本,在这个版本里,它的特点是:
- 显式地描述与呈现架构。
- 架构文档即是规则
- 设计、文档与实现一致
当然了,还有各种的可扩展能力(这是一个再普通不过的特点了)。
显式地描述与呈现架构
回到日常里,我们经常听架构师说,“我们的服务采用的是标准的 DDD 的分层架构”。但是,这个分层是不是诸如于 “Interface 层依赖于 application、domain、infrastructure 层” 等一系列的依赖关系?开发人员是否知道这些规则?这些都是问题。所以,一个架构即代码的系统,它应该能显式地呈现出系统中的那些隐性知识。
诸如于,我们应该将分层中的依赖关系,显式地声明写出来:
layered {
prefixId("org.archguard")
component("interface") dependentOn component("application")
组件("interface") 依赖于 组件("domain")
component("interface") dependentOn component("infrastructure")
组件("application") 依赖于 组件("domain")
组件("application") 依赖于 组件("infrastructure")
组件("domain") 依赖于 组件("infrastructure")
}PS:请忽视上面 Kotlin 代码中的中文元素,它只是用来说明使用中文描述的可能性。毕竟,开心的话,也可以使用文言文。
结合 ArchGuard 中的 DSL 与可视化工具(这里采用的是 Mermaid.js),就能呈现我们所设计的分层架构:
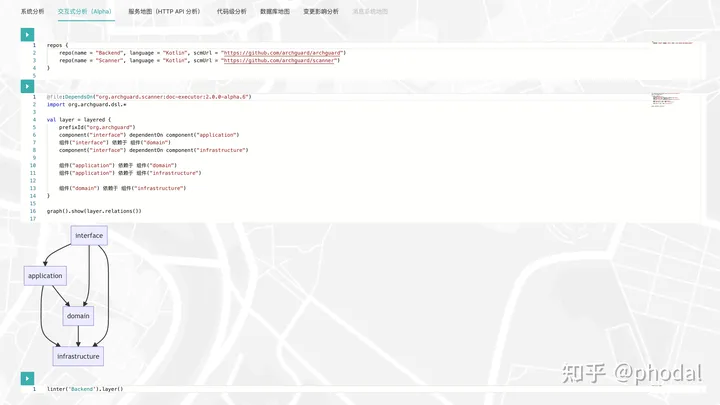
再再结合一下设计的分层 Linter 工具(正在实现中):
linter('Backend').layer()一旦分层中的依赖关系错了,就可以在持续集成中阻断这些代码的提交 —— 类似于 ArchUnit 这样的机制。稍有区别的是,你不需要将测试和代码放在代码库中,而是可以统一的去管理它们。
而对于其它一系列的更复杂的规则来说,我们可以自定义它们,并将他们与文档结合在一起。
架构文档即是规则
在这种模式之下,我们还可以将文档与代码相结合 —— 前提是:我们已经编写了一系列的规则。如我们在 ArchGuard 中,针对于不同的场景编写了一系列的规则:
- SQL,如不允许 select *
等 - Test Code,用于检测代码中的坏味道
- Web API ,分析 API 的设计是否 RESTful
- Layer (待实现),分析代码中的分层实现
- Arch (待实现),类似于 ArchUnit 或者 Guarding 制定更细的依赖规则
- Change(待实现),编写自定义的变更影响范围规则,如某个类不应该被其它的变更影响到
有了基本架构文档规范之后,我们可以规则化它们,并结合到一起。如下是一个结合 Checklist 和规则的列表示例:
- [x] 不应该存在被忽略(Ignore、Disabled)的测试用例 (#no-ignore-test)
- [ ] 允许存在重复的 assertion (#redundant-assertion) #no-ignore-test 对应于正在实现的 ArchGuard 中的规则,而 GFM 的 Checklist 中,如果 check 了,则可以表示为开启规则;如果没有 check,则为不开启。前面的文字部分,则是对应的规则描述,与传统的 linter 相比较,略显灵活。
而不论是编写文档还是阅读文档的人,他们可以很轻松地构建起对应的上下文。
设计、文档与代码一致
有了设计和文档之后,就需要结合到已有的代码中,让三者保持一致和准确。在我们的场景之下,就是 ArchGuard 已有的 API,它包含了:
- 创建对于代码仓库的分析
- 分析代码的语法和构建工具、变更历史等
- 分析代码是否满足规则等
如下是 ArchGuard 中对于 repo 设计的 DSL(基于 Kotlin),用于创建代码仓库的分析:
repos {
repo(name = "Backend", language = "Kotlin", scmUrl = "https://github.com/archguard/archguard")
repo(name = "Frontend", language = "TypeScript", scmUrl = "https://github.com/archguard/archguard-frontend")
repo(name = "Scanner", language = "Kotlin", scmUrl = "https://github.com/archguard/scanner")
}只有三者保持了一致,我们才能确保架构的设计与实现是一致的。
架构即代码是个什么系统?
从实现的层面来说,一个架构即代码系统是一个支持编排的数据系统。原因在于,我们并不想关心数据处理的过程,但是想获取数据的结果,从结果中获取洞见。正如,我们所见到的一个个大数据系统,构建了一个个的可视化能力,以祈祷从中得到洞见。
不过,和祈祷稍有不同的是,我们是带着 N% 可能性的猜想,所以叫做探索。
一种探索式的架构治理
传统的软件开发模型是:编辑-编译-运行(edit-compile-run),这种开发模型的前提是,我们拥有足够的业务洞见。对于一个带着丰富领域知识的业务系统来说,构建这样一个系统并不是一件困难。但是,当我们缺乏足够的领域专家,我们应该如何往下走呢?复杂问题,你只能探索 (Probe) -> 感知 (Sense) -> 响应 (Respond)。
而既然我们本身和很多新生代的架构师一样,也需要探索,也需要分析,然后才是得到结论。那么,我们不妨再尝试切换一下模式。如同,我们构建 ArchGuard 的软件开发模型,也是执行-探索(execute-explore),先从分析一下系统(发布一个分析功能),再配合已有的模式,最后得到 “结论” 或者规则(再发布一个 linter 功能)。
在数据领域,这种方式相当的流行,过去人们用 IPython,现在都改用 Jupyter;另外一个类型则是类似于 RMarkdown 提供的报表式的思路。
- IPython。 is a command shell for interactive computing in multiple programming languages.
- Jupyter Notebook. is a web-based interactive computing platform.
- R Markdown。Turn your analyses into high quality documents, reports, presentations and dashboards with R Markdown.
- D3.js 社区的 Observable。用于 Explore, analyze, and explain data. As a team.
从模式上来说,ArchGuard 更偏向于 RStudio 的模式,只是从社区的资源上来说,Jupyter 相关的实现比较多。
一个经常 OOM 的 “大数据系统”
在我们(ArchGuard core team)的 “数次讨论” 中,最终认为 ArchGuard 是一个大数据分析,而不是简单的数据分析。原因是系统中存在大量的 bug 和大数据相关的(狗头):
- 存在一定数量的 Out of Memory。
- 大数据量情况下的可视化优化。
也就是所谓的 ”bug 驱动的架构设计“。
除此,之后另外一个颇有意思的点是,对于更大型的系统来说,它存在大量的新的提交,又或者是新的分支。我们即需要考虑:应对持续提交的代码,构建增量分析的功能。
当我们尝试使用大数据的思路,如 MapReduce、Streaming Analysis 相关的模式来解决相关的问题时,发现它是可以 work 的不错的 —— 毕竟都是数据分析。
在 ArchGuard 是如何实现的?
ArchGuard 围绕于 DSL + Kotlin REPL + 数据可视化,构建了一个可交互的架构分析与治理平台。因为还在实现中,所以叫下一代。
1. 提炼架构元素
上文中的(https://ascode.ink/)系列中,也包含了两个架构相关的工具,一个是代码生成 DSL:Forming、另外一个则是架构守护 DSL:Guarding。两个 DSL 所做的事情是,围绕特定的规则将架构元素组合到一起,这里的架构元素。
如果没有做过,这一个过程看上去是挺麻烦的,实现上有一些颇为简单的东西可以参考(复制):
- 架构描述语言论文(ADL)。ADL 已经是一个很成熟的领域了,在设计模式火的那个年代,架构模式(《面向模式的软件架构》)也特别的火。
- 架构相关书籍的目录。一本好的架构书,只需要看目录就能有个索引,所以也就有了基本的架构元素。
- 架构的模式语言。模式语言所呈现的是模式之间的关系
- ……
仅仅是复制那多没意思,要是能自己做做抽象,也是一种非常好玩的事情。
2. 构建插件化与规则分析
如上所述,在 ArchGuard 中,我们尝试以一系列的规则,构建系统的规则,而这些规则是以插件化的形式暴露的。
这就意味着,这样一个系统应该是支持自定义的插件化能力,它即可以让你:
- 接入一个新的语言
- 编写新的规则
- 构建新数据的 pipeline
在 ArchGuard 中还需要改进的是,提供一种元数据的能力。
3. 抽象 DSL 作为胶水
从实现层面来说,为了支撑粘合的能力,我们目前计划设计了三种能力的 DSL:后端架构查询 DSL、架构 DSL、特征 DSL。
后端架构查询 DSL
类似于 LINQ (Language Integrated Query,语言集成查询)封装 CRUD 接口,以提供编译时类型检查或智能感知支持,在 Kotlin 中有诸如于:KtOrm 的形式。如:
database
.from(Employees)
.select(Employees.name)
.where { (Employees.departmentId eq 1) and (Employees.name like "%vince%") }
.forEach { row ->
println(row[Employees.name])
}
像一个编程语言编写,可以提供更友好的语法性支持。
架构 DSL
即架构描述语言(Architecture Description Language),以提供一种有效的方式来描述软件架构。
特征 DSL:分析、扫描与 Linter
即封装 ArchGuard Scanner、Analyser、Linter 等,用于构建系统所需要的基础性架构特征。
4. 构建可交互的环境
两年前,在与众多的 Thoughtworker 一起构建 Ledge 的时候,我们就一直在强调文档代码化,并提供可交互的文档环境。在 Ledge 里,你可以使用 Markdown 来绘制各类的图表,只需要借助声明图表类型,示例见:https://devops.phodal.com/helper 。
从模式上来说,ArchGuard 更像是一个 RStudio + Jupyter 的结合版,即提供了大量自定义图形 + 组件能力的 REPL。
在 REPL 上,由于我们计划使用 Kotlin 构建 DSL,所以需要寻找的是 Kotlin 的 REPL。Kotlin 官方创建的 kotlin-jupyter 便成为了一个很好的参考,可惜还没有用得上。与此同时,Kotlin 在设计初期就有了 Kotlin Scripting 的场景,所以其实
kotlin-scripting-compiler-embeddable就能满足需求。于是,在 PoC 里,我们参考了 Apache Zeppelin 引入了 Kotlin REPL,并创建了一个 WebSocket 作为服务。
在可视化上,稍微复杂一些,需要构建一个 Markdown 解析器、Block 编辑器等。我们暂时采用了 Mermaid.js 作为可视化的图形库之一,另外的还有 D3.js、Echarts 也是其中之一。剩下的问题,便是如何通过 DSL 来整合它们?构建前后端的数据模型是一个临时的方案?
PoC 示例见截图:
5. 依旧是一个 PoC
在这里,ArchGuard 的交互性分析,依然只是一个 PoC(概念证明),但是在不远的将来,你就可以在 ArchGuard 中使用它了。
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
- 上周热门
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1448
- 银河麒麟打印带有图像的文档时出错 1365
- 银河麒麟添加打印机时,出现“server-error-internal-error” 1151
- 统信桌面专业版【如何查询系统安装时间】 1073
- 统信操作系统各版本介绍 1070
- 统信桌面专业版【全盘安装UOS系统】介绍 1028
- 麒麟系统也能完整体验微信啦! 984
- 统信【启动盘制作工具】使用介绍 627
- 统信桌面专业版【一个U盘做多个系统启动盘】的方法 575
- 信刻全自动档案蓝光光盘检测一体机 484
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
