TF之DNN:TF利用简单7个神经元的三层全连接神经网络【2-3-2】实现降低损失到0.000以下

TF之DNN:TF利用简单7个神经元的三层全连接神经网络实现降低损失到0.000以下(输入、隐藏、输出层分别为 2、3 、 2 个神经元)
目录
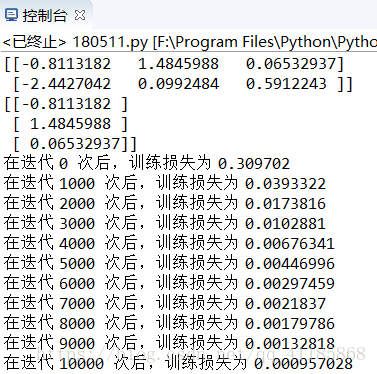
输出结果
实现代码
- -*- coding: utf-8 -*-
-
- import tensorflow as tf
- import os
- import numpy as np
-
- TF:TF实现简单的三层全连接神经网络(输入、隐藏、输出层分别为 2、3 、 2 个神经元)
- 隐藏层和输出层的激活函数使用的是 ReLU 函数。该模型训练的样本总数为 512,每次迭代读取的批量为 10。全连接网络以交叉熵为损失函数,并使用 Adam 优化算法进行权重更新。
- import tensorflow as tf
- from numpy.random import RandomState
- batch_size= 10
- w1=tf. Variable (tf.random_normal([ 2 , 3 ],stddev= 1 ,seed= 1 ))
- w2=tf. Variable (tf.random_normal([ 3 , 1 ],stddev= 1 ,seed= 1 ))
- None 可以根据batch 大小确定维度,在shape的一个维度上使用None
- x=tf.placeholder(tf.float32,shape=( None , 2 ))
- y=tf.placeholder(tf.float32,shape=( None , 1 ))
- 激活函数使用ReLU
- a=tf.nn.relu(tf.matmul(x,w1))
- yhat=tf.nn.relu(tf.matmul(a,w2))
- 定义交叉熵为损失函数,训练过程使用Adam算法最小化交叉熵
- cross_entropy=-tf.reduce_mean(y*tf.log(tf.clip_by_value(yhat, 1e-10 , 1.0 )))
- train_step=tf.train. AdamOptimizer ( 0.001 ).minimize(cross_entropy)
- tf.train.AdamOptimizer(learning_rate).minimize(cost_function) 是进行训练的函数,其中我们采用的是 Adam 优化算法更新权重,并且需要提供学习速率和损失函数这两个参数。
- rdm= RandomState ( 1 )
- data_size= 516
- 生成两个特征,共data_size个样本
- X=rdm.rand(data_size, 2 )X=rdm.rand(512,2) 表示随机生成 512 个样本,每个样本有两个特征值。
- 定义规则给出样本标签,所有x1+x2<1的样本认为是正样本,其他为负样本。Y,1为正样本
- Y = [[int(x1+x2 < 1 )] for (x1, x2) in X]
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- print (sess.run(w1))
- print (sess.run(w2))
- steps= 11000
- for i in range(steps):
- 选定每一个批量读取的首尾位置,确保在1个epoch内采样训练
- start = i * batch_size % data_size
- end = min(start + batch_size,data_size)
- sess.run(train_step,feed_dict={x:X[start:end],y:Y[start:end]})
- if i % 1000 == 0 :
- training_loss= sess.run(cross_entropy,feed_dict={x:X,y:Y})
- print ( "在迭代 %d 次后,训练损失为 %g" %(i,training_loss))
网站声明:如果转载,请联系本站管理员。否则一切后果自行承担。
赞同 0
评论 0 条
- 上周热门
- Kingbase用户权限管理 2007
- 信刻全自动光盘摆渡系统 1738
- 信刻国产化智能光盘柜管理系统 1407
- 银河麒麟添加网络打印机时,出现“client-error-not-possible”错误提示 1002
- 银河麒麟打印带有图像的文档时出错 906
- 银河麒麟添加打印机时,出现“server-error-internal-error” 698
- 麒麟系统也能完整体验微信啦! 645
- 统信桌面专业版【如何查询系统安装时间】 616
- 统信操作系统各版本介绍 607
- 统信桌面专业版【全盘安装UOS系统】介绍 581
- 本周热议
- 我的信创开放社区兼职赚钱历程 40
- 今天你签到了吗? 27
- 信创开放社区邀请他人注册的具体步骤如下 15
- 如何玩转信创开放社区—从小白进阶到专家 15
- 方德桌面操作系统 14
- 我有15积分有什么用? 13
- 用抖音玩法闯信创开放社区——用平台宣传企业产品服务 13
- 如何让你先人一步获得悬赏问题信息?(创作者必看) 12
- 2024中国信创产业发展大会暨中国信息科技创新与应用博览会 9
- 中央国家机关政府采购中心:应当将CPU、操作系统符合安全可靠测评要求纳入采购需求 8
热门标签更多
