糟糕!运行着的线上系统突然卡死无法访问,万恶的JVM GC!
2、年轻代gc到底多久一次对系统影响不大?
通常来说是不大的,不知道大家发现没有,其实年轻代gc几乎没什么好调优的,因为他的运行逻辑非常简单,就是Eden一旦满了 无法放新对象就触发一次gc。
一般来说,真要说对年轻代的gc进行调优,只要你给系统分配足够的内存即可,核心点还是在于堆内存的分配、新生代内存的分配
内存足够的话,通常来说系统可能在低峰时期在几个小时才有一次新生代gc,高峰期最多也就几分钟一次新生代gc。
而且一般的业务系统都是部署在2核4G或者4核8G的机器上,此时分配给堆的内存不会超过3G,给新生代中的Eden区的内存也就1G左 右。
而且新生代采用的复制算法效率极高,因为新生代里存活的对象很少,只要迅速标记出这少量存活对象,移动到Survivor区,然后回收 掉其他全部垃圾对象即可,速度很快。
3、什么时候新生代gc对系统影响很大?
当你的系统部署在大内存机器上的时候,比如说你的机器是32核64G的机器,此时你分配给系统的内存有几十个G,新生代的 Eden区可能30G~40G的内存。
比如类似Kafka、Elasticsearch之类的大数据相关的系统,都是部署在大内存的机器上的,此时如果你的系统负载非常的 高,对于大数据系统是很有可能的,比如每秒几万的访问请求到Kafka、Elasticsearch上去。
那么可能导致你Eden区的几十G内存频繁塞满要触发垃圾回收,假设1分钟会塞满一次。
然后每次垃圾回收要停顿掉Kafka、Elasticsearch的运行,然后执行垃圾回收大概需要几秒钟,此时你发现,可能每过一分钟,你的系 统就要卡顿几秒钟,有的请求一旦卡死几秒钟就会超时报错,此时可能会导致你的系统频繁出错。
4、如何解决大内存机器的新生代GC过慢的问题?
用G1,设置一个期望的每次GC的停顿时间,比如我们可以设置一个20ms。
那么G1基于他的Region内存划分原理,就可以在运行一段时间之后,比如就针对2G内存的Region进行垃圾回收,此时就仅仅停顿 20ms,然后回收掉2G的内存空间,腾出来了部分内存,接着还可以继续让系统运行。
G1天生就适合这种大内存机器的JVM运行,可以完美解决大内存垃圾回收时间过长的问题。
5、要命的频繁老年代gc问题.
对象进入老年代的几个条件:
1、年龄太大了、
2、动态年龄判断规则、
3、新生代gc后存活对象太多无法放入Survivor中。
第一个,对象年龄太大了,这种对象一般很少,都是系统中确实需要长期存在的核心组件,他们一般不需要被回收掉,所以在新生代熬 过默认15次垃圾回收之后就会进入老年代。
第二个,动态年龄判定规则,如果一次新生代gc过后,发现Survivor区域中的几个年龄的对象加起来超过了Survivor区域的50%,比如 说年龄1+年龄2+年龄3的对象大小总和,超过了Survivor区域的50%,此时就会把年龄3以上的对象都放入老年代。
第三个,新生代垃圾回收过后,存活对象太多了,无法放入 Surviovr中,此时直接进入老年代。
第二个和第三个都是很关键的,通常如果你的新生代中的Survivor区域内存过小,就会导致上述第二个和第三个条件 频繁发生,然后导致大量对象快速进入老年代,进而频繁触发老年代的gc,如下图。
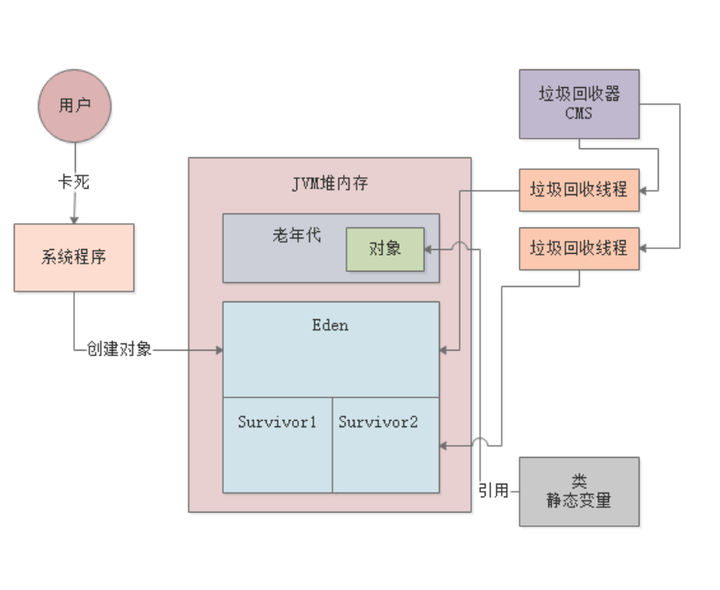
老年代gc通常来说都很耗费时间,无论是CMS垃圾回收器还是G1垃圾回收器,因为比如说CMS就要经历初始标记、并发标记、重新标 记、并发清理、碎片整理几个环节,过程非常的复杂,G1同样也是如此。
通常来说,老年代gc至少比新生代gc慢10倍以上,比如新生代gc每次耗费200ms,其实对用户影响不大,但是老年代每次gc耗费2s, 那可能就会导致老年代gc的时候用户发现页面上卡顿2s,影响就很大了。
所以一旦你因为jvm内存分配不合理,导致频繁进行老年代gc,比如说几分钟就有一次老年代gc,每次gc系统都停顿几秒钟,那简直对 你的系统就是致命的打击。此时用户会发现页面上或者APP上经常性的出现点击按钮之后卡顿几秒钟。
6、JVM性能优化到底在优化什么?
系统真正最大的问题,就是因为内存分配、参数设置不合理,导致你的对象 频繁的进入老年代,然后频繁触发老年代gc,导致系统频繁的每隔几分钟就要卡死几秒钟。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 125
- 统信桌面专业版【全盘安装UOS系统】介绍 120
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 111
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
