小案例:用Pandas分析招聘网Python岗位信息
小案例:用Pandas分析招聘网Python岗位信息
1. 读取数据
import pandas as pd
import numpy as np
df = pd.read_csv('data/Jobs.csv')
df.head(2)
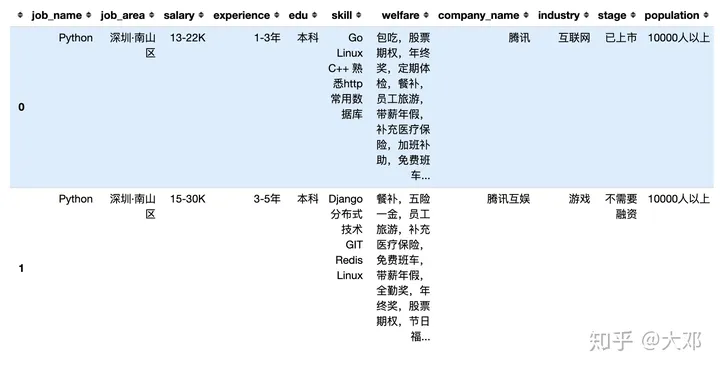
# 总数
len(df)
3562. 新增city字段
df['job_area'].unique()
array(['深圳·南山区', '深圳·龙岗区', '深圳', '深圳·福田区', '深圳·光明区', '深圳·龙华区', '深圳·宝安区',
'job_area', '北京', '北京·朝阳区', '北京·海淀区', '北京·通州区', '北京·东城区', '北京·丰台区',
'北京·大兴区', '北京·昌平区', '北京·西城区', '上海', '上海·杨浦区', '上海·浦东新区', '上海·徐汇区',
'上海·长宁区', '上海·青浦区', '上海·静安区', '上海·普陀区', '上海·黄浦区', '上海·闵行区',
'上海·虹口区', '上海·松江区', '广州·增城区', '广州·黄埔区', '广州·越秀区', '广州·番禺区',
'广州·天河区', '广州', '广州·海珠区', '广州·荔湾区', '广州·白云区'], dtype=object)
def extract_city(job_area):
if '深圳' in job_area:
return '深圳'
elif '广州' in job_area:
return '广州'
elif '北京' in job_area:
return '北京'
elif '上海' in job_area:
return '上海'
else:
return None
extract_city('上海-静安区')
'上海'
df['job_area'].apply(extract_city)
0 深圳
1 深圳
2 深圳
3 深圳
4 深圳
..
351 广州
352 广州
353 广州
354 广州
355 广州
Name: job_area, Length: 356, dtype: object
df['city']=df['job_area'].apply(extract_city)
df.head(2)
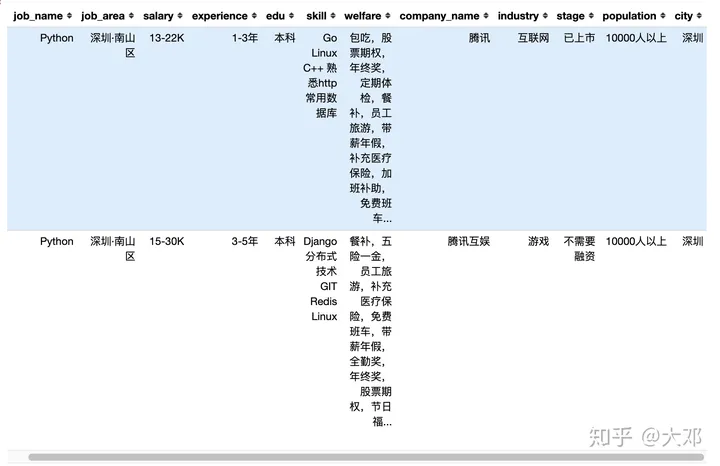
3. 三个字段公用一个apply函数
- salary
- experience
- population
步骤:
- 正则表达式抽取出数字列表
- 求均值
import re
text = '300-1000人'
def avg(text):
nums = re.findall('\d+', text)
nums = [float(x) for x in nums]
if nums:
return np.mean(nums)
else:
return 0
avg('300-1000人')
650.04. 薪资
salary
df['new_salary'] = df['salary'].apply(avg)
df.head(2)

5. 工作年限
experience
df['experience'].apply(avg)
0 2.0
1 4.0
2 0.0
3 7.5
4 4.0
...
351 4.0
352 2.0
353 6.0
354 4.0
355 0.0
Name: experience, Length: 356, dtype: float64
df['new_experience'] = df['experience'].apply(avg)
df.head(2)
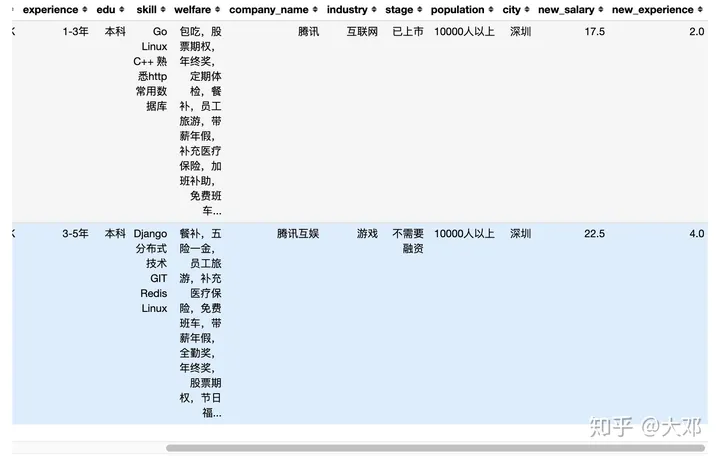
6. 员工人数
population
df['population'].apply(avg)
0 10000.0
1 10000.0
2 10000.0
3 10000.0
4 10000.0
...
351 299.5
352 59.5
353 59.5
354 299.5
355 10.0
Name: population, Length: 356, dtype: float64
df['new_population'] = df['population'].apply(avg)
df.head(2)

7. 教育
- 设计一个函数,出现正规学历,返回True(包括”不限“)
- 使用逻辑索引,把正规学历的招聘信息都保留
df['edu'].unique()
array(['本科', '博士', '硕士', '大专', '不限', 'edu', '6个月', '3个月', '7个月', '4天/周'],
dtype=object)
def edu_bool(level):
if level in ['本科', '博士', '硕士', '大专', '不限']:
return True
else:
return False
edu_bool('博士')
True
df['Edu_bool'] = df['edu'].apply(edu_bool)
df.head(2)
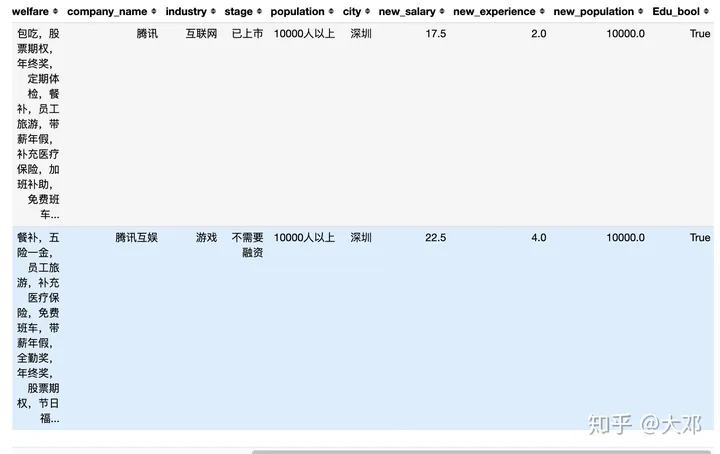
# 逻辑索引
new_df = df[df['Edu_bool']==True]
new_df.head(2)
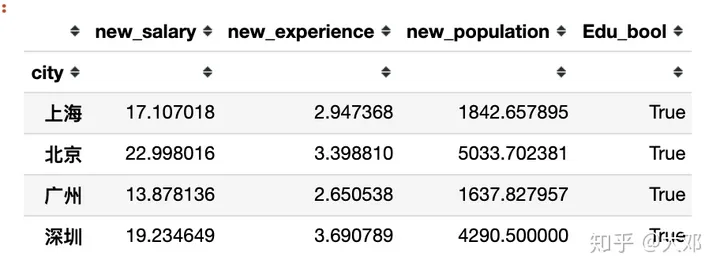
8. 城市/薪酬关系
city/salary
会用到df.groupby
new_df.groupby('city').mean()
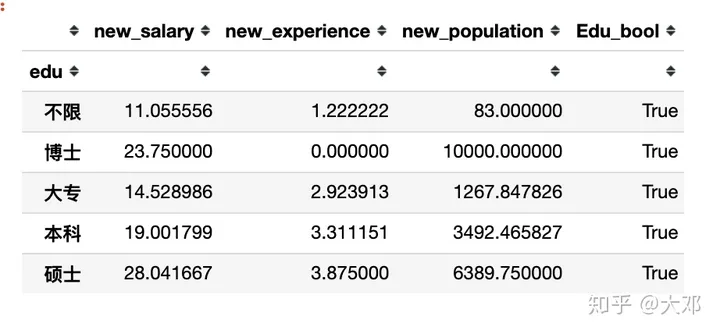
9. 学历/薪酬关系
edu/salary
会用到df.groupby
new_df.groupby('edu').mean()
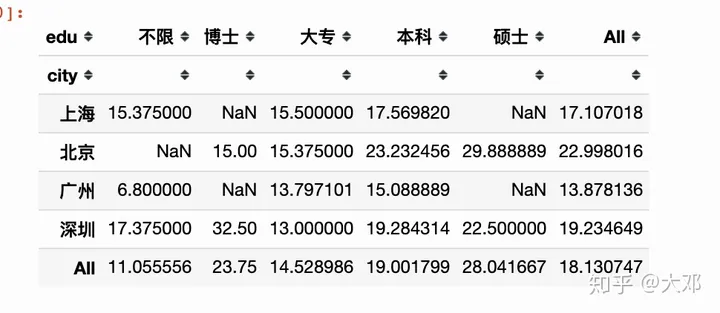
10. 城市/学历/薪酬关系
透视表
pd.pivot_table(df, index, columns, values, aggfunc, margins)
pd.pivot_table(new_df,
index='city',
columns='edu',
values='new_salary',
aggfunc=np.mean,
margins=True)
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
评价 0 条
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 126
- 统信桌面专业版【全盘安装UOS系统】介绍 121
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 114
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 105
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益209.03元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
