GaussDB数据库Query执行流程简介
图1 SQL引擎执行查询类SQL语句的流程
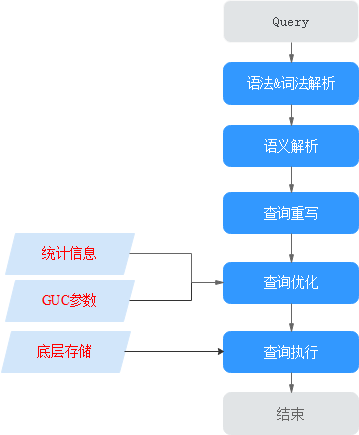
表1 SQL引擎执行查询类SQL语句的步骤说明
|
步骤 |
说明 |
|---|---|
|
语法&词法解析 |
按照约定的SQL语句规则,把输入的SQL语句从字符串转化为格式化结构(Stmt)。 |
|
语义解析 |
将“语法&词法解析”输出的格式化结构转化为数据库可以识别的对象。 |
|
查询重写 |
根据规则把“语义解析”的输出等价转化为执行上更为优化的结构。 |
|
查询优化 |
根据“查询重写”的输出和数据库内部的统计信息规划SQL语句具体的执行方式,也就是执行计划。统计信息和GUC参数对查询优化(执行计划)的影响 |
|
查询执行 |
根据“查询优化”规划的执行路径执行SQL查询语句。底层存储方式的选择合理性,将影响查询执行效率。 |
调优手段之统计信息
调优手段之GUC参数
查询优化的主要目的是为查询语句选择高效的执行方式。如下SQL语句:
select count(1)from customer inner join store_sales on (ss_customer_sk = c_customer_sk);
在执行customer inner join store_sales的时候,GaussDB支持Nested Loop、Merge Join和Hash Join三种不同的Join方式。优化器会根据表customer和表store_sales的统计信息估算结果集的大小以及每种join方式的执行代价,然后对比选出执行代价最小的执行计划。
正如前面所说,执行代价计算都是基于一定的模型和统计信息进行估算,当因为某些原因代价估算不能反映真实的cost的时候,我们就需要通过guc参数设置的方式让执行计划倾向更优规划。
调优手段之底层存储
GaussDB的表支持行存表、列存表,底层存储方式的选择严格依赖于客户的具体业务场景。一般来说计算型业务查询场景(以关联、聚合操作为主)建议使用列存表;点查询、大批量UPDATE/DELETE业务场景适合行存表。
对于每种存储方式还有对应的存储层优化手段,这部分会在后续的调优章节深入介绍。
调优手段之SQL重写
除了上述干预SQL引擎所生成执行计划的执行性能外,根据数据库的SQL执行机制以及大量的实践发现,有些场景下,在保证客户业务SQL逻辑的前提下,通过一定规则由DBA重写SQL语句,可以大幅度的提升SQL语句的性能。
这种调优场景对DBA的要求比较高,需要对客户业务有足够的了解,同时也需要扎实的SQL语句基本功,后续会介绍几个常见的SQL改写场景。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 2049
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 1990
- 银河麒麟桌面操作系统【保留数据盘重装系统】 1800
- 麒麟系统各种原因开不了机解决(合集) 1575
- 桌面通用(全架构)【rpm包转成deb包】操作方法 930
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 914
- 统信系统安装(合集) 852
- 统信桌面专业版【手动分区安装UOS系统】介绍 844
- 统启动异常几种类型(initramfs 模式) 687
- 最近下载排行榜
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 0
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 0
- 银河麒麟桌面操作系统【保留数据盘重装系统】 0
- 麒麟系统各种原因开不了机解决(合集) 0
- 桌面通用(全架构)【rpm包转成deb包】操作方法 0
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 0
- 统信系统安装(合集) 0
- 统信桌面专业版【手动分区安装UOS系统】介绍 0
- 统启动异常几种类型(initramfs 模式) 0

prtyaa 收益393.72元

zlj141319 收益220.97元

1843880570 收益214.2元

IT-feng 收益213.03元

风晓 收益208.24元

777 收益172.82元

Fhawking 收益106.6元

信创来了 收益105.89元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
