算力框架报告:拥抱AI算力加速国产化时代

算力全面国产化时代已提前到来
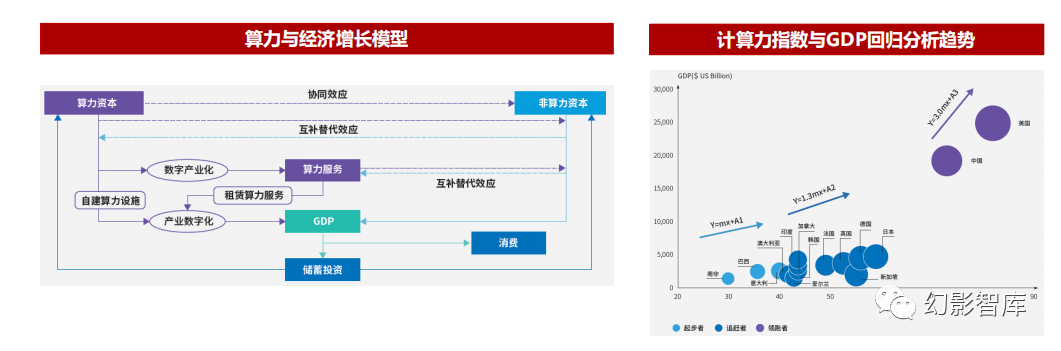
算力是数字经济运行和发展的基石和前提。IDC发布的《2021-2022全球计算力指数报告》指出,算力对经济增长的拉动具有长期性和倍增效应:计算力指数平均每提高1点,数字经济和GDP将分别增长3.5‰和1.8‰,当一个国家的计算力指数达到40分、60分时,计算力指数每提升1点,其 对于GDP增长的推动力将分别增加1.5倍和3.0倍;
算力全面国产化时代已提前到来。算力的基本载体是服务器,服务器的核心部件为CPU和类GPU等计算芯片,经过多年的技术积累和市场打磨,我 国国产CPU已从“可用”进入“好用”阶段,以运营商和金融为代表的大客户正有序进行信创服务器的集采和规模化应用;随着新一轮AI算力升级 的浪潮的兴起以及国际局势的迅速变化,我们认为AI算力芯片的国产化时点已提前到来。
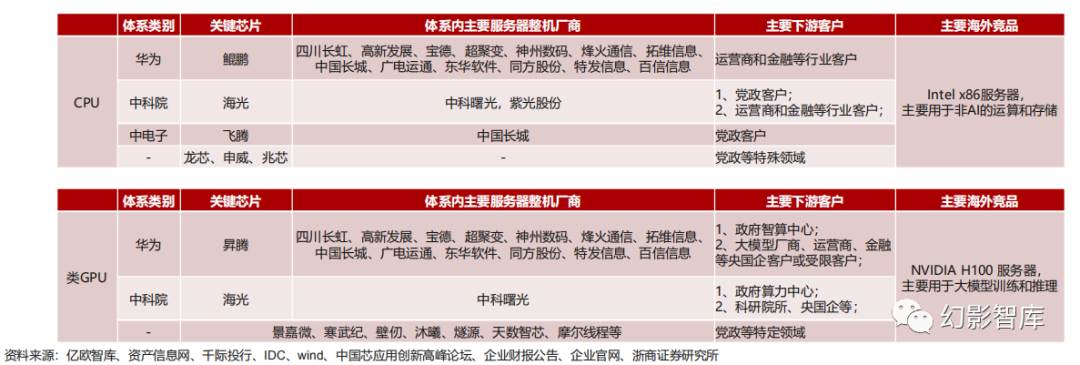
国内算力产业链的三大体系
在国内,算力产业链整体属于生产制造业,经过多年发展,上下游厂商往往存在较为密切的股权/业务关系,可分为如下体系:
中科院系——以海光为核心芯片,以中科曙光及ODM为主要整机厂的x86信创服务器体系,兼容性好;
华为系——以鲲鹏+昇腾为核心芯片,以华为硬件生态合作伙伴(四川长虹、高新发展、宝德、超聚变、神州数码、烽火通信、拓维信息等)为主 要整机厂的Arm信创服务器体系,自主可控程度更高;
中电子系——以飞腾为核心芯片,以中国长城为主要整机厂的Arm信创服务器体系,自主可控程度高;
整体上看,我国正在逐步完善产业链和生态,以应对日趋复杂的国际局势。
国产CPU技术路线正逐步趋于收敛
CPU根据架构主要分为x86及Arm,技术路线正逐步收敛于华为和海光两大体系。芯片的发展更看重能否形成更加完善的生态闭环,要求上游 供应相对充足、自身性能及价格相比国外芯片具备一定的性价比、下游生态覆盖面广且最好是主流生态,综合上述因素来看,未来信创及商用 CPU技术路线将逐步向华为ARM体系及海光X86体系收敛。

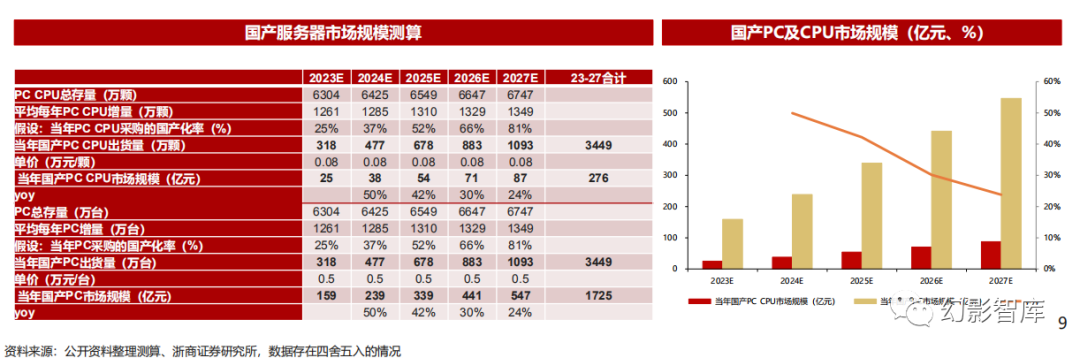
2027年国产PC市场规模有望达到547亿
我们预计27年国产PC市场空间有望达到547亿。根据我们《信创框架报告》测算,我们预计2024年国产PC CPU市场规模有望达到38亿(同比 +50%),2027年有望达到87亿(24-27年CAGR+19%);2024年国产PC市场规模有望达到239亿(同比+50%),2027年有望达到547亿 (24-27年CAGR+32%) 。
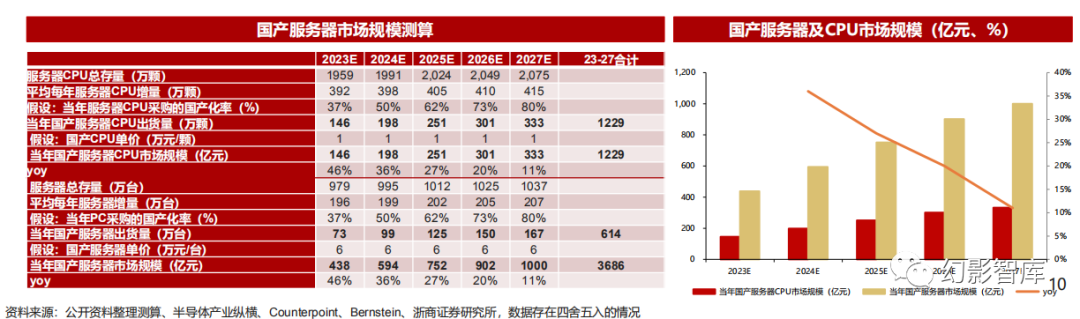
2027年国产服务器市场规模有望达到千亿
2022年服务器芯片国产化率达到25%。按照Counterpoint,2022年全球服务器芯片市场中X86占91%、ARM占6%、其它芯片占3%;根据 Bernstein,目前中国市场服务器中ARM占比约15%,其它国产CPU(龙芯、海光、兆芯、申威等)占比约10%,合计国产芯片服务器占比达到 25%;
我们预计27年国产服务器市场空间有望达到千亿。根据我们《信创框架报告》测算,我们预计2024年国产服务器CPU市场规模有望达到198亿 (同比+36%),2027年有望达到333亿(24-27年CAGR+19%);2024年国产服务器市场规模有望达到594亿(同比+36%),2027年有望 达到1000亿(24-27年CAGR+19%) 。
以运营商和金融为代表的行业客户已开始大规模集采国产服务器
23年下半年开始,运营商和金融客户陆续进行国产服务器大规模集采,我们预计未来能源电力、制造业、医疗、教育等行业的央国企客户信创 服务器集采也有望逐步开展;
供应上看,Arm服务器在以运营商和银行为代表的行业信创采购大单中占比持续提升,如中信银行65亿订单中Arm芯片服务器约占服务器采购 金额的3/4,我们预计未来Arm芯片服务器的份额将进一步提升。

ARM:华为鲲鹏CPU主打高性能和低功耗
鲲鹏920是华为自研的面向数据中心的核心CPU,主打高性能和低功耗。基于ARM v8.2架构,由华为公司自主设计完成,主频可达2.6GHz,单芯 片可支持64核,支持8通道DDR4、100G RoCE以太网卡,具备PCle4.0及CCIX接口,可提供640Gbps总带宽,通过优化分支预测算法、提升运算 单元数量、改进内存子系统架构等一系列微架构设计,大幅提高处理器性能,SPECint Benchmark评分超过930,超出业界标杆25%。
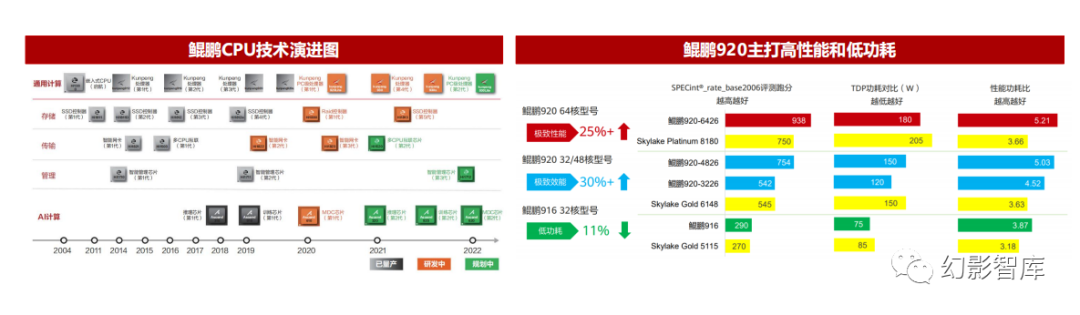
ARM:飞腾CPU可扩展性、安全性强
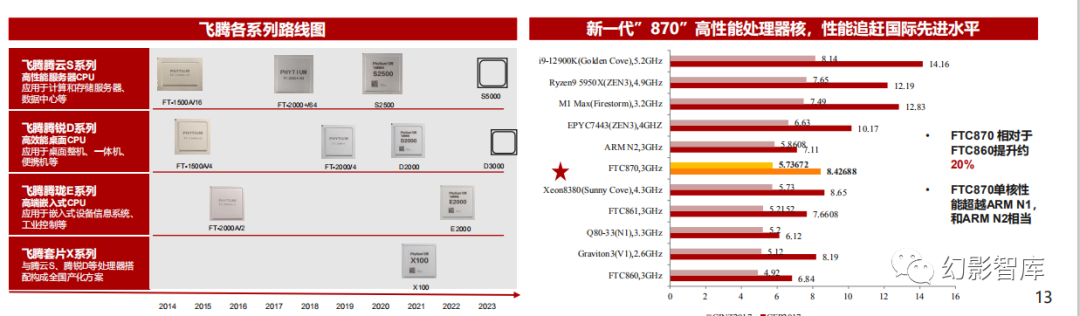
飞腾CPU兼具高可扩展、高性能、高安全、高可靠、高能效五大核心能力。2020年7月,飞腾正式发布了新一代可扩展多路服务器芯片——腾云S2500系 列,采用16nm工艺,64核架构,8路直连可达512核,与上代FT-2000+相比增加了4个直连接口,总带宽800Gbps,支持2路、4路和8路直连,可以形成 128核到512核的计算机系统;
根据芯智讯,飞腾新一代高性能处理器内核FTC870已经研发完成,并且性能达到了国际先进水平。FT870内核的主频可达3GHz,CINT2017得分为 5.73672,CFP2017得分为8.42688,整体性能相对于上一代的FTC860提升了约20%,同时也超越了Arm面向服务器市场的Neoverse N1内核,达到了与 Neoverse N2相当的水平,并且CFP2017的得分超过了Neoverse N2。
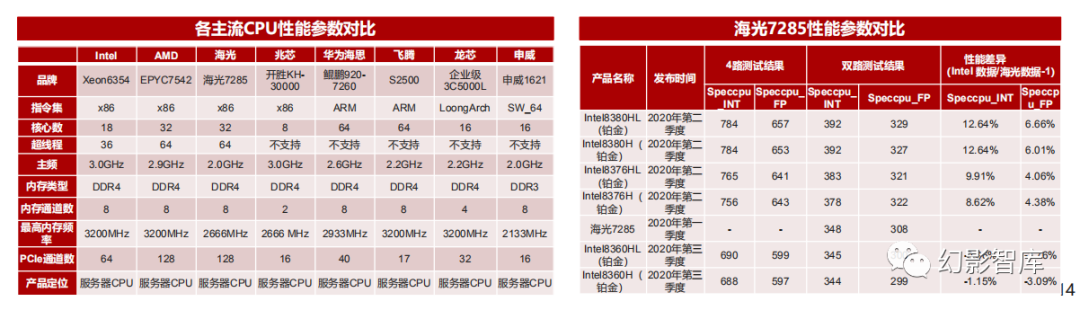
X86:海光CPU兼具性能和兼容性
海光基于AMD授权的x86指令集研制CPU,兼具性能和兼容性。以海光7285为例,相关参数为32核,64个超线程,2.0GHz主频,DDR4内存,内存通道数8, 最高内存频率2666MHz,PCIe通道数128;海光使用先进的处理器微结构和缓存层次结构,改进了分支预测算法,使得每个时钟周期执行的指令数得到显著提 高;依托先进的 SoC 架构和片上网络,集成了更多处理器核心;采用先进的工艺制程和物理设计方法,实现了处理器高主频设计,使海光 CPU 产品具有优异 的产品性能,目前公司多款产品已在核心数、支持内存、内存通道数、PCIe通道数等方面处于国内前列,比肩全球主流产品;
海光三号系列芯片是公司目前的主力产品。最高规格具备32核心64线程,拥有多达128条PCle4.0通道,支持内存频率提升至3200MHZ。相比上一代产品,海 光三号的整体实测性能提升了约45%。在SOC设计、I/O带宽、取指单元、功能模块、防御机制等方面,海光三号均做了不同程度的优化,综合性能大幅跃升。
海光四号有望采用全新自研微架构,有望对标Intel最新代顶级型号处理器的性能水平。
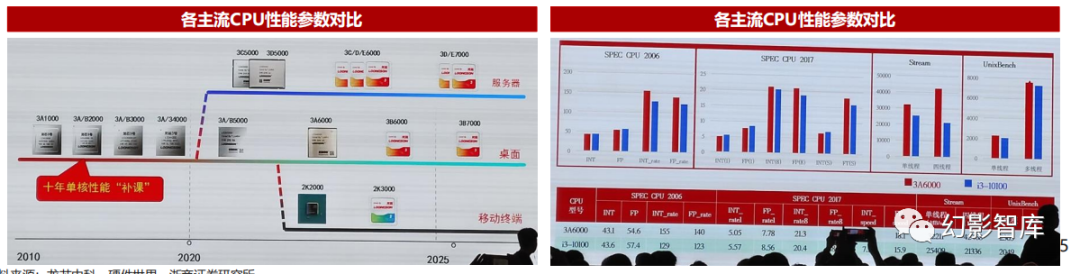
LoongArch:龙芯3A6000性能比肩第10代酷睿i3处理器
LoongArch龙架构为完全自主设计,与国际主流处理器的设计差距已补齐。第四代微架构LA664突破了国际主流CPU的标配——同时多线程 (SMT) 技术,全面提升了各 项指标,首次将4发射提升到6发射,同时在ROB、定点/向量物理寄存器、发射队列、功能部件、载入/存储队列等各项指标上,都实现了50%到100%的提升,基本补齐 了与当今主流处理器在通用处理能力、单核性能、设计能力的差距;
3A6000性能与2020年10代酷睿i3-10100处理器相当。首款产品龙芯3A6000采用自主成熟工艺制造,4个物理核心,支持同时多线程技术(SMT2),因此有8个逻辑核心, 主频为2.5GHz,集成安全可信模块,可提供安全启动方案和国密(SM2、SM3、SM4等)应用支持;根据芯智讯,龙芯3A6000处理器总体性能与Intel 2020年上市的第10 代酷睿i3-10100四核处理器基本相当,下一步争取使用成熟工艺达到英特尔、AMD 先进工艺 CPU 的性能;
龙架构开放授权,打造国际第四大开源生态。在国外,龙架构获得了国际开源生态编号258,与x86、Arm、RISC-V处于等同的地位,得到了Linux系统内核、GCC/LLVM 两大支柱性编译器、Rust/Golang/Pascal等传统与新兴编程语言、Nodejs/.net等主流应用开发框架等开源社区、开源软件的快速支持;在国内,首批面向微控制器、嵌 入式、终端的龙芯CPU IP核已开放授权,国产操作系统及国内基础应用已支持龙架构,可以满足基本的办公、娱乐需求。
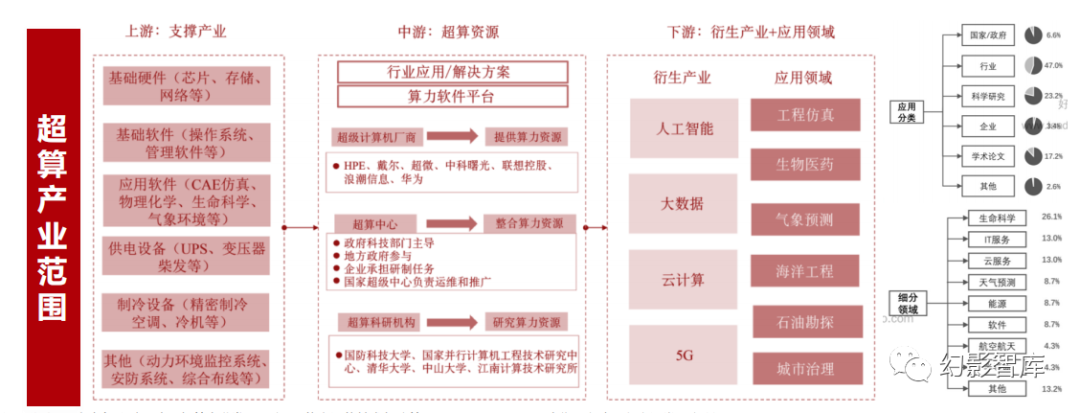
超级计算用于处理极端复杂或数据密集型问题
超级计算,又称高性能计算 (HPC),是计算科学的重要前沿分支,指利用并行工作的多台计算机系统(即超级计算机)的集中式计算资源,处理 极端复杂或数据密集型问题,与智算相比,超算要求双精度计算(FP64),而智算一般要求单精度、半精度计算(FP32、16、8);
超算产业呈现典型的政策性特征。由于超算芯片所需技术难度较大,同时下游应用一般以前沿基础科学研究等非商业化需求为主,因而主要参与 者为央国企、科研院所等单位,整体产业链发展呈现一定的政策周期性。
超算芯片受限较早,我国超算在政策加持下已进入互联阶段
超算CPU已在8年前受限。早在2015年4月,美国商务部就拒绝Intel向中国的国家超算广州中心、长沙中心、天津中心和国防科大出售“至强”芯片用于天河二号系统升 级的申请,并将这4所中国机构列入出口管制名单;后续美国不断加紧对我国超算相关单位的限制,如2019年6月美国商务部依据《进出口管理条例》对中国超算三巨头 中的“神威”和“曙光”实施制裁,将与此两者相关的5家中国企业列入“实体清单”,禁止向其提供美国技术及元器件;
我国自受限后就开启了自强之路。2016年《“十三五”国家科技创新规划》明确提出要突破超级计算机中央处理器(CPU)架构设计技术,而后2021年的十四五规划明确提 出建设E级和10E级超级计算中心,目前为了促进国产超算算力的上架率,科技部启动了超算互联网建设工作,目标建成一体化超算算力网络和服务平台,实现算力资源的 统筹调度。

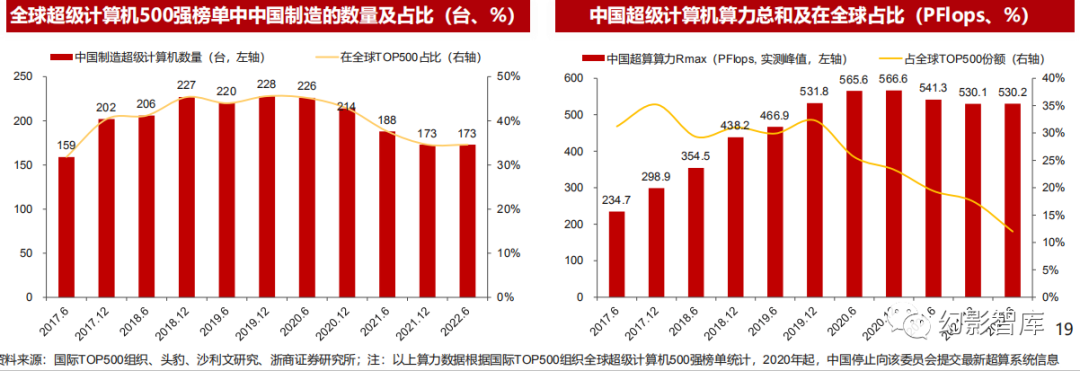
中国超算算力总和2020年已达566PFlops
在全球Top500榜单中,中国供应商制造超级计算机数量连续9次市场份额位居全球第一。2018年底-2020年中,全球Top500榜单中,中国 超算上榜数量占比约为45%。
2017-2019年,中国供应商制造超级计算机算力总和在全球Top500超算算力总和占比约为三成,低于数量占比。
2020年起,中国停止向TOP500组织提交最新超算系统信息,故此后数量和算力占比均有所下滑。
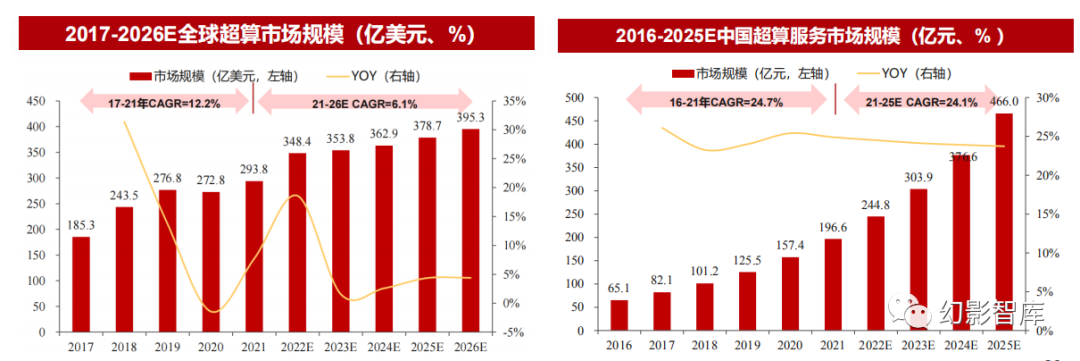
预计2025年中国超算市场规模达到466亿元
全球来看,据头豹研究院预计,以供应商HPC市场收入为口径进行市场规模测算,2017-2021年全球超算市场规模CAGR为12.2%,预计2021-2026年CAGR为 6.1%,2026年超算HPC市场规模将达到395.3亿美元;
中国来看,根据沙利文研究测算,2016-2021年中国超算服务市场规模CAGR为24.7%,预计2021-2025年CAGR为24.1%,2025年中国超算服务市场规模将达到 466亿元。
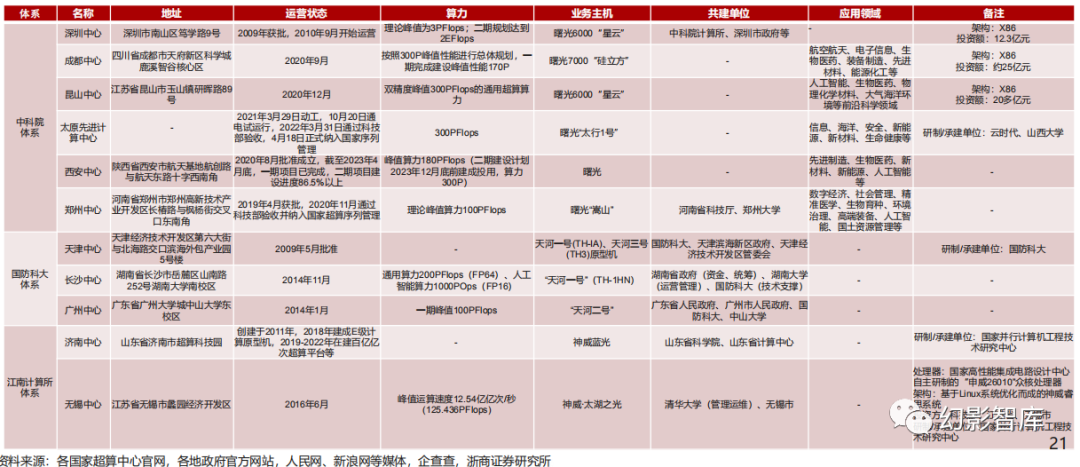
全国有11家国家级超算中心,中科院体系占比过半
由于超算与国家前沿基础科学研究的需求紧密相关,因此我国国家级超算中心基本可分为中科院、国防科大和江南计算所三大体系,从数量 上看,中科院体系份额超过50%;
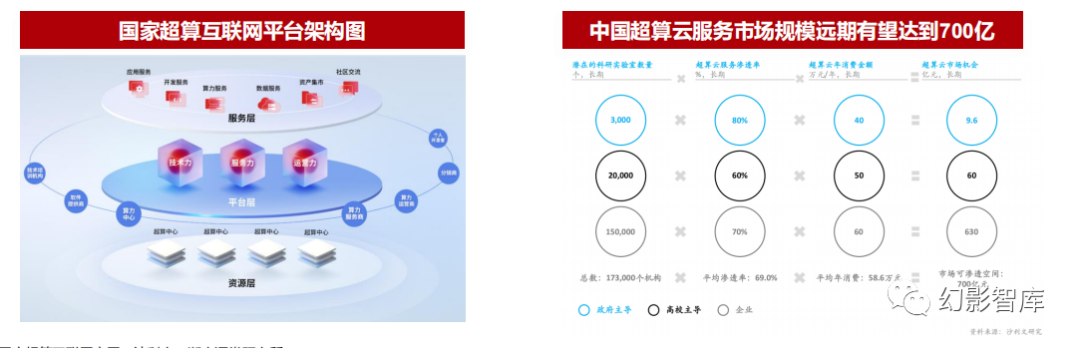
超算上云是必经之路,超算云服务市场规模有望达到700亿
国家超算互联网分为基础算力层、运行管理层、服务运营商三层参与者。由超算中心提供基础算力,运行管理者负责管理资源并实现接口调用,服务运营商作为超算服务 运营主体,未来还可以建设类似应用商店的超算应用软件平台,目标是到2025年底,通过超算互联网建设,打造国家算力底座,促进超算算力的一体化运营;
超算服务需要大量同时熟悉超算技术和行业科研思维的复合型人才,互联有利于资源的有效配置。由于超算涉及领域广泛且细碎,如海洋气象、地质勘探、工业仿真、富 媒体渲染等超算服务场景对超算服务的要求不尽相同,包括超算资源的调度、软件系统的搭配等均不一,因而只有服务商对各个典型使用场景有着深刻的理解,才能设计 出符合下游用户使用习惯的产品服务矩阵,各国家级超算中心人才专长领域不同,超算互联和上云有利于实现人才、资源的合理配置,促进超算行业的商业化发展;
中国超算云服务市场规模远期有望达到700亿。根据沙利文,按照实验室数量*超算云服务渗透率*年消费额的公式测算,预计中国超算云服务市场规模远期有望达到700亿 ,其中630亿为企业主导,未来商用企业市场潜力巨大。
智算算力新基建顶层规划已出,各地政策有望逐步跟进
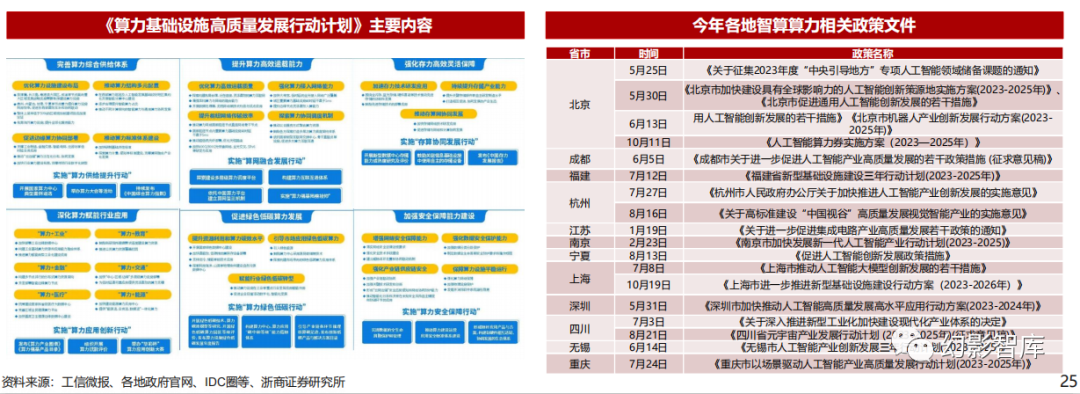
《算力基础设施高质量发展行动计划》从全局对全国智算算力进行了顶层规划,并强调网络联通,以往各自为政的局面有望得到统一,使用国产芯片建设的智算中心上架率 有望提升。10月9日,工信部等六部门联合印发《算力基础设施高质量发展行动计划》(以下简称“行动计划”),明确提出了到2025年全国算力目标规模超过300EFlops ,智能算力占比达到35%,重点应用场所光传送网(OTN)覆盖率达到80%,工业、金融等领域算力渗透率显著提升,医疗、交通等领域应用实现规模化复制推广,能源、 教育等领域应用范围进一步扩大;“行动计划”从顶层明确了未来三年全国智算算力的建设目标及节奏,解决了各地智算中心建设节奏、标准不统一、各自为政的情况,可 以从全国层面实现智算算力的混合调用,也将有利于提升国产智算算力上架率。
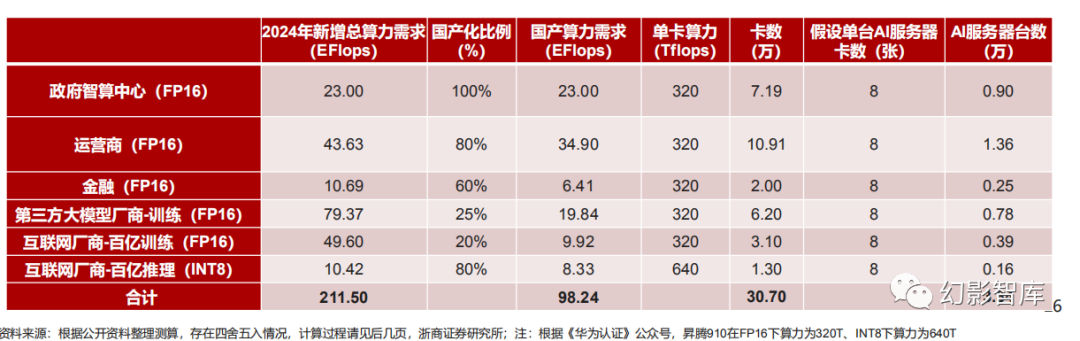
2024年国产AI算力需求有望接近100EFlops
考虑到我国国产AI芯片供应商的产能供应、生态适配、综合性价比等情况,国内AI芯片与英伟达H100芯片相比仍有一定差距, 因此我们认为政策性客户有望逐步全面转向国产AI芯片,商用客户如互联网有望将百亿参数模型的部分训练和推理需求转向国 产AI芯片,2024年我国国产芯片主要需求将包括:政府智算中心、运营商、金融、第三方大模型厂商、互联网厂商,根据我们 的测算,按8卡昇腾910 AI服务器计算,2024年预计昇腾910出货量为30.7万张,对应3.84万台AI服务器。
1、2024年政府智算中心国产AI算力增量需求为23EP,需要7.19万张昇腾910卡,0.90万台AI训练服务器
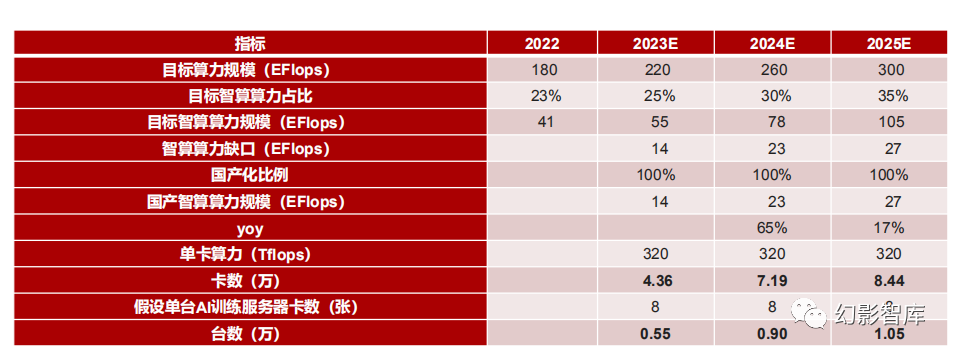
根据信通院发布的《2023智能算力发展白皮书》,2022年中国算力总规模已经高达180 EFlops,其中智能算力规模达到了41EFlops;工信部发 布的《算力基础设施高质量发展行动计划》设定到2025年全国算力目标规模超过300EFlops,智能算力占比达到35%,由此我们可得到2024年智 算算力缺口为260*30%-220*25%=23EFlops,考虑到智算中心建设为政府行为,因此我们认为国产芯片供应占比将达到100%,即2024年政府 智算中心国产AI算力需求为23EFlops,对应需要昇腾910卡7.19万张,AI训练服务器0.90万台。
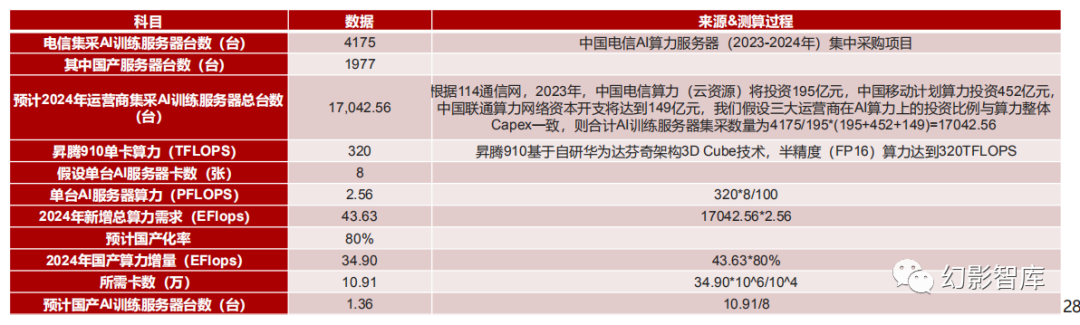
2、2024年运营商国产AI算力增量需求为34.90EFlops, 需要10.91万张昇腾910卡,1.36万台AI训练服务器
据C114通信网,中国电信AI算力服务器(2023-2024年)集中采购项目共分为4个标包,总金额为84.62亿,总采购规模为4175台训练型服务器 (根据芯智讯,使用国产鲲鹏芯片的AI服务器1977台,占整体采购数量的47.35%,总金额28亿)及1182台IB交换机,在当前背景下,我们认为 :
1)运营商将与云计算时代类似,部分承担地方算力基建任务,并提供智算算网服务;
2)移动、联通、电信三大运营商招采节奏相近,算力服 务器采购数量与2023年各家算力网络Capex比例一致;
3)运营商将作为信创排头兵承担AI算力信创任务,国产化率有望达到80%;由此可得到 2024年运营商增量国产AI算力需求为34.90EFlops, 需要10.91万张昇腾910卡,1.36万台AI训练服务器
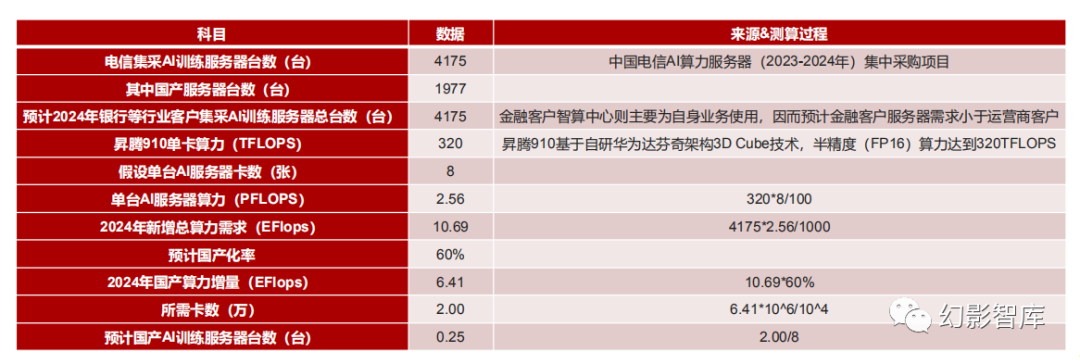
3、2024年金融等行业客户国产AI算力增量需求为6.41EFlops,需要2万张昇腾910卡,0.25万台AI训练服务器
我们认为运营商客户需要部分额外负担地方智算中心的基建职责,金融客户智算中心则主要为自身业务使用,因而预计金融客户服务器需求小于 运营商客户,即6家国有银行及12家股份制银行等行业客户的AI服务器采购规模为4175台,假设国产化率60%,则可得到国产AI服务器需求为 1670台,对应算力规模为6.41EFlops,需要2万张昇腾910卡,0.25万台AI训练服务器。
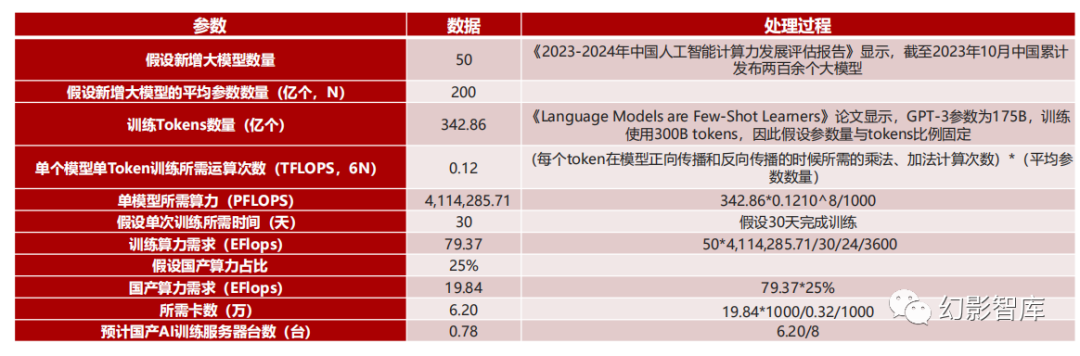
4、2024年第三方大模型厂商的国产AI算力增量需求为19.84EFlops,需要6.20万张昇腾910卡,0.78万台AI训练服务器
《2023-2024年中国人工智能计算力发展评估报告》显示,截至2023年10月中国累计发布两百余个大模型,其中以科研院所和互联网企业为开发 主力军,我们认为院所以及讯飞、智谱、智源等第三方大模型厂商或由于算力供应受限,可能会由国内芯片解决部分算力需求,假设2024年新增 大模型总数为50个,平均模型参数量为200亿,算力国产化率为25%,则可得到2024年第三方大模型厂商的国产AI算力增量需求为19.84EFlops ,需要6.20万张昇腾910卡,0.78万台AI训练服务器.
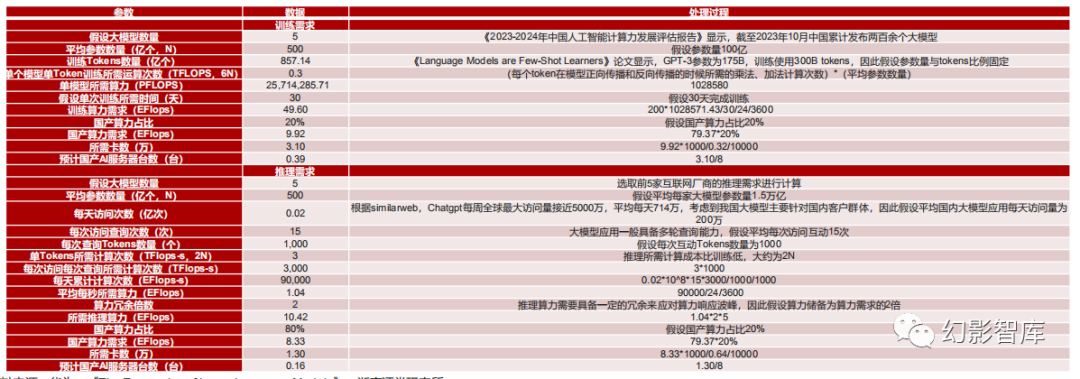
5、互联网厂商需要国产算力分别为9.92EFlops(FP16)、8.33EFlops(INT8),合计需要4.4万张昇腾910卡,0.55万台AI服务器
美国芯片禁令限制了国内通过官方渠道获取A800、H800等主流GPU的方式,目前阿里云官网已下架英伟达A系列服务器云计算产品、百度为200台服务器订购了1600片昇腾910BAI芯片,因而我 们预计互联网厂商在算力选择上将呈现如下情况:
1)百亿模型推理率先实现国产替代,通过工程师团队持续调优来实现学习和提升迁移能力以及运算性能,最终等效于A800;
2)百亿模型训练 在2024年逐步实现国产替代;
3)千亿模型推理、训练仍以英伟达芯片为主,后续预算根据各个芯片的实际性价比进行考虑,关键因素包括硬件成本+人员成本+实际性能;
我们假设2024年在百亿参数模型上将实现20%的训练需求国产化以及80%的推理需求国产化,则可算得需要国产算力分别为9.92EFlops、8.33EFlops,合计需要4.4万张昇腾910卡,0.55万台AI 服务器。
2024年国产AI服务器市场规模有望达到409亿
综上,我们预计2024年国内新增AI总算力需求为211.5EFlops(FP16),其中国产算力需求为98.24EFlops(FP16),国产化比例为46.45%,按 单张昇腾910算力320TFLOPS计算,对应需要昇腾910为30.70万张,按单台服务器8张昇腾910计算对应3.84万台AI服务器;
根据京东,昇腾Atlas 300T A2训练卡均价在10万以上,因此可得2024年昇腾芯片潜在市场规模约为=30.7*10=307亿;
根据IDC,训练型服务器的GPU成本占比约为72.8%,我们假设8张昇腾Atlas 300T A2的训练服务器中GPU占比75%,由此可得2024年华为昇腾服 务器潜在市场规模为409.33亿。
国产AI芯片单卡部分指标接近英伟达,华为、海光具备竞争力
运算协处理器基于不同的设计思想存在多条技术路线,包括 GPGPU、ASIC、FPGA等。其中 GPGPU 的代表企业包括 NVIDIA 和 AMD;利用 ASIC 技术,许多大公司都 研发了协处理器产品,包括 Intel 的 Phi 和 NNP、Google 的 TPU、华为昇腾、寒武纪思元等;基于 Intel、Xilinx 的 FPGA,出现过很多专用协处理器产品。综合考虑性 能、能效比和编程灵活性等方面的因素,GPGPU 在协处理器应用领域具有非常明显的优势,目前广泛应用于商业计算、人工智能和泛人工智能等领域。
国产AI芯片供应商基本可分为体系化厂商(华为、海光、寒武纪等)、互联网自研(平头哥等)、初创厂商(壁仞、沐曦、燧源、摩尔线程)三类,体系化厂商具备相对完 善的生态、丰富的行业应用经验、大量的客户积累以及相对稳定的供应体系,因为AI算力的底层硬件需求相对比较统一和标准化,所以我们认为未来AI芯片有望类似CPU芯 片,呈现集中度提升的趋势,最终形成寡头竞争的格局。
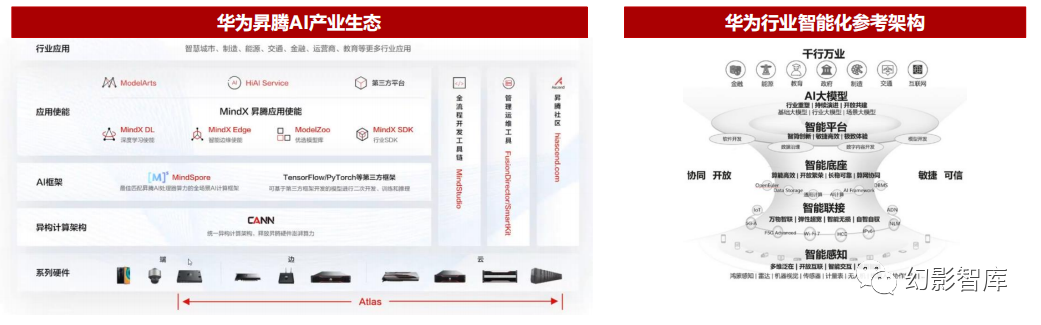
华为昇腾已形成完善的多层产业生态
昇腾计算产业:基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈AI计算基础设施、行业应用及服务,包括昇腾系列处理器、系列硬件、CANN( Compute Architecture for Neural Networks,异构计算架构)、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链。
华为昇腾AI产业生态包括昇腾AI基础软硬件平台,即Atlas系列硬件、异构计算架构CANN、全场景AI框架昇思MindSpore、昇腾应用使能MindX以及一站式开发平台 ModelArts等。基于昇腾910系列板卡,华为推出了AI训练集群Atlas900、AI训练服务器Atlas800、智能小站Atlas500、AI推理与训练卡Atlas300和AI加速模块 Atlas200,完成了Atlas全系列产品布局,支持万亿参数大模型训练,同时覆盖云、边、端全场景。
华为提出了具备分层开放、体系协同、敏捷高效、安全可信等特征的,全行业通用的行业智能化参考架构。其中智能底座提供大规模AI算力、海量存储及并行计算框架, 支撑大模型训练,提升训练效率,提供高性能的存算网协同。根据场景需求不同,提供系列化的算力能力。适应不同场景,提供系列化、分层、友好的开放能力。另外, 智能底座层还包含品类多样的边缘计算设备,支撑边缘推理和数据分析等业务场景。
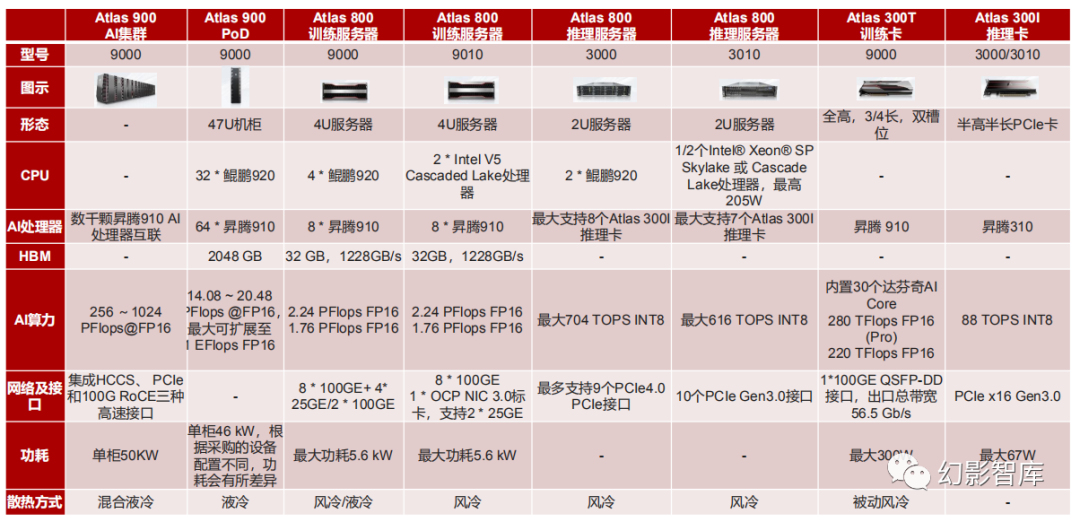
华为昇腾从推理卡到算力集群的多层AI算力硬件体
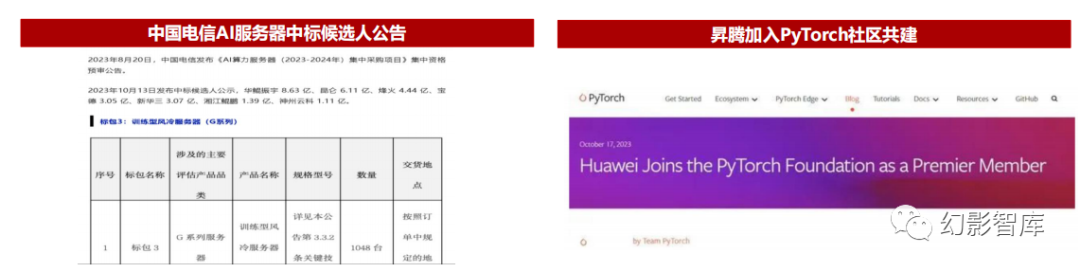
系昇腾加入PyTorch社区共建,有望为世界提供第二AI算力选择
性能上,昇腾910b正逐步接近A100。昇腾910基于自研华为达芬奇架构3D Cube技术,半精度(FP16)算力达到320TFlops,科大讯飞创始人、董事长刘庆峰表示华为 的 GPU 能力可以对标英伟达A100;
应用上,昇腾服务器已在政府智算中心、运营商、银行、央国企、互联网等AI算力领域全面规模化落地。智算中心方面,昇腾算力集群已在华为云、东数西算的枢纽节点 贵州和内蒙、中国28个城市的AI智算中心大规模商用部署,神州数码已与恒为科技签订4亿昇腾服务器订单合同;运营商方面,10月,中国电信公布了AI算力服务器集采 中标公告,G系列训练服务器总金额28亿,占整体订单金额的1/3;互联网方面,百度为200台服务器订购了1600片昇腾910B AI芯片,我们预计未来以政府智算中心、运 营商、金融以及IT企业、互联网等客户有望为昇腾服务器的增长提供强劲动力。
未来,昇腾有望构建世界第二“CUDA”生态。目前昇腾迭代的瓶颈在于生态,以英伟达CUDA为核心的AI算力生态是当今世界大模型的主流,10月18日华为作为 Premier最高级别会员正式加入全球AI开源框架PyTorch社区,PyTorch 2.1版本已同步支持昇腾NPU,开发者可直接在PyTorch 2.1上基于昇腾进行模型开发,基于 PyTorch,昇腾已经适配了BLOOM、GPT-3、LLaMA等业界主流大模型,深度优化后性能可持平业界,我们预计未来昇腾迭代速度有望加快,并复刻鲲鹏计算生态发展 历程,在各行业遍地开花。
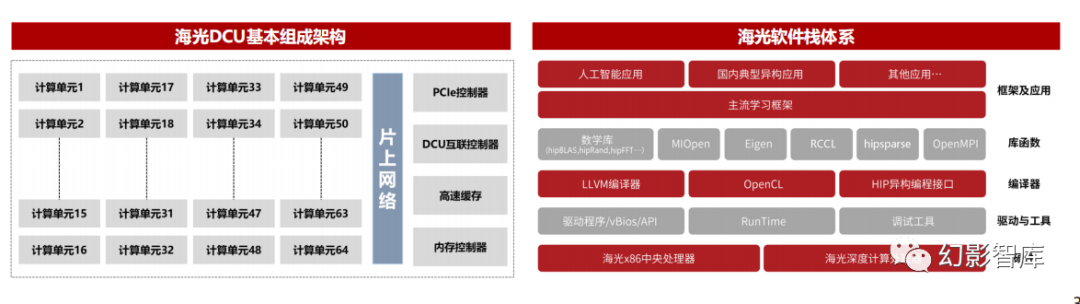
海光DCU产品具备完善的软件栈支持
海光DCU属于GPGPU的一种。CUDA是一种由NVIDIA推出的通用并行计算架构,包含了应用于NVIDIA GPU的指令集(ISA)以及GPU内部并行计算引擎。海光DCU协 处理器全面兼容ROCm GPU计算生态,由于ROCm和CUDA在生态、编程环境等方面具有高度的相似性,CUDA用户可以以较低代价快速迁移至ROCm平台,因此ROCm 也被称为“类CUDA”。因此,海光DCU协处理器能够较好地适配、适应国际主流商业计算软件和人工智能软件,软硬件生态丰富,可广泛应用于大数据处理、人工智能 、商业计算等计算密集类应用领域,主要部署在服务器集群或数据中心,为应用程序提供高性能、高能效比的算力,支撑高复杂度和高吞吐量的数据处理任务。
海光DCU具备开放式生态和统一底层硬件驱动平台,支持常见计算框架、库和编程模型层次化软件栈,适配不同API接口和编译器可最大限度利用已有的成熟AI算法和框 架
海光DCU性能逐步接近英伟达A100,能够完整支持大模型训练
公司新产品加速迭代,性能持续提升,研发团队在高端处理器设计、SoC架构设计、处理器安全、处理器验证、高主频与低功耗处理器实现、高端芯片IP设计、工艺物理设 计、先进封装设计、基础软件等关键技术上不断实现突破。
性能上,海光深算一号DCU内核频率、显存位宽已逐步接近英伟达A100,在显存容量、带宽、算力、互联性能上仍有一定的进步空间;深算二号已于2023年Q3发布,实 现了在大数据处理、人工智能、商业计算等领域的商业化应用,具有全精度浮点数据和各种常见整型数据计算能力,性能相对于深算一号实现了翻倍的增长;深算三号研 发进展顺利。
在AIGC持续快速发展的时代背景下,海光DCU能够完整支持大模型训练,实现LLaMa、GPT、Bloom、ChatGLM、悟道、紫东太初等为代表的大模型的全面应用,与 国内包括文心一言等大模型全面适配,达到国内领先水平。

总结:
AI算力有望实现加速国产化。
我们复盘了超算、通用算力的发展历史,认为国产AI算力有望复刻发展历程,从“可用”迈向“好用”,并且在当前国际局势下,AI算力国 产化进程有望加速,具体看2024年将为“客户初选适配年”,2025年将为“客户主动采购年”,2026年国产AI芯片有望成为主导。
普通云计算:已从“可用”迈向“好用”,27年国产服务器市场空间千亿。
我们预计2024年国产服务器CPU市场规模有望达到198亿(同比+35.6%),2027年有望达到 333亿(24-27年CAGR+19%);2024年国产服务器市场规模有望达到594亿(同比+35.6%),2027年有望达到1000亿(24-27年CAGR+19%);根据Bernstein, 2022年国产芯片服务器占比达到25%(ARM占15%,其余占10%);2023年下半年开始,运营商和金融客户陆续进行国产服务器大规模集采,其中Arm服务器在以运营 商和银行为代表的行业信创采购大单中占比持续提升,因而我们认为未来信创服务器将呈现华为、海光为主的格局。

超算:受限较早,超算云服务远期空间有望达到700亿。
我国超算CPU已在8年前受限并开启了自强之路,根据沙利文,2016-2021年中国超算服务市场规模CAGR为 24.7%,预计2021-2025年CAGR为24.1%,2025年中国超算服务市场规模将达到466亿元,为了促进国产超算算力的上架率,2023年科技部启动了超算互联网建设工作 ,预计中国超算云服务市场规模远期有望达到700亿,其中630亿为企业主导,未来商用企业市场潜力巨大。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 银河麒麟桌面操作系统备份用户数据 130
- 统信桌面专业版【全盘安装UOS系统】介绍 128
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 120
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 108
- 麒麟系统连接打印机常见问题及解决方法 28
- 最近下载排行榜
- 银河麒麟桌面操作系统备份用户数据 0
- 统信桌面专业版【全盘安装UOS系统】介绍 0
- 银河麒麟桌面操作系统安装佳能打印机驱动方法 0
- 银河麒麟桌面操作系统 V10-SP1用户密码修改 0
- 麒麟系统连接打印机常见问题及解决方法 0

prtyaa 收益393.62元

zlj141319 收益218元

1843880570 收益214.2元

IT-feng 收益210.13元

风晓 收益208.24元

777 收益172.71元

Fhawking 收益106.6元

信创来了 收益105.84元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
