GaussDB云数据库SQL应用系列—分区表管理
前言
本文将介绍GaussDB云数据库的分区表技术,包括原理、优势以及如何使用。通过本文,您将了解到如何利用GaussDB云数据库的分区表功能提高数据存储和查询性能。
一、分区表基本原理
1、分区表是一种数据组织方式,将一张大表按照某个字段的值进行划分,形成多个小表。每个小表独立管理,具有独立的索引和存储空间。这种方式可以提高查询性能和降低存储成本。
2、在GaussDB云数据库中,分区表可以根据用户需求自动或手动创建。目前行存表支持范围分区、哈希分区、列表分区,列存表仅支持范围分区。
二、分区表主要优势
1、查询性能提升 :分区表将数据分散到多个小表中,使得查询时只需扫描对应小表的数据,减少了扫描的范围,从而提高了查询速度。
2、数据维护便捷 :对于大型表,数据维护变得非常困难。而分区表可以将数据分散到多个小表中,使得数据维护更加便捷。例如,对某个分区进行删除操作时,只需要删除该分区对应的小表即可。
3、扩展性好 :随着业务的发展,数据量会不断增加。分区表可以根据业务需求动态调整分区数量,以满足更高的查询性能和存储需求。
三、分区表常见场景
1、大数据处理:在处理大量数据时,分区表可以显著提高查询性能和存储效率。通过将数据按照某个字段进行分区,可以减少扫描的数据量,从而提高查询速度。
2、高并发访问:分区表可以有效地降低单个表的锁竞争,提高并发访问能力。当多个用户同时访问一个分区表时,每个用户只能访问到自己需要的部分数据,降低了锁冲突的可能性。
关于GaussDB,若要把普通表转成分区表,需要新建分区表,然后把普通表中的数据导入到新建的分区表中。因此在初始设计表时,请根据业务提前规划是否使用分区表。
四、GaussDB分区表管理(示例)
示例一:创建范围分区表(RANGE)
范围分区表:将数据基于范围映射到每一个分区,这个范围是由创建分区表时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期,例如将销售数据按照月份进行分区。
1、创建一个按年份分区的订单表:
--创建范围分区表(RANGE)DROP TABLE orders_1;CREATE TABLE orders_1 (id INT PRIMARY KEY,order_date CHAR(4) ,customer_id INT,product_name VARCHAR(255)) PARTITION BY RANGE (order_date)( PARTITION p1 VALUES LESS THAN (2021),PARTITION p2 VALUES LESS THAN (2022),PARTITION p3 VALUES LESS THAN (2023),PARTITION P4 VALUES LESS THAN(MAXVALUE));--查看创建的分区表信息select relname,parttype,parentid,boundaries from pg_partition where parentid in (SELECT parentid FROM pg_partition where relname='orders_1');
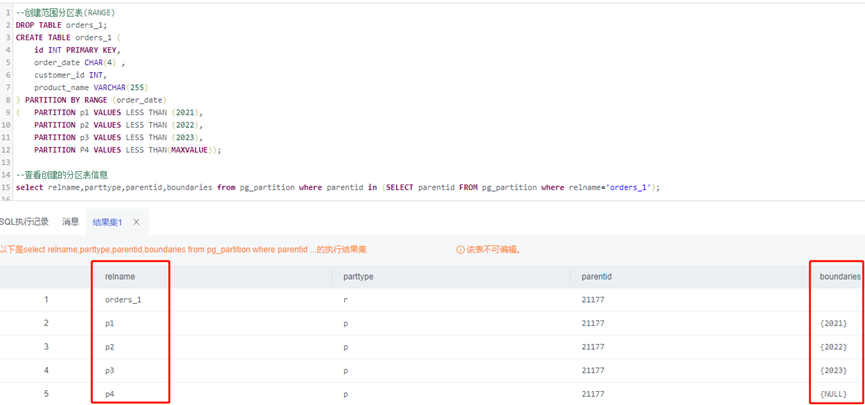
2、写入测试数据并访问
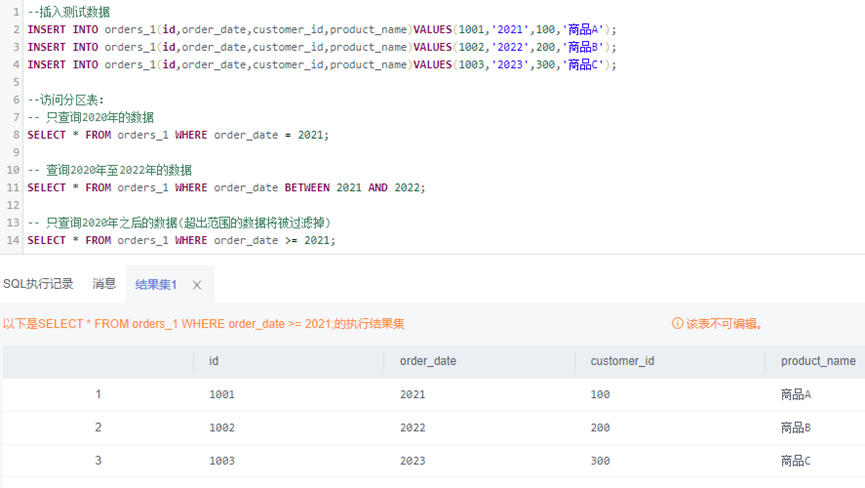
--插入测试数据INSERT INTO orders_1(id,order_date,customer_id,product_name)VALUES(1001,'2021',100,'商品A');INSERT INTO orders_1(id,order_date,customer_id,product_name)VALUES(1002,'2022',200,'商品B');INSERT INTO orders_1(id,order_date,customer_id,product_name)VALUES(1003,'2023',300,'商品C');--访问分区表:-- 只查询2020年的数据SELECT * FROM orders_1 WHERE order_date = 2021;-- 查询2020年至2022年的数据SELECT * FROM orders_1 WHERE order_date BETWEEN 2021 AND 2022;-- 只查询2020年之后的数据(超出范围的数据将被过滤掉)SELECT * FROM orders_1 WHERE order_date >= 2021;
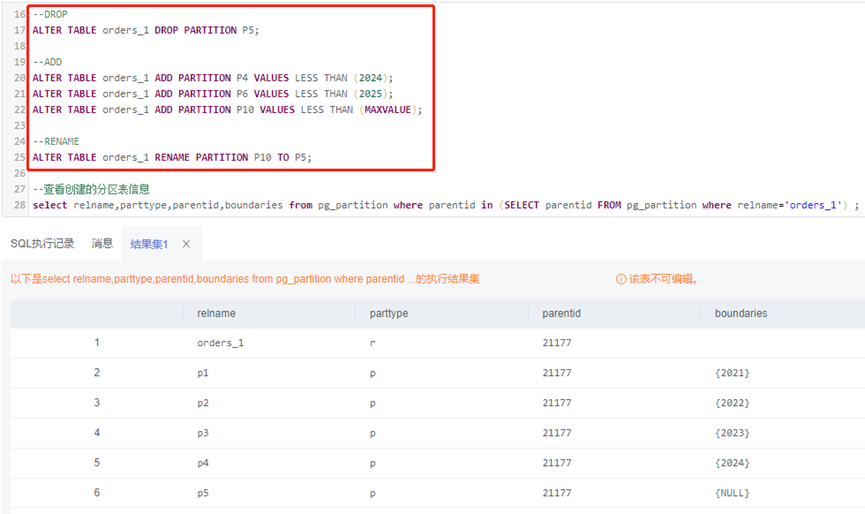
3、删除/增加/修改
--DROPALTER TABLE orders_1 DROP PARTITION P5;--ADDALTER TABLE orders_1 ADD PARTITION P4 VALUES LESS THAN (2024);ALTER TABLE orders_1 ADD PARTITION P6 VALUES LESS THAN (2025);ALTER TABLE orders_1 ADD PARTITION P10 VALUES LESS THAN (MAXVALUE);--RENAMEALTER TABLE orders_1 RENAME PARTITION P10 TO P5;--查看创建的分区表信息select relname,parttype,parentid,boundaries from pg_partition where parentid in (SELECT parentid FROM pg_partition where relname='orders_1') ;
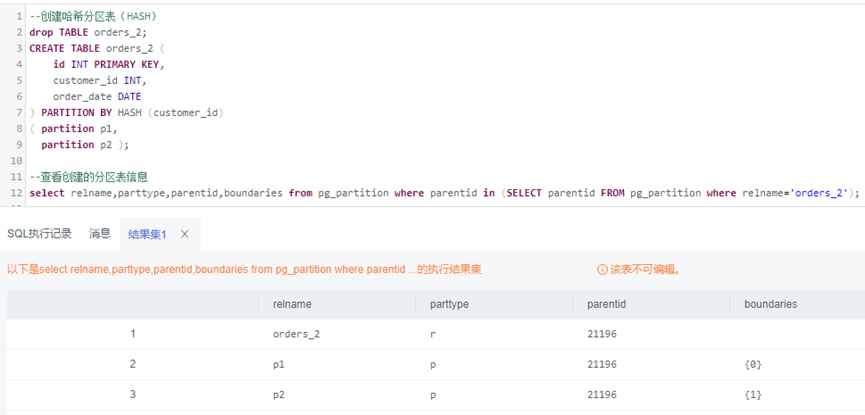
示例二:创建哈希分区表(HASH)
哈希分区表:将数据根据内部哈希算法依次映射到每一个分区中,包含的分区个数由创建分区表时指定。
1、假设我们有一个名为orders_2的大表,包含id(订单ID)、customer_id(客户ID)、order_date(订单日期)等字段。现在我们需要根据customer_id进行分区,以便更好地管理和查询这些数据。
--创建哈希分区表(HASH)drop TABLE orders_2;CREATE TABLE orders_2 (id INT PRIMARY KEY,customer_id INT,order_date DATE) PARTITION BY HASH (customer_id)( partition p1,partition p2 );--查看创建的分区表信息select relname,parttype,parentid,boundaries from pg_partition where parentid in (SELECT parentid FROM pg_partition where relname='orders_2');
2、写入测试数据并访问
--插入测试数据INSERT INTO orders_2(id,customer_id,order_date)VALUES(1001,100,date '20230613');INSERT INTO orders_2(id,customer_id,order_date)VALUES(1002,200,date '20230614');INSERT INTO orders_2(id,customer_id,order_date)VALUES(1003,300,date '20230615');INSERT INTO orders_2(id,customer_id,order_date)VALUES(1004,400,date '20230612');----访问分区表:--查询customer_id 为100的订单表信息SELECT * FROM orders_2 WHERE customer_id =100;--查询customer_id 为100、200的订单表信息SELECT * FROM orders_2 WHERE customer_id IN (100,200);--查询customer_id 不是100、200的订单表信息SELECT * FROM orders_2 WHERE customer_id NOT IN (100,200);
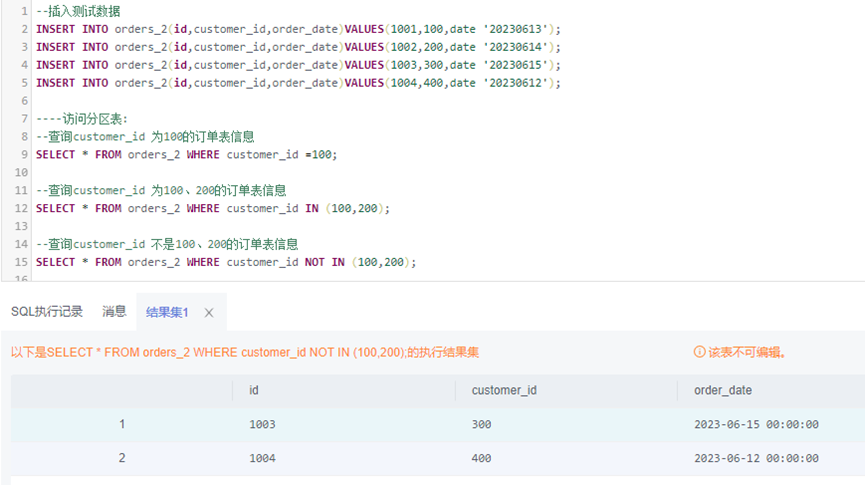
3、删除
--删除分区表 drop tableDROP TABLE orders_2 ;--删除分区数据 truncate分区alter table orders_2 truncate partition p2;
示例三:创建列表分区(LIST)
列表分区表:将数据中包含的键值分别存储在不同的分区中,依次将数据映射到每一个分区,分区中包含的键值由创建分区表时指定。
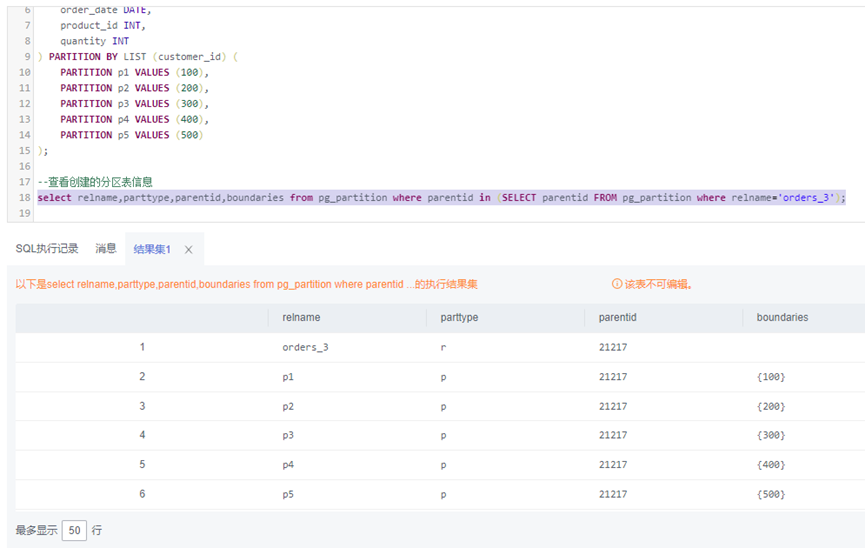
1、以订单表为例,创建一个list分区表
--创建列表分区(LIST)DROP TABLE orders_3;CREATE TABLE orders_3 (id INT PRIMARY KEY,customer_id INT,order_date DATE,product_id INT,quantity INT) PARTITION BY LIST (customer_id) (PARTITION p1 VALUES (100),PARTITION p2 VALUES (200),PARTITION p3 VALUES (300),PARTITION p4 VALUES (400),PARTITION p5 VALUES (500));--查看创建的分区表信息select relname,parttype,parentid,boundaries from pg_partition where parentid in (SELECT parentid FROM pg_partition where relname='orders_3');
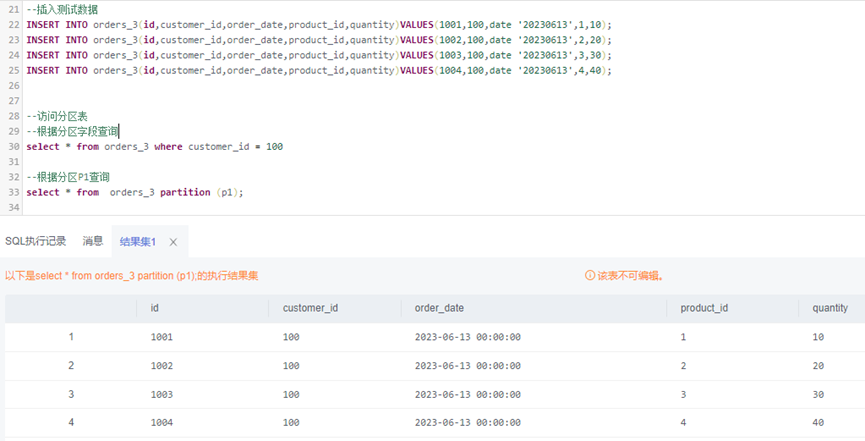
2、写入测试数据并访问
--插入测试数据INSERT INTO orders_3(id,customer_id,order_date,product_id,quantity)VALUES(1001,100,date '20230613',1,10);INSERT INTO orders_3(id,customer_id,order_date,product_id,quantity)VALUES(1002,100,date '20230613',2,20);INSERT INTO orders_3(id,customer_id,order_date,product_id,quantity)VALUES(1003,100,date '20230613',3,30);INSERT INTO orders_3(id,customer_id,order_date,product_id,quantity)VALUES(1004,100,date '20230613',4,40);--访问分区表--根据分区字段查询select * from orders_3 where customer_id = 100--根据分区P1查询select * from orders_3 partition (p1);
3、ADD/TRUNCATE/DROP
--ADD,增加分区ALTER TABLE orders_3 add partition p6 values (600);--TRUNCATE,删除分区数据ALTER TABLE orders_3 truncate partition p6;--DROP,删除分区表ALTER TABLE orders_3 drop partition p6;
五、总结
GaussDB云数据库是一款高性能、高可用的云原生关系型数据库,支持多种数据存储和计算引擎。其中,分区表是GaussDB云数据库的一项重要特性,在GaussDB云数据库中使用分区表,可以帮助用户提高查询性能、降低存储成本、方便数据维护等方面的问题。
如果您发现该资源为电子书等存在侵权的资源或对该资源描述不正确等,可点击“私信”按钮向作者进行反馈;如作者无回复可进行平台仲裁,我们会在第一时间进行处理!
- 最近热门资源
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 2065
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 1998
- 银河麒麟桌面操作系统【保留数据盘重装系统】 1808
- 麒麟系统各种原因开不了机解决(合集) 1598
- 桌面通用(全架构)【rpm包转成deb包】操作方法 932
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 916
- 统信系统安装(合集) 854
- 统信桌面专业版【手动分区安装UOS系统】介绍 846
- 统启动异常几种类型(initramfs 模式) 689
- 最近下载排行榜
- 桌面通用(全架构)【在双系统环境下隐藏Windows启动菜单】操作指南 0
- 银河麒麟桌面操作系统V10(SP1)2203-如何进行远程桌面互访? 0
- 银河麒麟桌面操作系统【保留数据盘重装系统】 0
- 麒麟系统各种原因开不了机解决(合集) 0
- 桌面通用(全架构)【rpm包转成deb包】操作方法 0
- 银河麒麟桌面操作系统 V10-SP1 双系统安装 efi 分区问题 0
- 统信系统安装(合集) 0
- 统信桌面专业版【手动分区安装UOS系统】介绍 0
- 统启动异常几种类型(initramfs 模式) 0

prtyaa 收益393.72元

zlj141319 收益221.27元

1843880570 收益214.2元

IT-feng 收益213.03元

风晓 收益208.24元

777 收益172.82元

Fhawking 收益106.6元

信创来了 收益105.89元

克里斯蒂亚诺诺 收益91.08元

技术-小陈 收益79.5元
